一种基于差分隐私的个性化位置语义发布方法及系统
本发明属于数据挖掘及隐私保护领域,涉及一种基于差分隐私的个性化位置语义发布方法及系统。
背景技术:
随着手机等移动终端设备的广泛使用以及无线通信技术的快速发展,基于位置的服务(location-basedservice,lbs)使用的越来越频繁,lbs通过定位技术,可以为用户提供如位置签到、周边商铺搜索、信息推送等的服务。在位置服务过程中会产生大量的空间位置数据,为了根据用户的喜好进行相关的推送,lbs提供商会将采集到的用户位置数据进行上传发布和分享。但是共享的位置数据中可能涉及用户的一些敏感信息,数据所有者可能不想直接分享自己的位置数据。
目前已有的位置隐私保护方法主要分为三种:基于空间匿名、基于加密和基于扰动的方法。空间匿名主要是将用户的位置进行隐藏,设置相应的的匿名参数级别,将用户的原始值和匿名值混淆来达到保护用户位置隐私的效果,但是基于匿名的保护方式匿名参数等级难以设置,而且匿名之后的数据可用性不高;基于加密的位置隐私保护方法通常利用对称加密和非对称加密算法来加密位置数据,从而隐藏位置数据的真实值,但是基于加密的方法往往比较复杂,对通信资源的消耗非常巨大;基于扰动的方法中,以差分隐私保护方法为代表,由于其严谨的数学推理模型,并对攻击者所具有的背景知识没有限制,已经成为位置隐私保护最重要的隐私保护方法。
目前位置差分隐私保护通常利用拉普拉斯噪声机制,对原始位置的经纬度进行小范围的扰动,在保护位置精确经纬度数据的同时,能够提供较高的数据可用性。但位置语义作为位置信息的重要组成部分,往往包含用户的敏感信息(例如,家庭住址、签到地点等),现有位置差分隐私保护方法仅仅保护了位置的经纬度数据,没有保护用户的位置语义,攻击者通过位置语义推断,能够得到用户的位置语义信息。如何在发布用户位置时既能保护用户的空间位置数据,又能保护用户的位置语义是一个亟待解决的问题。
技术实现要素:
有鉴于此,本发明的目的在于提供一种基于差分隐私的个性化位置语义发布方法及系统,首先根据用户的隐私保护需求设置参数为l的语义隐私保护等级,计算出距离待保护语义最近的l-1个位置语义;接着根据用户的语义访问次数计算所有位置的语义敏感度,基于语义敏感度分别得到l个语义的发布概率;最后由特定参数的高斯变量和指数分布变量生成符合特定概率的拉普拉斯变量,即为发布的符合特定语义敏感度的用户位置。
为达到上述目的,本发明提供如下技术方案:
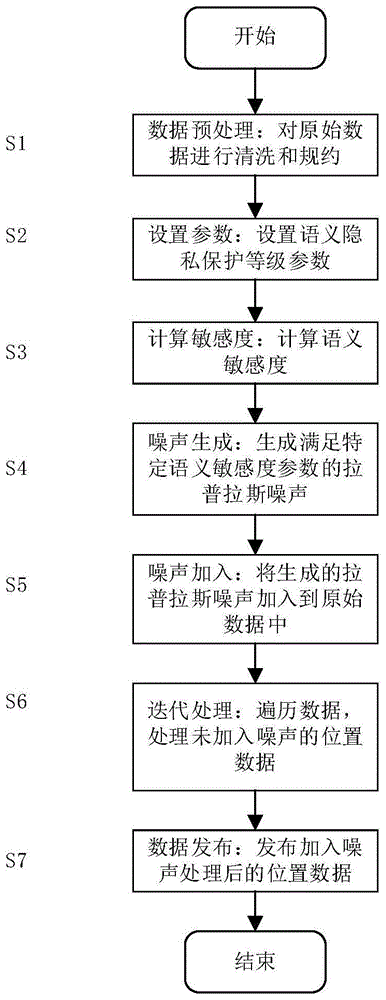
一方面,本发明提供一种基于差分隐私的个性化位置语义发布方法,包括以下步骤:
s1:数据预处理,对原始采集到的位置数据进行数据清洗和规约,得到待保护的位置敏感数据x={x1,...,xi,...,xn},共有n个位置,其中xi表示第i个位置,
s2:根据语义隐私保护需求设置相应的语义隐私保护等级l;
s3:计算语义敏感度;
s4:噪声生成,根据拉普拉斯噪声的生成原理生成符合特定语义敏感度的拉普拉斯噪声;
s5:噪声加入,向位置数据加入所求得的拉普拉斯噪声得到新的位置数据x′lng=xlng+ylng,x′lat=xlat+ylat;
s6:迭代处理,迭代处理每一个位置,重复步骤s2-s5,直到所有位置数据处理完成;
s7:数据发布,对于每个处理之后的位置数据,都有新的经过扰动之后的位置数据与之对应,并且这些位置至少处于l个不同的语义中,从中选取一个位置语义作为用户的位置发布,发布的新位置为x′={x′1,x′2,...,x′i,...,x′n},其中x′i表示加噪声后的第i个位置
进一步,步骤s3具体包括以下步骤:
s31:根据欧式距离计算第i个位置xi最近的l-1个语义,将本身所属的语义和这l-1个语义作为一个语义集合sem(sem1,sem2,...,semi,...,seml),其中
s32:位置语义敏感度计算,计算步骤s3-1得到的l个语义的敏感度
其中,h(semi)表示语义semi被访问的总次数,l表示所有语义被访问的次数之和。
