一种提升Flink实时计算框架数据处理效率的方法与流程
一种提升flink实时计算框架数据处理效率的方法
技术领域
1.本发明涉及大数据实时计算处理领域,特别涉及一种提升flink实时计算框架数据处理效率的方法。
背景技术:
2.flink是业界具有低处理时延、高吞吐量、精确一次性语义的分布式实时计算框架,可以处理多种数据源中的数据,目前最常用的数据源是kafka消息中间件;
3.根据kafka数据源分区数量及flinksourcetask数量,其处理模型分别如下:
4.(a)kafkapartitions==flinkparallelism,一个flinktask实例读取一个kafka分区数据,如图3所示;
5.(b)kafkapartitions《flinkparallelism,一个flinktask实例读取一个kafka分区数据,多余的flinktask4实例将处于空闲,如图4所示;
6.(c)kafkapartitions》flinkparallelism,部分flinktask实例将处理多个kafka区数据,如图5所示;对于场景b,flink读取数据时task4实例处于空闲状态导致该部分资源未能充分利用。而在实际的业务处理中,为了达到更高的处理吞吐量及低时延,一般会分配较多的物理资源,这也造成了flink在数据源读取阶段存在较多的cpu浪费。
技术实现要素:
7.本发明要解决的技术问题是克服现有技术的缺陷,提供一种提升flink实时计算框架数据处理效率的方法。
8.本发明提供了如下的技术方案:
9.本发明提供一种提升flink实时计算框架数据处理效率的方法,包括以下步骤:
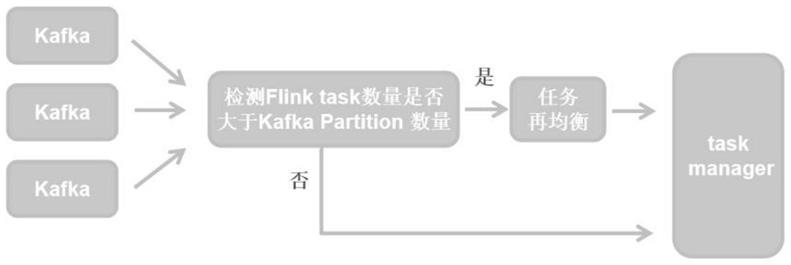
10.s1.检测kafka分区个数是否大于flink申请task实例个数;
11.s2.flinktask任务再均衡优化;
12.通过flink任务再均衡方法,可以显著提高实时计算的吞吐量并降低端到端的处理时延,避免flink在数据处理阶段存在较多的cpu浪费;以下将对每个步骤的实现过程做详细说明:
13.(1)flinkjobmanager获取待读取kafka分区信息及flink任务并行度;
14.(2)若kafkapartitions《=flinkparallelism,flink按模型a,c处理;否则进入步骤(3);
15.(3)对预读取的kafka分区按待处理数据量大小进行排序,并计算分区数据量中位数及每个分区数据量与中位数的比值n(不够整数则向上取整数);
16.(4)对于每个kafka分区预分配一个flinktask,保证至少有一个task去处理对应分区的数据;
17.(5)对于剩余的flinktask实例,按数值n划分给对应的kafka分区。
18.与现有技术相比,本发明的有益效果如下:
19.1.本案解决了现有flinkstreaming实时计算框架中在处理数据过程中遇到的部分task实例空闲,造成cpu资源浪费的问题;
20.2.通过检测kafka分区个数是否大于flink申请task实例个数,并对出现task实例空闲的情况进行任务再均衡优化,显著提高了资源利用率,进而增加了系统处理吞吐量、降低处理时延。
附图说明
21.附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
22.图1是本发明的框架图;
23.图2是本发明的实施例示意图;
24.图3是本发明的flink模型a示意图;
25.图4是本发明的flink模型b示意图;
26.图5是本发明的flink模型c示意图。
具体实施方式
27.以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。其中附图中相同的标号全部指的是相同的部件。
28.实施例1
29.如图1-5,本发明提供一种提升flink实时计算框架数据处理效率的方法,包括以下步骤:
30.s1.检测kafka分区个数是否大于flink申请task实例个数;
31.s2.flinktask任务再均衡优化;
32.通过flink任务再均衡方法,可以显著提高实时计算的吞吐量并降低端到端的处理时延,避免flink在数据处理阶段存在较多的cpu浪费;以下将对每个步骤的实现过程做详细说明:
33.(1)flinkjobmanager获取待读取kafka分区信息及flink任务并行度;
34.(2)若kafkapartitions《=flinkparallelism,flink按模型a,c处理;如图3和图5所示,否则进入步骤(3);
35.(3)对预读取的kafka分区按待处理数据量大小进行排序,并计算分区数据量中位数及每个分区数据量与中位数的比值n(不够整数则向上取整数);
36.(4)对于每个kafka分区预分配一个flinktask,保证至少有一个task去处理对应分区的数据;
37.(5)对于剩余的flinktask实例,按数值n划分给对应的kafka分区。
38.进一步的,举例说明,如图2所示:
39.kafka分区数量为3,数据量分别为
40.partition1=4,partition2=2,partition3=1
41.则中位数为2,各分区数据量与中位数的比值n(向上取整数):
[0042][0043]
首先各分区预分配一个flinktask,剩余的3个task按n分配,如下
[0044]
partition1=1+2=3 partition2=1+1=2
[0045]
partition3=1。
[0046]
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
技术特征:
1.一种提升flink实时计算框架数据处理效率的方法,其特征在于,包括以下步骤:s1.检测kafka分区个数是否大于flink申请task实例个数;s2.flink task任务再均衡优化;通过flink任务再均衡方法,可以显著提高实时计算的吞吐量并降低端到端的处理时延,避免flink在数据处理阶段存在较多的cpu浪费;以下将对每个步骤的实现过程做详细说明:(1)flink jobmanager获取待读取kafka分区信息及flink任务并行度;(2)若kafka partitions<=flink parallelism,flink按模型a,c处理;否则进入步骤(3);(3)对预读取的kafka分区按待处理数据量大小进行排序,并计算分区数据量中位数及每个分区数据量与中位数的比值n(不够整数则向上取整数);(4)对于每个kafka分区预分配一个flink task,保证至少有一个task去处理对应分区的数据;(5)对于剩余的flink task实例,按数值n划分给对应的kafka分区。
技术总结
本发明公开了一种提升Flink实时计算框架数据处理效率的方法,包括以下步骤:S1.检测Kafka分区个数是否大于flink申请task实例个数;S2.Flink task任务再均衡优化;通过Flink任务再均衡方法,可以显著提高实时计算的吞吐量并降低端到端的处理时延,避免flink在数据处理阶段存在较多的cpu浪费;以下将对每个步骤的实现过程做详细说明。本发明解决了现有Flink Streaming实时计算框架中在处理数据过程中遇到的部分task实例空闲,造成CPU资源浪费的问题;通过检测Kafka分区个数是否大于flink申请task实例个数,并对出现task实例空闲的情况进行任务再均衡优化,显著提高了资源利用率,进而增加了系统处理吞吐量、降低处理时延。时延。时延。
技术研发人员:张璐波 王全福 谢巍盛
受保护的技术使用者:天翼电子商务有限公司
技术研发日:2021.12.06
技术公布日:2022/4/22
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1