一种基于执行跟踪的微服务提取方法
本发明属于微服务技术领域,尤其是涉及一种基于执行跟踪的微服务提取方法。
背景技术:
近年来,随着微服务的发展,微服务架构已被众多公司采用,以开发应用程序并替代传统的单体应用程序。
基于微服务的系统旨在将一组较小的服务集成到应用程序中。每个服务都在其自己的进程中运行,并且可以独立发展。这些服务通常围绕业务功能构建,并负责其自身的功能。
如公开号为cn111124430a的中国专利文献公开了一种混合架构的微服务部署方法和装置,公开号为cn109947547a的中国专利文献公开了一种基于云计算的微服务构架方法。
相较于单体应用程序,微服务有着许多优势,微服务由协作以实现其目标的服务组成,并通过轻量级机制(例如webapi)进行通信。它是一种创建应用程序的方法,以独立的方式开发,通常可以高效地处理过程和互操作性,并允许连续集成、部署。它还促进了微服务之间的低耦合和高凝聚力。因此,它避免了更改一项微服务以影响另一项微服务,从而最大程度地减少了维护工作。此外,通过使不同的服务具有不同的部署周期,微服务可以独立使用和扩展,从而减少了发布周期。
微服务提取的主要任务是从现有的整体软件中查找哪些软件实体(例如方法,类)应归为一组,作为候选微服务,这些软件实体负责特定功能并独立发展。
现有的微服务提取技术,主要是提供一些微服务提取原则和方法,仍然需要软件架构师或开发人员根据约束去进行手动拆分,虽然这样的方法拆分的更为精准,但是这是一项劳动强度很大的工作,需要花费大量的人力时间。
技术实现要素:
为解决现有技术存在的上述问题,本发明提供了一种基于执行跟踪的微服务提取方法,以方便将传统的单体应用向微服务进行改造升级。
本发明的技术方案如下:
一种基于执行跟踪的微服务提取方法,包括以下步骤:
(1)执行跟踪工具在目标单体应用系统运行时收集跟踪信息,执行路径被记录在日志文件中;
(2)在日记记录中,找到traceid和sessionid都相同的记录归为一类,即一次调用的执行跟踪;其中,sessionid是标记会话的全局唯一id;traceid是标记执行链路的全局唯一id;
(3)根据每一次调用的执行跟踪记录,得到整个执行跟踪记录中的方法调用关系,进一步根据每个方法所属的类,得到类之间的调用关系;
(4)得到了类与类之间的调用后,使用聚类算法进行聚类得到对应的微服务。
优选地,步骤(1)中,所述的跟踪工具为kieker,收集跟踪信息的过程为:首先用kieker将探针插入目标单体应用系统中,使用事先准备好的涵盖所有功能的执行测试用例,在执行完测试用例后,得到执行的跟踪信息。
进一步地,每条日志记录由十个参数组成:type、seqid、method、sessionid、traceid、tin、tout、hostname、eoi和ess;
其中,type表示的是类型,seqid表示序号id,method表示被调用的方法,包括类名、方法名、参数列表和修饰符;sessionid是标记会话的全局唯一id;traceid是标记执行链路的全局唯一id;tin和tout表示调用方法前后的时间戳;hostname表示主机名;eoi和ess是方法调用顺序和调用堆栈的深度。
进一步地,步骤(3)中,得到整个执行跟踪记录中的方法调用关系的方法为:
在每一次调用的执行跟踪记录中,如果essi=essj-1并且eoii<eoij,则得到methodi调用methodj;
其中,essi和essj分别表示第i和第j条记录的调用堆栈深度,eoii和eoij分别表示第i和第j条记录的方法调用顺序,即essi=essj-1并且eoii<eoij的意思是记录i的调用堆栈深度比记录j小一层且记录i调用顺序比记录j早,methodi和methodj分别表示记录i和记录j记录的方法。
进一步地,步骤(3)中,得到类之间的调用关系的方法为:
如果classi!=classj并且methodi调用methodj,则得到classi调用classj;其中,!=表示不等于,methodi和methodj分别表示记录i和记录j记录的方法,classi和classj分别表示methodi和methodj所属的类。
