一种基于深度学习的自然语言语义理解方法
本发明涉及计算机自然语言处理技术领域,具体为一种基于深度学习的自然语言语义理解方法。
背景技术:
自然语言理解俗称人机对话,主要研究用电子计算机模拟人的语言交际过程,使计算机能理解和运用人类社会的自然语言如汉语、英语等,计算机在获取到用户语音后,经过对用户的识别和处理后得到语句信息,然后计算机系统对语句信息进行语音理解后,以获知用户的意图,然后再从计算机知识库内匹配出相应的语句后进行播放,以实现人机之间的自然语言通信,以代替人的部分脑力劳动,包括查询资料、解答问题、摘录文献、汇编资料以及一切有关自然语言信息的加工处理。而对于自然语言来说,哪怕对于同一个意思,对于不同的用户来说,表述出来的自然语言也就会所有不同。所以直至今天,自然语言理解依旧是人工智能领域尚未完全攻克的一块高地。而深度学习是近期人工智能研究取得突破性的进展,它结束了人工智能长达十年未能有突破性进展的局面,并迅速在工业界产生影响。计算机在对语句进行语义理解时,采用深度学习的语义理解方法有别于仅可以完成特定任务的狭隘的人工智能系统(面向特定任务的功能模拟),可以应对各种情况和问题,已在图像识别、语音识别等领域得到极其成功的应用,在自然语言处理领域(主要是英文)也取得一定成效。深度学习是目前实现人工智能最有效、也是取得成效最大的实施方法。
然而,就算基于深度学习的语义理解能够应对各种情况和问题,更能充分的满足用户的需求,但是前提是进行语义理解的语句的准确度要高,一旦语音识别出的语句是错误的,在语义理解后的结果也将是错误的。而目前的人工智能问答系统中,在使用时,通常是根据获取到的用户语音直接进行语义理解,然后将得到的结果进行反馈,这就导致有的时候反馈的结果与用户想要的结果完全不符,也就降低了问答结果的准确性。
技术实现要素:
本发明意在提供一种能够提高问答结果的基于深度学习的自然语言语义理解方法。
本发明提供基础方案是:一种基于深度学习的自然语言语义理解方法,包括以下步骤:
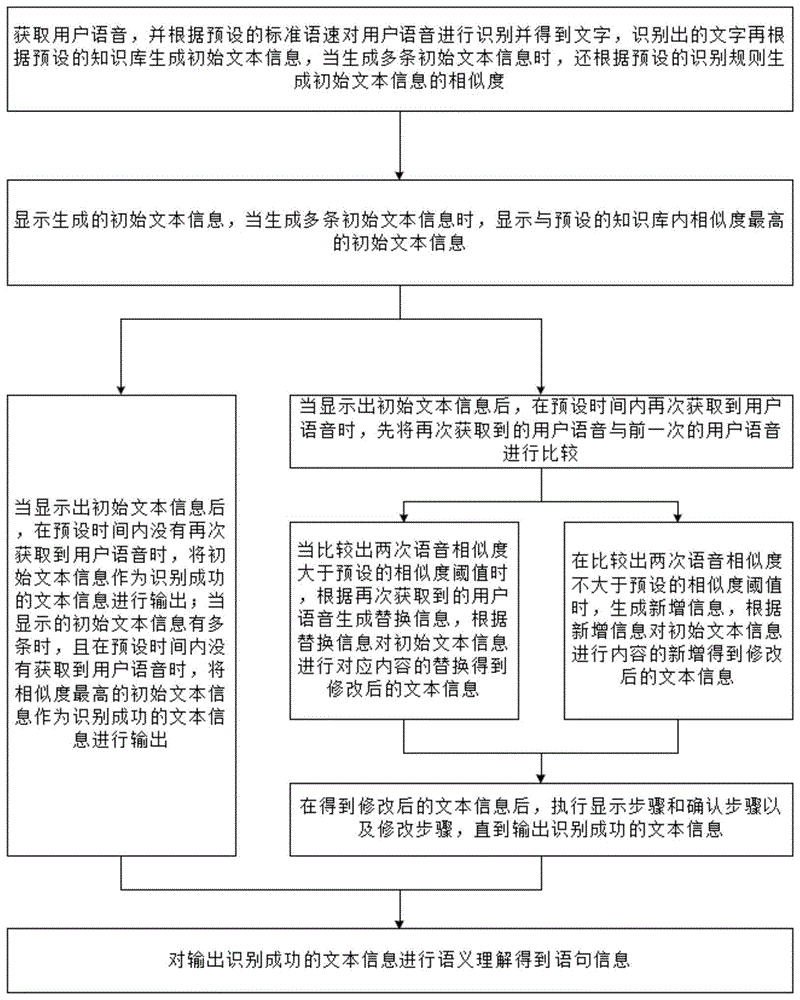
处理步骤:获取用户语音,并根据预设的标准语速对用户语音进行识别并得到文字,识别出的文字再根据预设的知识库生成初始文本信息,当生成多条初始文本信息时,还根据预设的识别规则生成初始文本信息的相似度;
显示步骤:显示生成的初始文本信息,当生成多条初始文本信息时,显示与预设的知识库内相似度最高的初始文本信息;
确认步骤:当显示出初始文本信息后,在预设时间内没有再次获取到用户语音时,将初始文本信息作为识别成功的文本信息进行输出;
修改步骤:当显示出初始文本信息后,在预设时间内再次获取到用户语音时,先将再次获取到的用户语音与前一次的用户语音进行比较,当比较出两次语音相似度大于预设的相似度阈值时,根据再次获取到的用户语音生成替换信息,根据替换信息对初始文本信息进行对应内容的替换得到修改后的文本信息;在比较出两次语音相似度不大于预设的相似度阈值时,根据再次获取到的用户语音生成新增信息,根据新增信息对初始文本信息进行内容的新增得到修改后的文本信息;在得到修改后的文本信息后,执行显示步骤和确认步骤以及修改步骤,直到输出识别成功的文本信息;
语义理解步骤:对输出识别成功的文本信息进行语义理解得到语句信息。
