基于transformer结构的softmax函数量化实现方法和装置与流程
1.本发明涉及神经网络技术领域,特别涉及一种基于transformer结构的softmax函数量化实现方法和装置。
背景技术:
2.基于自注意力机制的翻译模型transformer没有使用cnn和rnn的方法和模块,而是开创性的将注意力机制作为编解码器的核心构建执行翻译操作。
3.参见图1,图1是现有技术transformer结构示意图,如图1所示,transformer结构中依次包括:用于对transformer结构的输入参数q(query,请求)和k(key,主键)进行矩阵相乘运算的matmul模块、用于对上述matmul模块的输出数据进行按比缩放的scale模块、用于对scale模块的部分输出数据进行屏蔽的mask(opt.)模块、用于对mask(opt.)模块的输出数据执行softmax运算的softmax模块、以及用于将softmax模块的输出数据与transformer结构的输入参数v(value,数值)相乘的matmul模块。可以看出,在transformer结构中softmax模块的运算之前是matmul模块的运算,softmax模块的运算实质上是对matmul模块运算后输出的矩阵逐行进行运算。
4.softmax模块对输入矩阵的每行数据统一量化时共用一个scale,然而,由于输入矩阵中行与行之间数据分布不平衡,实际scale (一行数据中的最大值与最小值的差值)差异会比较大,会出现因量化误差而导致两行数据的量化结果一致的情况,例如[41.45, 42.15, 42.84, 43.89] 和 [40.81, 41.93, 43.36, 44.27]被量化后得到相同的量化结果[41, 42, 43, 44](scale=1),导致量化精度不高。
技术实现要素:
[0005]
有鉴于此,本发明的目的在于提供了一种基于transformer结构的softmax函数量化实现方法和装置,计算简单,且能够有效提高量化精度。
[0006]
为了达到上述目的,本发明提供了如下技术方案:一种基于transformer结构的softmax函数量化实现方法,应用于transformer结构中的softmax模块,包括:获取transformer结构中的matmul模块传送的输入矩阵;根据预先为transformer结构配置的全局共享指数映射表的输入数据位宽,对从matmul模块传送到softmax模块的输入矩阵中的每行输入数据进行数据调整,得到该行输入数据的调整数据;对每行输入数据的调整数据进行截断处理,得到该行输入数据的截断数据;查找所述全局共享指数映射表确定每行输入数据的截断数据对应的指数映射数据;将每行输入数据的截断数据对应的指数映射数据相加,得到该行输入数据对应的指数映射数据总和;
根据预先为transformer结构配置的全局共享倒数映射函数确定每行输入数据对应的指数映射数据总和的倒数映射值;对每行输入数据的截断数据对应的指数映射数据与该行输入数据对应的指数映射数据总和的倒数映射值进行乘法运算和移位运算,得到该行输入数据对应的最终结果;将所述最终结果输出到softmax模块所属神经网络层的后一神经网络层。
[0007]
一种基于transformer结构的softmax函数量化实现装置,应用于transformer结构中的softmax模块,包括:获取单元,用于获取transformer结构中的matmul模块传送的输入矩阵;调整单元,用于根据预先为transformer结构配置的全局共享指数映射表的输入数据位宽,对从matmul模块传送到softmax模块的输入矩阵中的每行输入数据进行数据调整,得到该行输入数据的调整数据;对每行输入数据的调整数据进行截断处理,得到该行输入数据的截断数据;指数单元,用于查找所述全局共享指数映射表确定每行输入数据的截断数据对应的指数映射数据;求和单元,用于将每行输入数据的截断数据对应的指数映射数据相加,得到该行输入数据对应的指数映射数据总和;倒数单元,用于根据预先为transformer结构配置的全局共享倒数映射函数确定每行输入数据对应的指数映射数据总和的倒数映射值;乘法单元,用于对每行输入数据的截断数据对应的指数映射数据与该行输入数据对应的指数映射数据总和的倒数映射值进行乘法运算和移位运算,得到该行输入数据对应的最终结果;输出单元,用于将所述最终结果输出到softmax模块所属神经网络层的后一神经网络层。
[0008]