进一步,所述步骤s4具体包括以下步骤:
s41:根据语义敏感度和位置语义范围求出高斯逆累计分布函数标准差σ1,σ2:
其中,μ为0,σ1,σ2即为所求的高斯标准差参数;
s42:根据语义敏感度和位置语义范围求出逆累计指数分布函数生成指数分布所需要的参数λ1,λ2:
s43:根据步骤s41所求得的高斯分布参数,生成高斯分布噪声zlng,zlat;
s44:根据步骤s42所求得的指数分布参数,生成指数分布噪声wlng,wlat;
s45:计算广义拉普拉斯变量
另一方面,本发明提供一种基于差分隐私的个性化位置语义发布系统,包括
数据预处理模块:用于对原始采集到的位置数据进行数据清洗和规约,得到待保护的位置数据x={x1,x2,...,xi,...,xn},其中xi表示第i个位置,
参数设置模块:用于设置语义位置隐私水平保护参数l。
语义敏感度计算模块:用于计算这l个语义的敏感度psem=(psem1,psem2,...,pseml);
噪声生成模块:用于生成符合特定语义敏感度的拉普拉斯噪声;
噪声加入模块:用于向位置数据加入噪声生成模块中第五单元所求得的广义拉普拉斯噪声得到新的位置数据x′lng=xlng+ylng,x′lat=xlat+ylat;
迭代处理模块:用于迭代处理每一个位置,直到所有位置数据更新完成;
数据发布模块:对于每个处理之后的位置数据,都有新的经过扰动之后的位置数据与之对应,并且这些位置至少处于l个不同的语义中,从中选取一个位置语义作为用户的位置发布,发布的新位置为x′={x′1,x′2,...,x′i,...,x′n},其中x′i表示加噪声后的第i个位置
进一步,所述语义敏感度计算模块包括以下子单元:
语义敏感度计算第一单元:根据欧式距离计算第i位置最近的l-1个语义,将本身所属的语义和这l-1个语义作为一个语义集合sem=(sem1,sem2,...,seml),其中
语义敏感度计算第二单元:位置语义敏感度计算,计算这l个语义的敏感度
其中,h(semi)表示语义semi被访问的总次数,l表示所有语义被访问的次数之和。
进一步,所述噪声生成模块包括以下子单元:
噪声生成第一单元,根据语义敏感度和位置语义范围求出高斯逆累计分布函数标准差σ1,σ2,
其中,μ为0,σ1,σ2即为我们所求的参数;
噪声生成第二单元,根据语义敏感度和位置语义范围求出逆累计指数分布函数生成指数分布所需要的参数λ1,λ2;
噪声生成第三单元,根据步骤s4-1所求得的高斯分布参数,生成高斯分布噪声zlng,zlat;
噪声生成第四单元,根据步骤s4-2所求得的指数分布参数,生成指数分布噪声wlng,wlat;
噪声生成第五单元,计算广义拉普拉斯变量
本发明的有益效果在于:本发明可以生成具有特定概率的拉普拉斯噪声,不仅可以保护位置的经纬度数据隐私,而且可以保护用户的位置语义隐私;可以根据用户对不同语义敏感度的隐私保护需求,生成符合特定语义敏感度的噪声,实现对用户位置语义的个性化保护;实施过程和步骤简单易实现,提高了发布数据的可用性并降低了通信资源的消耗,具有重要的市场价值。
本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
附图说明
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作优选的详细描述,其中:
图1是本发明实施例所述基于差分隐私的个性化位置语义发布方法步骤流程图;
图2是本发明实施例提供的总体流程图;
图3是本发明实施例所述的基于差分隐私的个性化位置语义发布系统示意图。
具体实施方式
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
其中,附图仅用于示例性说明,表示的仅是示意图,而非实物图,不能理解为对本发明的限制;为了更好地说明本发明的实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
