基于注意力的音频和歌词的多模态音乐风格分类方法
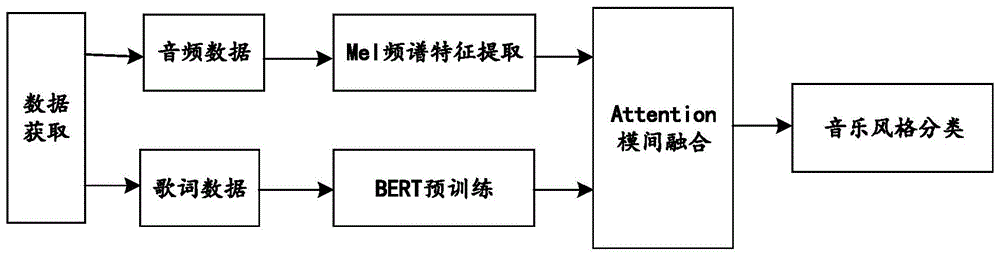
本发明涉及音乐风格分类
技术领域:
,具体地说,涉及一种基于注意力的音频和歌词的多模态音乐风格分类方法。
背景技术:
:音乐风格分类是音乐信息检索和音乐推荐当中的重要一环。随着当今互联网技术和数字多媒体的飞速发展,对音乐风格分类效率的要求也越来越高。但是现在的音乐风格分类技术只用音频特征并不能完整的表示音乐风格,歌词包含的语义信息也部分代表这歌曲的风格,所以还需要将歌词内容考虑进去。而且融合音频和歌词两个方面的信息的技术较少,主要的问题就是对歌词的处理难度较大。一般的歌词处理方法,比如bow(词袋)、word2vec(词向量),都不能获取句子的上下文语义信息。但是对歌词来说,上下文的语义信息对音乐风格具有重要意义。对于音频和歌词融合技术来说,目前使用的是基于简单操作的融合,比如特征级别的拼接和决策级别的加权,这些操作只是相当于对子分类器进行了简单的集成,并没有真正做到音频和歌词信息的融合,对融合结果的提升较小。因此,基于音频和歌词的多模态音乐风格分类技术还有待提升。技术实现要素:本发明的内容是提供一种基于注意力的音频和歌词的多模态音乐风格分类方法,其能够克服现有技术的某种或某些缺陷。根据本发明的一种基于注意力的音频和歌词的多模态音乐风格分类方法,其包括以下步骤:一、数据获取:获取音频和歌词对应的数据集;二、音频预处理:先对音频数据采取mel频谱特征提取,然后经过cnn网络进一步得到音频特征;三、歌词预处理:先进行bert预训练得到单词的词向量,然后经过han网络得到歌词特征向量;四、attention模间融合:通过attention模间融合,将获取的音频和歌词特征,进行交互融合获取融合的attention注意力向量,再与音频和歌词特征向量拼接,获得包含音频和歌词各自模态特征,以及模态间融合特征的音乐风格特征;五、经过softmax层进行分类。作为优选,步骤一中,根据metrolyrics数据集中的歌手和歌名信息,检索并下载对应歌曲,实现批量下载;根据歌曲的编号将相应的歌词数据与歌曲的数据组合在一起,获取音频和歌词对应的数据集。作为优选,步骤二中,mel频谱特征提取的参数如下:音频数据的采样率是22.5hz,对音频信号以12hz进行下采样;帧长21ms;短时傅里叶n_fft=512;帧移hop_len=256;梅尔尺度mel_scale=125;梅尔频谱数n_mels=96;一首歌的音频特征大小是(96,1366)。作为优选,步骤二中,cnn网络结构为:网络有5个3x3核的卷积层和4个池化层,然后接一个全连接层,输出张量维度为64,使每首歌的特征变成一个64维的向量。作为优选,步骤三中,bert预训练模型参数为:uncasedbert-base(12-layer,768-hidden,12-heads);忽略大小写的bert基础模型(12个encoder解码层,768个隐藏层,12个多头注意力);利用bert预训练模型,对输入的歌词文本中每个单词表示成一个768维的向量,把文字符号转换成可供计算机处理的数字,同时还隐含了单词上下文的语义信息。作为优选,步骤三中,han网络参数为:bert词向量维度768维,最大分句数66,分句最大单词数300,bi_gru层数100,attention输出维度200;先对每首歌词文本按句子划分成分句,对分句的每个单词使用bert预训练词向量进行嵌入表示;然后每个分句经过bi_gru层进行wordencoder单词级别编码,计算每个分句wordattention词注意力特征;然后对每首歌词的各个分句经过单词级别的编码后得到的词注意力特征,再经过bi_gru层进行sentenceencoder句子级别的编码,计算每首歌词的sentenceattention句子注意力特征。作为优选,步骤四中,模间注意力计算步骤如下:歌曲用u表示,音频数据用v表示,歌词数据用t表示,d为最后全连接层的维度64,音频的64维向量v(u*d),歌词的64维向量t(u*d);先计算矩阵m1,m2;m1=v.tt&m2=t.vt;(2)使用softmax计算m1,m2的概率分布n1,n2;i表示u的音频第i个样本;j表示u的歌词第j个样本;k表示累加变量,从1到u;(3)模态表示矩阵o1,o2;o1=n1.t&o2=n2.v;(4)注意力矩阵a1,a2;a1=o1⊙v&a2=o2⊙t;(5)模间注意力矩阵bavt;bavt=concat[a1,a2];模间注意力计算先点乘计算矩阵m1、m2;经过softmax得到概率分布n1、n2,表示模态特征的权重系数;再交叉点乘得到新的模态表示矩阵o1、o2;再与原特征逐元素相乘得到注意力矩阵a1、a2;对v、t、a1、a2拼接就是最终的特征向量。