一种基于自适应知识迁移的多任务演化算法
本发明属于演化计算中的多任务优化方法技术领域,具体涉及一种基于自适应知识迁移的多任务演化算法。
背景技术:
在处理科学研究、工程技术、经济管理等领域中的复杂问题时,不难发现,许多问题之间存在一定程度的相似性,传统的演化算法只能解决单个优化问题,并不能动态的交互多个不同的优化问题之间的有效信息,因此忽略多个任务之间有用信息的挖掘。
多任务进化算法(multi-taskingevolutionaryalgorithm,mtea)也称多因子进化算法(multi-factorialoptimizationalgorithm,mfea)的提出使得演化算法能够跨域解决多个不同的优化任务。mtea受多因子遗传模型的启发,自然界生物的许多特征并不是直接由单一遗传基因决定,而是由多个遗传基因控制且受到文化基因的影响。mtea融合了基因和文化之间协调进化的概念。多重任务相当于多基因环境,在同一时间优化多个任务时,任务可以利用不同基因进化的相似性来学习有效的信息,从相似任务的学习经验中提取的知识可以建设性地应用于更复杂或看不见的任务。与传统的进化算法相比mtea具有显著优势,它通过建立一个统一的搜索空间同时优化多个跨域任务,在统一搜索空间中不同任务的信息可以进行迁移。目标任务在优化过程中利用其他任务的学习经验加速自身优化进程,使得多个优化任务均以较快的速度得到其最优解。mtea的一般表达式如下式所示:
{x1,x2,x3,...xk}=argmin{f1(x)f2(x)f3(x),...fk(x)}
其中k表示优化任务的数量,fi(x)为第i个任务,xi为对应的最优解,i∈[1,k]。
2016年,新加坡南洋理工大学ong教授首次提出mtea,用于处理跨域的多任务优化问题。目前,mtea对算法主要研究方向可分为两种类别,分别是mtea的理论研究、mtea与其他传统进化算法的融合和改进。mtea的理论研究主要是对mtea的工作机理进行探究,从理论层面论证mtea的可行性。lian等人提出了一个简单的mtea来同时优化基准jumpk和leadingones函数。理论分析表明,在leadingones函数的预期运行时间的上限没有增加时,jumpk函数期望运行时间的上限相比于单任务得到显著提高。这一结果表mtea可以解决传统优化方法难以优化的问题。gupta等人以求解数独问题(sudokupuzzles)为例,验证了基因迁移和种群多样性在多任务环境中的相互关系。尽管基因迁移和种群多样性在mtea算法中具有同等重要的作用,但对于具有较强互补性的多任务,基因迁移对于种群快速收敛的影响更为显著。这些研究成果表明了mtea的算法理论可行性。
mtea可以和其他经典的进化算法融合,利用其进化算子的优势提升算法的优化性能。feng等人将经典的差分进化算法(differentialevolution,de)和粒子群优化算法(particleswarmoptimization,pso)与mfea相结合提出了mfde和mfpso算法,其优化性能较优于原始的de和pso算法。cheng从子种群的角度结合pso算法进行多任务演化,当优化陷入停滞阶段时产生新的子代,并对全局最优个体进行拉马克学习(lamarckianlearning)。同时,他还在在mfde的基础上进行了延伸,使得mfde可以自适应的调整知识在不同任务之间的迁移方式,tang等人提出了一中自适应多因子粒子群优化算法,可以自适应调整任务之间的学习概率。cai提出了一种用于多任务差分进化的差分向量共享机制(dvsm),其目的是在不同任务之间捕获、共享和利用有用的知识,提高知识迁移效率。zhou等人根据子代的提升率自适应的选择mtea的交叉算子提升了mtea的优化性能。feng提出了一种具有跨任务显式遗传传递的emt算法,它允许在emt范式中包含具有不同偏差的多个搜索机制。
