扩展LBA环境中的有效TLP分片的制作方法
扩展lba环境中的有效tlp分片
1.相关申请的交叉引用
2.本技术要求2020年9月25日提交的美国临时专利申请序列号63/083,647的权益,该美国临时专利申请以引用方式并入本文。
背景技术:
技术领域
3.本公开的实施方案整体涉及数据存储设备中的有效传输层数据包(tlp)分片。
4.相关领域的描述
5.元数据是基于每个逻辑块分配的附加数据。对主机设备如何使用元数据区域没有要求。元数据的最常见用途之一是传送端到端保护信息。
6.元数据可由控制器以两种方式中的一种方式传输往来于主机设备。当名称空间被格式化时,选择所使用的机制。用于传输元数据的一种机制是作为与元数据相关联的逻辑块的连续部分。元数据在相关联的逻辑块的末尾传输,从而形成扩展的逻辑块,如图1所示。
7.在支持无序数据传输时,扩展逻辑块地址(lba)格式在数据传输中设立了重大挑战。图2示出了简单示例中的问题。在该示例中,存储器页面大小表示主机设备dram中的每个缓冲区的大小并且被设置为4kb。lba大小也被设置为4kb,而元数据大小为16字节。主机设备发送读/写命令并且总传输大小为三个lba,这意味着以下应在pcie总线上传输:lba a、元数据a、lba b、元数据b、lba c和元数据c。如图2所示,对于该命令,需要四个主机设备缓冲区。第一缓冲区保存lba a。第二缓冲区保存元数据a加上lba b的第一部分。第三缓冲区保存lba b的尾部、元数据b和lba c的第一部分。最后的缓冲区保存lba c的尾部和元数据c。
8.在无序数据传输中,数据存储设备可能需要首先传输lba b和元数据b。在这种情况下,将通过pcie总线发出未优化数据包以进行未对齐的传输。稍后,数据存储设备可能需要传输lba a和元数据a。同样,数据存储设备将发出未优化数据包以仅从第二缓冲区传输元数据。
9.因此,本领域需要传输层数据包(tlp)分片优化。
技术实现要素:
10.本公开整体涉及数据存储设备中的有效传输层数据包(tlp)分片。对于来自主机流的未对齐读取,将足以对齐的数据量从主机传输到存储器设备,同时将数据的其余部分存储在数据存储设备的高速缓存中以稍后递送到存储器设备。对于对主机流的未对齐写入,将未对齐数据写入高速缓存,并且稍后高速缓存将被刷新到主机设备。在这两种情况下,虽然总数据将不对齐,但数据的一部分被放置在高速缓存中,使得未放置在高速缓存中的数据对齐。高速缓存中的数据在稍后的时间点递送。
11.在一个实施方案中,一种数据存储设备包括:一个或多个存储器设备;和控制器,
该控制器耦接到该一个或多个存储器设备,其中该控制器被配置为:接收来自主机请求的读取;确定该来自主机请求的读取超过最大有效载荷大小(mps);将该请求的地址和大小与该mps对齐以创建对齐的请求;为该来自主机请求的读取分配高速缓存缓冲区存储空间;将该对齐的请求发送至主机设备;接收超过该对齐的请求的该mps的返回数据;以及将该返回数据存储在所分配的高速缓存中。
12.在另一个实施方案中,一种数据存储设备包括:一个或多个存储器设备;接口模块;和控制器,该控制器耦接到该一个或多个存储器设备,其中该控制器被配置为:通过该接口模块接收主机请求;确定该主机请求未对齐;以及从高速缓存检索数据。
13.在另一个实施方案中,一种数据存储设备包括:一个或多个存储器设备;用于确定来自主机设备的未对齐的访问请求的接口装置;以及控制器,该控制器耦接到该一个或多个存储器设备。
附图说明
14.因此,通过参考实施方案,可以获得详细理解本公开的上述特征的方式、本公开的更具体描述、上述简要概述,所述实施方案中的一些在附图中示出。然而,应当注意的是,附图仅示出了本公开的典型实施方案并且因此不应视为限制其范围,因为本公开可以允许其他同等有效的实施方案。
