基于源选择的跨项目软件缺陷预测方法
本发明属于软件缺陷预测的技术领域,具体涉及一种基于源选择的跨项目软件缺陷预测方法,主要用于优化源项目选择方面的数据集质量,进一步提高软件缺陷预测结果。
背景技术:
在软件开发快速发展的过程中,开发人员会在开发的过程中无形中产生一些软件错误,这就是软件缺陷。软件缺陷隐患非常大,它不仅会影响用户的使用体验和软件质量,更会危及社会安全,所以我们有必要更早的发现软件中存在的潜在的软件缺陷。
软件缺陷预测可以帮助软件开发者有效的预测软件潜在的缺陷,最近,研究人员已经提出了许多方法,这些方法主要用于提升软件缺陷预测的结果。然而,对于跨项目的软件预测极为困难,主要是由于源项目和目标项目之间数据分布差异较大,导致预测的效果不佳。
技术实现要素:
本发明要解决的技术问题是提供一种基于源选择的跨项目软件缺陷预测方法,提高跨项目软件缺陷预测的准确性,能够有效辅助软件开发人员使用该预测模型来减少软件开发过程中的缺陷,具有较高的精确率和效率。
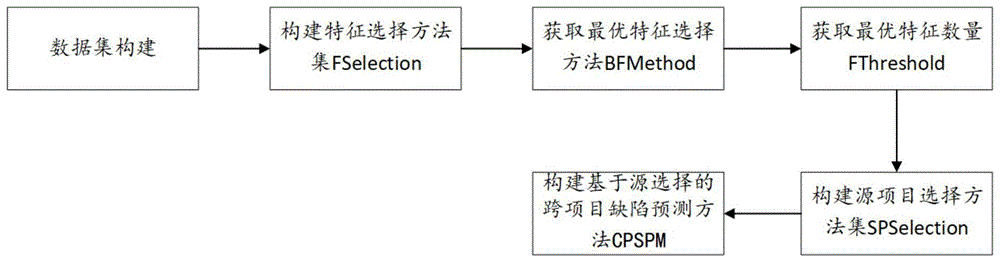
为解决上述技术问题,本发明的实施例提供一种基于源选择的跨项目软件缺陷预测方法,包括如下步骤:
s1、数据集构建;
s2、构建特征选择方法集fselection;
s3、获取最优特征选择方法bfmethod;
s4、获取最优特征数量fthreshold;
s5、构建源项目选择方法集spselection;
s6、构建基于源选择的跨项目缺陷预测方法cpspm。
其中,步骤s1的具体步骤为:
s1.1、基于开源网站获取软件项目集合;
s1.2、以项目类作为实例构建项目实例集合;
s1.3、基于开源数据历史记录、项目源代码语法结构、源代码抽象语法树构建特征集{wmc,dit,noc,cbo,rfc,lcom,lcom3,npm,dam,moa,mfa,cam,ic,cbm,amc,ca,ce,max_cc,avg_cc,loc};
其中,wmc代表每个类的加权方法;dit代表继承树的深度;noc代表子类的数目;cbo代表对象类之间的耦合;rfc代表一个类的响应;lcom和lcom3代表在方法上缺少的凝聚力;npm代表公共类的个数;dam代表数据访问指标;moa代表聚合的量度;mfa代表功能抽象的量度;cam代表类方法之间的聚合;ic代表继承耦合;cbw代表方法之间的耦合;amc代表平均方法复杂度;ca代表传入耦合;ce代表传出耦合;max_cc代表mccabe圈复杂性的最大值;avg_cc代表mccabe圈复杂性的平均值;loc代表代码的行数;
s1.4、基于实例和特征,形成缺陷预测数据集dataset。
其中,步骤s2的具体步骤为:
fselection={rf,cl,gr,ig,or,su};
其中,rf方法通过反复采样一个实例,并将给定属性的值考虑到最近的同一类和不同类的实例中,来评估属性的值,它可以操作离散的和连续的类数据;
cl方法通过测量属性和类之间的相关性来判定属性的价值,名义属性是在一个值的基础上考虑的,将每个值视为一个指标。一个名义属性的整体相关值是通过权重向量平均得到的;
gr方法通过测量一个属性相对于类的增益值评估一个属性的值;
ig方法通过测量一个属性对于一个类的信息增益来评估一个属性的权重;
or方法使用最小误差属性进行预测,可以离散化数值化属性;
su方法通过测量一个属性对于类的对称不确定性来评估一个属性的值。
其中,步骤s3的具体步骤为:
s3.1、构建特征数量集合,初始时,特征数量从α开始,步长为β,选择γ个特征作为特征数量集合{α+β,…α+γ*β},其中,α+γβ等于特征总数20;
s3.2、从集合fselection选择一种特征选择方法fs;
s3.3、从特征数量集合选择一种特征数量fn;
s3.4、基于fs、fn、逻辑回归分类算法,训练数据集dataset,并得出f-measure性能参数;
s3.5、重复步骤s3.3至步骤s3.4,直到所有的特征数量均被选择;
s3.6、重复步骤s3.2至步骤s3.5,直到所有的特征选择方法被选择;