mtea也成功的解决了现实世界中的工程实践。cheng等人认为合作协同进化的机制适用于在单个多任务环境中利用不同(但可能相关)优化任务之间的共性或互补性,并通过基于协同进化算法的框架进一步强调跨问题多任务处理的有效性,利用该算法有效解决了复杂工程设计工程实例问题。在模糊关联挖掘的隶属度函数优化中,相比传统分别优化的方式,mtea优化过程中发挥了其知识共享的优势。ding等人对现有的mtea进行了推广,提出了两种策略,一种用于决策变量转换,另一种用于决策变量洗牌,以促进具有不同位置的优化问题之间的知识转移,有效的解决昂贵优化问题。同时,mtea还可以用来解决光伏模型的参数优化问题和车辆路径规划问题。除此之外,多任务优化算法也很好的解决了云计算中大规模虚拟机布局的优化问题和选矿工艺中操作指标的优化问题。
mtea算法目前在理论研究和算法性能改进都有所建树,但仍存在许多不足之处,面临着多方面的挑战,主要总结为以下两个方面。
(1)在解决现实应用场景中的技术问题时,不能实时的反映优化任务之间的先关程度,导致效率低下。任务之间知识迁移时具有负面效应。多任务环境中的任务存在一定程度的相似性或者互补性,mtea借助任务之间的特性将有利的信息在这些任务之间进行迁移,加快优化多个任务的收敛性。但在任务优化过程中,每个阶段任务之间会出现不相似或者不互补的现象,多任务算法不能很好自适应去发现这一问题,导致会出现负向迁移的情况,使得任务的优化方向发生转换,从而影响任务优化的性能,问题的解决效率低下。
(2)mtea算法自身的效率和适应性有待提高。多项优化任务同时进行,进化算法的效率和适应性对于算法的应用价值显得尤为关键。传统的mtea算法只是在交叉、变异、选择等进化算子的基础上,添加了选型交配和垂直文化传播等操作,算法效率并不高效。因此,在研究任务特征的基础上,基于种群分布特征设计新的编解码方案、高效的进化算子,以实现种群多样性的主动控制和种群搜索方向的自适应调整,是当前需要解决的一个关键问题。
技术实现要素:
本发明的目的在于提供一种基于自适应知识迁移的多任务演化算法,相较现有的mfde和mfea更能够有效地解决多任务优化问题。
本发明所采用的技术方案是:一种基于自适应知识迁移的多任务演化算法,包括以下步骤:
步骤1、种群初始化:在统一搜索空间随机生成n个个体作为初始化种群p,p={y1,y2,y3,...yn},学习期初始化为75代,任务间的交配概率rmp初始化为0.3,根据每个优化任务评估每个个体,并计算个体的标量适应度值
其中,个体的标量适应度值
步骤2、评估任务间相关程度:使用公式(2)跨任务适应度距离相关度ctfdc来计算任务之间的相关程度;t1、t2分别表示任务1和任务2,n为t1任务上采样个体的数量,f1为采样个体在t1任务上评估的适应度值向量,其中
步骤3、更新rmp:根据步骤2中的相关程度重新计算rmp,若任务之间为负相关,rmp设置为0,否则将ctfdc所反映的任务之间的相似程度通过fm(s)映射重新作为rmp的值,fm(s)函数由公式(3)所示,a1、b1由区间[0,1]和[0.3,1]根据如公式(4)所示的区间映射关系计算得到,[nmax,nmin]为目标区间,[omax,omin]原始区间,ox,y为原始区间内任意一点;