15.图1是扩展逻辑块地址(lba)的示意图。
16.图2是数据缓冲区示例的示意图。
17.图3是根据一个实施方案的存储系统的示意图。
18.图4是示出根据一个实施方案的写入命令处理的方法的流程图。
19.图5是示出根据一个实施方案的读取命令处理的方法的流程图。
20.图6a和6b是示出根据多个实施方案的高速缓存刷新的方法的流程图。
21.为了有助于理解,在可能的情况下,使用相同的参考标号来表示附图中共有的相同元件。可以设想是,在一个实施方案中公开的元件可以有利地用于其他实施方案而无需具体叙述。
具体实施方式
22.在下文中,参考本公开的实施方案。然而,应当理解的是,本公开不限于具体描述的实施方案。相反,思考以下特征和元件的任何组合(无论是否与不同实施方案相关)以实现和实践本公开。此外,尽管本公开的实施方案可以实现优于其他可能解决方案和/或优于现有技术的优点,但是否通过给定实施方案来实现特定优点不是对本公开的限制。因此,以下方面、特征、实施方案和优点仅是说明性的,并且不被认为是所附权利要求书的要素或限制,除非在权利要求书中明确地叙述。同样地,对“本公开”的引用不应当被解释为本文公开的任何发明主题的概括,并且不应当被认为是所附权利要求书的要素或限制,除非在权利要求书中明确地叙述。
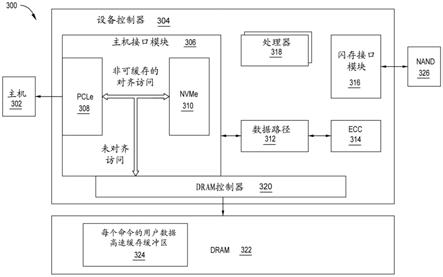
23.本公开整体涉及数据存储设备中的有效传输层数据包(tlp)分片。对于来自主机流的未对齐读取,将足以对齐的数据量从主机传输到存储器设备,同时将数据的其余部分存储在数据存储设备的高速缓存中以稍后递送到存储器设备。对于对主机流的未对齐写
入,将未对齐数据写入高速缓存,并且稍后高速缓存将被刷新到主机设备。在这两种情况下,虽然总数据将不对齐,但数据的一部分被放置在高速缓存中,使得未放置在高速缓存中的数据对齐。高速缓存中的数据在稍后的时间点递送。
24.图1是扩展逻辑块地址(lba)的示意图。元数据是基于每个逻辑块分配的附加数据,其中元数据可以是关于相关联的用户数据的信息。例如,元数据可传送相关联用户数据的端到端保护信息。在一个示例中,元数据可作为逻辑块的连续部分的一部分由数据存储设备的控制器传输往来于主机设备。元数据可在相关联的逻辑块的末尾被传输,其中逻辑块和相关联的元数据形成扩展的逻辑块。
25.扩展lba包括第一数据缓冲区,该第一数据缓冲区包括第一物理区域页面(prp)prp1和第二prp prp2。扩展lba中的每个lba包括相关联的元数据。例如,第一lba n元数据与第一lba n数据的数据相关联,并且第二lba n+1元数据与第二lba n+1数据的数据相关联。应当理解,扩展lba可具有任何适当数量的lba数据和lba元数据对,并且所示数量并非旨在进行限制,而是用于提供可能实施方案的示例。
26.图2是数据缓冲区示例的示意图。图1的各方面可类似于图2的数据缓冲区示例。当将扩展的lba传输到主机时,每个lba数据大小可为约4kb,并且每个lba元数据大小可为约16字节。此外,在通过数据总线将扩展的lba传输到主机设备之前,扩展lba可存储在一个或多个缓冲区中。在一个示例中,一个或多个缓冲区中的每个缓冲区具有约4kb的大小。例如,pcie架构中的每个缓冲区可具有最大有效载荷大小(mps),其中该mps表示每个缓冲区的大小。应当理解,虽然例示了pcie架构,但其他架构也是相关的,并且本文的实施方案适用于其他架构。