由上面的技术方案可知,本发明中,对transformer结构中从matmul模块传送到softmax模块的输入矩阵中的每行输入数据进行数据调整和截断处理后,采用预先为transformer结构配置的全局共享的指数映射表和倒数映射函数实现指数运算和倒数运算,计算简单,且可以解决从matmul模块传送到softmax模块的输入矩阵中不同行之间的数据分布不均衡而导致的量化精度不高的问题,能够有效提高量化精度。
附图说明
[0009]
为了更清楚地说明本技术实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
[0010]
图1是现有技术transformer结构示意图;图2是本发明实施例提供的transformer结构中softmax模块的运算过程示意图;图3是本发明实施例一基于transformer结构的softmax函数量化实现方法流程图;图4是本发明实施例二基于transformer结构的softmax函数量化实现方法流程
图;图5是本发明实施例softmax模块的输入数据分解示意图;图6是现有技术exp指数函数图像示意图;图7是本发明实施例三基于transformer结构的softmax函数量化实现方法流程图;图8是本发明实施例pipeline方式示意图;图9是本发明实施例基于transformer结构的softmax函数量化实现装置的结构示意图。
具体实施方式
[0011]
下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
[0012]
本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”、“第三”、“第四”等(如果存在)是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本发明的实施例例如能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含。例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其他步骤或单元。
[0013]
下面以具体实施例对本发明的技术方案进行详细说明。下面几个具体实施例可以相互结合,对于相同或相似的概念或过程可能在某些实施例不再赘述。
[0014]
本发明中,预先为transformer结构配置全局共享的指数映射表和倒数映射函数,使得transformer结构中的softmax模块可以利用全局共享的指数映射表和倒数映射函数实现指数运算和倒数运算,计算简单,能够减少硬件资源消耗,降低功耗;而且还可以解决从matmul模块传送到softmax模块的输入矩阵中不同行之间的数据分布不一致而导致的量化精度不高的问题,能够有效提高量化精度。
[0015]
图2是本发明实施例提供的transformer结构中softmax模块的运算过程示意图,如图2所示,假设从transformer结构中的matmul模块传送到softmax模块的输入矩阵的每行输入数据中包括n+1个输入数据,则对从matmul模块传送到softmax模块的输入矩阵的第i+1行输入数据[x
i0
,
……
,x
in
]的运算过程如下:步骤1、确定该行输入数据[x
i0
,
……
,x
in
]中的最大值max;本实施例中,softmax模块的输入数据位宽已经在图2中标示,是i_bits,一般取值为16bits。
[0016]
步骤2、将该行输入数据[x
i0
,
……
,x
in
]中的每个输入数据减去该行输入数据中的最大值max后再加上offset(调整值)得到调整数据,再对调整数据进行截断处理,得到该行输入数据的截断数据[x
′
i0
,
……
,x
′
in
]。
[0017]
步骤3、根据全局共享指数映射表(glut-exp)确定该行输入数据的截断数据
[x
′
i0
,
……
,x
′
in
]对应的指数映射数据[q
i0
,
……
,q
in
];本实施例中,全局共享指数映射表的输入数据位宽t_bits和输出数据位宽e_bits已经在图2中标示,其中,t_bits的取值一般为8bits,e_bits的取值一般为8bits,也可以根据需要适当调高e_bits的取值。
[0018]
步骤4、将该行输入数据的截断数据对应的指数映射数据[q
i0
,
……
,q
in
]相加,得到该行输入数据对应的指数映射数据总和sum=q