s3.7、通过比较f-measure性能参数得到最优特征选择方法bfmethod。
其中,步骤s4的具体步骤为:
s4.1、构建特征数量集合,初始时,特征数量从α开始,步长为β,选择γ个特征作为特征数量集合{α+β,…α+γ*β},其中,α+γβ等于特征总数20;
s4.2、选择特征选择方法为bfmethod;
s4.3、从特征数量集合选择一种特征数量fn;
s4.4、基于bfmethod、fn、逻辑回归分类算法,训练数据集dataset,并得出f-measure性能参数;
s4.5、重复步骤s4.3至步骤s4.4,直到所有的特征数量均被选择;
s4.6、比较f-measure性能参数,得出最优特征数量fthreshold。
其中,步骤s5的具体步骤为:
s5.1、构建源项目选择方法mean_log:对于给定的源项目集{x1,x2,...,xn},其中i=1,2,...,n,目标项目y,xi′=log(1+xi),y′=log(1+y);mean(xi′)是xi′所有特征度量值的平均值组成的向量;dist(xi′,y′)是xi′和y′之间的欧式距离,如果dist(xj′,y′)是{dist(x1′,y′),dist(x2′,y′),...,dist(xn′,y′)}的最小距离,那么xj就被选择为源项目;
s5.2、构建源项目选择方法std_log:对于给定的源项目集{x1,x2,...,xn},目标项目y,xi′=log(1+xi),y′=log(1+y);std(xi′)是xi′所有特征度量值的标准差组成的向量;dist(xi′,y′)是xi′和y′之间的欧式距离,如果dist(xj′,y′)是{dist(x1′,y′),dist(x2′,y′),...,dist(xn′,y′)}的最小距离,那么xj就被选择为源项目;
s5.3、构建源项目选择方法median_log:对于给定的源项目集{x1,x2,...,xn},目标项目y,xi′=log(1+xi),y′=log(1+y);median(xi′)是xi′所有特征度量值的中位数组成的向量;dist(xi′,y′)是xi′和y′之间的欧式距离,如果dist(xj′,y′)是{dist(x1′,y′),dist(x2′,y′),...,dist(xn′,y′)}的最小距离,那么xj就被选择为源项目;
s5.4、构建源项目选择方法median_zscore:对于给定的源项目集{x1,x2,...,xn},目标项目y,xi′=zscorexi,y′=zscore(y);median(xi′)是xi′所有特征度量值的中位数组成的向量;dist(xi′,y′)是xi′和y′之间的欧式距离,如果dist(xj′,y′)是{dist(x1_,y′),dist(x2′,y′),...,dist(xn′,y′)}的最小距离,那么xj就被选择为源项目;
s5.5、构建源项目选择方法tds:该方法通过数据的分布特征选择数据,提出两种基于相似性作为距离的训练数据选择策略方法(em-clustering,nearestneighborselection);
s5.6、组成源项目选择方法集spselection={mean_log,std_log,median_log,median_zscore,tds}。
其中,步骤s6的具体步骤为:
s6.1、从步骤s5源项目选择方法集spselection中选择一种方法进行测试;
s6.2、在fthreshlod特征个数下,计算源项目和其他项目之间的预测和评估效果;
s6.3、计算同一源项目选择方法下预测结果的平均值;
s6.4、重复步骤s6.1到步骤s6.3,直到所有源项目选择方法测试完毕;
s6.5、比较预测结果的平均值,得出最优源项目选择方法;
s6.6、得到跨项目缺陷预测方法cpspm。
在软件预测的研究中,广泛的使用f-measure指标来衡量特征方法的效率。而这个指标都使用到了precision和recall两个参数。
precision表示的是实例被正确划分为clean的个数占所有实例的百分比。其中tp表示将有缺陷模块预测为有缺陷模块的个数、tn表示将无缺陷模块预测为无缺陷模块的个数、fp表示将无缺陷模块预测为有缺陷模块的个数、fn表示将有缺陷模块预测为无缺陷模块的个数。
