利用DialoGPT作为特征标注器的对话摘要生成系统
本发明涉及自然语言处理领域,具体涉及对话摘要生成系统。
背景技术:
对话摘要旨在为一段对话生成简要的概述。[1](题目:semanticsimilarityappliedtospokendialoguesummarization,作者:irynagurevych和michaelstrube,年份:2004年,文献引自proceedingsofthe20thinternationalconferenceoncomputationallinguistics)。从理论上讲,peyrard[2](题目:asimpletheoreticalmodelofimportanceforsummarization,作者:maximepeyrard,年份:2019年,文献引自proceedingsofthe57thannualmeetingoftheassociationforcomputationallinguistics)指出,摘要的评价与三个方面有关,包括信息量,冗余性和相关性。一个好的摘要应该包含多的信息量,低的冗余性和高的相关性。针对上述三个方面,之前的工作利用“辅助标注”的方式来帮助模型理解对话。为了提高信息量,一些工作在对话中标注对话关键词,例如一些特定单词(名词和动词),领域术语和主题词。为了降低冗余性,一些工作使用了基于句子相似度的方法来标注冗余句。为了提高摘要与对话相关性,一些工作为对话标注主题信息,使得生成的摘要与原对话主题一致。但是,这些额外的标注通常需要耗时耗力的人工标注或者通过不适用于对话的开放域工具包获得的。
技术实现要素:
本发明是为了解决现有对话摘要生成方法人工向对话中加入标注,以及通过不适用于对话的开放域工具包获得标注,标注不准确,导致对话摘要获取耗时耗力,效率差,准确率低的问题,而提出利用dialogpt作为特征标注器的对话摘要生成系统。
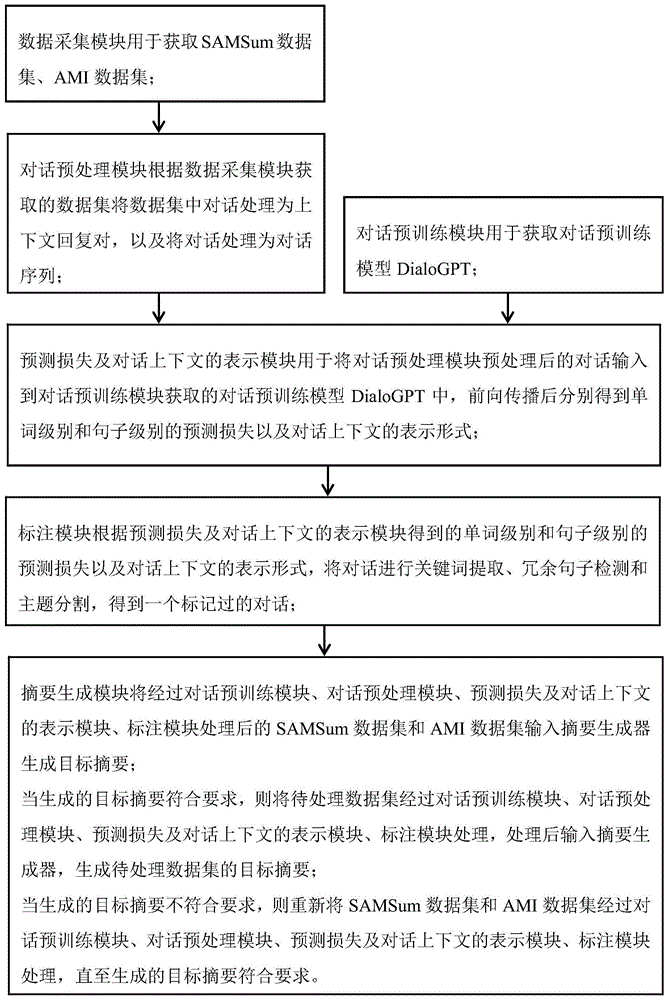
利用dialogpt作为特征标注器的对话摘要生成系统包括:
数据采集模块、对话预训练模块、对话预处理模块、预测损失及对话上下文的表示模块、标注模块、摘要生成模块;
所述数据采集模块用于获取samsum数据集、ami数据集;
所述对话预训练模块用于获取对话预训练模型dialogpt;
所述对话预处理模块根据数据采集模块获取的数据集将数据集中对话处理为上下文回复对,以及将对话处理为对话序列;
所述预测损失及对话上下文的表示模块用于将对话预处理模块处理后的对话输入到对话预训练模块获取的对话预训练模型dialogpt中,前向传播后分别得到单词级别和句子级别的预测损失以及对话上下文的表示形式;
所述标注模块根据预测损失及对话上下文的表示模块得到的单词级别和句子级别的预测损失以及对话上下文的表示形式,将对话进行关键词提取、冗余句子检测和主题分割,得到一个标记过的对话;
所述摘要生成模块将经过对话预训练模块、对话预处理模块、预测损失及对话上下文的表示模块、标注模块处理后的samsum数据集和ami数据集输入摘要生成器生成目标摘要;
当生成的目标摘要都符合要求,则将待处理数据集经过对话预训练模块、对话预处理模块、预测损失及对话上下文的表示模块、标注模块处理,处理后输入摘要生成器,生成待处理数据集的目标摘要;
当生成的目标摘要不符合要求,则重新将samsum数据集和ami数据集经过对话预训练模块、对话预处理模块、预测损失及对话上下文的表示模块、标注模块处理,直至生成的目标摘要符合要求。
本发明的有益效果为:
本发明获取samsum数据集、ami数据集和对话预训练模型dialogpt;将数据集中对话处理为上下文回复对,以及将对话处理为对话序列;将处理后的对话输入到对话预训练模型dialogpt中,前向传播后分别得到单词级别和句子级别的预测损失以及对话上下文的表示形式;将对话进行关键词提取、冗余句子检测和主题分割,得到一个标记过的对话;将经过处理后的samsum数据集和ami数据集输入摘要生成器生成目标摘要;对话摘要获取快速,效率高,准确率高,解决现有对话摘要生成方法人工向对话中加入标注,以及通过不适用于对话的开放域工具包获得标注,标注不准确,导致对话摘要获取耗时耗力,效率差,准确率低的问题。
