基于骨骼肌知识图谱的医疗自动问答方法与流程
1.本发明涉及一种人体骨骼运动康复模型构建方法,尤其涉及一种基于骨骼肌知识 图谱的医疗自动问答方法。
背景技术:
2.目前在运动康复领域,按照专业能力进行分类,可大致分为专业(职业)人群、 高水平爱好者、普通爱好者、普通人群按身体年龄状况可分为残疾人群、亚健康人 群、中老年人群等。在众多运动损伤和疾病中,仅非特异性腰痛(nonspecific low backpain,nlbp)这种病例在2016年因该病造成病人身体健康寿命受损达到了5760万人/ 年。而目前国内的专业康复师和医生的数量有限,但需求人群巨大。非医疗康复专 业人士在查询人体骨骼肌相关知识(主要是运动康复方面),如果不是在咨询专业医 生或者运动康复专业人士的情况下,将更多依赖于互联网搜索引擎去寻找相关知识, 需要在较多杂乱的信息中去筛选出有价值的信息,这样存在效率较低下且不准确的 问题。
3.目前已有的医疗康复方面的知识图谱,大都基于传统方法进行构建:比如2013 年dao等人尝试用语义匹配建立基于互联网的人体骨骼肌搜索引擎;2018年gyrard 等人提出基于个人的健康知识图谱;2018年马浩晨等基于规则的关系抽取建立了甲 状腺知识图谱;2020年付洋等建立了基于规则和相似度的心脏病病知识图谱;2020 翟兴等建立了基于模板匹配和相似度计算的智能养生的知识图谱;2020年尤欢欢等 人建立了基于骨科疾病的知识图谱;但是都存在效率较低、人工成本较高的问题。 对于知识图谱医疗问答应用也普遍存在匹配精度不高,需要人工辅助判断的问题, 大大影响了用户的使用体验。
技术实现要素:
4.本发明所要解决的技术问题是提供一种基于骨骼肌知识图谱的医疗自动问答方 法,能够针对用户输入问题精准选出最为匹配的答案,有效降低人工判断工作量, 方便专业人士实现快速查询某块骨骼肌基本信息和相应的测试或康复方案,实现不 用去医院也能够获得良好的预诊断。
5.本发明为解决上述技术问题而采用的技术方案是提供一种基于骨骼肌知识图谱 的医疗自动问答方法,包括如下步骤:s1、构建人体骨骼运动知识图谱;s2、将构 建的人体骨骼运动知识图谱作为一个知识库进行实体链接;s3、通过用户输入问题, 将语义问题与人体骨骼肌知识图谱中的实体、关系进行匹配,推理得出答案。
6.进一步地,所述步骤s1包括:s11、获取人体骨骼运动相关的结构化、半结构 化和非结构化数据;s12、利用预训练模型对获取数据中的词语进行分布式表示;s13、 通过实体关系联合抽取模型对数据进行实体、关系和属性抽取,完成人体骨骼运动 知识图谱的搭建。
7.进一步地,所述步骤s11利用scrapy对网页进行爬取获取人体骨骼运动相关 的数据,或者通过书籍和医生康复师人工获取结构化数据;所述步骤s12在对数据 进行文本表
示之前先进行如下数据预处理和数据增强处理:对于得到的非结构化数 据中的文本信息,按照信息抽取模型的标注模式进行标注,并将标注的文本作为训 练集、验证集和测试集;通过人工构造的方式扩充数据量进行数据增强,扩充方式 包括:原文扩充、随机截断、字符替换、随机翻转、同性词替换以及预训练模型输 出替换;所述步骤s13利用基于深度学习的端到端的joint模型对数据进行实体、 关系和属性抽取,并在tplinker模型的基础上增加了属性识别,然后利用tplinker 模型将joint实体关系提取任务转换为token对的连接关系。
8.进一步地,所述步骤s13通过token链接矩阵的标记方案来提取所有实体和重 叠关系,具体包括:
9.设置实体头部-实体尾部链接eh-et:用于表示一个实体的开始和终止token;
10.设置主体头部-目标头部链接sh-oh:用于表示同一关系的两个实体的开始 token;
11.设置主体尾部-目标尾部链接st-ot:用于表示同一关系的两个实体的结束 token;