基础方案的工作原理及有益效果是:本方案中,处理步骤在获取到用户语音后对用户语音进行语音识别得到文字,然后根据预设的知识库将识别出的文字组合生成初始文本信息,显示步骤显示初始文本信息,为用户进行展示,供用户进行确认,当识别出多条初始文本信息时,则会将与预设的知识库内相似度最高的初始文字进行显示;若在预设时间内若没有获取到用户语音,则默认显示出来的初始文本信息是正确的,此时确认初始文本信息为识别成功的文本信息进行输出。
而在显示初始文本信息后,若在预设时间内再次获取到用户语音,说明当前显示的文本信息有误,所以用户重新进行了表达,对再次获得的用户语音进行识别后生成修改信息,并根据修改信息对初始文本信息进行修改,得到修改后的文本信息即为根据用户重新表达的语音进行修改后的文本信息,此时再将修改后的文本信息显示出来供用户确认,若修改后的文本信息仍然有误,则根据再次获取到的用户语音继续进行修改,直到用户确认无误后,即在显示出文本信息后,在预设的时间内没有获取到用户的用户语音,此时将当前显示的文本信息作为识别成功的文本信息进行输出,完成整个语音识别过程。
而在上述修改步骤过程中,考虑到当用户想要表达的内容较多时,可能会说出多句话,也就是说,当再次获取用户语音时,一种可能是用户对之前的话进行修改,另一种可能则是用户在继续表达自己的内容;而若是用户对之前的话进行修改,则前后两次的用户语音具有较高的相似度,如用户只是修改其中一个词语,则相似度甚至能够达到90%以上,而若是用户在继续表达内容,则前后两次的用户语音的相似度相对而言会更低,甚至可能达到10%以下,所以根据用户的意图,在本方案中,根据前后两次用户语音的相似度的不同,修改步骤中的修改方式也设计有两种,一种是替换修改,另一种则是新增修改,具体的,在前后两次用户语音的相似度高时,即相似度大于预设的相似度阈值时,此时进行替换修改,而在前后两次用户语音的相似度低时,即相似度不大于预设的相似度阈值时,这种情况下则进行新增修改。
与现有技术相比,本方案中,在完成语音识别后通过将识别到的文本信息显示出来供用户进行确认,若确认有误,又通过语音输入的方式对文本信息进行修改,从而保证了作为识别成功的文本信息的准确性,而且整个过程中,只需要用户通过语音的方式进行操作,操作简单。
优选方案一:作为基础方案的优选,在对用户语音进行识别时还识别用户语音的语速;还包括有比较步骤:将识别出的语速与标准语速进行对比,并在比较出识别出的语速大于标准语速时,还获取当前的用户信息,并对用户信息进行标记,当再次对该用户的用户语音进行处理时,根据预设的慢语速对用户语音进行识别生成初始文本信息。说明:本方案中,根据预设的慢语速对用户语音进行识别指的是将获取到的用户语音按照预设的慢语速播放并进行识别。
有益效果:由于在进行语音识别时,语速过快也将会导致识别出的文本信息出现错误,如“这样子(zheyangzi)”在语速过快的时候可能最后会被识别为“酱紫(jiangzi)”,因此本方案中,在对进行语音识别时,还识别语速,若识别出语速大于标准语速时,则说明第一次识别出的文本信息错误,则可能是因为用户的语速过快的原因,而考虑到用户说话的语速是自己的个人习惯,一般都是变化不大的,所以本方案中,还会对当前的用户信息进行标记,表示该用户语速过快,为了保证识别到的文本信息的准确性,在识别时,就需要根据预设的慢语速对用户语音进行识别以提高识别的准确性,也提高了语音识别的效率。