本发明将预训练语言模型作为一种对话特征标注器来自动为对话提供标注。具体而言,本发明使用dialogpt[3](题目:dialogpt:largescalegenerativepre-trainingforconversationalresponsegeneration,作者:yizhezhang,siqisun,michelgalley,yen-chunchen,chrisbrockett,xianggao,jianfenggao,jingjingliu,和billdolan,年份:2020年,文献引自proceedingsofthe58thannualmeetingoftheassociationforcomputationallinguistics:systemdemonstrations),一种在对话领域的对话回复预训练模型,给对话提供关键词抽取,冗余句检测和主题分割三种标注。
本发明提出了dialogpt特征标注器,该标注器可以执行三类对话标注任务,包括关键词抽取,冗余句检测和主题分割。关键词抽取旨在自动识别对话中的关键单词。本发明综合考虑dialogpt中编码的背景知识和对话上下文信息,如果dialogpt很难预测(根据步骤五一一预测损失,损失较大的难以预测)某一个词语,则该词语包含更高的信息量。本发明的dialogpt特征标注器将该词语作为关键词。冗余句检测旨在检测对于对话的整体含义没有核心贡献的冗余话语;如果添加新的语句不会更改对话上下文的语义,则新加入的语句是多余的。本发明的dialogpt特征标注器将对于对话上下文表示无用的语句检测为冗余句。主题分割旨在将对话分为多个主题讨论片段;如果dialogpt很难根据对话上下文推断出下一句回复,则该回复属于一个新主题。本发明的dialogpt特征标注器会在一个难以预测(根据步骤五三预测损失,损失较大的难以预测)的句子之前插入主题分割点。
本发明使用dialogpt标注器来标注samsum[4]和ami[5]数据集。然后,本发明采用预训练模型bart[6](题目:bart:denoisingsequence-to-sequencepretrainingfornaturallanguagegeneration,translation,andcomprehension,作者:mikelewis,yinhanliu,namangoyal,marjanghazvininejad,abdelrahmanmohamed,omerlevy,veselinstoyanov,和lukezettlemoyer.,年份:2020年,文献引自proceedingsofthe58thannualmeetingoftheassociationforcomputationallinguistics)和非预训练模型pgn[7](题目:gettothepoint:summarizationwithpointergeneratornetworks,作者:abigailsee,peterj.liu,andchristopherd.manning,年份:2017年,文献引自proceedingsofthe55thannualmeetingoftheassociationforcomputationallinguistics)分别作为samsum和ami的摘要生成器。大量的实验结果表明,在两个数据集上,本发明方法都可以获得一致且显著的改进,并在samsum数据集上获得了世界最优的性能。
附图说明
图1为本发明流程图。
具体实施方式
具体实施方式一:本实施方式利用dialogpt作为特征标注器的对话摘要生成系统包括:
数据采集模块、对话预训练模块、对话预处理模块、预测损失及对话上下文的表示模块、标注模块、摘要生成模块;
所述数据采集模块用于获取samsum数据集、ami数据集;
所述对话预训练模块用于获取对话预训练模型dialogpt;
所述对话预处理模块根据数据采集模块获取的数据集将数据集中对话处理为上下文回复对,以及将对话处理为对话序列;
所述预测损失及对话上下文的表示模块用于将对话预处理模块处理后的对话输入到对话预训练模块获取的对话预训练模型dialogpt中,前向传播后分别得到单词级别和句子级别的预测损失以及对话上下文的表示形式;
所述标注模块根据预测损失及对话上下文的表示模块得到的单词级别和句子级别的预测损失以及对话上下文的表示形式,将对话进行关键词提取、冗余句子检测和主题分割,得到一个标记过的对话;
所述摘要生成模块将经过对话预训练模块、对话预处理模块、预测损失及对话上下文的表示模块、标注模块处理后的samsum数据集和ami数据集输入摘要生成器生成目标摘要;