12.对每个关系进行一次标记,如果有n个关系则解析成2n+1的序列标记子任务 了,每一个子任务的长度为n为输入的句子长度;
13.从实体头部-实体尾部链接eh-et中提取所有实体,并通过字典将每个头部位 置映射到相应到实体;然后开始进行解码,对于每个关系st-ot确定头实体的尾部 和尾实体的尾部,将其添加到集合e中;接着以sh-oh序列查找字典d中头部位 置开始的所有可能实体;最后开始迭代检查所有候选实体是否在集合e中,如果在 则直接提取三元组放入集合t中。
14.进一步地,所述步骤s13中人体骨骼运动知识图谱以人体关节为节点建立对应 的关节肌群以及关节肌肉功能;所述人体关节的节点类型包括身体部位、关节肌群、 肌肉、骨骼、筋膜、韧带、神经、关节、软骨、肌肉功能、肌肉功能测试、肌肉群、 肌肉伸展测试、肌腱、器官、皮肤、关节囊、部位和动作;所述人体关节的节点属 性包括:临床意义、名字、特别属性、状态、神经延展性测试说明、等级、简介、 肌肉延展测试说明、英文和说明,所述人体关节的关系属性包括:位置、动作指令、 备注、测试方法、状态、短头位置、结论、说明、起始姿势和长头位置。
15.进一步地,所述步骤s2中知识库包含一个实体集合e;每一个从互联网上获 取的数据中抽取出来的实体,均为实体集合e的潜在提及对象;所述步骤s2将每个 实体提及对象m∈m匹配对应到目标实体e∈e;如果在实际计算中集合e不包含m 的目标实体,则将m链接到一个候选实体,并将候选实体作为新的目标实体补充到 原有实体库。
16.进一步地,所述步骤s2采取基于图卷积网络的模型,利用图卷积网络来对局 部上下文和全局一致性信息进行建模实现知识图谱中的实体对齐,具体通过如下函 数计算为候选实体寻找一个最优分配:
17.18.为输出候选实体的变量;p()为概率函数,为拓扑图的归一化邻接矩阵,f为 候选实体的特征表示;
[0019][0020]
f()是在参数ω下的一个映射函数,其利用编码器、子图卷积网络和解码器来获得 该映射函数。
[0021]
进一步地,所述步骤s3通过识别问题语句的语义确定查询关系,将问题和实体 进行嵌入获得其稠密向量表示,并在候选知识图谱中进行相关匹配,获得匹配知识 后将相应节点关系嵌入后获得其稠密向量表示,并计算问题和候选答案的匹配度。
[0022]
进一步地,所述步骤s3包括:采用预训练模型提取问题特征,将获取的单个词 向量进行相加得到对应句子的向量表示;使用transe系列模型将答案实体向量化; 使用多列卷积网络,提取三个特征向量作为答案的三个维度,分别为答案的路径、 答案的上下文信息和答案的类型。
[0023]
进一步地,针对不同的答案特征(实体,关系,类型,上下文),所述步骤s3 采用得分函数s(q,a)度量问题和候选答案之间的关联程度;对于答案i的分布式表达 为:
[0024]gi
(a)∈{ge(a),gr(a),g
t
(a),gc(a)}
[0025]
ge(a),gr(a),g
t
(a),gc(a)分别表示实体向量,关系向量,类型向量和上下文向量;
[0026]
对于问题i中的第j个词的词向量,对应问题的分布式表达记为:
[0027][0028]aij
为句子i对于词j的注意力权重;
[0029]
将最终的得分函数设为问题与答案的点积和:
[0030][0031]
采用hinge-loss作为其损失函数。
[0032]
本发明对比现有技术有如下的有益效果:本发明提供的基于骨骼肌知识图谱的 医疗自动问答方法,能够针对用户输入问题精准选出最为匹配的答案,有效降低人 工判断工作量,方便专业人士实现快速查询某块骨骼肌基本信息和相应的测试或康 复方案,实现不用去医院也能够获得良好的预诊断。
附图说明
[0033]
图1为信息抽取一般流程图;
[0034]
图2为传统实体连接一般方法流程图;
[0035]
图3为本发明使用的深度学习的命名实体识别流程图;
[0036]