rmp=fm(s)=a1·s+b1(3)
步骤4、变异:在满足rand(0,1)<rmp,任务之间进行信息迁移并采用公式(5)来更新子代,其中,
步骤5、交叉:对变异产生的个体进行交叉操作;
步骤6、评估:采用垂直文化传播机制来评估子代,当子代通过知识迁移产生时,子代携带了多个不同任务的信息,其父代拥有不同的技能因子,子代的技能因子以相同的概率随机继承父代的技能因子,当子代的产生不涉及多个任务之间的信息迁移时,子代直接继承父代的技能因子,子代直接在技能因子所表示的任务上进行评估;
步骤7、合并更新:将父代种群和子代种群进行合并,并更新合并种群个体的标量适应度值和技能因子;
步骤8、选择:将合并种群中个体根据标量适应度值进行排序,选出前n个较优的个体组成下一代种群;
步骤9、判断是否满足终止条件,若不满足终止条件,返回步骤2。
本发明的特点还在于,
步骤1具体为:在搜索空间中随机生成n个个体作为初始种群,p={y1,y2,...,yn},初始个体维度为max{di},i∈[1,k],k为多任务的总个数,学习期初始化为75代,rmp初始化为0.3,根据每个优化任务评估每个个体,并计算个体的标量适应度值
步骤1.1、随机键解码计算目标值:将初始化种群中的随机键值,按照xi=li+(ui-li)×yi映射到某个实际优化任务的搜索空间,其中l、u分别为实际优化任务的上下界,然后计算每一个个体在每一个任务上的目标值;
步骤1.2、初始种群排序:针对不同优化问题,根据目标值依次对种群排序,得到k个排序集合{set1,set2,...setk},seti为种群n个个体根据其在第k个任务上目标值的排序集合;
步骤1.3、个体评价:依据步骤1.2中种群排序结果,计算个体的标量适应度值和技能因子。
步骤1.3具体包括以下步骤:
步骤1.3.1、计算个体的标量适应度值
步骤1.3.2、计算个体的因子排名
步骤1.3.3、计算个体的技能因子τi:个体的技能因子表示个体具有优势的任务,
步骤2具体为:使用公式(2)跨任务适应度距离相关度
步骤2.1、计算采样个体的在目标任务上的适应度值向量:f1为采样个体在t1任务上评估的适应度值向量,其中
步骤2.2、计算采样个体与在源任务上表现最好的个体之间距离向量:d2是采样个体在t1任务上评估的适应度值最好的个体xbest和所有采样个体之间的距离组成的向量,其中
步骤2.3、计算t1、t2之间的相似度:如公式(2)所示,
步骤5具体为:对变异产生的个体进行交叉操作,具体操作如公式(7)所示,xi,j表示第i个体的第j维,vi,j为xi,j变异得到的个体维度值,randn为[0,1]之间的随机数,cr为交叉概率,jrand为[1,...,d]的随机整数,d为统一搜索空间的维度。
本发明的有益效果是:本发明一种基于自适应知识迁移的多任务演化算法,先通过跨任务适应度距离相关度来衡量任务之间的相关程度,然后根据相关程度来动态的调整不同任务之间知识迁移的概率,可以动态的反映任务之间的可利用的信息状态,增加了任务之间的正向知识迁移概率;本发明所提出的akt_mfde比现有的mfde和mfea更能够有效地解决多任务优化问题。
附图说明
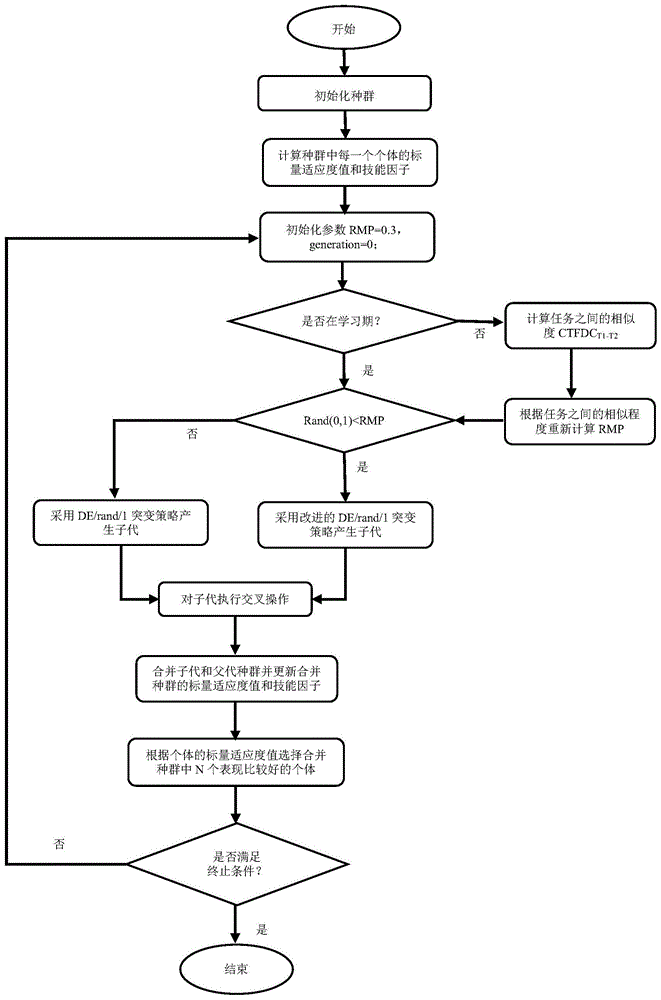