27.当主机设备发送读/写命令并且总传输大小为3个lba时,使得3个lba和相关联的lba元数据形成扩展的lba,由于缓冲区mps,需要四个缓冲区202a、202b、202c、202d来传输3个lba和相关联的lba元数据。3个lba包括第一用户数据204a、第二用户数据204b、204ba和第三用户数据204c、204ca。第一缓冲区202a包括第一用户数据204a。出于示例性目的,术语“用户数据”可互换地指lba数据,诸如图1的第一lba n数据。第二缓冲区202b包括与第一用户数据204a相关联的第一元数据206a和第二用户数据204b的第一部分。由于第二缓冲区202b具有约4kb的大小并且相关元数据被顺序地写入到一个或多个缓冲区,因此第二用户数据无法完全存储在第二缓冲区202b中。
28.因此,第二用户数据204ba的第二部分存储在第三缓冲区202c中。第二元数据206b被顺序地存储在第二用户数据204ba的第二部分之后。同样,由于第三缓冲区202c具有约4kb的大小,因此第三用户数据204c的第一部分存储在第三缓冲区202c中,并且第三用户数据204ca的第二部分存储在第四缓冲区202d中。第三元数据206c在第三用户数据204ca的第二部分之后顺序地存储在第四缓冲区202d中。
29.当数据按顺序从第一数据传输到最后的数据时,往来于主机设备的传输可以是无缝的。然而,在无序数据传输期间,数据存储设备可能需要传输第二用户数据204b、204ba和第二元数据206b,而不是第一用户数据204a和第一元数据206a。当无序传输数据时,通过pcie总线发出与未对齐传输相关联的未优化数据包。此外,当传输第一用户数据204a和第一元数据206a时,数据存储设备发出用于从第二缓冲区202b传输第一元数据206a的未优化数据包,而没有第二用户数据204b的第一部分。
30.图3是根据一个实施方案的存储系统300的示意图。存储系统300包括与数据存储设备的设备控制器304交互的主机设备302。例如,主机设备302可以使用nand 326,或者在一些实施方案中使用包括在数据存储设备中的非易失性存储器来存储和检索数据。在一些示例中,存储系统300可以包括可作为存储阵列工作的多个数据存储设备。例如,存储系统300可以包括多个数据存储设备,其被配置成共同用作主机设备302的大容量存储设备的廉价/独立磁盘(raid)冗余阵列。
31.设备控制器304包括主机接口模块(him)306、数据路径312、纠错码(ecc)模块314、一个或多个处理器318、闪存接口模块(fim)316和动态随机存取存储器(ram)控制器320。动态ram(dram)控制器320与包括每个命令的用户数据高速缓存缓冲区324的dram 322交互。在本文的描述中,出于示例性目的,每个命令的用户数据高速缓存缓冲区324可被称为高速缓存缓冲区324。
32.在一些实施方案中,dram控制器320可以是与sram交互的静态ram(sram)控制器。fim 316可以被配置为对来自nand 326中的位置的数据的存储和检索进行调度。该一个或多个处理器可以被配置为生成并执行系统命令以存储、访问nand 326的数据并对其执行操作。ecc模块314可以为nand 326中存储的用户数据生成ecc数据,其中ecc数据可以是与用户数据相关联的元数据的一部分。
33.当主机设备302向设备控制器304发送读/写命令时,him 306接收读/写命令。him 306包括pcie 308和nvme 310。pcie 308和nvme 310可被配置为根据相应协议进行操作。例如,每个缓冲区(诸如图2的缓冲区202a、202b、202c、202d)的大小由主机设备203在初始化阶段进行配置。在一些实施方案中,缓冲区的大小为约4kb、8kb、16kb、32kb等。应当理解,列出的大小并非旨在限制,而是提供可能的实施方案的示例。当数据传输大小满足公式n*mps(其中n是整数值)并且第一缓冲区的地址与mps对齐(例如,pcie地址%mps=0)时,数据传输可被认为是对齐的。当数据传输不满足公式n*mps或者第一缓冲区的地址不与mps对齐时,数据传输可被认为是未对齐的。当存在元数据时,不满足这两个条件。虽然元数据很小(例如,16字节),但元数据导致未对齐。