图4为本发明使用的基于深度学习的端到端的joint模型;
[0037]
图5为本发明获取人体骨骼运动相关数据示意图;
[0038]
图6为本发明使用爬虫获取互联网数据示意图;
[0039]
图7为本发明采用bert_base_chinese、roberta-wwm-ext、ernie作为知识表 示的预训练模型;
roberta-wwm-ext、ernie作为知识表示的预训练模型。bert的框架如图7所示,其 采用双向transfomer的encoder结构,基于中文的维基百科作为相关语料进行预训 练。
[0081]
roberta-wwm-ext是由哈工大和讯飞联合发布的预训练模型、采用了动态mask 和更多的训练数据。
[0082]
ernie是由百度发布的基于百度贴吧等语料进行预训练的模型。采用了词语级别 的mask。
[0083]
在对数据进行文本表示之前先进性数据预处理和数据增强,具体步骤如下。
[0084]
1)对于得到的非结构化数据处理;
[0085]
2)对文本按照信息抽取模型的标注模式进行标注
[0086]
将标注的文本作为训练集、验证集和测试集。
[0087]
3)通过人工构造的方式扩充数据量达到数据增强的效果弥补标注数据量稀少问 题。
[0088]
常见的扩充方法如下表数据增强方法所示:
[0089]
扩充方法示例原文股直肌属于股四头肌随机截断股直肌与股四头肌[unk]字符替换股直肌属于[unk][unk][unk][unk]随机翻转股直肌属于股头肌四同性词替换股直肌属于臀大肌预训练模型输出替换股直肌属于大腿前侧肌肉
[0090]
三、知识图谱搭建
[0091]
本发明通过实体关系联合抽取模型对数据进行实体、关系和属性抽取。
[0092]
利用多头指针标注方案(tplinker)的联合抽取方法和基于关系注意力机制的 联合抽取方法进行实体和关系抽取。利用多头指针标注方案(tplinker)的联合抽 取方法进行属性抽取。
[0093]
(1)通过tplinker模型进行实体、关系和属性抽取
[0094]
因为在医学实体中,实体重叠率较高,tplinker模型在实体重叠的句子中识别率 较高。拟采用实体识别和关系识别联合模型:tplinker,并且在原模型的基础上增 加了属性识别。
[0095]
下面先介绍原始模型,该模型解决了之前的模型偏移曝光问题(exposure bias): 训练时每一次接受的是上一时刻的真实值和输入,在测试时每次接受的是上一时刻 的预测值和输入。tplinker将joint实体关系提取任务转换为token对的连接问题。 在一个句子中两个位置分别为p1,p2和一个明确的关系r。该模型需要回答以下三 个问题“p1和p2是否为同一个实体的开始和结尾位置”,“p1和p2是否为关系r的 两个实体的起始位置”,“p1和p2是否为关系r的两个实体的结束位置”,该模型设 计了一种token链接矩阵的标记方案,通过该方法能够提取所有实体和重叠关系。其 显著提高了在正常句子,单个实体重复句子(single entity overlap,seo)和实体 对重复(entity pair overlap,epo)和多关系提取的性能。该模型提出的握手标记方 案(handshaking tagging scheme)给出了三种链接定义:实体头部-实体尾部(entityheadto entity tail,eh-et):一个实体的开始和终止
token、主体头部-目标头部(subjecthead to object head,sh-oh):同一关系的两个实体的开始token、主体尾部-目标尾部 (subject tail to object tail,st-ot):同一关系的两个实体的结束token。为了节省储 存空间,将左下角矩阵(稀疏矩阵)进行上卷,其中右下角的tag有1变为2以区分 顺序。
[0096]
