一种敏感数据识别方法及装置与流程
本发明涉及计算机信息安全技术领域,特别是涉及一种对数据库系统中含有的敏感数据识别的敏感数据识别方法及装置。
背景技术:
敏感数据又称隐私数据,常见的有姓名、身份证号码、住址、电话、银行账号、邮箱、密码、医疗信息、教育背景等。目前,银行、保险、证券等金融机构保存的数据含有大量个人隐私的数据,这些与个人生活、工作密切相关的信息受到不同行业和政府数据隐私法规的管制。如果负责存储和发布这些信息的企业或政府无法保证数据隐私,他们就会面临严重的财务、法律或问责风险,同时在用户信任方面蒙受巨大损失。因此,有效可靠的敏感数据检测技术,相当重要。
在现有技术中,一般都是指定数据库对应的表名列名来确定是否进行脱敏,然而,这样的方式需要大量人工去完成,并有遗漏敏感数据的可能性,费事费力且效率低下。
技术实现要素:
为克服上述现有技术存在的不足,本发明之目的在于提供一种敏感数据识别方法及装置,以解决现有技术人工识别工作量大且可能遗漏敏感数据的问题,自动识别数据库是否含有敏感数据,并输出含有敏感数据的列及其类型。
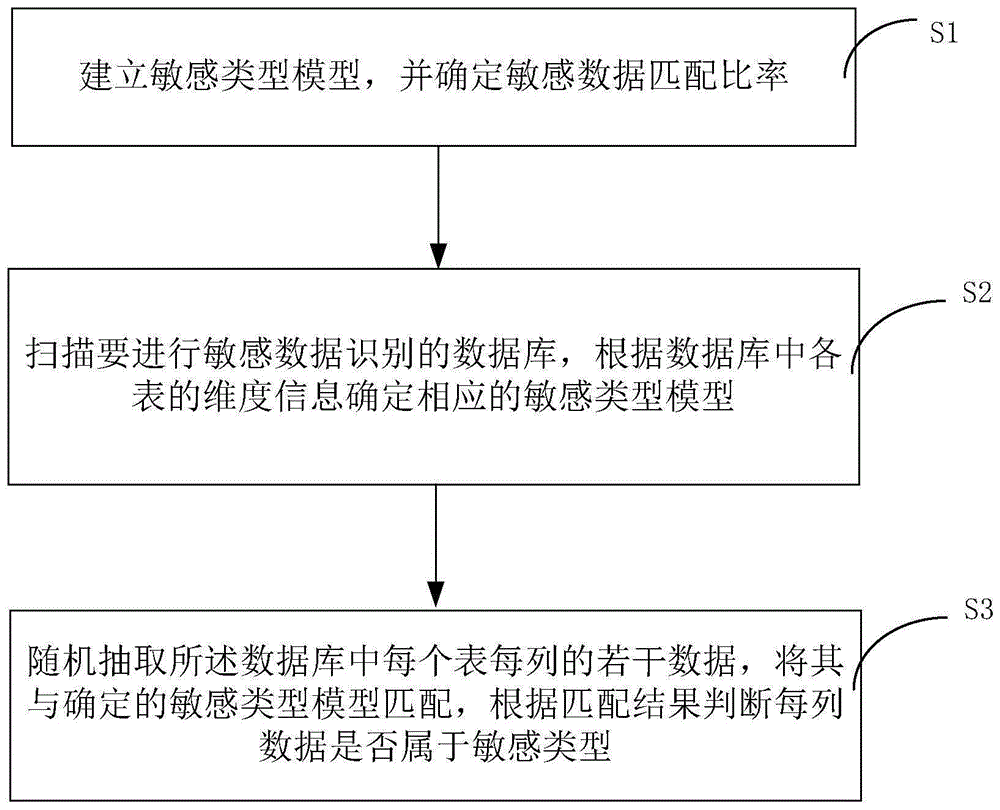
为达上述目的,本发明提出一种敏感数据识别方法,包括如下步骤:
步骤s1,建立敏感类型模型,并确定敏感数据匹配比率;
步骤s2,扫描欲进行敏感数据识别的数据库,根据其中各表的各维度信息确定相应的敏感类型模型;
步骤s3,随机抽取所述数据库中每个表每列的若干数据,将其与确定的敏感类型模型匹配,根据匹配结果判断每列数据是否属于敏感类型。
优选地,步骤s1进一步包括:
步骤s100,根据通用的敏感数据定义,建立通用的敏感类型模型;
步骤s101,自定义敏感类型,根据自定义的敏感类型建立自定义的敏感数据模型;
步骤s102,定义并预设敏感数据匹配比率。
优选地,于步骤s2中,扫描欲进行敏感数据识别的数据库,提取所述数据库的库名、表名、表注释,针对各个表获取列名及列注释并进行判断,从而确定相应的敏感类型模模型。
优选地,步骤s3进一步包括:
步骤s300,对所述数据库的每张表每列数据随机抽取预设数量数据;
步骤s301,根据步骤s2确定的敏感类型模型对抽取的当前列数据一一进行匹配,确定其是否与步骤s2中确定的敏感类型模型匹配;
步骤s302,根据步骤s301的匹配结果与步骤s1定义的敏感数据匹配比率,确定当前列数据是否属于敏感类型。
优选地,于步骤s300中,若当前表当前列的数据量大于预设阈值时,则抽取预设阈值量的数据;若当前表当前列的数据量小于或等于预设阈值时,则将当前表当前列的数据全部抽取。
优选地,于步骤s302中,当根据步骤s301的匹配结果,与步骤s2中确定的敏感类型模型匹配的数据量与抽取总量的比值大于步骤s1定义的敏感数据匹配比率,则确定当前列数据属于敏感类型。
为达到上述目的,本发明还提供一种敏感数据识别装置,包括如下步骤:
敏感类型模型构建单元,用于建立敏感类型模型,并确定敏感数据匹配比率;
敏感类型模型确定单元,用于扫描欲进行敏感数据识别的数据库,根据其中各表的各维度信息确定相应的敏感类型模型;
敏感数据识别单元,用于随机抽取所述数据库中每个表每列的若干数据,将其与确定的敏感类型模型匹配,根据匹配结果判断每列数据是否属于敏感类型。
优选地,所述敏感类型模型构建单元进一步包括:
通用敏感类型模型构建模块,用于根据通用的敏感数据定义,建立通用的敏感类型模型;
自定义敏感类型构建模块,用于自定义敏感类型,根据自定义的敏感类型建立自定义的敏感数据模型;
敏感数据匹配比率定义模块,用于定义并预设敏感数据匹配比率。
优选地,所述敏感类型模型确定单元扫描欲进行敏感数据识别的数据库,提取所述数据库的库名、表名、表注释,针对各个表获取列名及列注释并进行判断,从而确定相应的敏感类型模模型。
优选地,所述敏感数据识别单元进一步包括:
抽取模块,用于对所述数据库的每张表每列数据随机抽取预设数量数据;
数据匹配模块,根据所述敏感类型模型确定单元确定的敏感类型模型对抽取的当前列数据一一进行匹配,确定是否与所述敏感类型模型确定单元中确定的敏感类型模型匹配;
敏感类型确定模块,用于根据所述数据匹配模块的匹配结果与敏感类型模型构建单元定义的敏感数据匹配比率,确定当前列数据是否属于敏感类型。
与现有技术相比,本发明一种敏感数据识别方法及装置通过建立敏感类型模型,确定敏感数据匹配比率,然后扫描欲进行敏感数据识别的数据库,根据数据库的多个维度信息确定相应的敏感类型模型,随机抽取所述数据库中每个表每列的若干数据,将其与确定的敏感类型模型匹配,根据匹配结果判断每列数据是否属于敏感类型,以自动识别数据库是否含有敏感数据,并输出含有敏感数据的列及其类型的目的,从而解决现有技术人工识别工作量大且可能遗漏敏感数据的问题,
附图说明
图1为本发明一种敏感数据识别方法的步骤流程图;
图2为本发明一种敏感数据识别装置的系统架构图;
图3为本发明实施例中敏感数据识别方法的流程图。
具体实施方式
以下通过特定的具体实例并结合附图说明本发明的实施方式,本领域技术人员可由本说明书所揭示的内容轻易地了解本发明的其它优点与功效。本发明亦可通过其它不同的具体实例加以施行或应用,本说明书中的各项细节亦可基于不同观点与应用,在不背离本发明的精神下进行各种修饰与变更。
图1为本发明一种敏感数据识别方法的步骤流程图。如图1所示,本发明一种敏感数据识别方法,包括如下步骤:
步骤s1,建立敏感类型模型,并确定敏感数据匹配比率。
具体地,步骤s1进一步包括:
步骤s100,根据通用的敏感数据定义,建立通用的敏感类型模型。
于步骤s100中,可以根据现行通用的敏感数据定义建立通用的敏感类型模型。例如,现行通用的敏感类型有银行卡号、居民身份证号,电话号码等,而对于每种敏感类型,对应不同的格式特征,例如居民身份证号,其格式为18位全数字或17位数字加末尾一个字母等。
步骤s101,根据自定义的敏感数据,建立自定义的敏感数据模型。
也就是说,在本发明中,用户还可以对敏感数据进行自定义,例如用户可以自定义如金融行业、基金代码等非常见的敏感数据类型,并根据其对应的特征,构建自定义敏感数据模型。
步骤s102,确定敏感数据匹配比率。
在本发明中,预先确定并设置敏感数据匹配比率,本发明确定敏感数据匹配比率的目的是当数据库中某列的数据匹配对应的敏感类型模型超过该敏感数据匹配比率时,才将该列数据识别为敏感数据。例如当确定敏感数据匹配比率为50%时,只有当某列数据的匹配数据量超过检测总量的50%,认为该列数据为敏感数据。
步骤s2,扫描要进行敏感数据识别的数据库,根据数据库中各表的维度信息确定相应的敏感类型模型。