优选方案二:作为优选方案一的优选,在比较步骤中,当再次对该用户的用户语音进行处理时,先对再次获取的用户语音的语速进行识别,并将识别到的语速与标准语速进行比较,在比较出识别到的语速大于标准语速时,根据预设的慢语速对用户语音进行识别生成初始文本信息,反之则根据标准语速对用户语音进行识别生成初始文本信息。有益效果:由于用户的语速虽然通常是不变的,但是若用户之后为了提高识别的准确性而下意识的降低自己的语速,在这种情况下,识别时按照标准语速进行识别即可,若依旧根据慢语速进行识别,则反而将会降低识别的准确性,如“很久以前”中的“久(jiu)”在慢语速识别的情况下容易被识别为“ji”和“you”,因此本方案中,当再次获取到用户语音时,会先对用户语音的速度进行识别和比较,只有在比较出当前的用户语音的语速大于标准语速时,说明用户本次的语速与以往一样,还是比较快,因此才会根据慢语速对用户语音进行识别,在其他情况下,则依旧采用预设的标准语速进行识别,实现语速自适应的语音识别过程,以提高识别的准确性。
优选方案三:作为优选方案一的优选,比较步骤中,还对后一次用户语音的语速与前一次用户语音的语速进行比较,在比较出后一次用户语音的语速小于前一次用户语音的语速时,还获取用户的面部信息并根据面部信息识别出用户表情,在识别出用户表情为思考时,还根据互联网的词库生成修改信息。有益效果:考虑到出显示出来的识别出的初始文本信息不是用户想要表述的意思时,可能是因为用户在表述过程中采用了新出现的流行语,而预设的知识库中还未进行收录更新,如“给力”原本是动词,表示给出力量,现在大多人们都说的是名词,表示夸奖能干有能力的意思,因此本方案中,当用户放慢语速时,还会获取用户的面部信息并根据面部信息识别出用户表情,在识别出的用户表情为思考时,则根据互联网的词库生成修改信息,由于修改信息是从互联网的词库中匹配出来的,准确性会更高,之后更换修改信息修改后的文本信息的准确性也就会更高。
优选方案四:作为优选方案三的优选,还包括有更新步骤:在根据互联网的词库生成修改信息后,还根据互联网的词库更新预设的知识库。有益效果:本方案中,还根据互联网的词库对预设的知识库进行更新,从而扩充了知识库,提高了识别的准确率。
优选方案五:作为基础方案的优选,显示步骤中,当生成多条初始文本信息时,将多条初始文本信息按照相似度从高到低的顺序进行显示,且在预设时间内没有获取到用户语音时,将相似度最高的初始文本信息作为识别成功的文本信息进行输出。有益效果:本方案中,通过将生成的所有初始文本信息都显示出来的方式,用户通过显示出来的初始文本信息也就能够知道所有识别出的初始文本信息,从而能够更清楚的知晓识别出错的地方,因此在表述修改信息时可以准确的针对出错的地方进行表述,而不用再重新全部进行描述,在对初始文本信息进行修改时,也只需要对对应位置进行修改,而无需全部修改,减少了修改量,从而提高了修改效率;而若是没有再次获取到用户语音,则表明相似度高的初始文本信息是正确的,此时则将相似度最高的初始文本信息默认为识别成功的文本信息进行输出。