但是这个方案无法解决epo问题。为了解决这个问题就对每个关系进行一次标 记如图8所示。如果有n个关系那么该任务就被解析成2n+1的序列标记子任务了。 其中每一个子任务有的长度,n为输入的句子长度,如图8中例子n=2,n=14, 一共有5个子任务,每个子任务长度为91。在eh-et中有3个tag为1,他们代表 实体的有三个分别为《股四头肌》,《股直肌》,《屈髋》。在关系“协同”中,sh-oh中 有2个tag为1,eh-et有2个tag为1,基于这三个序列的tag可以联解出《股四头 肌,协同,屈髋》,《股直肌,协同,屈髋》。同理在关系“属于”中,sh-oh和st-ot 中分别有1个tag为2。联合eh-et可得关系《股直肌,属于,股四头肌》。
[0097]
算法总结为在开始从eh-et中提取所有实体,并通过字典d将每个头部位置映 射到相应的实体。然后开始进行解码,对于每个关系st-ot确定头实体的尾部和尾 实体的尾部,将其添加到集合e中,然后以sh-oh序列查找字典d中头部位置开 始的所有可能实体。然后开始迭代检查所有候选实体是否在集合e中,如果在则直 接提取三元组放入集合t中。
[0098]
对于token对表示具体过程如下:一个长为n的句子[w1,w2,
…
,wn]将每个tokenwi通过编码映射到一个低维的上下文向量hi。然后生成[wi,wj]token对的对应表示向量 h
i,j
计算公式为:
[0099]hi,j
=tanh(wh·
[hi;hj]+bh),j≥i
[0100]
其中wh为参数矩阵,bh为偏移向量这两个参数都可以在训练中进行学习。该公式也 是图7中的“handshaking kernel”。对于eh-et,sh-oh和st-ot的标记在该模 型中使用的是一个统一框架。公式为:
[0101]
p(yi,j)=softmax(wo·hi,j
+bo)
[0102][0103]
其中p(yi,j)表示将(wi,wj)识别为l的概率密度。其损失函数为:
[0104][0105]
n为输入的句子长度,是真实的标签,e,h和t表示eh-et,sh-oh和st-ot 的标签。
[0106]
(2)根据对模型结构调整提高模型识别实体和关系抽取准确率。
[0107]
除了对文本进行实体和关系的抽取还需要对实体进行属性抽取,对于不同类别 的实体具有不同的属性,并且属性的结构也不同,有的属性可能是词语级别,有的 可能是句子级别,有的可能是文档级别。那么对于属性的提取同样引入标记符号: 实体属性头部-实体属性尾部(entity attribute head to entity attribute tail,eah-eat)、 实体头部-实体属性头部(entity head to entity attribute head,eh-eah)、实体尾部-实体属性尾部(entity tail to entity attribute tail,et-eat)。对于eh-eah和et-eat 部分可以属性在前实体在后所以tag可以为2。属性在文本为顺序所以tag只能为1。 将其转化为
tplinker框架如图9和图10所示,假如实体共有m种属性(属性可为 空值)那么子任务将由原模型中的2n+1,变成了2m+2n+2。子任务的长度不变仍为 属性tag的计算方法和原模型关系和实体tag计算方式相同。如果进行关系 属性提取定义关系属性类别为k类,任务变为2k+2m+2n+3个子任务。
[0108]
(3)通过基于关系注意力机制网络的实体关系抽取方案进行实体关系抽取
[0109]
使用基于关系门的信息抽取模型。该模型通过使用关系注意力机制使得能够通过 关系门在一个文本中对不同关系进行提取。该模型的embedding层使用词嵌入、词 性嵌入和字符嵌入。通过将字符对应id、词对应id和词性对应id,先转换为低维向 量再通过一维卷积和全连接层获取输入的词向量输入enconder,encoder结构如图 11所示。enconder层输入向量通过一个双向lstm输出的隐向量记为h1,h2,
