一种基于增量式宽度学习系统模型的负荷预测方法
本发明属于负荷预测领域,提出了一种人工智能方法,适用于对综合能源系统负荷预测。
背景技术:
电力负荷预测是综合能源系统优化调度中的一项重要工作。因为电能无法大量存储,所以电力的生产与消费需要在一定的时间范围保持平衡。电能对各个行业起着至关重要的作用,所以提高负荷预测的准确性,有利于电网安全稳定的运行,减少经济成本。一般来说,历史用电量和天气的变化都会影响负荷预测的准确性,而且随着电力市场的发展,电力负荷会出现新的特点,这就需要不断地对已有的预测模型进行优化从而达到满意的预测效果。
近年来,宽度学习系统被提出来用于各种预测问题中,并表现出了高精确性。与深度学习相比,宽度学习系统结构简单运算速度也更快。增量学习能保存之前的学习结果,并在此基础上学习新数据集中的新内容。当一个系统训练好时,对该系统进行修改的代价通常低于重新训练一个系统所需的代价。本发明提出一种基于增量式宽度学习系统模型来预测综合能源系统中的电力负荷,该模型结构简单并且训练速度快。当输入新数据集时,模型保留旧数据集学到的知识,并通过新数据集更新所学到的内容。本发明将增量学习的思想运用到宽度学习系统中,保存以前由旧数据集训练的模型的相关权重用于新数据集预测,如果新旧数据集数据相差较大,也无需重新训练,对由旧数据集训练的模型产生的权重的基础上稍作调整得到满意的训练结果。
技术实现要素:
本发明提出一种基于增量式宽度学习系统模型的负荷预测方法。该方法将增量学习的思想用于宽度学习系统中,能够提高负荷预测的准确性和模型训练的效率;所提方法在使用过程中的主要步骤为:
步骤1:生成特征节点,设输入因素的数据集x,其中特征数为1,共有l个数据,对x进行标准化并增加一项偏置项,数据集x的维数为l×2,共有m个特征窗口,每个窗口都生成n个特征节点
zm=x×wem,m=1,2,...,m(1)
其中wem为产生的2×n随机权重矩阵,zm为生成的第m个特征窗口,z=[z1,z2...,zm],z的维数为l×(n×m)。
步骤2:对z进行归一化和稀疏表示。
步骤3:对特征节点矩阵z进行标准化得到z′,生成p个增强窗口,假设n×m>p,则由公式(2)生成增强节点矩阵h′
h′=z′×wh(2)
与特征节点不同,增强节点矩阵的权重矩阵wh不是随机矩阵而是经过正交规范化后的随机权重矩阵,wh的维数为(n×m)×p。
步骤4:用公式(3)对增强节点矩阵进行激活,激活后的增强节点矩阵为
其中s为增强节点的缩放尺度,max(h′)表示返回h′中的最大元素值,tansig()是常用的一种激活函数。
步骤5:形成网络的输入矩阵a=[zh]。
步骤6:由公式(4)求伪逆矩阵
w=(at×a+c×i)-1(at×y)(4)
其中at为a的转置,c为常数,i为单位矩阵,y为训练集的输出数据。
步骤7:将每个因素单独进行训练,假设所有相关性大于0.6的因素的个数为k,则把这k个因素组合起来作为输入矩阵,按上述步骤1至步骤6形成新的预测模型。
步骤8:输入新数据集,若新数据集与旧数据集的数据相关性大于0.6,则直接输入训练好的模型进行训练。输入新数据集,若新数据集与旧数据集的数据相相关性不大于0.6,则对训练好的模型的权重wem、wh和w进行更新,更新方法是:加上一个随机的范围为(0,0.01]权重矩阵调整,直到输出负荷预测准确率达到98%为止。
本发明相对于现有技术具有如下的优点及效果:
(1)本发明通过对能考虑到的每个因素都进行了筛选,提取相关性较高的所有因素,得到最佳数据集,并把这些因素组合重新训练了模型,提高了预测的准确性。
(2)本发明将增量学习的思想用于宽度学习系统中,最终形成的模型结构简单并且训练速度快,当输入新数据集时,模型保留旧数据集学到的知识,并通过新数据集更新所学到的内容。
附图说明
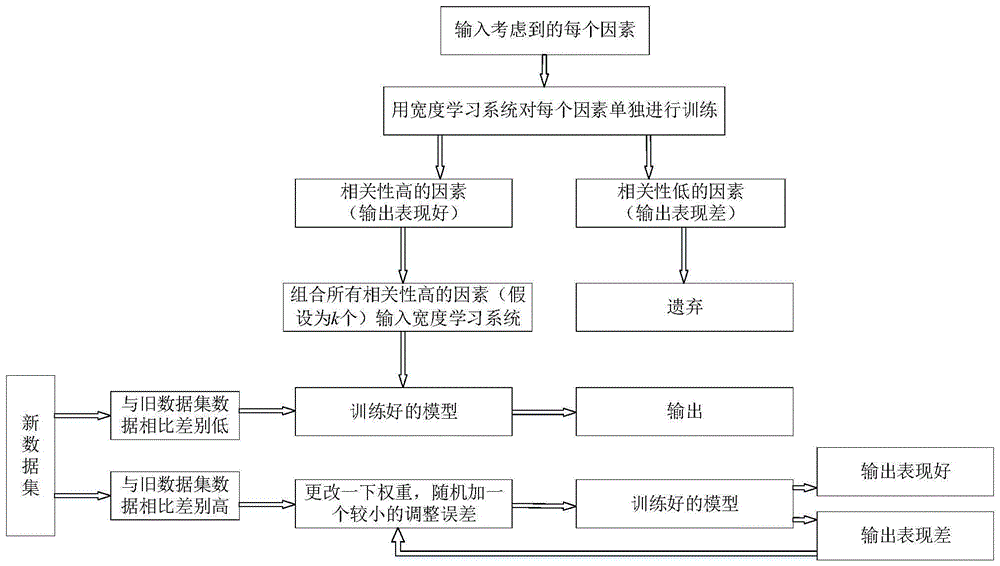
