一种基于句法树匹配的智能合约相似性检测方法
本发明属于程序相似性检测技术领域,具体涉及一种基于句法树匹配的智能合约相似性检测方法。
背景技术:
近年来,为了提高软件开发效率,越来越多的研发人员开始利用代码复用技术,例如复用现有的程序代码、复用通用的软件框架、复用常见的设计模式等。然而,盲目地复用现有的程序代码可能会造成很多问题,例如项目额外成本提高、软件易存在漏洞风险、容易侵犯软件著作权。
代码相似性检测是检查代码复用的有效技术之一,也称为代码克隆检测,能够判断两个程序是否存在相同或相似的代码片段。根据代码的相似程度不同,代码相似性检测一般分为四个层次:(1)完全相同的程序代码;(2)完全复用除空格、注释、变量或函数重命名等之外的代码;(3)类型(2)基础上略有修改的代码;(4)实现方式不同但语义或功能相同的代码。传统的检测方法通常只考虑语法层面的代码相似性检测,因此只能达到类型(1)和类型(2)的检测水平,现有的相似性检测方法结合词汇、语法、语义等多维度分析方法,实现了类型(3)和类型(4)层面的代码相似性检测。
智能合约相似性检测是针对区块链智能合约的代码克隆检测,智能合约是由图灵完备语言编写的程序代码,具有不可逆和不可变性,即合约部署后将不能进行修改和更新。若是某个智能合约存在漏洞,可能会导致其克隆的衍生合约也存在相应的漏洞,因此研究针对智能合约代码的相似性检测方法是有必要的,其能够有效地避免合约漏洞的传播,从而进一步提高智能合约的可靠性和安全性。
基于句法树匹配的方法能够有效地解决智能合约相似性检测问题,通过把智能合约代码转换为抽象语法树(ast),再将每个ast分割成多个句法树,得到相应的句法树序列,并利用相似性检测算法计算两个不同句法树的合约相似度矩阵;该方法不仅能实现高效精准地智能合约相似性检测,而且可以给出精确到代码行的相似性解释,具有良好的前瞻性和参考性。
技术实现要素:
鉴于上述,本发明提供了一种基于句法树匹配的智能合约相似性检测方法,能够实现语义层面的智能合约源代码相似性检测。
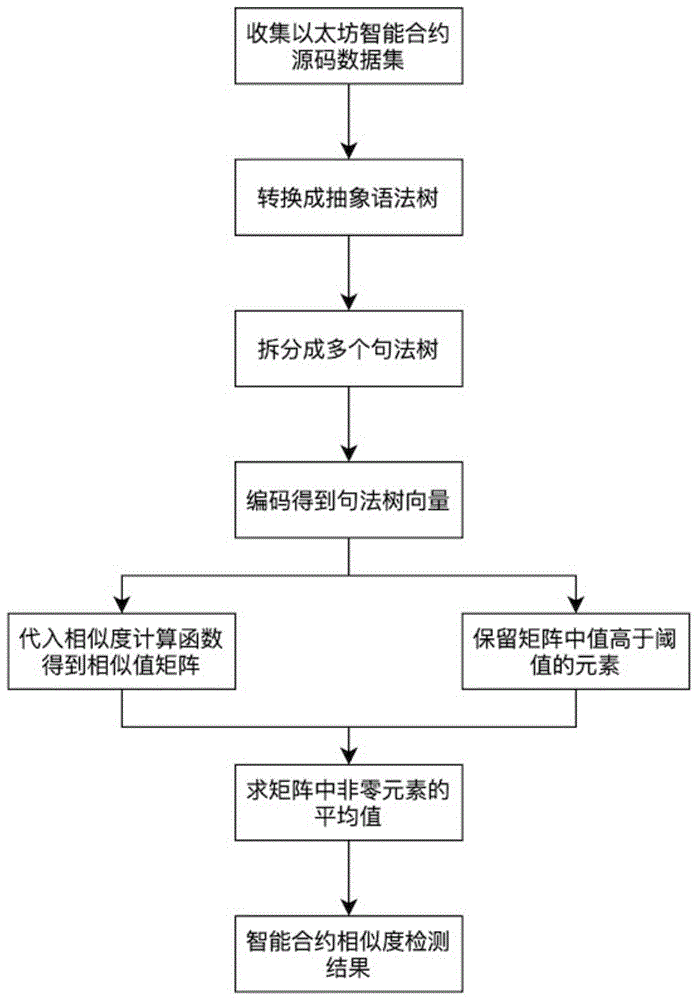
一种基于句法树匹配的智能合约相似性检测方法,包括如下步骤:
(1)构建抽象语法树:针对以太坊智能合约为研究对象,利用语法树抽取工具从智能合约源码中提取抽象语法树;
(2)构建句法树序列:以智能合约代码段z1和z2为拟检测的合约克隆对,利用语法树抽取工具得到z1和z2对应的抽象语法树f1和f2,将f1和f2按照相应的语句进行拆分并通过先序遍历对应得到句法树序列s1和s2;
(3)句法树特征提取:构建基于attention机制的句法树编码器,提取句法树序列s1和s2中每个句法树对应的特征向量,进一步得到句法树序列s1的特征向量集合
(4)相似性计算:利用皮尔逊相似性算法计算
(5)合约相似性检测:设定阈值a1和a2,将矩阵tm×k中高于a1的元素值保持不变,低于a1的元素值置零,计算矩阵中所有非零元素的平均值m,该平均值即为智能合约代码段z1与z2的相似度,进而比较m与a2的大小,判断合约代码段z1与z2是否相似;
(6)可解释性分析:若矩阵tm×k中第i行第j列元素值为矩阵中的最大元素值,则代表s1中第i个句法树与s2中第j个句法树的相似度最高,进而即可定位合约代码段z1与z2存在相似性的具体代码行。
进一步地,所述步骤(2)的具体实现方式为:首先,利用语法树抽取工具将智能合约代码段z1和z2提取为抽象语法树f1和f2;然后按照语句层次对f1和f2进行拆分,通过先序遍历得到句法树序列s1={fi∈f1|f1,...,fm}和s2={fj∈f2|f1,...,fk},其中每一棵句法树对应智能合约中的一条语句,即z1和z2分别含有m条和k条语句,i和j为自然数且1≤i≤m,1≤j≤k;