…hn
,n 为输出隐向量个数。
[0110][0111]dhe
为bilstm的隐状态。
[0112]
sc={h1,...,hn}用来表示文本上下文句子特征。
[0113]
通过对隐向量取平均池化得到sg。
[0114]
sg=avg{h1,h2,
…
,hn}
[0115]
并定义关系向量rk。通过两个全连接层获得关系向量。
[0116]
计算sk,其计算公式为:
[0117]eik
=v
t
tanh(wrrk+wgsg+whhi)
[0118][0119][0120]
w1,w2,w3,b1,b2,b3为参数,theta为sigmoid函数。
[0121]
deconder结构如图12所示,其输入uk计算公式为:
[0122][0123][0124]
通过将encoder输入的隐向量和uk进行拼接输入双向lstm,然后通过softmax 输出。
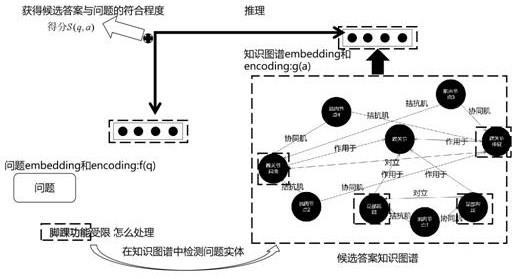
[0125]
本发明通过对标注数据进行预处理,生成两种方案。
[0126]
方案一:按照原模型中构建对应的word2id和re2id的对应字典,并且通过lac 对文本进行词性标注获得其pos2id对应字典。按照该模型进行训练计算。lac词性 如下表所示。
[0127]
标签含义标签含义标签含义标签含义n普通名词f方位名词s处所名词nw作品名nz其他专名v普通动词vd动副词vn名动词
a形容词ad副形词an名形词d副词m数量词q量词r代词p介词c连词u助词xc其他虚词w标点符号per人名loc地名org机构名time时间
[0128]
方案二:通过预训练模型获得相应词向量进行输入。在预训练模型选择上,选择 roberta_base还有bert。通过预训练模型获得词向量输入enconder和deconder进行训 练计算。
[0129]
通过以上三种方法:tplinker和基于关系注意力机制的实体关系抽取模型(分 布式表示用原模型方法和用预训练模型)可以获得实体和对应关系。因为在各个模 型中对于不同的实体类别:单个实体重复(singleentityoverlap,seo)和实体对重 复(entitypairoverlap,epo)。具体如下表所示。
[0130][0131]
本发明的人体骨骼肌知识图谱的构建是以人体关节为节点建立了对应的关节肌 群以及关节肌肉功能和其拮抗肌和协同肌,实现了对人体骨骼肌系统的细节划分, 如图13所示。
[0132]
1.协同肌:又叫合作肌,指在完成特定动作时,除发生收缩的主动肌以外,其 他协作完成这一动作的肌肉。
[0133]
2.拮抗肌:又叫对抗肌,指在主动技收缩完成动作的过程中,位于运动轴对侧 的发生松弛或生长的肌肉。
[0134]
节点类型目前如下表所示。
[0135][0136][0137]
节点属性包括:临床意义、名字、特别属性、状态、神经延展性测试说明、等 级、简介、肌肉延展测试说明、英文、说明。节点属性用于对个节点进行补充说明。
[0138]
本发明知识图谱的关系类型如下表所示:
[0139][0140]
关系属性包括:位置、动作指令、备注、测试方法、状态、短头位置、结论、 说明、起始姿势、长头位置。
[0141]
最终完成的知识图谱的数据可以通过写好的python文档、利用py2neo库将3.4.1 中得到的实体、关系、属性自动构建在neo4j数据库中并存于云端。
[0142]
构建好人体骨骼运动知识图谱后,就可以将其作为一个知识库进行实体链接
[0143]