附图说明
图1为本发明一种基于深度学习的自然语言语义理解方法实施例的流程图。
具体实施方式
下面通过具体实施方式进一步详细说明:
说明:为了便于理解,本实施例中的基于深度学习的自然语言语义理解方法将应用于农业种植领域相关信息的智能咨询和智能问答以举例进行说明。
实施例基本如附图1所示:一种基于深度学习的自然语言语义理解方法,包括以下步骤:
处理步骤:获取用户语音,并根据预设的标准语速对用户语音进行识别并得到文字,识别出的文字再根据预设的知识库生成初始文本信息,当生成多条初始文本信息时,还根据预设的识别规则生成初始文本信息的相似度;在对用户语音进行识别时还识别用户语音的语速;本实施例中,预设的知识库内存储有农业种植领域知识图谱,农业种植领域知识图谱的内容采用爬虫工具通过各大农业网站的标题和链接中获取。由于本实施例应用于农业种植领域相关信息的智能咨询和智能问答,因此识别规则为:以农业种植领域作为标准,根据识别的初始文本信息的应用领域与农业种植领域的相关性作为相似度进行排序,如“ganzi”识别得到的初始文本信息有“竿子”、“柑子”、“秆子”,其中“柑子”是一种果实,与农业种植领域最相近,而“竿子”则与农业种植领域最不贴合,因此显示时,则按照“柑子”、“秆子”、“竿子”的顺序进行显示。在其他实施例中,预设的识别规则还可以根据用户的职业来进行排序,如用户的职业是木工,则“竿子”作为有一定用途的细长的木头,则相似度最高;在处理中,还将识别到的方言词汇显示为标准词汇,如重庆方言中“柑子”对应的标准词汇则为“柑橘”。
显示步骤:显示生成的初始文本信息,当生成多条初始文本信息时,显示与预设的知识库内相似度最高的初始文本信息;优选的,在显示时,将多条初始文本信息按照相似度从高到低的顺序进行显示;
确认步骤:当显示出初始文本信息后,在预设时间内没有再次获取到用户语音时,将初始文本信息作为识别成功的文本信息进行输出;当显示的初始文本信息有多条时,且在预设时间内没有获取到用户语音时,将相似度最高的初始文本信息作为识别成功的文本信息进行输出。
修改步骤:当显示出初始文本信息后,在预设时间内再次获取到用户语音时,先将再次获取到的用户语音与前一次的用户语音进行比较,当比较出两次语音相似度大于预设的相似度阈值时,根据再次获取到的用户语音生成替换信息,根据替换信息对初始文本信息进行对应内容的替换得到修改后的文本信息;在比较出两次语音相似度不大于预设的相似度阈值时,生成新增信息,根据新增信息对初始文本信息进行内容的新增得到修改后的文本信息;在得到修改后的文本信息后,执行显示步骤和确认步骤以及修改步骤,直到输出识别成功的文本信息;
语义理解步骤:对输出识别成功的文本信息进行语义理解得到语句信息;
比较步骤:将识别出的语速与标准语速进行对比,并在比较出识别出的语速大于标准语速时,还获取当前的用户信息,并对用户信息进行标记,当再次对该用户的用户语音进行处理时,先对再次获取的用户语音的语速进行识别,并将识别到的语速与标准语速进行比较,在比较出识别到的语速大于标准语速时,根据预设的慢语速对用户语音进行识别生成初始文本信息,反之则根据标准语速对用户语音进行识别生成初始文本信息;还对后一次用户语音的语速与前一次用户语音的语速进行比较,在比较出后一次用户语音的语速小于前一次用户语音的语速时,还获取用户的面部信息并根据面部信息识别出用户表情,在识别出用户表情为思考时,还根据互联网的词库生成修改信息。