34.对齐的传输绕过高速缓存(即,缓冲区),并且可根据先前的方法与主机设备302直接交互。更具体地讲,数据由nand感测,并且数据的准备就绪状态可能不按顺序。考虑到上述示例,lba b可能首先准备就绪。在这种情况下,应首先传输lba b以及元数据b。对于该特定块,数据存储设备基于pcie mps参数确定对齐的和未对齐的块。与pcie mps完全对齐的块将绕过高速缓存,而未对齐的区与高速缓存进行交互。换句话讲,当对齐传输的大小等于由主机设备203在初始化阶段配置的pcie参数的mps时,数据传输绕过高速缓存。然而,未对齐的传输被归类为可缓存数据。未对齐的传输被传输到dram控制器320,其中dram控制器将未对齐的传输存储到dram 322的高速缓存缓冲区324。对于每个未完成命令,高速缓存缓冲区324的已分配缓冲区存储空间被分配给未完成命令。
35.为了更好地理解数据存储设备如何处理对齐的和未对齐的传输,针对具有以下参数的系统提供以下示例:存储器页面大小为4kb,lba为4lb,元数据大小为16字节,并且pcie mps为512字节。对于主机命令,主机提供主机写入命令(pcie读取流)。命令大小为3个lba。第一缓冲区具有4kb的大小,第二缓冲区具有4kb的大小,第三缓冲区具有4kb的大小,并且第四缓冲区具有4kb的大小,但仅48字节是有效的。3个lba的总传输大小将为3x(lba大小+
元数据大小)=12kb+48字节。当数据存储设备决定首先传输第二lba时,第二缓冲区将是第一需要的缓冲区。因此,由于第二缓冲区的4kb大小减去为第一lba的元数据预留的16字节,第二缓冲区将具有4kb-16字节的可用性。因此,为了传输第二lba,也需要下一个缓冲区(即,第三缓冲区)来保存第二lba的尾部(即,16字节)以及第二lba元数据(即,16字节)。换句话讲,下一个缓冲区(即,第三缓冲区)需要16字节用于第二lba。
36.定义哪些缓冲区与pcie mps对齐可在继续上述存在用于传输的9个缓冲区的示例的情况下发生。第一缓冲区具有512-16字节(即496字节)的大小。第二缓冲区至第八缓冲区具有512字节的大小。第九缓冲区具有32字节的大小。因此,第一缓冲区和第九缓冲区未对齐,而第二缓冲区至第八缓冲区是对齐的。因此,第一缓冲区和第九缓冲区与高速缓存进行交互,同时第一缓冲区和第九缓冲区将被保存在高速缓存中。因此,数据存储设备将如下对齐:第一个对齐的缓冲区将是具有512字节的第二缓冲区,并且具有512字节的第三缓冲区将是最后一个对齐的缓冲区。所需数据由控制器使用,而额外数据存储在两个高速缓存缓冲区中并且将在需要时使用。在传输第一lba和第三lba时将需要这两个高速缓存缓冲区,因为在那些场景中将存在高速缓存命中。
37.在pcie读取流期间,逻辑块地址和请求的大小与mps对齐。由设备控制器304向主机设备302发出与mps的大小对齐的传输。当返回的数据超过对齐请求的mps时,返回的数据(即,扩展的lba)被存储在dram 322的高速缓存缓冲区324的被分配的高速缓存缓冲区存储空间中。将读取命令的请求数据返回到主机设备302,同时将剩余数据存储在高速缓存缓冲区324的被分配的高速缓存缓冲区存储空间中。当接收到用于剩余数据的另一个读取命令时,将剩余数据从高速缓存缓冲区324的被分配的高速缓存缓冲区存储空间直接返回到主机设备302。然而,在pcie写入流期间,未对齐的数据被写入高速缓存缓冲区324。当与未对齐数据相关联的剩余数据被写入高速缓存缓冲区324时,高速缓存缓冲区324被刷新到主机设备302。