将人工搭建的知识图谱当作一个知识库,该知识库包含一个实体集合e;本发 明从互联网上获取的大量数据并抽取出来的实体,本发明认为都是与实体集合e的 潜在提及对象,记该集合为m;任务目的是将每个实体提及m∈m到其对应的无歧 义的目标实体e∈e。如果在实际计算中集合e不包含m的目标实体,则将m链接 到一个新的实体(作为原有实体库的补充)。在具体模型选用上本发明采取基于图卷 积网络的模型,其利用图卷积网络来对局部上下文和全局一致性信息进行建模。通 过函数计算寻找为候选实体寻找一个最优
分配。
[0144][0145]
为输出候选实体的变量;p()为概率函数,为拓扑图的归一化邻接矩阵,f为候选 实体的特征表示。
[0146][0147]
f()是在参数ω下的一个映射函数。其利用编码器、子图卷积网络和解码器来获得该 映射函数。
[0148]
本发明医疗问答应用时主要包含实体链接和关系推理两个部分:
[0149]
实体链接:通过命名实体识别将问题中的实体进行提取对应的话题实体;通过 实体消歧确定实体在人体骨骼肌知识图谱中对应的实体。
[0150]
关系推理:将语义问题与人体骨骼肌知识图谱中的关系进行匹配。通过识别问 题语句的语义确定查询关系,根据骨骼肌知识图谱中已有关系和其对应的三元组进 行匹配或进行多条查询再进行匹配等联合推理得出答案。
[0151]
主要流程为:通过用户输入问题,将问题和实体进行嵌入获得其稠密向量表示, 并在候选知识图谱中进行相关匹配,获得匹配知识后将相应节点关系嵌入后获得其 稠密向量表示,并计算问题和候选答案的匹配度,通过模型选出最为匹配的答案; 如图14所示。
[0152]
本发明的自动问答方法有两个关键点:
[0153]
1、如何将问题和答案映射到一个低维稠密的向量空间,并且在讲问题和答案进行 映射时也需要将知识图谱中的知识进行映射。
[0154]
对于问题的映射方法,可以选取bert等预训练模型作为问题特征的提取。将获 取的单个词向量进行相加得到对应句子的向量表示,该方法能够有效对词性和顺序 进行识别,比如“小明的父亲是谁”和“小明是谁的父亲”如果使用word2vec等向 量表示方法是不能有效识别两个问题的区别。
[0155]
对于候选答案的映射,可以使用transe系列模型将答案实体向量化,这里举一 个transr模型,模型结构如图15所示。其建立实体空间和关系空间,将实体投影 到关系空间中。其表达式为:hmr+r≈tmr但是不同的实体投影应该有不同的转换方 式。
[0156]
同时为了提高模型性能,也可以引入额外的信息,比如使用多列卷积网络,提 取三个特征向量,分别表示答案的三个维度,分别为答案的路径、答案的上下文信 息和答案的类型。
[0157]
2、如何度量问题和候选答案之间的关联程度,即对图14中的得分函数s(q,a) 进行设计。
[0158]
对于得分函数s(q,a)的设计可以引入注意力机制,针对不同的答案特征(实体, 关系,类型,上下文)分别有不同的表达。比如对于答案i的分布式表达为:
[0159]gi
(a)∈{ge(a),gr(a),g
t
(a),gc(a)}
[0160]
ge(a),gr(a),g
t
(a),gc(a)分别表示实体向量,关系向量,类型向量和上下文向量。 对于问题i中的第j个词的词向量(bert的输出hj)那么对应问题的分布式表达可以 记为:
[0161][0162]aij
为句子i对于词j的注意力权重。
[0163]
将最终的得分函数定义为问题与答案的点积和。
[0164][0165]
采用hinge-loss作为其损失函数。
[0166]
该模型方法几乎不需要任何人工定义的特征,也不会需要借助额外的系统;模型不 会受知识库的缺失限制(可以通过transe的方法预测三元组)。
[0167]
虽然本发明已以较佳实施例揭示如上,然其并非用以限定本发明,任何本领域 技术人员,在不脱离本发明的精神和范围内,当可作些许的修改和完善,因此本发 明的保护范围当以权利要求书所界定的为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1