本发明实施例的附图中相同或相似的标号对应相同或相似的部件;在本发明的描述中,需要理解的是,若有术语“上”、“下”、“左”、“右”、“前”、“后”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此附图中描述位置关系的用语仅用于示例性说明,不能理解为对本发明的限制,对于本领域的普通技术人员而言,可以根据具体情况理解上述术语的具体含义。
请参阅图1~图3,图1和图2分别是实施本发明的总体方法流程图,本发明提供的特定语义敏感度的拉普拉斯噪声生成方法的实施例具体步骤包括:
步骤s1,数据预处理,对原始采集到的位置数据进行数据清洗和规约,得到待保护的位置敏感数据x={x1,...,xi,...,xn},共有n个位置,其中xi表示第i个位置,
实施例中,将签到数据进行清洗和规约得到待保护的签到数据x={x1,x2,...,x1303}。
步骤s2,设置语义隐私保护等级参数,用户根据自身的语义隐私保护需求设置相应的隐私保护等级l。
实施例中,设置语义隐私保护水平参数l=4,具体实施时可有本领域技术人员自行设定语义隐私保护水平参数。
步骤s3,语义敏感度计算,包括以下步骤,
步骤s3-1,根据欧式距离计算第i个位置xi最近的l-1个语义,将本身所属的语义和这l-1个语义作为一个语义集合sem=(sem1,sem2,...,seml),其中
实施例中,取第一个位置点x1={106.61704,29.541919,<新华书店>},根据欧式距离计算第一个位置附近最近的3个语义分别为{<新世纪超市>,<中国移动>,<肯德基>}这四种语义的范围分别为,新华书店的语义范围为{[106.61647,106.61760],[29.541427,29.542410]},新世纪超市的语义范围为{[106.61495,106.616128],[29.541529,29.54255]},中国移动的语义范围为{[106.613461,106.61486],[29.54121,29.5424362]},肯德基的语义范围为{[106.617366,106.61809],[29.54063,29.54126]};
步骤s3-2,位置语义敏感度计算,计算步骤s3-1得到的l个语义的敏感度
其中,h(semi)表示语义semi被访问的总次数,l表示所有语义被访问的次数之和。
实施例中,新华书店语义一共被访问了30次,新世纪超市一共被访问了200,中国移动一共被访问15次,肯德基一共被访问10次得到的位置语义敏感度分别为0.023,0.0075,0.21,0.007;
步骤s4,噪声生成,根据拉普拉斯噪声的生成原理生成符合特定语义敏感度的拉普拉斯噪声,包括以下步骤,
步骤s4-1,根据语义敏感度和位置语义范围求出高斯逆累计分布函数标准差σ1,σ2:
其中,μ为0,σ1,σ2即为所求的高斯标准差参数;
实施例中,根据步骤s3中的语义范围和计算的语义敏感度分别求得4个语义的参数σ1={0.00346,0.0000213,0.000317,0.0000278},σ2={0.00023001,0.000321,0.0000378,0.00001265}
步骤s4-2,根据语义敏感度和位置语义范围求出逆累计指数分布函数生成指数分布所需要的参数λ1,λ2:
实施例,根据步骤s3中的语义范围和计算的语义敏感度分别求得4个语义的参数λ1={0.000075,0.00067,0.0000379,0.0000543},λ2={0.0003954,0.0001534,0.000069023,0.00001357};
步骤s4-3,根据步骤s4-1所求得的高斯分布参数,生成高斯分布噪声zlng,zlat;
实施例,从步骤s4-1所求得的σ1,σ2合集中分别随机选取一个作为高斯分布参数,这里我们从σ1中选取0.000317生成zlng=0.0000131,从σ2中选取0.000321生成zlat=0.000678;