recall表示的是实例被正确划分为缺陷模块的个数占所有缺陷模块的百分比。该值越高,表明模型能正确识别缺陷的概率越大,能够识别更多的缺陷模块。
accuracy表示的正确划分的模块个数占所有模块个数的比例,比例越高说明模型分类的准确度越高,反之准确度越低。
f-measure是p和crr两种测量参数的复合方法。值越高,那么该方法就表现的越好。
f-measure的值在0~1之间,值越高表明模型性能越好。
本发明的上述技术方案的有益效果如下:
本发明提供的基于源选择的跨项目软件缺陷预测方法,提出多种源项目选择方法,并结合相应的特征选择方法对源项目进行选择,通过该方法选择出高质量的源项目,这有助于极大提高软件缺陷预测效果。
附图说明
图1为本发明的方法流程图;
图2为本发明中构建特征选择方法集和源项目选择方法图;
图3为本发明中六种特征选择方法得到的f-measure图;
图4为本发明中不同特征值下使用rf方法得到的结果图;
图5为本发明中使用不同源项目选择技术得到的accuracy图;
图6为本发明中使用不同源项目选择技术得到的f-measure图。
具体实施方式
为使本发明要解决的技术问题、技术方案和优点更加清楚,下面将结合附图及具体实施例进行详细描述。
如图1所示,本发明提供一种基于源选择的跨项目软件缺陷预测方法,主要用于优化软件缺陷性能,包括如下步骤:
s1、数据集构建;
s2、构建特征选择方法集fselection;
s3、获取最优特征选择方法bfmethod;
s4、获取最优特征数量fthreshold;
s5、构建源项目选择方法集spselection;
s6、构建基于源选择的跨项目缺陷预测方法cpspm。
步骤s1、数据集构建具体步骤如下:
以promise数据集为例,从promise数据集中选取项目进行测试,数据集主要包含数据集名称、缺陷模块个数、模块的总个数、模块特征的个数、错误实例所占总实例数的百分比等几个方面的内容。
步骤s2、构建特征选择方法集fselection具体步骤如下:
fselection={rf,cl,gr,ig,or,su}。
rf方法通过反复采样一个实例,并将给定属性的值考虑到最近的同一类和不同类的实例中,来评估属性的值。它可以操作离散的和连续的类数据;
cl方法通过测量属性和类之间的相关性来判定属性的价值。名义属性是在一个值的基础上考虑的,将每个值视为一个指标。一个名义属性的整体相关值是通过权重向量平均得到的;
gr方法通过测量一个属性相对于类的增益值评估一个属性的值;
ig方法通过测量一个属性对于一个类的信息增益来评估一个属性的权重;
or方法使用最小误差属性进行预测,可以离散化数值化属性;
su方法通过测量一个属性对于类的对称不确定性来评估一个属性的值。
构建过程如图2所示。
步骤s3、获取最优特征选择方法bfmethod具体步骤如下:
在同样的特征数目范围下,对六种方法分别进行效果测试,测试的结果如图3所示。从图可以看出,当特征数目较少的情况下,六种方法的表现效果差异较大,而当特征数目大于14的时候,六种方法的表现效果接近一致。
基于上面的六种特征选择方法的效果评估,本发明最终使用rf方法作为特征选择方法。
步骤s4、获取最优特征数量fthreshold具体步骤如下:
初始时,特征数量从1开始,步长为1,选择1个特征作为特征数量集合{α+β,...α+γ*β},其中,α+γβ等于特征总数20。
从集合fselection选择一种特征选择方法fs,同时从特征数量集合中选择一种特征数量fn,基于fs、fn和逻辑回归分类算法,训练数据集并得到accuracy和f-measure值。从如图4可以看出,f-measure值随着特征值的增加而增加,最终接近于0.3;从特征值为2开始,accuracy的值也随着特征值的增加而增加,最终在0.6上下浮动。
步骤s5、构建源项目选择方法集spselection具体步骤如下:
s5.1、构建源项目选择方法mean_log:对于给定的源项目集{x1,x2,...,xn},其中i=1,2,...,n,目标项目y,xi=log(1+xi),y=log(1+y)。mean(xi)是xi所有特征度量值的平均值组成的向量。dist(xi′,y′)是xi′和y′之间的欧式距离,如果dist(xj′,y′)是{dist(x1′,y′),dist(x2′,y′),...,dist(xn′,y′)}的最小距离,那么xj就被选择为源项目。
s5.2、构建源项目选择方法std_log:对于给定的源项目集{x1,x2,...,xn},目标项目y,xi=log(1+xi),y=log(1+y)。std(xi)是xi所有特征度量值的标准差组成的向量。dist(xi′,y′)是xi′和y′之间的欧式距离,如果dist(xj′,y′)是{dist(x1′,y′),dist(x2′,y′),..,dist(xn′,y′)}的最小距离,那么xj就被选择为源项目。
s5.3、构建源项目选择方法median_log:对于给定的源项目集{x1,x2,...,xn},目标项目y,xi=log(1+xi),y=log(1+y)。median(xi)是xi′所有特征度量值的中位数组成的向量。dist(xi′,y′)是xi′和y′之间的欧式距离,如果dist(xj′,y′)是{dist(x1′,y′),dist(x2′,y′),...,dist(xn′,y′)}的最小距离,那么xj就被选择为源项目。
s5.4、构建源项目选择方法median_zscore:对于给定的源项目集{x1,x2,...,xn},目标项目y,xi=zscorexi,y=zscore(y)。median(xi)是xi′所有特征度量值的中位数组成的向量。dist(xi,y)是xi和y之间的欧式距离,如果dist(xj′,y′)是{dist(x1′,y′),dist(x2′,y′),...,dist(xn′,y′)}的最小距离,那么xj就被选择为源项目。
s5.5、构建源项目选择方法tds:该方法通过数据的分布特征选择数据,提出两种基于相似性作为距离的训练数据选择策略方法(em-clustering,nearestneighborselection)。
s5.6、组成源项目选择方法集spselection={mean_log,std_log,median_log,median_zscore,tds}。
s6、构建基于源选择的跨项目缺陷预测方法cpspm具体步骤如下:
使用这四种源项目选择方法得到的accuracy指标如图5所示,同时结合tds方法进行效果对比。从该图可以看出,当特征值数目很少的情况下,基于tds、std_log和median_log方法得到的accuracy值均小于没有采用选择技术的值;当特征数目逐渐增加时,这四种方法得到的accuracy值趋向于稳定,与没有使用选择技术的值相差不大。
使用这四种源项目选择方法得到的f-measure指标如图6所示,当特征值小于9时,只有median_log方法得到的值大于没有采用选择技术的方法;在特征值逐渐增加的情况下,tds方法得到的值是逐渐增加的,当特征值为9是,得到的f-measure值首次高于没有采用选择技术的方法。当特征值为20时,除了median_zscore方法,其余方法得到的f-measure均高于没有使用选择技术的值,但特征值在6到12之间时,median_zscore表现优于其他方法。
本发明共提出了四种不同的源项目选择方法,首先,采用六种特征选择方法,得到效果较好的rf特征选择方法;使用该方法进行下一步源项目选择操作,在本步骤下,分别使用accuracy和f-measure指标进行对方法评估。从得出的结果来看,两者指标均随着特征值数量的增加而增加,当特征值为20时,除了median_zscore方法其余方法均优于没有使用选择技术方法,但从本实验看来,该方法仍然是最好的源项目选择方法。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明所述原理的前提下,还可以作出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!