本发明利用获取的数据集,对音频和歌词分别进行处理,利用mel_spectrogram(梅尔频谱)对音频数据进行特征提取,使用bert(双向编码表征)预训练模型进行歌词的词向量表征;分别使用cnn(卷积神经网络)和han(层次注意力网络)获取两种模态的特征向量,然后进行特征级别的attention模间融合;最后对融合特征向量进行分类。在传统的基于音频的方法上,添加了利用歌词的信息,再把两种特征信息融合起来。对于歌词来说,歌词以文本作为载体,表达了歌曲的情感、主题、风格等。将音频和歌词作为两种不同模态的数据,信息融合可以将模态之间的交互关系更好的提取出来。不仅提取各自模态的重要信息,还融合模态间的数据关系信息,所以融合特征向量更加有效表征一首歌,也就可以容易对数据进行学习和分类。附图说明图1为实施例1中一种基于注意力的音频和歌词的多模态音乐风格分类方法的流程图;图2为实施例1中音频特征-梅尔频谱示意图;图3为实施例1中处理频谱的cnn网络结构示意图;图4为实施例1中bert预训练词向量示意图;图5为实施例1中han(层次注意力)网络示意图;图6为实施例1中模间注意力计算流程图;图7为attention注意力融合总体网络框图。具体实施方式为进一步了解本发明的内容,结合附图和实施例对本发明作详细描述。应当理解的是,实施例仅仅是对本发明进行解释而并非限定。实施例1如图1所示,本实施例提供了一种基于注意力的音频和歌词的多模态音乐风格分类方法,其包括以下步骤:一、数据获取:获取音频和歌词对应的数据集;多模态音乐风格一个很困难的问题就是获取可用的数据集,关于音乐风格分类的数据集较少。数据来源是metrolyrics(https://www.metrolyrics.com/)一个歌词收集网站上获取的超过380000首歌的歌词,但是还需要获取对应音频。根据metrolyrics数据集中的歌手和歌名信息,检索并下载对应歌曲,实现批量下载。再根据歌曲的编号将相应的音频数据与歌词数据组合在一起,就获取一份音频和歌词对应的数据集。数据集是5个类别,每个类别是1000首。5个类别分别是hip-hop、metal、country、folk、jazz。二、音频预处理:先对音频数据采取mel频谱特征提取,然后经过cnn网络进一步得到音频特征;mel(梅尔)频谱特征提取的参数如下:音频数据的采样率是22.5hz,对音频信号以12hz进行下采样;帧长21ms;短时傅里叶n_fft=512;帧移hop_len=256;梅尔尺度mel_scale=125;梅尔频谱数n_mels=96;一首歌的音频特征大小是(96,1366)。特征提取后得到如图2所示的音频特征-梅尔频谱图,梅尔频谱(mel-spectrogram)图横轴表示时间轴,共30秒;纵轴表示频率轴,单位hz(赫兹);右侧表示能量值,单位db(分贝)。处理频谱的cnn网络结构如图3所示,音频信号使用二维的cnn模型对输入特征进一步提取。网络有5个3x3核的卷积层和4个池化层,然后接一个全连接层,输出张量维度为64,使每首歌的音频特征变成一个64维的向量。图3中:input:输入(这里输入的数据是二维数据-频谱图);output:输出(一维特征向量);frequery:频率轴;time:时间轴;n:网络层数。三、歌词预处理:先进行bert(双向编码表征)预训练得到单词的词向量,然后经过han(层次注意力)网络得到歌词特征向量;bert(双向编码表征)预训练模型比较传统的bow(词袋),可以获取文本的上下文的语义信息,学习句子级别的信息,让提取的特征更具有代表性。同时避免基于统计的方法,只获取词频信息,但是忽略文本语义的误区。han(层次注意力)网络,是为了更好的获取一个句子里各单词之间,一首歌词各句子之间的信息,通过单词和句子两个层次,获取单词前后,句子上下文的隐含信息。