特别地,对于嵌套语句,需要定义一系列独立的节点ns={block,body},其中block用于拆分嵌套语句的header和body,body用于方法声明;以节点s为根的句法树由s及其所有的后代节点d(s)组成,如果节点s和d之间存在一条路径通过n,即意味着节点d为包含于s的body中的某条语句,其中d∈d(s),n∈ns。
进一步地,所述步骤(3)的具体实现方式如下:
首先,利用word2vec工具将需要编码的句法树中的所有节点(如果该句法树表示的是定义变量的语句,则其节点可能是相应变量的类型定义)转换为对应的向量表示,得到向量序列x={x1,...,xm},将x作为句法树编码器的输入,m为句法树中的节点数量;
然后,构建基于attention的句法树编码器,学习序列x中各向量之间的语义关系,经过多层迭代学习,获得与输入向量序列x对应的语义化向量序列y={y1,...,ym};
最后,将序列y中的所有向量输入卷积池化层中,生成句法树对应的特征向量。
进一步地,所述步骤(4)的具体实现方式为:将
其中:pit表示向量pi中的第t个元素值,
进一步地,所述步骤(5)的具体实现方式如下:
首先,设定阈值a1和a2,其中a1用于过滤合约相似度矩阵中相似值偏低的元素,a2用于判断两个代码段是否相似;
然后,将矩阵tm×k中高于a1的元素值保持不变,低于a1的元素值置零,计算矩阵中所有非零元素的平均值m,该平均值即为智能合约代码段z1与z2的相似度;
最后,比较m与a2的大小,判断z1与z2的相似性:如果m≥a2,则表示z1与z2具有相似性,否则z1与z2不具有相似性。
进一步地,所述步骤(6)的具体实现方式为:首先,通过比较矩阵tm×k中的元素值大小,可以锁定其中一些数值较高的元素,并得到这些元素在矩阵中的位置;具体地,矩阵tm×k中第i行第j列的值即表示s1中的第i个句法树与s2中第j个句法树的相似度,若是该相似度值大于设定阈值,则表示智能合约代码段z1中的第i个语句与z2中的第j个语句高度相似,以此可以锁定至智能合约中具体的代码行,从而给出智能合约相似性检测的可解释性。
本发明基于句法树匹配的智能合约相似度检测方法,有效地解决了以太坊智能合约相似性检测问题;相较于传统的代码克隆检测方法,本发明方法实现了更准确的检测效果,同时具备精确到代码行的相似性检测解释,具有良好的通用性和实用价值,具体有益技术效果和创新性主要表现在以下四个方面:
1.本发明阐述的智能合约句法树构建方法,通过抽象语法树提取工具捕获了智能合约语法信息,并在语句层面进行细分,能够更精确的比较两个代码段的相似性。
2.本发明提出的基于attention机制的句法树编码器,能够提取合约句法树中高语义的向量表示,提高了相似性检测的准确率和效率。
3.本发明将不同合约代码行的相似性数值化,能够相应的给出智能合约相似性检测解释性,具有可靠的参考意义。
4.本发明提出的基于句法树匹配的智能合约相似度检测方法,具有很好的拓展性与借鉴意义。
附图说明
图1为本发明基于句法树匹配的智能合约相似度检测方法的流程示意图。
图2为本发明拆分抽象语法树为句法树的流程示意图。
图3为本发明基于attention的编码器的编码示意图。
图4为本发明具体实例检测智能合约相似度的仿真示意图。
具体实施方式
为了更为具体地描述本发明,下面结合附图及具体实施方式对本发明的技术方案进行详细说明。
本发明基于句法树匹配的智能合约源码相似性进行检测,其借助抽象语法树提取工具捕获智能合约语法信息,利用编码器的注意力机制获取句法树中各节点的语义信息,最终提取智能合约句法树的高语义特征向量,以特征向量为相似度计算函数的输入得到不同句法树之间的相似值,通过求平均值的方法得到两段智能合约源码的相似性检测结果,其流程如图1所示。