38.图4是示出根据一个实施方案的写入命令处理的方法400的流程图。图3的存储系统300的各方面可类似于本文所述的实施方案。在框402处,设备控制器(诸如图3的设备控制器304)接收内部主机(诸如图3的主机设备302)读取请求(即,数据存储设备写入命令)。读取请求的最大大小等于最大读取请求大小(mrrs)pcie参数的值。在框404处,控制器确定从主机请求的读取是否为高速缓存命中。高速缓存命中是指存储在高速缓存(诸如图3的高速缓存缓冲区324)中的来自先前读取请求的数据。如果在框404处存在高速缓存命中,则在框406处,从高速缓存读取数据。
39.然而,如果在框404处不存在高速缓存命中,则在框408处,控制器确定从主机请求的读取是否具有高速缓存行粒度。高速缓存行粒度是指读取是与mps对齐还是不与mps对齐。如果在框408处读取具有高速缓存行粒度,则在框410处,将读取确定为非可缓存请求,并且在绕过高速缓存时将与读取请求相关联的数据直接传输到主机设备。
40.如果在框408处从主机请求的读取不具有高速缓存行粒度,则在框412处,控制器在考虑写入命令的属性时请求与高速缓存行对齐。首先通过扩展请求同时保持写入命令边界来将请求地址和大小与mps对齐。在框414处,分配高速缓存缓冲区。在框416处,将对齐的请求传输至主机设备。在框418处,返回的数据被存储在高速缓存缓冲区中,同时在框420处将相关数据传输到主机设备。当设备控制器接收到读取高速缓存行的另一部分的请求时,
可稍后传输存储在高速缓存缓冲区中的剩余数据。当接收到读取高速缓存行的另一部分的请求时,控制器在框404处确定高速缓存命中,并且将从高速缓存缓冲区读取相关数据。
41.图5是示出根据一个实施方案的读取命令处理的方法500的流程图。图3的存储系统300的各方面可类似于本文所述的实施方案。在框502处,设备控制器(诸如图3的设备控制器304)接收内部主机(诸如图3的主机设备302)写入请求(即,数据存储设备读取命令)。写入请求的最大大小等于mps pcie参数的值。在框504处,控制器确定是否存在高速缓存命中,其中高速缓存命中是指确定与写入请求相关的数据是否存储在高速缓存缓冲区(诸如图3的高速缓存缓冲区324)中。
42.如果在框504处存在高速缓存命中,则在框506处,将数据写入高速缓存,其中将数据写入高速缓存是指将相关数据从高速缓存读取到主机设备。然而,如果在框504处不存在高速缓存命中,则在框508处,控制器确定写入请求是否具有高速缓存行粒度。如果在框508处写入请求具有高速缓存行粒度,则控制器在框510处确定写入请求是非可缓存请求,并且写入请求直接与主机进行交互。然而,如果在框508处写入请求不具有高速缓存行粒度,则在框512处分配高速缓存缓冲区。当写入请求不具有高速缓存行粒度时,则主机请求被认为是未对齐的。在框514处,将写入请求的数据写入高速缓存缓冲区。当高速缓存缓冲区被完全填充或读取命令完成时,高速缓存缓冲区的数据被刷新到主机设备。
43.图6a和6b是示出根据多个实施方案的高速缓存刷新的方法600、650的流程图。高速缓存刷新的方法600开始于框602处,其中控制器接收向主机设备发布完成条目的请求,诸如当图4的写入命令或图5的读取命令完成时。在框604处,设备控制器用完成的命令刷新相关高速缓存缓冲区,并且在框606处,将高速缓存缓冲区释放到可用于被分配以存储高速缓存数据的高速缓存缓冲区池。在框608处,设备控制器向主机设备发布完成条目。在框610处,设备控制器在启用时向主机断言中断。