当生成的目标摘要都符合要求,则将待处理数据集经过对话预训练模块、对话预处理模块、预测损失及对话上下文的表示模块、标注模块处理,处理后输入摘要生成器,生成待处理数据集的目标摘要;
当生成的目标摘要不符合要求,则重新将samsum数据集和ami数据集经过对话预训练模块、对话预处理模块、预测损失及对话上下文的表示模块、标注模块处理,直至生成的目标摘要符合要求(重新执行上述过程)。
具体实施方式二:本实施方式与具体实施方式一不同的是,所述数据采集模块用于获取samsum数据集、ami数据集;具体过程为:
在samsum和ami两个数据集上进行实验;
samsum是人为产生的对话摘要数据集,其中包含现实生活中各种场景中的对话;
ami是会议摘要数据集,每个会议包含四个参与者,围绕远程控制设计展开会议讨论;
samsum数据集从https://arxiv.org/abs/1911.12237获取;
ami数据集从https://groups.inf.ed.ac.uk/ami/corpus/获取。
samsum[4](题目:ahuman-annotateddialoguedatasetforabstractivesummarization,作者:bogdangliwa,iwonamochol,maciejbiesek,和aleksanderwawer,年份:2019年,文献引自proceedingsofthe2ndworkshoponnewfrontiersinsummarization);
ami[5](题目:theamimeetingcorpus:apre-announcement,作者:jeancarletta,simoneashby,sebastienbourban,mikeflynn,maelguillemot,thomashain,jaroslavkadlec,vasiliskaraiskos,wesselkraaij,melissakronenthal,年份:2005年,文献引自internationalworkshoponmachinelearningformultimodalinteraction)。
其它步骤及参数与具体实施方式一相同。
具体实施方式三:本实施方式与具体实施方式一或二不同的是,所述samsum数据集和ami数据集中的对话形式化为:
每一段对话d包含|d|个句子[u1,u2,...,ui,...,u|d|];
每一个句子
其中i∈[1,2,3,…,|d|],eosi代表该句的结束符号,ui,1代表第i个句子的第一个词语,以此类推;
对于每一个对话d有一个对应的摘要s=[s1,s2,...,s|s|],s1代表摘要s中第一个词语,s|s|代表摘要s中第|s|个词语;
在一段对话中,每个句子ui都对应一个说话人pi;
因此最终对话d=]p1,u1,1,...,eos1,...,p|d|,u|d|,1,...,eos|d|]。
其它步骤及参数与具体实施方式一或二相同。
具体实施方式四:本实施方式与具体实施方式一至三之一不同的是,所述对话预训练模块用于获取对话预训练模型dialogpt;具体过程为:
对话预训练模型dialogpt是一种预训练对话回复生成模型,对话预训练模型dialogpt获取的链接为:
https://huggingface.co/transformers/model_doc/dialogpt.html?highlight=dialogpt;
利用reddit评论链中的对话数据对dialogpt进行训练,得到训练好的对话预训练模型dialogpt。(后面涉及的对话预训练模型dialogpt都是训练好的对话预训练模型dialogpt)
在各种对话生成任务中,它可以实现当下最优结果。
所述训练好的对话预训练模型dialogpt的输入为samsum数据集或ami数据集中给定的句子
对话预训练模型dialogpt将句子ui-1的词序列表示为:
其中,
其它步骤及参数与具体实施方式一至三之一相同。
具体实施方式五:本实施方式与具体实施方式一至四之一不同的是,所述对话预处理模块根据数据采集模块获取的数据集将数据集中对话处理为上下文回复对,以及将对话处理为对话序列;
将对话d=[p1,u1,1,...,eos1,...,p|d|,u|d|,1,...,eos|d|]转换为dialogpt可以处理的格式;对于给定的对话,本发明将其预处理为两种格式:上下文回复对和对话序列;