在本发明具体实施例中,扫描要进行敏感数据识别的数据库,提取数据库的库名、表名、表注释,并针对各个表的若干维度信息确定相应的敏感类型模型。具体地,首先获取表的列名、列注释,同时进行判断,并记录当前匹配的敏感类型,然后进入步骤s3对该列数据取值,判断,记录匹配的敏感类型和概率,最终确定是哪种敏感类型。
步骤s3,随机抽取所述数据库中每个表每列的若干数据,将其与确定的敏感类型模型匹配,根据匹配结果判断每列数据是否属于敏感类型。
具体地,步骤s3进一步包括:
步骤s300,对所述数据库的每张表每列数据随机抽取一定量数据。
在本发明具体实施例中,若当前表的数据大于2000条,则随机抽取其中的2000条,若当前表的数据小于等于2000条,则全部抽取。
步骤s301,根据步骤s2确定的敏感类型模型对抽取的当前列数据一一进行匹配,确定是否与步骤s2中构建的敏感类型模型匹配。
例如,假设步骤s2确定当前列是通用的敏感类型模型,例如某一列名或列注释为居民身份证号码,确定该列为通用的敏感类型模型,则对该列提取的每个数据,一一判断其是否为18位以及判断其是否符合身份证规则,若符合,则表示匹配,否则,则表示不匹配。
步骤s302,根据步骤s301的匹配结果与步骤s1定义的敏感数据匹配比率,确定当前列数据是否属于敏感类型。
具体地说,当根据步骤s301的匹配结果,与步骤s2中构建的敏感类型模型匹配的数据量与抽取总量的比值大于步骤s1定义的敏感数据匹配比率,则确定当前列数据属于敏感类型,则需要进行脱敏,并输出含有敏感数据的列及其类型,例如,输出列名id,抽样数据130203200301012730,类型中国居民身份证号等。
图2为本发明一种敏感数据识别装置的系统架构图。如图2所示,本发明一种敏感数据识别装置,包括如下步骤:
敏感类型模型构建单元20,用于建立敏感类型模型,并确定敏感数据匹配比率。
具体地,敏感类型模型构建单元20进一步包括:
通用敏感类型模型构建模块201,用于根据通用的敏感数据定义,建立通用的敏感类型模型。
通用敏感类型模型构建模块201可以根据现行通用的敏感数据定义建立通用的敏感类型模型。例如,现行通用的敏感类型有银行卡号、居民身份证号,电话号码等,而对于每种敏感类型,对应不同的格式特征,例如居民身份证号,其格式为18位全数字或17位数字加末尾一个字母,等。
自定义敏感类型构建模块202,用于自定义敏感数据,根据自定义的敏感数据建立自定义的敏感数据模型。
也就是说,在本发明中,用户还可以对敏感数据进行自定义,例如用户可以自定义如金融行业、基金代码等非常见的敏感数据类型,并根据其对应的特征,构建自定义敏感数据模型。
敏感数据匹配比率定义模块203,用于确定敏感数据匹配比率。
在本发明中,预先确定并设置敏感数据匹配比率,本发明确定敏感数据匹配比率的目的是当数据库中某列的数据匹配对应的敏感类型模型超过该敏感数据匹配比率时,才将该列数据识别为敏感数据。例如当确定敏感数据匹配比率为50%时,只有某列数据的匹配数据量为检测总量的50%,才认为该列数据为敏感数据。
敏感类型模型确定单元21,用于扫描要进行敏感数据识别的数据库,根据其中各表的多个维度信息确定相应的敏感类型模型。
