一种基于语法糖解析的一键式代码混淆方法与流程
1.本发明涉及软件开发技术领域,尤其涉及一种基于语法糖解析的一键式代码混淆方法。
背景技术:
2.代码混淆(obfuscation)是将计算机程序的代码,转换成功能上等价,但是难于阅读和理解的形式的行为。代码混淆可以用于程序源代码,也可以用于程序编译而成的中间代码。执行代码混淆的程序被称作代码混淆器。目前已经存在许多种功能各异的代码混淆器。
3.其主要工作有:
4.1、将代码中的各种元素,如变量、函数、类的名字改写成无意义的名字。比如改写成单个字母,或是简短的无意义字母组合,甚至改写成“__”这样的符号,使得阅读的人无法根据名字猜测其用途。
5.2、重写代码中的部分逻辑,将其变成功能上等价、但是更难理解的形式。比如将for循环改写成while循环、将循环改写成递归、精简中间变量,等等。
6.3、打乱代码的格式。比如删除空格、将多行代码挤到一行中、或者将一行代码断成多行等等。
7.4、添加花指令,通过特殊构造的指令来使得反汇编器出错,进而干扰反编译工作的进行。
8.代码混淆器也会带来一些问题。主要的问题包括:
9.1、被混淆的代码难于理解,因此调试也变得困难起来。开发人员通常需要保留原始的未混淆的代码用于调试。
10.2、对于支持反射的语言,代码混淆有可能与反射发生冲突。
11.3、代码混淆并不能真正阻止反向工程,只能增大其难度。因此,对于对安全性要求很高的场合,仅仅使用代码混淆并不能保证源代码的安全。
12.实际应用中,问题2会导致混淆后的程序对语法糖支持不完整,影响正常运行,目前也有一些解决方案:
13.1:针对不同系统的代码,用到的相关语法糖各有区别,可针对不同系统或模块,分别设置混淆参数,忽略无法兼容的语法。
14.2:基于开源方案扩展,主动适配用到的语法糖,实现起来难度较高,且需要随语法更新及时更新混淆工具。
15.由于上述方案2实现难度大,成本不可控,目前采用较多的是方案1,其特点在于:
16.1、可解决混淆后程序无法正常运行的问题,但会增加代码工程的复杂度。
17.2、编译期配置调整工作量较多,因为不同代码模块存在的混淆兼容性问题各有不同。
18.3、运行期验证工作较多,很多兼容性问题要在运行期测试才能发现。
19.综上,代码混淆工作存在编译期调整和运行期验证两部分可控性较差的投入。
20.针对以上缺点,本发明希望通过知识复用和调整测试过程工具化的方法提升代码混淆工作量的可控程度和混淆输出物的可靠性。
技术实现要素:
21.有鉴于现有技术的上述缺陷,本发明所要解决的技术问题是如何提升代码混淆工作量的可控程度和混淆输出物的可靠性。
22.为实现上述目的,本发明提供了一种基于语法糖解析的一键式代码混淆方法,其特征在于,包括以下步骤:
23.步骤1、初始化;
24.步骤2、代码提取;
25.步骤3、语法糖过滤;
26.步骤4、混淆配置生成;
27.步骤5、代码混淆;
28.步骤6、运行测试。
29.进一步地,所述步骤1是指分析使用的代码混淆工具,得出非兼容语法清单,记录到配置文件。
30.进一步地,所述配置文件若初始为空,可在后续环节逐步填充该文件。
31.进一步地,所述步骤2是指从源码文件读取源码内容,并进行结构化解析,获取代码清单。
32.进一步地,所述步骤3是指遍历所述代码清单,逐个比对所述非兼容语法清单中是否包含当前代码单元,如果包含,保留当前代码单元并传递到步骤4,否则丢弃。
33.进一步地,所述步骤4是指遍历步骤3过滤后的所述代码清单,对其中每一项进行忽略配置,最终生成混淆配置参数集合。
34.进一步地,所述步骤5按照步骤4生成的所述混淆配置参数集合,执行代码混淆,生成程序包。
35.进一步地,所述步骤6测试混淆后的所述程序包,得出测试结果,如有异常,排查原因,如无异常,测试通过,所述程序包可用。
36.进一步地,所述测试结果如发现新的非兼容语法,存入所述非兼容语法清单。
37.进一步地,所述代码单元包括类、代码文件和函数。
38.本发明可有效改进现有代码混淆工具的兼容性和混淆后程序运行的稳定性。由于采用了自动化的语法糖解析和非兼容语法库积累,本发明具有较高的易用性,可实现一键式代码混淆。
39.以下将结合附图对本发明的构思、具体结构及产生的技术效果作进一步说明,以充分地了解本发明的目的、特征和效果。
附图说明
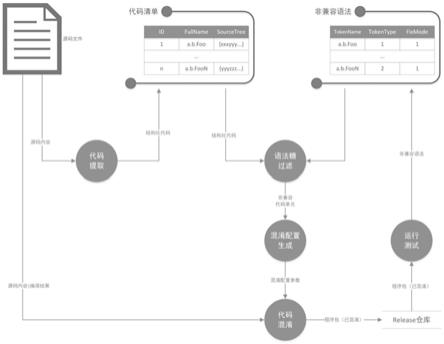
40.图1是本发明的一个较佳实施例的一种基于语法糖解析的一键式代码混淆方法的数据流图。
具体实施方式