更新步骤:在根据互联网的词库生成修改信息后,还根据互联网的词库更新预设的知识库。
具体实施过程如下:使用时,首先获取用户语音,然后对获取到的用户语音进行识别得到文字,在这个过程中,包括信号处理、信号表征和模式识别,其中信号处理指的是对获取到的用户语音进行模数转换,识别端头以及降噪等,然后信号表征则是将处理后的信号进行分帧、特征提取以及向量化等,最后模式识别则是寻找最有概率路径,声学模型识别音素,根据音素从而识别出文字,然后在得到文字后,再根据预设的知识库生成初始文本信息。
若在识别后生成一条初始文本信息,则直接将生成的初始文本信息进行显示,而若是生成了多条初始文本信息,则根据预设的识别规则还生成初始文本信息的相似度,显示时则按照相似度由高到低排序后进行显示。
在显示出初始文本信息后,设定预设时间为五秒,则在显示出初始文本信息五秒内,若没有再次获取到用户语音,则将显示出的初始文本信息作为识别成功的文本信息输出,对输出的文本信息进行语义理解得到语句信息。
而若在显示出初始文本信息后的五秒内,再次接收到了用户语音,会先将再次接收到的用户语音与前一次的用户语音进行比较,从而得到前后两次用户语音的相似度,然后还会将相似度与预设的相似度阈值进行比较,设定比较得出的相似度为k,预设的相似度为k0,则当比较出相似度大于相似度阈值时,即k>k0,则说明前后两次的用户语音相似度很高,在这种情况下,根据用户语音生成替换信息,并根据替换信息对初始文本信息进行对应内容的替换得到修改后的文本信息;而在比较出相似度不大于相似度阈值时,即k≤k0时,则说明前后两次的用户语音相似度较低,则后一次的用户语音可能为用户对前一次用户语音进行的补充内容,此时根据再次获取到的用户语音生成新增信息,根据新增信息对初始文本信息进行内容的新增得到修改后的文本信息;在得到修改后的文本信息后,执行显示步骤和确认步骤以及修改步骤,直到输出识别成功的文本信息。
而在显示的初始文本信息有多条时,且在显示出初始文本信息五秒内,若没有再次获取到用户语音,则将显示出的相似度最高的初始文本信息作为识别成功的文本信息输出;而若在显示后的五秒内有再次获取到用户语音,执行修改步骤,然后再执行显示步骤和确认步骤以及修改步骤,直到输出识别成功的文本信息。
以上所述的仅是本发明的实施例,方案中公知的具体结构及特性等常识在此未作过多描述,所属领域普通技术人员知晓申请日或者优先权日之前发明所属技术领域所有的普通技术知识,能够获知该领域中所有的现有技术,并且具有应用该日期之前常规实验手段的能力,所属领域普通技术人员可以在本申请给出的启示下,结合自身能力完善并实施本方案,一些典型的公知结构或者公知方法不应当成为所属领域普通技术人员实施本申请的障碍。应当指出,对于本领域的技术人员来说,在不脱离本发明结构的前提下,还可以作出若干变形和改进,这些也应该视为本发明的保护范围,这些都不会影响本发明实施的效果和专利的实用性。本申请要求的保护范围应当以其权利要求的内容为准,说明书中的具体实施方式等记载可以用于解释权利要求的内容。
- 还没有人留言评论。精彩留言会获得点赞!