优选地,步骤(4)中,所述的聚类算法采用层次聚类算法,将类i与类j之间的调用次数作为距离dij,计算聚类之间的距离时使用average-linkage,经过层次聚类算法计算后得到类的结果,每一个簇类就是要提取的微服务。
将类i与类j之间的调用次数作为距离dij的公式为:
dij=cntij+cntji
其中,cntij表示类i调用类j的次数,cntji表示类j调用类i的次数。
使用average-linkage的具体过程为:
把两个集合中的点两两的距离全部放在一起求一个平均值,从而分离簇类间有噪声的数据集,公式为:
其中,dismn表示候选簇类m和候选簇类n之间的距离,σdij表示候选簇类m和候选簇类n中的类两两距离之和,sizem和sizen分别表示候选簇类m和候选簇类n所含类的个数,clusterm和clustern分别表示候选簇类m和候选簇类n。
与现有技术相比,本发明具有以下有益效果:
现有的相关微服务提取技术,仍需软件架构师或开发人员根据约束去进行手动拆分,需要花费大量的人力时间,该发明可以明显减少架构师或开发人员进行微服务拆分时的人力时间投入。
附图说明
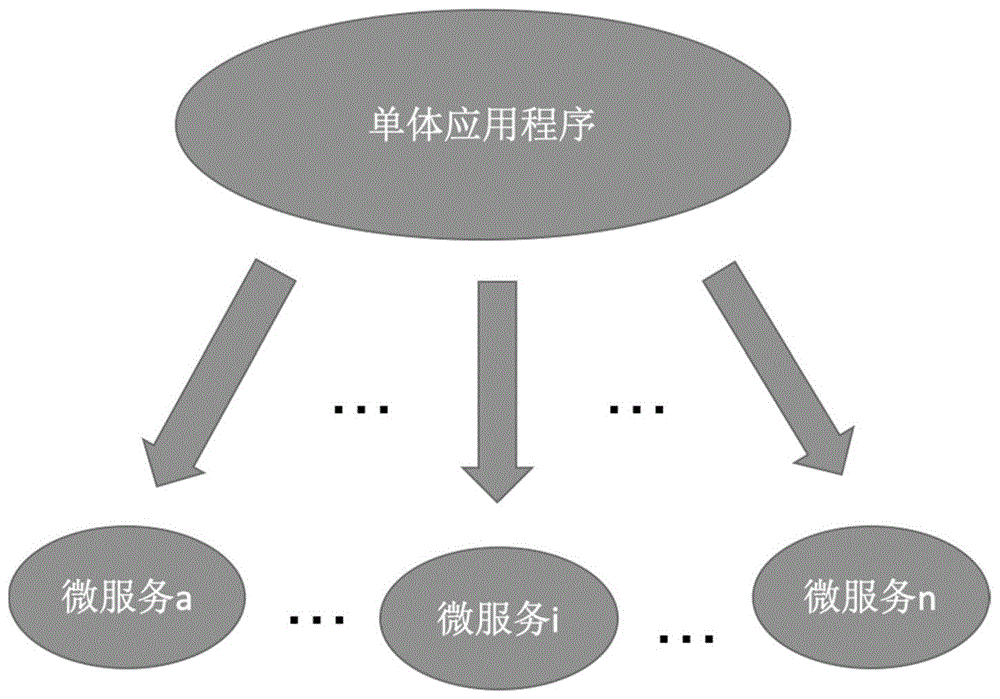
图1为微服务的拆分示意图
图2为本发明实施例使用kieker执行跟踪后根据日志得到类之间调用关系流程图;
图3为本发明实施中采用的层次聚类算法示意图。
具体实施方式
下面结合附图和实施例对本发明做进一步详细描述,需要指出的是,以下所述实施例旨在便于对本发明的理解,而对其不起任何限定作用。
如图1所示,微服务的系统旨在将一组较小的服务集成到应用程序中。本发明的微服务提取方法基于执行跟踪信息来进行提取,采用的执行跟踪信息收集工具是kieker。
首先将kieker将探针插入目标单体应用系统中,使用事先准备好的尽可能涵盖所有功能的执行测试用例,在执行完测试用例后,可以得到执行跟踪信息,执行跟踪信息被记录在日志文件中。
每条日志记录由十个参数组成:type,seqid,method,sessionid,traceid,tin,tout,hostname,eoi和ess。其中method表示被调用的方法,包括类名,方法名,参数列表,修饰符。sessionid是标记会话的全局唯一id。traceid是标记执行链路的全局唯一id。eoi和ess是方法调用顺序和调用堆栈的深度。
在日志记录中,首先聚合traceid和sessionid都相同的记录归为一类,即一次调用的执行跟踪。
在每一次调用的执行跟踪记录中,如果essi=essj-1并且eoii<eoij,即方法调用顺序i在j之前,且他们的调用深度差为1,所以就可以得到methodi调用methodj。
针对每一次调用的执行跟踪记录可以得到该链路中的方法调用关系,同理对所有的调用都分别进行这样的计算就可以得到应用程序中所有方法之间的调用关系。可以根据每个方法所属的类,得到类之间的调用关系,即如果classi!=classj并且methodi调用methodj,那么就可以得到classi调用classj,根据kieker得到执行日志从而得到类之间调用关系的流程图如图2。
得到了类与类之间的调用后,可以使用聚类算法进行聚类得到对应的微服务。本实施例中,聚类算法采用的层次聚类算法,将类i与类j之间的调用次数作为距离dij,包括类i调用类j和类j调用类i即:
dij=cntij+cntji
其中,cntij表示类i调用类j的次数,cntji表示类j调用类i的次数。
计算聚类之间的距离使用的是average-linkage,这种方法是把两个集合中的点两两的距离全部放在一起求一个平均值,该方法可以很好的分离簇类间有噪声的数据集,即:
式中,dismn表示候选簇类m和候选簇类n之间的距离,σdij表示候选簇类m和候选簇类n中的类两两距离之和,sizem和sizen分别表示候选簇类m和候选簇类n所含类的个数,clusterm和clustern分别表示候选簇类m和候选簇类n。
这样经过层次聚类算法计算后就可以得到类的结果,如图3所示。这样每一个簇类就是我们所要提取的微服务。
以上所述的实施例对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的具体实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!