bert预训练模型参数:uncasedbert-base(12-layer,768-hidden,12-heads);忽略大小写的bert基础模型(12个encoder解码层,768个隐藏层,12个多头注意力);采用的bert预训练模型的一种,名称uncasedbert-base。利用bert预训练模型,对输入的歌词文本中每个单词表示成一个768维的向量,把文字符号转换成可供计算机处理的数字,同时还隐含了单词上下文的语义信息;之后用bert预训练得到的单词词向量对歌词文本中的单词进行替换,按歌词文本内容嵌入到数据矩阵中,得到歌词文本的数字数据。然后就可以对歌词文本的数据进行一系列的特征提取操作。图4为bert预训练词向量示意图,其中,sentence1:句子1;sentence2:句子2;w1,w2,w3,w4,w5:代表单词;[cls]:bert中用于分类任务的特殊符号;[sep]:bert中表示分句符号,用于断开输入语料的两个句子。对获取的歌词文本数据,经过han进行单词和句子两个层次的信息提取,attention(注意力)机制可以把句子中与音乐风格关系近的部分提取出来,对这部分的特征给予较高的权重,使其突出出来。先对每首歌词文本按句子划分成分句,对分句的每个单词使用bert预训练词向量进行嵌入表示;然后按照图5的网络结构,每个分句经过bi_gru(双向门控记忆网络)层进行wordencoder单词级别编码,计算每个分句wordattention词注意力特征;然后对每首歌词的各个分句经过单词级别的编码后得到的词注意力特征,再经过bi_gru(双向门控记忆网络)层进行sentenceencoder句子级别的编码,计算每首歌词的sentenceattention句子注意力特征。这样就分层次获取了歌词文本的特征,而且对单词前后位置信息,句子的上下文语义信息都有提取。han(层次注意力网络)网络参数为:bert词向量维度768维,最大分句数66,分句最大单词数300,bi_gru层数100,attention输出维度200。图5中,wordencoder:词编码器,单词级别的编码;wordattention:词注意力层,词级别的注意力;sentenceencoder:句子编码器,句子级别的编码;sentenceattention:句子注意力层,句子级别的注意力;softmax:归一化指数函数,作为神经网络的多分类任务中的分类层激活函数;w表示单词,s表示句子,h表示记忆网络隐藏层,v:歌词文本特征向量h1-hl:表示句子级别bi_gru(双向门控记忆网络)的隐藏层,l表示分句数;h21-h2t:表示单词级别bi_gru(双向门控记忆网络)的隐藏层,t表示单词数;箭头向右表示正向,箭头向右表示逆向;us:句子注意力矩阵;α1-αl:句子注意力权重;uw:单词注意力矩阵,α21-α2t:单词注意力权重;s1-sl:歌词文本划分出的各个分句;w21-w2t:分句句子的各单词词向量。四、attention模间融合:通过attention模间融合,将获取的音频和歌词特征,进行交互融合获取融合的attention注意力向量,再与音频和歌词特征向量拼接,获得包含音频和歌词各自模态特征,以及模态间融合特征的音乐风格特征;音频和歌词是两种不同的信息模态,两种模态的数据都包含了音乐的风格信息,所以融合两种信息对音乐风格进行预测会有更好的表现,只利用一种信息是不够的。当下融合方案通常都是直接将获取的音频和歌词特征进行简单的拼接,这种方法只是获取一个拼接向量。没有进行模态间信息的交互融合,对于音频和歌词具有时间上的对应关系,除了获取各自模态的信息,还应考虑两种模态间的交互信息。通过attention模型融合,将获取的音频和歌词特征,进行交互融合获取融合的attention注意力向量,再与音频和歌词特征向量拼接,就可以获得包含音频和歌词各自模态特征,以及模态间融合特征的音乐风格特征。模间注意力计算步骤如下:歌曲用u表示,音频数据用v表示,歌词数据用t表示,d为最后全连接层的维度64,音频的64维向量v(u*d),歌词的64维向量t(u*d);先计算矩阵m1,m2;m1=v.tt&m2=t.vt;(2)使用softmax计算m1,m2的概率分布n1,n2;i表示u的音频第i个样本;j表示u的歌词第j个样本;k表示累加变量,从1到u;(3)模态表示矩阵o1,o2;o1=n1.t&o2=n2.v;(4)注意力矩阵a1,a2;a1=o1⊙v&a2=o2⊙t;(5)模间注意力矩阵bavt;bavt=concat[a1,a2];模间注意力计算流程图如图6所示,模间注意力计算先点乘计算矩阵m1、m2;经过softmax得到概率分布n1、n2,表示模态特征的权重系数;再交叉点乘得到新的模态表示矩阵o1、o2;再与原特征逐元素相乘得到注意力矩阵a1、a2;对v、t、a1、a2拼接就是最终的特征向量。