图1是本发明一种基于自适应知识迁移的多任务演化算法akt_mfde的流程图;
图2是akt_mfde和mfde在ci+ls任务组t1(task1)的收敛曲线;
图3是akt_mfde和mfde在ci+ls任务组t2(task2)的收敛曲线;
图4是akt_mfde和mfde在mi+ls任务组t1(task2)的收敛曲线;
图5是akt_mfde和mfde在mi+ls任务组t2(task2)的收敛曲线;
图6是akt_mfde和mfde在ni+ls任务组t1(task1)的收敛曲线;
图7是akt_mfde和mfde在ni+ls任务组t2(task2)的收敛曲线。
具体实施方式
下面结合附图以及具体实施方式对本发明进行详细说明。
本发明提供了一种基于自适应知识迁移的多任务演化算法,如图1所示,包括以下步骤:
step1:种群初始化与评估:在搜索空间中随机生成n个个体作为初始种群,p={y1,y2,...,yn},初始个体维度为max{di},i∈[1,k],k为多任务的总个数,学习期初始化为75代,rmp初始化为0.3,根据每个优化任务评估每个个体,并计算个体的标量适应度值
1.1:随机键解码计算目标值:将初始化种群中的随机键值,按照xi=li+(ui-li)×yi映射到某个实际优化任务的搜索空间,其中l、u分别为实际优化任务的上下界,然后计算每一个个体在每一个任务上的目标值。
1.2:初始种群排序:针对不同优化问题,根据目标值依次对种群排序,得到k个排序集合{set1,set2,...setk},seti为种群n个个体根据其在第k个任务上目标值的排序集合。
1.3:个体评价:依据步骤1.2中种群排序结果,计算个体的标量适应度值和技能因子。
1.3.1:计算个体的标量适应度值
1.3.2:计算个体的因子排名
1.3.3:计算个体的技能因子τi:个体的技能因子表示个体具有优势的任务,
step2:评估任务间相关程度:当算法演化超过学习期,使用(2)式跨任务适应度距离相关度
2.1:计算采样个体的在目标任务上的适应度值向量:f1为采样个体在t1任务上评估的适应度值向量,其中
2.2:计算采样个体与在源任务上表现最好的个体之间距离向量:d2是采样个体在t1任务上评估的适应度值最好的个体xbest和所有采样个体之间的距离组成的向量,其中
2.3:计算t1、t2之间的相似度:如下(2)所示,
step3:更新rmp:根据步骤2中的相关程度重新计算rmp,a1、b1由区间[0,1]和[0.3,1]根据如(4)式所示的区间映射关系计算得到,[nmax,nmin]为目标区间,[omax,omin]原始区间,ox,y为原始区间内任意一点。
step4:变异:在满足rand(0,1)<rmp,任务之间进行信息迁移并采用下式(5)来更新子代,其中,
在满足rand(0,1)>rmp使用下式(6)de/rand/1并更新子代个体的技能因子,
step5:交叉:对变异产生的个体进行交叉操作,具体操作如下式(7)所示,xi,j表示第i个体的第j维,vi,j为xi,j变异得到的个体维度值,randn为[0,1]之间的随机数,cr为交叉概率,jrand为[1,...,d]的随机整数,d为统一搜索空间的维度。
step6:评估:采用垂直文化传播机制来评估子代,当子代通过知识迁移产生时,子代携带了多个不同任务的信息,其父代拥有不同的技能因子,子代的技能因子以相同的概率随机继承父代的技能因子,当子代的产生不涉及多个任务之间的信息迁移时,子代直接继承父代的技能因子,子代直接在技能因子所表示的任务上进行评估。