具体过程为:
步骤三一、将对话d=[p1,u1,1,...,eos1,...,p|d|,u|d|,1,...,eos|d|]处理为上下文回复对;具体为:
给定一个对话d=[p1,u1,1,...,eos1,...,p|d|,u|d|,1,...,eos|d|],两个相邻的句子(ui-1,ui)被组合成一个上下文回复对,其中i∈[2,3,…,|d|];
步骤三二、将对话d=[p1,u1,1,...,eos1,...,p|d|,u|d|,1,...,eos|d|]处理为对话序列;具体为:
将对话d=[p1,u1,1,...,eos1,...,p|d|,u|d|,1,...,eos|d|]中的所有对话都序列化为对话序列d=[u1,1,...,eos1,...,u|d|,1,...,eos|d|]。
其它步骤及参数与具体实施方式一至四之一相同。
具体实施方式六:本实施方式与具体实施方式一至五之一不同的是,所述预测损失及对话上下文的表示模块用于将对话预处理模块处理后的对话输入到对话预训练模块获取的对话预训练模型dialogpt中,前向传播后分别得到单词级别和句子级别的预测损失以及对话上下文的表示形式;具体过程为:
步骤四一、对于步骤三一的每个上下文回复对,获得单词级别和句子级别的预测损失;过程为:
给定一个标准上下文回复对(ui-1,ui)(samsum数据集和ami数据集中上下文回复对),
其中i∈[2,3,…,|d|];
将句子ui-1输入到对话预训练模块获取的对话预训练模型dialogpt中,计算dialogpt模型输出的预测概率分布与给定的标准(samsum数据集或ami数据集中已知的对话输入dialogpt模型输出给定的标准摘要,这里将samsum数据集或ami数据集中已知的对话中的句子ui-1输入dialogpt模型输出给定的标准回复)回复ui之间的负对数似然:
lossi,t=-logp(ui,t|ui,<t,ui-1)
其中ui,<t代表已经预测出来的部分词语序列;ui,t代表当前要预测的词语;lossi,t代表每个词语ui,t的预测损失;lossi代表每个句子ui的预测损失;t代表第t个解码步骤;
步骤四二、基于步骤三二的对话序列,获取对话上下文的表示形式;具体过程为:
利用对话预训练模块获取的对话预训练模型dialogpt模型对对话序列d=[u1,1,...,eos1,...,u|d|,1,...,eos|d|]进行一次前向传递之后,获得每个词语的表示形式h;
然后,基于每个词语的表示形式h获取对话上下文的表示形式(提取每个eos的表示);
其中,
对话预训练模型dialogpt将句子ui-1的词序列表示为:
其中,
其它步骤及参数与具体实施方式一至五之一相同。
具体实施方式七:本实施方式与具体实施方式一至六之一不同的是,所述标注模块根据预测损失及对话上下文的表示模块得到的单词级别和句子级别的预测损失以及对话上下文的表示形式,将对话进行关键词提取、冗余句子检测和主题分割,得到一个标记过的对话;具体过程为:
步骤五一、关键词提取:
步骤五一一、给定一个对话d,根据步骤四一每个单词ui,t都有预测损失lossi,t;按照百分比rke提取lossi,t较高的单词作为关键字;
步骤五一二、将对话中提到的所有说话人p的姓名添加到关键字集中;
步骤五一三、基于步骤五一二,在步骤五一一给定对话d的末尾附加一个特定的标记#key#,得到带有关键字注释的新对话dke;
带有关键字注释的新对话dke为:
其中key1为抽取出来的第一个关键词,key2为抽取出来的第二个关键词,以此类推;
步骤五二、冗余句检测:
dialogpt继承了一种解码器体系结构,在该体系结构中,一个词语的表示会融合在其之前出现的所有词语的表示。因此,给定每个eosi的表示
从最后的两个对话上下文表示开始,即
在每个冗余的句子之前插入一个特定的标签[rd];
例如,若句子u1是冗余的,则带有冗余话语注释的新对话
步骤五三、主题分割:
dialogpt擅长生成上下文一致的回复;因此,如果基于dialogpt在给定上下文的情况下很难预测下一句回复,则本发明认为在上下文和回复之间存在一个主题分割。
给定一个对话d,根据步骤四一每个句子ui都有预测损失lossi,按照百分比rts提取lossi较高的句子作为预测的回复,并在选定的句子之前插入主题分割点[ts];