图6中:rowsoftmax:按行计算softmax,得到概率分布结果;notations:符号;matrixmultiplication:矩阵乘法;elemwisemultiplication:逐元素乘法;五、经过softmax层进行分类。图7为attention注意力融合总体网络框图,其中:v表示音频数据,t表示歌词文本;主要对歌词文本做bert预训练,然后利用层次注意力网络提取歌词特征;通过attention模间融合方法,对音频和歌词特征进行融合。mel-spect:梅尔频谱;cnn:卷积神经网络;dense:密集层,一维的隐藏层;bert:词向量预训练模型;han:层次注意力;attention:注意力concat:连接层;softmax:分类层。本实施例利用获取的数据集,对音频和歌词分别进行处理,利用mel_spectrogram(梅尔频谱)对音频数据进行特征提取,使用bert(双向编码表征)预训练模型进行歌词的词向量表征;分别使用cnn(卷积神经网络)和han(层次注意力网络)获取两种模态的特征向量,然后进行特征级别的attention模间融合;最后对融合特征向量进行分类。在传统的基于音频的方法上,添加了利用歌词的信息,再把两种特征信息融合起来。对于歌词来说,歌词以文本作为载体,表达了歌曲的情感、主题、风格等。将音频和歌词作为两种不同模态的数据,信息融合可以将模态之间的交互关系更好的提取出来。不仅提取各自模态的重要信息,还融合模态间的数据关系信息,所以融合特征向量更加有效表征一首歌,也就可以容易对数据进行学习和分类。实验一:将单一音频、单一歌词和attention模间融合三种方式分类结果进行对比。歌曲数据由5种风格,各1000首,共5000条数据;5种风格分别是hip-hop,metal,country,folk,jazz;各分类f1结果对比:表1:四种方式各分类f1结果从上面的表格中,可以看出音频的分类结果78%比歌词的分类结果70%高,因为音频包含的信息比歌词密集,但是歌词信息也是考虑音乐风格的重要部分。融合了音频和歌词的结果比单一的分类结果都要好,无论是拼接的方式,还是attention融合的方式,都表明了融合后的数据确实有利于音乐风格分类任务。从分类的f1结果来看,attention融合的模型在各分类的结果上都得到增强达到84%,而且比简单的拼接操作的结果要高2%,说明attenion融合模型准确提取到了模态间的交互信息,这种融合更有利于音乐的风格分类任务,有效的增强了分类模型的实用性。实验二:实验方案:1:分别对音频和歌词进行单模的分类实验,测试单模的分类效果;2:进行attention注意力融合实验,测试多模融合分类效果;3:对歌词文本进行bow(词袋)和bert(双向编码表征)预训练两种方式进行实验对比;4:对直接拼接和attention注意力融合进行实验对比;5:与现有方案结果对比;表2:各实验f1值结果对比歌词音频拼接attention融合bow_mel64%78%79%81.5%bert_mel70%78%82%84.4%bow_mel:表示歌词采用bow处理,音频采用mel频谱;bert_mel:表示歌词采用bert处理,音频采用mel频谱;从表中可以看到,bert方法处理歌词结果是70%比bow方法高6%;所有attention融合的结果都比直接特征拼接的结果要高,验证了方案的先进性。以上示意性的对本发明及其实施方式进行了描述,该描述没有限制性,附图中所示的也只是本发明的实施方式之一,实际的结构并不局限于此。所以,如果本领域的普通技术人员受其启示,在不脱离本发明创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结构方式及实施例,均应属于本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1