图1是本发明所提基于增量式宽度学习系统模型的负荷预测方法流程图。
图2是本发明方法模型训练过程的结构图。
具体实施方式
本发明提出一种基于增量式宽度学习系统模型的负荷预测方法,结合附图详细说明如下:
图1是本发明所提基于增量式宽度学习系统模型的负荷预测方法流程图。首先,把能考虑到的每一个因素单独输入所提方法中的宽度学习系统进行训练,假设得到k个相关性较高的因素。然后,把这k个相关性高的因素组合起来输入所提方法中的宽度学习系统进行训练,得到一个训练好的所提方法中的宽度学习系统模型。最后,输入新数据集与旧数据集比较,如果新旧数据集数据相差不大,则将新数据集输入训练好的模型直接预测,如果新旧数据集数据相差较大,则更新权重,直到输出达到满意的结果为止。
图2是本发明方法模型训练过程的结构图。首先,输入数据集x,通过相关函数形成特征节点。然后,通过形成的特征节点生成增强节点。最终特征节点和增强节点共同组合成训练模型的输入并乘以计算出的权重得到输出结果。
技术特征:
1.一种基于增量式宽度学习系统模型的负荷预测方法,其特征在于,该方法将增量学习的思想用于宽度学习系统中,能够提高负荷预测的准确性和模型训练的效率;所提方法在使用过程中的主要步骤为:
步骤1:生成特征节点,设输入因素的数据集x,其中特征数为1,共有l个数据,对x进行标准化并增加一项偏置项,数据集x的维数为l×2,共有m个特征窗口,每个窗口都生成n个特征节点
zm=x×wem,m=1,2,...,m(1)
其中wem为产生的2×n随机权重矩阵,zm为生成的第m个特征窗口,z=[z1,z2...,zm],z的维数为l×(n×m);
步骤2:对z进行归一化和稀疏表示;
步骤3:对特征节点矩阵z进行标准化得到z′,生成p个增强窗口,假设n×m>p,则由公式(2)生成增强节点矩阵h′
h′=z′×wh(2)
与特征节点不同,增强节点矩阵的权重矩阵wh是经过正交规范化后的随机权重矩阵,wh的维数为(n×m)×p;
步骤4:用公式(3)对增强节点矩阵进行激活,激活后的增强节点矩阵为
其中s为增强节点的缩放尺度,max(h′)表示返回h′中的最大元素值,tansig()是常用的一种激活函数;
步骤5:形成网络的输入矩阵a=[zh];
步骤6:由公式(4)求伪逆矩阵
w=(at×a+c×i)-1(at×y)(4)
其中at为a的转置,c为常数,i为单位矩阵,y为训练集的输出数据;
步骤7:将每个因素单独进行训练,假设所有相关性大于0.6的因素的个数为k,则把这k个因素组合起来作为输入矩阵,按上述步骤1至步骤6形成新的预测模型;
步骤8:输入新数据集,若新数据集与旧数据集的数据相关性大于0.6,则直接输入训练好的模型进行训练;输入新数据集,若新数据集与旧数据集的数据相相关性不大于0.6,则对训练好的模型的权重wem、wh和w进行更新,更新方法是:加上一个随机的范围为(0,0.01]权重矩阵调整,直到输出负荷预测准确率达到98%为止。
技术总结
本发明提出一种基于增量式宽度学习系统模型的负荷预测方法。该方法将增量学习的思想用于宽度学习系统中,目的是提高负荷预测的准确性和模型训练的效率。首先,把能考虑到的每一个因素单独输入所提方法中的宽度学习系统进行训练,得到相关性较高的因素。然后,把这些相关性高的因素组合起来输入到所提方法中的宽度学习系统进行训练,得到一个训练好的所提方法中的宽度学习系统模型。最后,输入新数据集与旧数据集比较,如果新旧数据集数据相差不大,则将新数据集输入训练好的模型直接预测,如果新旧数据集数据相差较大,则更新权重,直到输出达到满意的结果为止。
技术研发人员:殷林飞;陶敏;韦潇莹;高放
受保护的技术使用者:广西大学
技术研发日:2021.05.14
技术公布日:2021.08.03
- 还没有人留言评论。精彩留言会获得点赞!