如图2所示,本发明将智能合约语法树(ast)拆分成句法树的方法可概括为:按照不同的语句对ast进行拆分,以先序遍历得到句法树序列s,即每棵句法树对应源码中的一个语句。对于嵌套语句,定义一系列独立节点ns={block,body},其中block用于拆分嵌套语句的header和body(如句法树f4和句法树f5之间的嵌套关系),body用于方法声明;句法树的定义为:以s为根的句法树由s及其所有的后代节点d(s)组成(其中s∈s);后代节点的定义为:如果s和d之间存在一条路径通过n,即意味着节点d包含于s的body中的某条语句(其中d∈d(s),n∈ns)。
以图2中的funstatement句法树为例,本发明基于attention机制的句法树编码器的过程为:(1)利用word2vec工具将句法树的所有节点转换为初始向量表示,得到序列x={x1,...,xm}(其中xi为每个节点的向量表示);(2)将句法树初始向量x输入到attention网络中,各向量之间通过互相使用注意力机制学习彼此间存在的语义关系,以此提取句法树中各节点之间的语义关系;(3)通过步骤(2)多次迭代学习,将学习结果经过softmax层进行归一化处理,得到对应于初始向量的语义化向量表示y={y1,...,ym}(其中yi和xi依次对应),其不仅包含语法信息,也包含语义信息(本发明中所述的语义化向量为:考虑句法树节点对应的代码在不同代码行中可能含有不同含义,将节点的初始向量转换为结合使用环境的语义化向量,如图2中代码段第3、4行均存在public,其中第3行public表示变量类型,而第4行public表示函数类型);(4)利用卷积池化层,将y转换成最终的句法树向量pi。
以下实施方式以图4所示的智能合约相似性检测为例,具体检测流程如下:
(1)首先,利用语法树抽取工具分别将智能合约a和b转换成抽象语法树f1和f2。
(2)如图2所示,将f1和f2按照不同的语句进行拆分,并通过先序遍历得到句法树序列s1={fi∈f1|f1,...,f8},s2={fi∈f2|f1,...,f10}。本例中,合约a和b分别含有8条语句和10条语句,故序列s1含有8棵句法树,s2含有10棵句法树。
(3)如图3所示,通过基于attention机制的句法编码器,生成句法树序列s1和s2中每个子句法树fi对应的特征向量,进一步得到句法树序列s1的特征向量集合
(4)将
4.1利用皮尔逊相似性计算函数计算
最终得到合约相似度矩阵t8×10,矩阵第i行第j列元素值即序列s1中第i个句法树和s2中第j个句法树的相似值。
4.2设定阈值a1=0.75,将t8×10中元素值高于a1的元素保留,低于a1的元素置零。
(5)设定阈值a2,求合约相似度矩阵t8×10中非零元素的平均值,得到智能合约a,b的相似值m,比较m和a2的大小,从而判断智能合约a和b是否相似,具体实施过程如下:
5.1计算矩阵t8×10非零元素的平均值m,m即为智能合约a和b的相似度。
5.2设定一个阈值a2=0.8,若m≥a2,即合约a和b的相似值高于0.8,则表示合约a与b存在语义相似性;反之,则合约a与b不存在语义相似性。
5.3本案例相似值m大于0.8,表示合约a与b存在语义相似性。
(6)对t8×10中元素的进行进一步分析,若t8×10中第i行第j列元素的相似值较高,则表示合约a中的第i条语句和b中第j条语句具有高度相似性,这进一步体现了该相似性检测方法的可解释性分析,具体实施过程如下:
6.1将合约相似度矩阵t8×10中的元素值进行比较,可以得出该矩阵相似值比较高的元素及在其在矩阵的位置。
6.2显然在本例中,相似度最高的为合约a、b中的第一条和第二条语句(相似值为1.00),以此可以锁定至合约第1、2两行。
上述对实施例的描述是为便于本技术领域的普通技术人员能理解和应用本发明。熟悉本领域技术的人员显然可以容易地对上述实施例做出各种修改,并把在此说明的一般原理应用到其他实施例中而不必经过创造性的劳动。因此,本发明不限于上述实施例,本领域技术人员根据本发明的揭示,对于本发明做出的改进和修改都应该在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!