一种自动驾驶系统、装置及方法与流程
1.本发明属于人工智能技术领域,特别涉及一种自动驾驶系统、装置及方法。
背景技术:
2.随着新一代信息技术与制造技术的深度融合,汽车正由传统的机械产品逐步演变为机电一体化、智能化和网联化的高科技产品,呈现出与电子、信息、交通等相关技术产业紧密相连、协同发展的趋势。
3.智能网联汽车,亦或是自动驾驶汽车,与智能交通系统深度交叉融合,因此在行驶中感知周围路况是需要解决的基本问题。
技术实现要素:
4.本发明实施例之一,一种自动驾驶系统,该系统通过机器视觉对环境路况场景进行三维重建,从而获得路况三维图像信息,用于驾驶判断和决策。所述机器视觉通过单目相机或摄像机获取环境路况图像。所述的环境路况图像通过输入经过训练的卷积神经网络模型重建所述环境路况的三维图像模型。
附图说明
5.通过参考附图阅读下文的详细描述,本发明示例性实施方式的上述以及其他目的、特征和优点将变得易于理解。在附图中,以示例性而非限制性的方式示出了本发明的若干实施方式,其中:
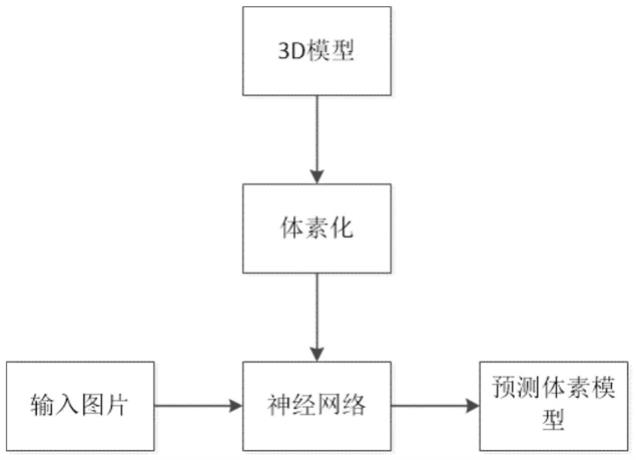
6.图1根据本发明实施例之一的自动驾驶图像三维重建原理示意图。
7.图2根据本发明实施例之一的卷积神经网络原理示意图。
具体实施方式
8.目前对于行驶道路环境的感知,存在2种技术路线,即激光雷达或者是视觉感知图像摄取摄像头。激光雷达感知技术是以激光雷达为主导,间或以毫米波雷达、超声波传感器及摄像头作为辅助。激光雷达感知环境的工作原理,是通过激光雷达发射激光束,测量激光在发射及收回过程其中的时间差、相位差,来确定车与物体之间的相对距离,实现环境实时感知及避障功能。
9.激光雷达具有较长的探测距离与较高的精准度,抗干扰能力强,可以主动检测周围多物体环境,获取周围环境点云构建3d环境模型。即使夜间光线不好,也不会影响探测效果。虽然激光雷达不怕暗光,但是对于天气敏感,雨雪、沙尘、大雾天气等会影响激光雷达识别效果。同时,在可预见的时间内,激光雷达的价格会始终处于高位,从而阻碍激光雷达的迅速应用。
10.视觉感知是以摄像头为主导的方案,摄像头成本相较激光雷达优势极大,再者摄像头技术逐渐成熟,高分辨率、高帧率成像技术使得感知的环境信息更为丰富,但摄像头在
光线复杂黑暗环境中感知受限,精度及安全性会有所下降。由于在视觉感知中,三维重建可帮助自动驾驶汽车辅助识别环境路况,因此三维重建的范围、精度、实时性都很重要。然而,现有的三维重建算法,识别不准确,能够构建范围小,重构速度不够快,重构细节部分效果不理想。
11.现有的三维重建技术,基于sfm的运动恢复结构,基于深度学习的深度估计和结构重建,以及基于rgb
‑
d深度摄像头的三维重建。用于车辆自动驾驶,存在效果和成本方面的问题。
12.通常,运动恢复结构(structure
‑
from
‑
motion,简称sfm)是一种能够从多张图像或视频序列中自动地恢复出相机的参数以及场景三维结构。sfm(structure from motion),主要基于多视觉几何原理,用于从运动中实现3d重建,可以从无时间序列的2d图像中推算三维信息。
13.根据一个或者多个实施例,如图1所示,一种自动驾驶系统,通过机器视觉对环境路况场景进行三维重建,从而获得路况三维图像信息,用于驾驶判断和决策。该机器视觉通过单目相机或摄像机获取环境路况图像,所述的环境路况图像通过输入经过训练的卷积神经网络模型重建所述环境路况的三维图像模型。
14.所述卷积神经网络模型的训练过程包括,将多幅行驶环境路况三维图像样本,进行体素化处理后输入卷积神经网络,用以对所述卷积神经网络的训练。
15.体素化(voxelization)是将物体的几何形式表示转换成最接近该物体的体素表示形式,产生体数据集,其不仅包含模型的表面信息,而且能描述模型的内部属性。包括对模型表面、模型内部的体素化。
16.对模型表面的体素化,首先计算出模型的aabb包围盒,然后根据空间分辨率对包围盒进行划分,得到每个大小为(x/n)*(y/n)*(z/n)空间像素列表。然后对构成3d模型的多边形或三角形列表进行遍历,得到这些基本体元所对就应的包围盒,然后由aabb求交运算得到这些基本体元所能影响到的体素单元,将这些体素单元做为待判断的基本对象。为了做进一步的精确判定,使用三角形与aabb的求交算法确定这些基本体元所能影响到最终体素,并将这些体素标记为非空,这样就完成了对3d模型表面的体素化操作。