i0
+q
i1
+
……
+q
in
。
[0019]
步骤5、根据全局共享的指数映射函数(glut-1/q)确定该行输入数据对应的倒数映射值;本实施例中,全局共享指数映射函数的输出数据位宽已经在图2中标示,是r_bits,一般取值为16bits,也可以根据需要适当调整r_bits的取值。
[0020]
步骤6、将该行输入数据的截断数据对应的指数映射数据 [q
i0
,
……
,q
in
]与该行输入数据对应的指数映射数据总和的倒数映射值进行乘法运算,在对乘法运算结果进行移位运算得到该行输入数据对应的最终结果[y
i0
,
……
,y
in
]。
[0021]
本实施例中,softmax模块的输出数据位宽已经在图2中标示,是o_bits,一般取值为8bits,o_bits的取值可以提高至16bits,但是这样做会提高整个网络消耗的带宽。
[0022]
本技术的输入数据位宽可以是16bit,实现方案精度比较高,可以适应各种场景。例如,目标分类,目标监测等。
[0023]
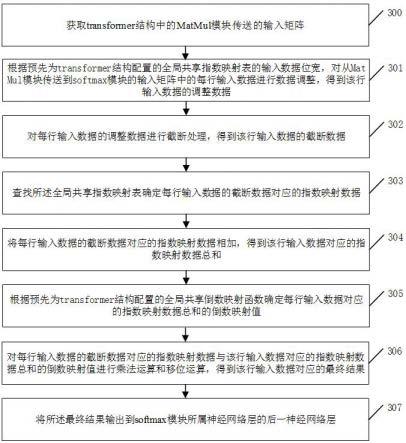
以下结合具体的实施例对本发明提供的基于transformer结构的softmax函数量化实现方法进行详细说明:参见图3,图3是本发明实施例一基于transformer结构的softmax函数量化实现方法流程图,该方法应用于transformer结构中的softmax模块,如图3所示,该方法主要包括以下步骤:步骤300、获取transformer结构中的matmul模块传送的输入矩阵;步骤301、根据预先为transformer结构配置的全局共享指数映射表的输入数据位宽,对从matmul模块传送到softmax模块的输入矩阵中的每行输入数据进行数据调整,得到该行输入数据的调整数据;步骤302、对每行输入数据的调整数据进行截断处理,得到该行输入数据的截断数据;步骤303、查找所述全局共享指数映射表确定每行输入数据的截断数据对应的指数映射数据;步骤304、将每行输入数据的截断数据对应的指数映射数据相加,得到该行输入数据对应的指数映射数据总和;步骤305、根据预先为transformer结构配置的全局共享倒数映射函数确定每行输入数据对应的指数映射数据总和的倒数映射值;步骤306、对每行输入数据的截断数据对应的指数映射数据与该行输入数据对应的指数映射数据总和的倒数映射值进行乘法运算和移位运算,得到该行输入数据对应的最终结果;步骤307、将所述最终结果输出到softmax模块所属神经网络层的后一神经网络层。
[0024]
从图3所示方法可以看出,本实施例中,对transformer结构中从matmul模块传送到softmax模块的输入矩阵中的每行输入数据进行数据调整和截断处理后,采用预先为transformer结构配置的全局共享的指数映射表和倒数映射函数实现指数运算和倒数运算,简化了计算过程,能够减少硬件资源消耗,降低功耗,且可以解决从matmul模块传送到softmax模块的输入矩阵中不同行之间的数据分布和数据精度不一致的问题,能够有效提高量化精度。
[0025]
参见图4,图4是本发明实施例二基于transformer结构的softmax函数量化实现方法流程图,该方法应用于transformer结构中的softmax模块,如图4所示,该方法主要包括以下步骤:步骤400、获取transformer结构中的matmul模块传送的输入矩阵;步骤4011、对从matmul模块传送到softmax模块的输入矩阵中的每行输入数据执行以下操作步骤4012至步骤4013:步骤4012、确定该行输入数据中的最大值,并根据预先为transformer结构配置的全局共享指数映射表的输入数据位宽确定一调整值;本实施例中,全局共享指数映射表的输入数据位宽t_bits的具体取值,可以是8bits。
[0026]
本实施例中,根据所述全局共享指数映射表的输入数据位宽t_bits确定一调整offset,具体可以采用以下公式实现:offset=(1《《t_bits)-1,例如,当t_bits=8时,可以根据上述公式计算确定offset=255。
[0027]
步骤4013、针对该行输入数据中的每一输入数据,计算该输入数据与所述最大值的差值,利用所述调整值对该差值进行调整,得到该输入数据的调整数据;本实施例中,利用所述调整值对该差值进行调整,具体是将该差值加上所述调整值。
[0028]