步骤s4-4,根据步骤s4-2所求得的指数分布参数,生成指数分布噪声wlng,wlat;
实施例,从步骤s4-2所求得的λ1,λ2合集中分别随机选取一个作为指数分布参数,这里我们从λ1中选取0.00067生成wlng=0.000362,从σ2中选取0.000354生成wlat=0.000714;
步骤s4-5,计算广义拉普拉斯变量
实施例,根据步骤s4-3和步骤s4-4所求得的zlng,zlat,wlng,wlat得到ylng=0.0002492444,ylat=0.000181166;
步骤s5,噪声加入,向位置数据加入步骤s4-5所求得的广义拉普拉斯噪声得到新的位置数据x′lng=xlng+ylng,x′lat=xlat+ylat。
实施例,向第一个位置数据x1={106.61704,29.541919,<新华书店>}加入步骤s4-5生成的广义拉普拉斯噪声得到新的位置数据得到位置数据x′1={106.6172892444,29.54210016}。
步骤s6,迭代处理,迭代处理每一个位置,重复上述步骤s2-s5,直到所有位置数据处理完成。
实施例,遍历每个位置数据,将1303个位置全部进行上述步骤s2-s5处理,直到所有位置数据处理完成;
步骤s7,数据发布,对于每个处理之后的位置数据,都有新的经过扰动之后的位置数据与之对应,并且这些位置至少处于l个不同的语义中,我们从中选取一个位置语义作为用户的位置发布,发布的新位置为x′={x′1,x′2,...,x′i,...,x′n},其中x′i表示加噪声后的第i个位置,
实施例,x1发布的位置数据为加噪声之后的经纬度数据106.6172892444,29.54210016,语义为新华书店、新世纪超市、中国移动、肯德基中以语义敏感度的大小为概率度量单位选取一个语义发布。
具体实施中,本发明所提供方法可以基于软件技术实现自动运行流程,也可采用模块化方式实现相应系统。
数据预处理模块,用于对原始采集到的位置数据进行数据清洗和规约,得到待保护的位置数据x={x1,x2,...,xi,...,xn},其中xi表示第i个位置,
参数设置模块,用于设置语义位置隐私水平保护参数l。
语义敏感度计算模块,用于计算这l个语义的敏感度psem=(psem1,psem2,...,pseml),包括以下子单元,
第一单元,根据欧式距离计算第i位置最近的l-1个语义,将本身所属的语义和这l-1个语义作为一个语义集合sem=(sem1,sem2,...,semi,...seml),其中
第二单元,位置语义敏感度计算,计算这l个语义的敏感度
其中,h(semi)表示语义semi被访问的总次数,l表示所有语义被访问的次数之和。
噪声生成模块,用于生成符合特定语义敏感度的拉普拉斯噪声,包括以下子单元,
第一单元,根据语义敏感度和位置语义范围求出高斯逆累计分布函数标准差σ1,σ2,
其中,μ为0,σ1,σ2即为我们所求的参数;
第二单元,根据语义敏感度和位置语义范围求出逆累计指数分布函数生成指数分布所需要的参数λ1,λ2;
第三单元,根据步骤s4-1所求得的高斯分布参数,生成高斯分布噪声zlng,zlat;
第四单元,根据步骤s4-2所求得的指数分布参数,生成指数分布噪声wlng,wlat;
第五单元,计算广义拉普拉斯变量
噪声加入模块,用于向位置数据加入噪声生成模块中第五单元所求得的广义拉普拉斯噪声得到新的位置数据x′lng=xlng+ylng,x′lat=xlat+ylat。
迭代处理模块,用于迭代处理每一个位置,重复上述步骤s2-s5,直到所有位置数据更新完成。
数据发布模块,对于每个处理之后的位置数据,都有新的经过扰动之后的位置数据与之对应,并且这些位置至少处于l个不同的语义中,我们从中选取一个位置语义作为用户的位置发布,发布的新位置为x′={x′1,x′2,...,x′i,...,x′n},其中x′i表示加噪声后的第i个位置,
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!