例如,如果在句子u2之前有一个主题分割点,则带有主题标注的新对话为
其它步骤及参数与具体实施方式一至六之一相同。
具体实施方式八:本实施方式与具体实施方式一至七之一不同的是,所述步骤五一一中rke值的确定过程为:本发明使用启发式规则来预先确定rke的值:
给定samsum数据集的训练集或ami数据集的训练集,计算训练集中删除停用词后所有摘要的长度(摘要中词的个数)除以训练集中所有对话的长度(对话中词的个数),得到rke。
其它步骤及参数与具体实施方式一至七之一相同。
具体实施方式九:本实施方式与具体实施方式一至八之一不同的是,所述步骤五三中rts值的确定过程为:本发明使用启发式规则来预先确定rts的值:
给定samsum数据集的训练集或ami数据集的训练集,计算训练集中删除停用词后所有摘要的长度(摘要中词的个数)除以训练集中所有对话的长度(对话中词的个数),得到rts。
其它步骤及参数与具体实施方式一至八之一相同。
具体实施方式十:本实施方式与具体实施方式一至九之一不同的是,所述摘要生成模块将经过对话预训练模块、对话预处理模块、预测损失及对话上下文的表示模块、标注模块处理后的samsum数据集和ami数据集输入摘要生成器生成目标摘要;
当生成的目标摘要都符合要求,则将待处理数据集经过对话预训练模块、对话预处理模块、预测损失及对话上下文的表示模块、标注模块处理,处理后输入摘要生成器,生成待处理数据集的目标摘要;
当生成的目标摘要不符合要求,则重新将samsum数据集和ami数据集经过对话预训练模块、对话预处理模块、预测损失及对话上下文的表示模块、标注模块处理,直至生成的目标摘要符合要求;
具体过程为:
本发明使用两种摘要生成器:
一种是bart[8](题目:bart:denoisingsequence-to-sequencepretrainingfornaturallanguagegeneration,translation,andcomprehension,作者:mikelewis,yinhanliu,namangoyal,marjanghazvininejad,abdelrahmanmohamed,omerlevy,veselinstoyanov,和lukezettlemoyer.,年份:2020年,文献引自proceedingsofthe58thannualmeetingoftheassociationforcomputationallinguistics),这是一种基于transformer的预训练模型;
另一个是pgn[9](题目:gettothepoint:summarizationwithpointergeneratornetworks,作者:abigailsee,peterj.liu,andchristopherd.manning,年份:2017年,文献引自proceedingsofthe55thannualmeetingoftheassociationforcomputationallinguistics),这是一个基于lstm的模型;
将经过对话预训练模块、对话预处理模块、预测损失及对话上下文的表示模块、标注模块处理后的samsum数据集输入bart摘要生成器,生成目标摘要;
bart采用了transformer[10](题目:attentionisallyouneed,作者:ashishvaswani,noamshazeer,nikiparmar,jakobuszkoreit,llionjones,aidann.gomez,lukaszkaiser,和illiapolosukhin,年份:2017年,文献引自advancesinneuralinformationprocessingsystems30:annualconferenceonneuralinformationprocessingsystems2017)作为基础架构;它首先将对话d映射到分布式表示形式,然后解码器将根据这些表示形式生成目标摘要;
将经过对话预训练模块、对话预处理模块、预测损失及对话上下文的表示模块、标注模块处理后的ami数据集输入pgn摘要生成器,生成目标摘要。
pgn基于序列到序列模型seq2seq[11](题目:abstractivetextsummarizationusingsequence-to-sequencernnsandbeyond,作者:rameshnallapati,bowenzhou,cicerodossantos,