本实施例中,对于第i+1行输入数据中的每一输入数据x
ij
(j=0、1、2、
……
、n),计算该输入数据与所述最大值的差值,利用所述调整值对该差值进行调整,得到该输入数据的调整数据x
′
ij
,具体可以采用以下公式实现:x
′
ij
=x
ij-max+offset。
[0029]
本实施例中,该行输入数据中的所有输入数据的调整数据构成该行输入数据对应的调整数据。
[0030]
以上步骤4011至步骤4013是图3所示步骤301的具体细化。
[0031]
步骤402、针对每行输入数据中的每一输入数据,如果该输入数据的调整数据小于0,则将该输入数据的调整数据截断为0后作为该输入数据的截断数据,否则,将该输入数据的调整数据作为该输入数据的截断数据;本实施例中,softmax模块的输入数据位宽i_bits可以是16bits。16bits的输入数据,可以分解为三部分,如图5所示,第一部分为符号位,包括1bit,第二部分和第三部分分别为整数位和小数位,共占用15bits,其中,小数位占用的bit数越多,则相应表示的精度越高,但是整数的表示能力下降。
[0032]
在实际应用中,exp指数函数的值下降比较快,如图6所示,exp(-7)的值已经很小,基本可以忽略不计,因此,只要softmax模块的输入数据中的最大值和最小值的差值保持在7左右即可。
[0033]
因此,在本实施例中,在计算该输入数据与所述最大值的差值,并利用所述调整值对该差值进行调整得到该输入数据的调整数据之后,可以继续通过对该输入数据的调整数据进行截断处理得到该输入数据的截断数据,使得该输入数据的截断数据只保留3bits整数位,保证截断数据中的最大值和最小值的差值保持在7左右。另外,本实施例中,小数位的位数可以根据精度需求预先设定,例如小数位的位数可以是5bits、6bits、或7bits。
[0034]
本实施例中,通过将每个输入数据x
ij
进行调整和截断处理得到x
′
ij
, x
′
ij
的取值范围为[0, offset],以t_bits=8为例,x
′
ij
的取值范围为[0, 255]。
[0035]
以上步骤402是图3所示步骤302的具体细化。
[0036]
步骤403、查找所述全局共享指数映射表确定每行输入数据的截断数据对应的指数映射数据;本实施例中,所述全局共享指数映射表可以根据预先设定的定点量化后可表示的最小刻度s、所述共享指数映射表的输入数据位宽t_bits和输出数据位宽e_bits生成,包括1《《t_bits个表项,占用的存储空间为(1《《t_bits)
×
e_bits
÷
8字节,“《《”为左移运算符。其中,s的取值可以预先根据精度需求设定的小数位的位数k进行设定, k为正整数,s=1/2k。例如,当小数位的位数是5时,s的取值是1/32;小数位的位数是6时,s的取值是1/64;小数位的位数是7时,s的取值是1/128。
[0037]
本实施例中,全局共享指数映射表的具体生成方法,具体可以是:对softmax模块的输入数据x
ij
的截断数据x
′
ij
的取值范围[0,offset]内的每一个整数值u,采用以下公式计算其对应的指数映射值v:v=round(exp((u-offset)
×
s)
×
((1《《e_bits)
ꢀ‑
1)),其中函数round(x)用于对括号内的值x进行四舍五入计算。通过该计算公式,可以计算得到offset个u到v的映射关系,这些映射关系就构成了全局共享指数映射表。
[0038]
步骤404、将每行输入数据的截断数据对应的指数映射数据相加,得到该行输入数据对应的指数映射数据总和;本实施例中,假设第i+1行输入数据包括n+1个输入数据,其中的第j个输入数据x
ij
的调整数据x
′
ij
对应的指数映射数据为q
ij
,则第i+1行输入数据对应的指数映射数据总和为sum=q
i0
+q
i1
+
……
+q
in
。
[0039]
步骤405、根据预先transformer结构配置的全局共享倒数映射函数确定每行输入数据对应的指数映射数据总和的倒数映射值;本实施例中,所述全局共享倒数映射函数可以根据预设函数生成的倒数映射表、对预设函数进行线性拟合得到的一次函数、或者对预设函数进行多项式拟合生成的多项式函数;其中,所述预设函数为f(x)=2
r_bits
/x,x的取值范围为预设取值区间,较佳地,所述预设取值区间为[256, 512),其中r_bits是所述倒数映射函数的输出数据位宽,通常取值为16bit。
[0040]