step7:合并更新:将父代种群和子代种群进行合并,并更新合并种群个体的标量适应度值和技能因子。
step8:选择:将合并种群中个体根据标量适应度值进行排序,选出前n个较优的个体组成下一代种群。
step9:判断是否满足终止条件,若不满足终止条件,返回step2。
本发明的效果通过以下的仿真实验进一步说明。基准测试函数具体如表1所示,其中第三列是变量的取值范围、问题的最优解、问题的最优值。这7个基准问题的最优值都为0,所以优化的值越小,表示算法的优化性能越好。表2为以基准测试函数所构建的多任务优化问题组。其中相交程度表示两个任务之间全局最优解的相交程度,ci(completelyintersection)、pi(partialintersection)、ni(nointersection)分别表示完全相交、部分相交、不相交。任务之间的相似性采用斯皮尔曼相关系数(spearman’srank)计算,spearman’srank是由问题上的采样点之间的分布特性来估计不同任务之间的相似程度,具体表示如下:
r(x1),r(x2)为采样个体在不同问题上根据适应度值的排序,cov(x)为协方差计算表达式,std(x)为标准差计算表达式。hs、ms、ls、分别表示高度相似(highsimilarity)、中度相似(middlesimilarity)、低度相似(lowsimilarity)。分别将不同相交程度的问题和相似度不同的问题组合在一起模拟九组不同的多任务优化环境,具体如图表2所示。
表1具体的测试函数集
表2进化多任务优化问题的性质总结
为证明自适应迁移策略(akt)的有效性,本发明首先将提出来的自适应的迁移策略与原始的多任务算法mfea_alpha和mfea_beta结合,验证了自适应知识迁移策略的普适性,本发明将mfea_alpha和akt_mfea_alpha、mfea_beta和akt_mfea_beta分别运行20次,然后将20次运行的均值和标准差整理得到表3,括号内为标准差,最优的均值使用黑体加粗,由表3数据可以得到:添加了自适应知识迁移策略的多任务基准算法比原始的算法表现更好,akt_mfea_alpha在14个实例上都优于mfea_alphaakt_mfea_beta在12个实例上都优于mfea_beta,表明自适应知识迁移策略对于可以普遍有效增加多任务环境中的正向知识迁移。
表3自适应知识迁移策略的普适性探究
为了更好的说明本发明的效果,按照图1所示流程进行试验仿真,并将akt_mfde与mfea_alpha、mfea_beta、mfpso、mfde这四种基准算法进行比较,这五种算法20次独立运行的结果如表4所示,最优结果采样黑体加粗。由表4分析得出,本发明提出的算法在18个实例中,共有12个优于mfea_alpha、mfea_beta、mfpso、mfde,进一步说明了发明所提出的算法的有效性。
表4五种算法在多任务基准问题上运行20的实验结果
为了直观的说明本发明所提出来的akt_mfde算法在增加正向迁移的优势,本发明将原始的mfde与akt_mfde在相似度比较低的多任组中优化过程进行了比较。如图2至图7分别为mfde与akt_mfde在相似度比较低的多任组中的收敛曲线,可以看出akt_mfde在处理不相似的多个任务时可以有效提高的收敛性。
- 还没有人留言评论。精彩留言会获得点赞!