44.高速缓存刷新的方法650可以是高速缓存刷新的任选方法。在框652处,数据存储设备已完全访问特定高速缓存缓冲区,而非在框604处刷新与命令相关联的所有高速缓存缓冲区。在框654处,设备控制器刷新与特定高速缓存行相关联的高速缓存条目缓冲区。在框656处,释放高速缓存缓冲区。与方法600不同,其中整个高速缓存缓冲区被刷新和释放,方法650可另选地刷新和释放特定高速缓存缓冲区。在框656处完成步骤之后,方法650可返回到框608处的方法600。
45.通过将高速缓存缓冲区存储用于未对齐的主机请求,仅通过pcie总线递送优化的数据包,这提高了数据存储设备的总体性能。
46.在一个实施方案中,一种数据存储设备包括:一个或多个存储器设备;和控制器,该控制器耦接到该一个或多个存储器设备,其中该控制器被配置为:接收来自主机请求的读取;确定该来自主机请求的读取超过最大有效载荷大小(mps);将该请求的地址和大小与该mps对齐以创建对齐的请求;为该来自主机请求的读取分配高速缓存缓冲区存储空间;将该对齐的请求发送至主机设备;接收超过该对齐的请求的该mps的返回数据;以及将该返回数据存储在所分配的高速缓存中。该控制器被进一步配置为将该返回数据从所分配的高速缓存存储空间递送到该一个或多个存储器设备。该控制器被进一步配置为请求来自所分配的高速缓存缓冲区存储空间的该返回数据。该返回数据响应于该请求递送到该一个或多个存储器设备。该控制器被进一步配置为确定该来自主机请求的读取是否为高速缓存命中。
该控制器被进一步配置为当该来自主机请求的读取为高速缓存命中时从所分配的高速缓存读取数据。该控制器被进一步配置为确定该来自主机请求的读取是否为高速缓存行粒度。该控制器被进一步配置为当确定该来自主机请求的读取为高速缓存行粒度时,在不使用该高速缓存缓冲区存储的情况下处理该来自主机请求的读取。
47.在另一个实施方案中,一种数据存储设备包括:一个或多个存储器设备;接口模块;和控制器,该控制器耦接到该一个或多个存储器设备,其中该控制器被配置为:通过该接口模块接收主机请求;确定该主机请求未对齐;以及从高速缓存检索数据。该主机请求是对主机请求的写入。该控制器被进一步配置为确定该主机请求是否为高速缓存命中。该控制器被进一步配置为响应于确定该主机请求为高速缓存命中而将数据写入该高速缓存。该控制器被进一步配置为确定在该主机请求中是否存在高速缓存行粒度。该控制器被进一步配置为在确定存在高速缓存行粒度时与该主机直接交互。该控制器被进一步配置为分配高速缓存缓冲区存储并将数据写入所分配的高速缓存缓冲区存储。该控制器还包括耦接到该接口模块的随机存取存储器(ram)控制器。该数据存储设备还包括耦接到该ram控制器的ram设备,其中该高速缓存在该ram设备中。
48.在另一个实施方案中,一种数据存储设备包括:一个或多个存储器设备;用于确定来自主机设备的未对齐的访问请求的接口装置;以及控制器,该控制器耦接到该一个或多个存储器设备。该数据存储设备还包括:用于接收将完成条目发布到该主机设备的请求的装置;以及用于刷新与命令相关联的所有高速缓存缓冲区并将完成条目发布到该主机设备的装置。该数据存储设备还包括:用于释放相关高速缓存缓冲区的装置;以及用于将完成条目发布到该主机设备的装置。
49.虽然前述内容针对本公开的实施方案,但是可以在不脱离本公开的基本范围的情况下设想本公开的其他和另外的实施方案,并且本公开的范围由所附权利要求书确定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1