步骤406、对每行输入数据的截断数据对应的指数映射数据与该行输入数据对应的指数映射数据总和的倒数映射值进行乘法运算和移位运算,得到该行输入数据对应的最终结果;步骤407、将所述最终结果输出到softmax模块所属神经网络层的后一神经网络层。
[0041]
从图4所示方法可以看出,本实施例中,对从matmul模块传送到softmax模块的输入矩阵中的每行输入数据中的每个输入数据进行数据调整和截断处理得到该行输入数据的截断数据,利用全局共享的指数映射表实现指数运算得到该行输入数据的截断数据对应的指数映射数据,再通过求和得到该行输入数据对应的指数映射数据总和,根据全局共享的倒数映射函数确定该指数映射数据总和对应的倒数映射值,最后通过乘法运算和移位运算得到该行输入数据对应的最终结果。可以看出,本实施例中利用全局共享的指数映射表和倒数映射函数,简化了计算过程,能够减少硬件资源消耗,降低功耗,且可以解决从matmul模块传送到softmax模块的输入矩阵中不同行之间的数据分布和数据精度不一致的问题,能够有效提高量化精度。
[0042]
参见图7,图7是本发明实施例三基于transformer结构的softmax函数量化实现方法流程图,该方法应用于transformer结构中的softmax模块,如图7所示,该方法主要包括以下步骤:步骤700、获取transformer结构中的matmul模块传送的输入矩阵;步骤701、根据预先为transformer结构配置的全局共享指数映射表的输入数据位宽,对从matmul模块传送到softmax模块的输入矩阵中的每行输入数据进行数据调整,得到该行输入数据的调整数据;本实施例中,从matmul模块传送数据到softmax模块时,可以采用pipeline方式实现,图8示出了pipeline方式示意图,如图8所示,灰色部分表示matmul模块操作,白色部分表示softmax模块操作,在pipeline方式下,matmul模块每次只传送输入矩阵的部分数据到softmax模块,而不是一次性将整个输入矩阵传送到softmax模块。这种实现方式使得matmul模块和softmax模块强耦合,matmul模块输出的数据不需要被传送到ddr中,而是直接被传送到softmax模块,可以减少带宽占用,加快softmax模块获取数据的速度。
[0043]
本实施例中,从matmul模块传送数据到softmax模块时,采用pipeline方式实现,softmax模块不会同时运算得到整个输入矩阵对应的最终结果,而是逐行得到最终结果,为此,可以将运算得到的输入矩阵中的每行输入数据对应的最终结果暂存在静态随机存取存储器(sram)中,这种暂存方式代价极低。
[0044]
步骤702、对每行输入数据的调整数据进行截断处理,得到该行输入数据的截断数据;步骤703、查找所述全局共享指数映射表确定每行输入数据的截断数据对应的指数映射数据;步骤704、将每行输入数据的截断数据对应的指数映射数据相加,得到该行输入数据对应的指数映射数据总和;步骤7051、对每行输入数据对应的指数映射数据总和进行数据转换;本实施例中,对每行输入数据对应的指数映射数据总和进行数据转换,具体可包括:s11、确定表示该行输入数据对应的指数映射值总和所需占用的第一有效比特位数和表示预设取值区间的左边界值所需占用的第二有效比特位数,将第一有效比特位数与第二有效比特位数的差值确定为将该行输入数据对应的指数映射值总和映射到预设取值区间所需的第一右移位数;
本实施例中,确定表示一个数值val所需占用的有效比特位数bits(val)的具体方法可以采用以下公式 bits(val)=floor(log2(val))+1计算得到,其中,函数floor(x)用于对括号内的数值x进行向下取整。
[0045]
假设所述指数映射值总和为1600,预设取值区间为[256, 512)为例,则根据上述公式可知,表示所述指数映射值总和所需占用的第一有效比特位数= floor(log2(1600))+1=11,表示设取值区间为[256, 512)的左边界值256所需占用的第二有效比特位数= floor(log2(256))+1=9,因此,可以确定将所述指数映射值总和映射到预设取值区间所需的右移位数bits=11-9=2。
[0046]
s12、根据所述第一右移位数将该行输入数据对应的指数映射数据总和进行右移,将右移结果映射到由所述指数映射表的输出数据位宽确定的取值范围内的一个数值,将该数值作为该行输入数据对应的指数映射数据总和的转换数据。