当生成的两个目标摘要都符合要求,则将待处理数据集经过对话预训练模块、对话预处理模块、预测损失及对话上下文的表示模块、标注模块处理,处理后输入bart摘要生成器或pgn摘要生成器,生成待处理数据集的目标摘要。
当生成的两个目标摘要不符合要求,则重新将samsum数据集和ami数据集经过对话预训练模块、对话预处理模块、预测损失及对话上下文的表示模块、标注模块处理,直至生成的两个目标摘要都符合要求;
其它步骤及参数与具体实施方式一至九之一相同。
采用以下实施例验证本发明的有益效果:
实施例一:
本发明对提出的模型进行了实现,同时和目前的基线模型和标准摘要进行了对比。
基线模型一:bart
基线模型二:mv-bart[13](题目:multi-viewsequence-to-sequencemodelswithconversationalstructureforabstractivedialoguesummarization,作者:jiaaochen和diyiyang,年份:2020年,文献引自proceedingsofthe2020conferenceonempiricalmethodsinnaturallanguageprocessing)是一种基于bart的方法,其中包含主题和阶段信息。
(1)基线模型一生成的摘要:
robiswatchingthegame.bobishavingafewpeopleover.jim'sbirthdayisnextwednesday.heisgoingforaskiingtripwithhisfamily.hemightorganizeameetupwithafewfriendsatsomebarthisweekend.robwillletbobknowifhecancome.bobhasn'tseenjiminpersonforawhile.
罗布在看比赛。鲍勃有几个人了。吉姆的生日是下个星期三。他准备和家人一起滑雪。这个周末他可能会和一些朋友在一些酒吧举行聚会。rob将让bob知道他是否可以来。鲍勃已经有一段时间没有亲自见过吉姆了。
(2)基线模型二生成的摘要:
bobandrobarewatchingthegame.jimisgoingforaskiingtripwithhisfamilynextweekend.hemightorganizeameetupwithafewfriendsatsomebarthisweekend.bobwilllethimknowifhewantstocome.bobhasn'tseenjiminpersonforawhile.
鲍勃和罗布正在观看比赛。吉姆下个周末要和家人一起去滑雪。这个周末他可能会和一些朋友在一些酒吧举行聚会。鲍勃会告诉他是否要来。鲍勃已经有一段时间没有亲自见过吉姆了。
(3)本发明模型生成的摘要:
robandbobarewatchingthegame.jimisgoingforaskiingtripwithhisfamilynextweekend.hemightorganizeameetupwithafewfriendsatsomebarthisweekend.robwilllethimknowifhecancome
罗布和鲍勃正在观看比赛。吉姆下个周末要和家人一起去滑雪。这个周末他可能会和一些朋友在一些酒吧举行聚会。罗布会告诉他是否可以来。
(4)标准摘要:
robandbobarewatchingthegame.bobwillrunsomeerrandsontheweekend.jim'sbirthdayisnextwednesday.hemightorganizeameetupthisweekend.bobwillseerobontheweekend.
罗布和鲍勃正在观看比赛。鲍勃周末要出差。吉姆的生日是下周三。他可能在这个周末组织一次聚会。鲍勃周末会见罗布。
根据以上实施例可以看出,本发明的模型可以生成与标准摘要更加相似的结果,通过基于预训练模型dialogpt向对话中加入标注的方法,可以更好的理解对话信息。
本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,本领域技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!