17.对模型内部的体素化,将模型表面体素化的操作进行完之后即可得到对模型体素表示的一个“外壳”,接下来要做的操作就是进行模型的内部体素化操作。其中,首先将对应的3d模型建立空间八叉树,这棵八叉树主要用于进行基本体元面片的求交操作。然后对模型aabb中的所有空体素,从其中心位置以轴对齐方向来发射两条射线,这两条射线的方向相反,但基本方向都是轴对齐的。对于这两条的射线利用空间模型的八叉树来得到其与3d模型的相交位置,并得到相交点的法向量及到相交点的距离,然后根据这两点法向量之间的关系来判断得到当前体素是在3d模型的内部或是在3d模型的外部。将这样的操作施加于每一个空的体素之后就可以完成对3d模型内部的体素化操作。
18.本发明实施例采用可实用单目相机图像三维重建的算法,达到了智能网联汽车对于自动驾驶中的环境路况的判断要求。通过采用神经网络模型,使用三维路况图像作为输入,将3d模型体素化用以训练神经网络。通过做场景重建,解决定位不准问题。同时,通过神经网络拟合标签信息,使得系统达到一定的鲁棒性。在实际自动驾驶过程中,通过输入单目路况图片,通过经过训练的神经网络输出体素3d模型供系统做出驾驶控制判断。
19.根据一个或者多个实施例,一种自动驾驶判断方法,通过机器视觉对环境路况场景进行三维重建,从而获得路况三维图像信息,用于驾驶判断和决策,所述机器视觉通过单目相机或摄像机获取环境路况图像。
20.所述的环境路况图像通过输入经过训练的卷积神经网络模型重建所述环境路况的三维图像模型。
21.所述卷积神经网络模型的训练过程包括,将多幅行驶环境路况三维图像样本,进行体素化处理后输入卷积神经网络,用以对所述卷积神经网络的训练。
22.可见,本发明的技术效果包括:
23.1.使用单个相机重构自动驾驶汽车前方环境路况图像的三维特征;2.扩大了感知范围;
24.3.提升感知数据的可信度和精确度;
25.4.通过重建道路前方三维信息,实现对路面和障碍物的识别。
26.值得说明的是,虽然前述内容已经参考若干具体实施方式描述了本发明创造的精神和原理,但是应该理解,本发明并不限于所公开的具体实施方式,对各方面的划分也不意味着这些方面中的特征不能组合,这种划分仅是为了表述的方便。本发明旨在涵盖所附权利要求的精神和范围内所包括的各种修改和等同布置。
技术特征:
1.一种自动驾驶系统,其特征在于,该系统通过机器视觉对环境路况场景进行三维重建,从而获得路况三维图像信息,用于驾驶判断和决策。2.根据权利要求1所述的自动驾驶系统,其特征在于,所述机器视觉通过单目相机或摄像机获取环境路况图像。3.根据权利要求2所述的自动驾驶系统,其特征在于,所述的环境路况图像通过输入经过训练的深度学习模型重建所述环境路况的三维图像模型。4.根据权利要求3所述的自动驾驶系统,其特征在于,所述深度学习模型为卷积神经网络模型。5.根据权利要求4所述的自动驾驶系统,其特征在于,所述卷积神经网络模型的训练过程包括,将多幅行驶环境路况三维图像样本,进行体素化处理后输入卷积神经网络,用以对所述卷积神经网络的训练。6.根据权利要求1所述的自动驾驶系统,其特征在于,使用激光雷达作为对机器视觉的辅助判断。7.根据权利要求6所述的自动驾驶系统,其特征在于,该系统还包括毫米波雷达、超声波传感器作为机器视觉的辅助判断。8.一种自动驾驶判断装置,其特征在于,所述装置包括存储器;以及耦合到所述存储器的处理器,该处理器被配置为执行存储在所述存储器中的指令,所述处理器执行以下操作:通过机器视觉对环境路况场景进行三维重建,从而获得路况三维图像信息,用于驾驶判断和决策,所述机器视觉通过单目相机或摄像机获取环境路况图像。9.一种自动驾驶判断方法,其特征在于,通过机器视觉对环境路况场景进行三维重建,从而获得路况三维图像信息,用于驾驶判断和决策,所述机器视觉通过单目相机或摄像机获取环境路况图像。10.一种存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时,实现如权利要求9的方法。
技术总结
一种自动驾驶系统,该系统通过机器视觉对环境路况场景进行三维重建,从而获得路况三维图像信息,用于驾驶判断和决策。所述机器视觉通过单目相机或摄像机获取环境路况图像。所述的环境路况图像通过输入经过训练的深度学习模型重建所述环境路况的三维图像模型。模型重建所述环境路况的三维图像模型。模型重建所述环境路况的三维图像模型。
技术研发人员:张宇超 秦超
受保护的技术使用者:上海智能网联汽车技术中心有限公司
技术研发日:2021.08.30
技术公布日:2021/11/5
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1