[0047]
本实施例中,根据所述第一右移位数将该行输入数据对应的指数映射值总和进行右移,即将该行输入数据对应的指数映射值总和右移所述第一右移位数。将右移结果映射到由所述指数映射表的输出数据位宽确定的取值范围内的一个数值,可以通过将该右移结果减去预设取值区间中的左边界值得到。以预设取值区间为[256, 512)为例,可采用以下公式得到该行输入数据对应的指数映射值总和对应的转换数据sum
′
=(sum》》bits)-256,“》》”为右移运算符。
[0048]
步骤7052、将对每行输入数据对应的指数映射数据总和的转换结果输入预先为transformer结构配置的全局共享倒数映射函数,得到该行输入数据对应的指数映射数据总和的倒数映射值;本实施例中,所述倒数映射函数可以是:根据预设函数生成的倒数映射表、对预设函数进行线性拟合得到的一次函数、或者对预设函数进行多项式拟合生成的多项式函数;其中,所述预设函数为f(x)=2
r_bits
/x,x∈的取值范围为预设取值区间,较佳地,所述预设取值区间为[256, 512),其中r_bits是所述倒数映射函数的输出数据位宽,通常取值为16。
[0049]
以上步骤7051至步骤7052是图3所示步骤305的具体细化。
[0050]
步骤706、对每行输入数据的截断数据对应的指数映射数据与该行输入数据对应的指数映射数据总和的倒数映射值进行乘法运算和移位运算,得到该行输入数据对应的最终结果。
[0051]
本实施例中,对每行输入数据的截断数据对应的指数映射数据与该行输入数据对应的指数映射数据总和的倒数映射值进行乘法运算和移位运算,得到该行输入数据对应的最终结果,具体可以包括:s21、针对该行输入数据中的每一输入数据,执行以下操作步骤s22至步骤s23:s22、计算该输入数据的截断数据对应的指数映射数据与该行输入数据对应的指数映射数据总和的倒数映射值的乘积,对该乘积进行四舍五入处理得到该输入数据对应的中间结果;s23、根据所述第一右移位数、所述全局共享倒数映射函数的输出数据位宽、和softmax模块的输出数据位宽确定将该输入数据对应的中间结果映射到由softmax模块的输出数据位宽确定的取值范围所需的第二右移位数,根据第二右移位数对该输入数据对应的中间结果进行右移得到该输入数据对应的最终结果。
[0052]
上述步骤s23中,根据所述第一右移位数bits1、所述全局共享倒数映射函数的输出数据位宽r_bits、和softmax模块的输出数据位宽o_bits确定将该输入数据对应的中间结果映射到由softmax模块的输出数据位宽确定的取值范围所需的第二右移位数bits2,具体可采用以下公式实现:bits2= r_bits-o_bits+ bits1。
[0053]
步骤707、将所述最终结果输出到softmax模块所属神经网络层的后一神经网络层。
[0054]
从图7所示方法可以看出,本实施例中,对从matmul模块传送到softmax模块的输入矩阵中的每行输入数据进行数据调整和截断处理后,采用全局共享的指数映射表实现指数运算得到该行输入数据的截断数据对应的指数映射数据,再通过求和得到该行输入数据对应的指数映射数据总和,将该指数映射数据总和进行数据转换后代入全局共享倒数映射函数得到该指数映射数据总和对应的倒数映射值,最后通过乘法运算和移位运算得到该行输入数据对应的最终结果。可以看出,本实施例中利用全局共享的指数映射表和倒数映射函数,简化了计算过程,能够减少硬件资源消耗,降低功耗,且可以解决从matmul模块传送到softmax模块的输入矩阵中不同行之间的数据分布和数据精度不一致的问题,能够有效提高量化精度。
[0055]
以上对本发明实施例基于transformer结构的softmax函数量化实现方法进行了详细说明,本发明实施例还提供了一种基于transformer结构的softmax函数量化实现装置,以下结合图9进行详细说明。
[0056]