在本发明具体实施例中,敏感类型模型确定单元21扫描要进行敏感数据识别的数据库,提取数据库的库名、表名、表注释,并针对各个表的若干维度信息确定相应的敏感类型模型。具体地,首先获取表的列名、列注释,同时进行判断,并记录当前匹配的敏感类型,然后进入敏感数据识别单元22对该列数据取值,判断,记录匹配的敏感类型和概率,最终确定是哪种敏感类型。
敏感数据识别单元22,用于随机抽取所述数据库中每个表每列的若干数据,将其与确定的敏感类型模型匹配,根据匹配结果判断每列数据是否属于敏感类型。
具体地,敏感数据识别单元22进一步包括:
抽取模块221,用于对所述数据库的每张表每列数据随机抽取一定量数据。
在本发明具体实施例中,若当前表的数据大于2000条,则随机抽取其中的2000条,若当前表的数据小于等于2000条,则全部抽取。
数据匹配模块222,根据敏感类型模型确定单元21确定的敏感类型模型对抽取的当前列数据一一进行匹配,确定是否与敏感类型模型确定单元21中确定的敏感类型模型匹配。
例如,假设敏感类型模型确定单元21确定当前列是通用的敏感类型模型,例如某一列名或列注释为居民身份证号码,确定该列为通用的敏感类型模型,则对该列提取的每个数据,一一判断其是否为18位以及判断其是否符合身份证规则,若符合,则表示匹配,否则,则表示不匹配。
敏感类型确定模块223,用于根据数据匹配模块222的匹配结果与敏感类型模型构建单元20定义的敏感数据匹配比率,确定当前列数据是否属于敏感类型。
具体地说,当根据数据匹配模块222的匹配结果,与敏感类型模型确定单元21中构建的敏感类型模型匹配的数据量与抽取总量的比值大于敏感类型模型构建单元20定义的敏感数据匹配比率,则确定当前列数据属于敏感类型,则需要进行脱敏,并输出含有敏感数据的列及其类型,例如,输出列名id,抽样数据130203200301012730,类型中国居民身份证号等。
实施例
如图3所示,在本实施例中,一种敏感数据识别方法的步骤如下:
步骤1,敏感类型建模,并定义敏感数据匹配比率。
具体地,根据用户现有的敏感数据定义,建立敏感类型模型,并根据现行通用的敏感数据定义,进行相应的敏感类型建模。
定义敏感数据匹配比率,当数据匹配敏感类型超过一定比率,该数据识别为敏感数据,例如当匹配数据量为检测总量的50%,认为该列数据为敏感数据。
步骤2,扫描数据库,通过数据库的库名,表名,表注释,列名,列注释几个维度,确定相应的敏感类型模型。
步骤3,对每张表每列数据随机抽取一定量数据。
具体地,若当前表的数据大于2000条,则随机抽取2000条;若当前表的数据小于等于2000条,则全部抽取。
步骤4,根据相应的敏感类型模型对列名,列注释进行匹配,确定该列是否为步骤1中构建的敏感类型,若是,则写入结果集。
步骤5,对抽取的数据进行匹配,确定是否为步骤1中构建的敏感类型,若是,则将匹配结果写入结果集。
步骤6,根据步骤5的匹配结果计算匹配的比率,根据匹配的比率与定义的敏感数据匹配比率判断该列数据是否为敏感数据,并将结果写入结果集。
步骤7,综合步骤4,5,6中的结果确定当前列数据是否为敏感类型。
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何本领域技术人员均可在不违背本发明的精神及范畴下,对上述实施例进行修饰与改变。因此,本发明的权利保护范围,应如权利要求书所列。
- 还没有人留言评论。精彩留言会获得点赞!