41.以下参考说明书附图介绍本发明的多个优选实施例,使其技术内容更加清楚和便于理解。本发明可以通过许多不同形式的实施例来得以体现,本发明的保护范围并非仅限于文中提到的实施例。
42.在附图中,结构相同的部件以相同数字标号表示,各处结构或功能相似的组件以相似数字标号表示。附图所示的每一组件的尺寸和厚度是任意示出的,本发明并没有限定每个组件的尺寸和厚度。为了使图示更清晰,附图中有些地方适当夸大了部件的厚度。
43.如图1所示,初始化:分析使用的代码混淆工具,得出非兼容语法清单,记录到配置文件。以java语言为例,比如springbootapplication等注解在某些混淆工具中不能被兼容,可以直接记录到配置文件。
44.代码提取:从源码文件读取源码内容,并进行结构化解析,获取代码清单。
45.参考伪代码如下:
[0046][0047]
语法糖过滤:遍历上一步得到的代码清单,逐个比对非兼容语法清单中是否包含当前代码单元(类、代码文件、函数等),如果包含,保留当前代码单元并传递到下一步,否则丢弃。
[0048]
参考伪代码如下:
[0049][0050]
混淆配置生成:遍历上一步过滤后的代码清单,对其中每一项进行忽略配置,最终
生成混淆配置参数集合。
[0051]
参考伪代码如下:
[0052][0053]
代码混淆:按照上一步生成的混淆配置,执行代码混淆,生成程序包。
[0054]
参考伪代码如下:
[0055]
sh build.sh input/xxx.jar
[0056]
运行测试:测试混淆后的程序包,如有异常,排查原因,如发现新的非兼容语法,存入非兼容语法清单。如无异常,测试通过,混淆程序包可用。
[0057]
以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术无需创造性劳动就可以根据本发明的构思作出诸多修改和变化。因此,凡本技术领域中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。
技术特征:
1.一种基于语法糖解析的一键式代码混淆方法,其特征在于,包括以下步骤:步骤1、初始化;步骤2、代码提取;步骤3、语法糖过滤;步骤4、混淆配置生成;步骤5、代码混淆;步骤6、运行测试。2.如权利要求1所述的一种基于语法糖解析的一键式代码混淆方法,其特征在于,所述步骤1是指分析使用的代码混淆工具,得出非兼容语法清单,记录到配置文件。3.如权利要求2所述的一种基于语法糖解析的一键式代码混淆方法,其特征在于,所述配置文件若初始为空,可在后续环节逐步填充该文件。4.如权利要求3所述的一种基于语法糖解析的一键式代码混淆方法,其特征在于,所述步骤2是指从源码文件读取源码内容,并进行结构化解析,获取代码清单。5.如权利要求4所述的一种基于语法糖解析的一键式代码混淆方法,其特征在于,所述步骤3是指遍历所述代码清单,逐个比对所述非兼容语法清单中是否包含当前代码单元,如果包含,保留当前代码单元并传递到步骤4,否则丢弃。6.如权利要求5所述的一种基于语法糖解析的一键式代码混淆方法,其特征在于,所述步骤4是指遍历步骤3过滤后的所述代码清单,对其中每一项进行忽略配置,最终生成混淆配置参数集合。7.如权利要求6所述的一种基于语法糖解析的一键式代码混淆方法,其特征在于,所述步骤5按照步骤4生成的所述混淆配置参数集合,执行代码混淆,生成程序包。8.如权利要求7所述的一种基于语法糖解析的一键式代码混淆方法,其特征在于,所述步骤6测试混淆后的所述程序包,得出测试结果,如有异常,排查原因,如无异常,测试通过,所述程序包可用。9.如权利要求8所述的一种基于语法糖解析的一键式代码混淆方法,其特征在于,所述测试结果如发现新的非兼容语法,存入所述非兼容语法清单。10.如权利要求9所述的一种基于语法糖解析的一键式代码混淆方法,其特征在于,所述代码单元包括类、代码文件和函数。
技术总结
本发明公开了一种基于语法糖解析的一键式代码混淆方法,涉及软件开发技术领域,包括以下步骤:(1)初始化;(2)代码提取;(3)语法糖过滤;(4)混淆配置生成;(5)代码混淆;(6)运行测试。本发明使其自动适配现有混淆工具的语法兼容问题,从而以较低成本实现关键代码的有效保护。保护。保护。
技术研发人员:孙新河 张登 张宇杰
受保护的技术使用者:上海熙菱信息技术有限公司
技术研发日:2021.09.10
技术公布日:2021/12/6
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1