参见图9,图9是本发明实施例基于transformer结构的softmax函数量化实现装置的结构示意图,该装置应用于transformer结构中的softmax模块,如图9所示,该装置包括:获取单元900,用于获取transformer结构中的matmul模块传送的输入矩阵;调整单元901,用于根据预先为transformer结构配置的全局共享指数映射表的输入数据位宽,对从matmul模块传送到softmax模块的输入矩阵中的每行输入数据进行数据调整,得到该行输入数据的调整数据;对每行输入数据的调整数据进行截断处理,得到该行输入数据的截断数据;指数单元902,用于查找所述全局共享指数映射表确定每行输入数据的截断数据对应的指数映射数据;求和单元903,用于将每行输入数据的截断数据对应的指数映射数据相加,得到该行输入数据对应的指数映射数据总和;倒数单元904,用于根据预先为transformer结构配置的全局共享倒数映射函数确定每行输入数据对应的指数映射数据总和的倒数映射值;乘法单元905,用于对每行输入数据的截断数据对应的指数映射数据与该行输入数据对应的指数映射数据总和的倒数映射值进行乘法运算和移位运算,得到该行输入数据对应的最终结果;输出单元906、用于将所述最终结果输出到softmax模块所属神经网络层的后一神经网络层。
[0057]
图9所示装置中,所述调整单元901,根据预先为transformer结构配置的全局共享指数映射表的输入数据位宽,对从matmul模块传送到softmax模块的输入矩阵中的每行输入数据进行数据
调整,包括:确定该行输入数据中的最大值,并根据所述共享指数映射表的输入数据位宽确定一调整值;针对该行输入数据中的每一输入数据,计算该输入数据与所述最大值的差值,利用所述调整值对该差值进行调整,得到该输入数据的调整数据;所述调整单元901,对每行输入数据的调整数据进行截断处理,得到该行输入数据的截断数据,包括:针对该行输入数据中每一输入数据,如果该输入数据的调整数据小于0,则将该输入数据的截断数据设置为0,否则,将该输入数据的截断数据设置为该输入数据的调整数据。
[0058]
图9所示装置中,所述全局共享指数映射表是根据预先设定的定点量化后可表示的最小刻度s、所述全局共享指数映射表的输入数据位宽t_bits和输出数据位宽e_bits生成的,包括1《《t_bits个表项,占用的存储空间为(1《《t_bits)
×
e_bits
÷
8字节。
[0059]
图9所示装置中,所述全局共享倒数映射函数为根据预设函数生成的倒数映射表、对预设函数进行线性拟合得到的一次函数、或者对预设函数进行多项式拟合生成的多项式函数;其中,所述预设函数为f(x)=2 r_bits
/x,x的取值范围为预设取值区间,r_bits为所述倒数映射函数的输出值位宽;所述倒数单元904,根据预先为transformer结构配置的全局共享倒数映射函数确定每行输入数据对应的指数映射数据总和的倒数映射值,包括:对该行输入数据对应的指数映射数据总和进行数据转换;将转换结果输入所述全局共享倒数映射函数,得到该行输入数据对应的指数映射数据总和的倒数映射值。
[0060]
图9所示装置中,所述倒数单元904,对该行输入数据对应的指数映射数据总和进行数据转换,包括:确定表示该行输入数据对应的指数映射值总和所需占用的第一有效比特位数和表示预设取值区间的左边界值所需占用的第二有效比特位数,将第一有效比特位数与第二有效比特位数的差值确定为将该行输入数据对应的指数映射值总和映射到预设取值区间所需的第一右移位数;根据所述第一右移位数将该行输入数据对应的指数映射数据总和进行右移,将右移结果映射到由所述指数映射表的输出数据位宽确定的取值范围内一个数值,将该数值作为该行输入数据对应的指数映射数据总和的转换数据。
[0061]
图9所示装置中,所述乘法单元905,对每行输入数据的截断数据对应的指数映射数据与该行输入数据对应的指数映射数据总和的倒数映射值进行乘法运算和移位运算,得到该行输入数据对应的最终结果,包括:针对该行输入数据中的每一输入数据,执行以下操作:
计算该输入数据的截断数据对应的指数映射数据与该行输入数据对应的指数映射数据总和的倒数映射值的乘积,对该乘积进行四舍五入处理得到该输入数据对应的中间结果;根据所述第一右移位数、所述全局共享倒数映射函数的输出数据位宽、和softmax模块的输出数据位宽确定将该输入数据对应的中间结果映射到由softmax模块的输出数据位宽确定的取值范围所需的第二右移位数,根据第二右移位数对该输入数据对应的中间结果进行右移得到该输入数据对应的最终结果。
[0062]
图9所示装置中,从matmul模块传送输入矩阵到softmax模块时,采用pipeline方式实现;softmax模块运算得到所述输入矩阵中的每行输入数据对应的最终结果暂存在静态随机存取存储器sram中。
[0063]
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1