基于图卷积网络的多粒度人体动作分类方法
1.本发明属于视频动作识别领域,涉及一种基于图卷积网络的多粒度动作分类方法。
背景技术:
2.基于图卷积网络的多粒度人体动作分类是视频动作识别领域非常具有挑战性的一个研究方向。其中,对于骨骼点数据的分类方法的研究是最为热门和核心的研究内容。图卷积网络主要基于空间卷积-时间卷积模式构建,输入的信息是二维或三维的特征序列。
3.目前,动作识别领域中分类问题的研究已经取得了很多进展,各种方法层出不穷。所研究的数据模态从最初rgb数据扩展到了骨骼点数据,视频帧的选择策略从整段输入进阶为随机多帧抽取,提取的判别信息也逐渐细化到人体的时空位置信息。人体动作分类面向的是人体运动的视频数据,分类性能的好坏着力于空间尺度和时间尺度上信息的提取。空间尺度信息表现为单个视频帧中人体结构的空间分布,时间尺度信息表现为人体结构在时间轴上的变化。当前的主流方法大多只关注同一帧节点的空间连接信息,时间上的信息只通过时域卷积进行传播。但是,这些方法忽略了每个节点在不同帧中的差异性,丢失了时空层面上的高等级特征。主流的公开数据集也多为粗粒度数据集,与之相比,细粒度分类问题的研究较为缓慢。细粒度分类问题具有许多的实际应用场景,比如滑冰运动中的不同级别跳跃的判别,滑冰运动中的每种跳跃只有很细微的差别且都属于一个大类别跳跃。这些细粒度分类问题更加具有挑战性,也更加具有应用价值。
技术实现要素:
4.本发明目的是提供一种基于图卷积网络的多粒度人体动作分类方法,通过在每个样本中提取时间维度和空间维度的特征,捕获骨骼点和骨骼点之间,帧与骨骼点之间,帧与帧之间的关系,进而生成准确和高鲁棒性的动作分类结果。
5.为实现上述目的,本发明提供如下技术方案:
6.一种基于图卷积网络的多粒度人体动作分类方法,包括
7.s1.获取目标动作的骨骼点数据集;
8.s2.将骨骼点划分为骨骼点本身、靠近重心的一近邻节点、远离重心的一近邻节点三个子集,使用v表示骨骼点数量,每个子集是v
×
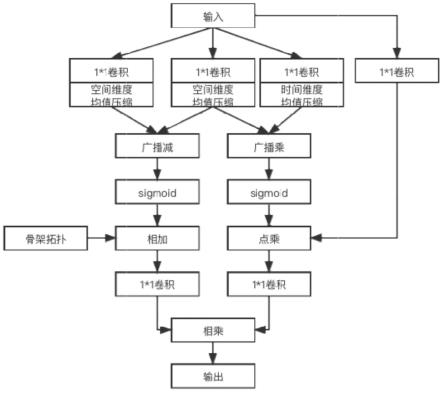
v的矩阵;
9.根据所述三个子集划分形状为3
×v×
v的所述三个子集的邻接矩阵,根据所述邻接矩阵划分骨架拓扑的三个通道;
10.对所述邻接矩阵标准化得到骨架拓扑矩阵a,用ai表示第i个通道的骨架拓扑矩阵a的子集;
11.s3.对骨骼点数据集进行抽帧得到形状为c
×
t
×
v的输入数据x
in
,c表示特征数量,t表示时间窗大小;
12.s4.在骨架拓扑的三个通道上,将输入数据x
in
通过cr维度的1
×
1卷积、不同维度的
均值压缩和维度扩展处理,提取空间的特征矩阵x1、x2和时间特征矩阵x3,空间的特征矩阵x1形状为cr×
t
×
1、空间的特征矩阵x2形状为cr×1×
t、时间特征矩阵x3形状为cr×
t
×
1,同时,对输入数据x
in
进行c
out
维度的1
×
1卷积,得到形状为c
out
×
t
×
v的时空向量x4;
13.s5.空间的特征矩阵x1和空间的特征矩阵x2通过减法运算进行空间关系建模,通过激活函数φ1和c
out
维度的1
×
1卷积f1,生成空间向量x5:
14.x5=f1(φ1(x
1-x2))
ꢀꢀꢀ
(1)
15.空间的特征矩阵x2和时间特征矩阵x3通过乘法运算融合建立时空关系,通过激活函数φ2和c
out
维度的1
×
1卷积f2,生成时空权重向量x6:
16.x6=f2(φ2(x2·
x3))
ꢀꢀꢀ
(2)
17.s6.空间向量x5和每个通道的骨架拓扑子集ai通过融合函数构建细化的空间向量x7,空间向量x5和每个通道的骨架拓扑子集ai之间的数值关系是可学习的,权重系数为α;
[0018][0019]
时空权重向量x6通过融合函数为时空向量x4提供权重,产生细化的时空向量x8;
[0020][0021]
s7.将两个空间向量x7和x8在每个通道上进行矩阵乘法运算和通道拼接得到时空细化的拓扑
[0022]
s8.将所有通道的输出相加进行融合,通过归一化和relu函数激活,得到通道细化拓扑xc;
[0023]
s9.将通道细化拓扑xc输入到时域卷积网络得到输出x
out
;
[0024]
s10.输出x
out
作为输入数据x
in
循环若干次执行步骤s4~s9,将每一次循环执行步骤s4~s8所得输出x
out
输入全连接层,进行最大池化得到特征f
out
,特征f
out
表示从输入骨骼点数据中提取的动作特征,最后将特征f
out
输入softmax层得到多粒度人体动作分类标签。
[0025]
在一种实施例中,输出x
out
作为输入数据x
in
循环八次执行步骤s4~s9。
[0026]
在一种实施例中,最大池化得到维度为256的特征f
out
。
[0027]
在一种实施例中,每个时域卷积网络由卷积核为3和卷积核为5的两个时间卷积模块构成。
[0028]
在一种实施例中,所述步骤s4~s7执行所构建的网络为时空细化图卷积网络。
[0029]
在一种实施例中,所述步骤s8~s9执行所构建的网络为多维度细化图卷积网络。
[0030]
在一种实施例中,所述多维度细化图卷积网络共有九层,前三层有64个输出通道,中间三层有128个输出通道,最后三层有256个输出通道,九层多维度细化图卷积网络的输出输入全连接层,进行最大池化得到特征f
out
。
[0031]
在一种实施例中,所述的基于图卷积网络的多粒度人体动作分类方法还包括
[0032]
s11.通过特征f
out
和训练集的标签y计算角弦损失函数l
al
,并根据损失函数结果进行优化,迭代训练,直到达到预设的迭代轮次;l
al
由常规损失函数ls、角度损失函数l
in
、角度补偿损失函数l
out
和弦长损失函数l
l
组成;l
al
通过训练得到中心特征矩阵c,c的形状为类别数k
×
特征数f,类别y在c上的特征向量表示为cy;i
l
和l
out
通过权重常量λ与ls和l
in
联合作用得到l
al
,通过如下公式表示:
[0033][0034][0035][0036]
l
al
=ls+l
in
+λ(l
l-l
out
)
ꢀꢀꢀ
(8)
[0037]
lin在角度上使得类内的分布比较集中,l
l
是在距离上使得类内的分布比较集中,l
out
扩大类间的距离。
[0038]
在一种实施例中,步骤s5所述的激活函数可以是tanh,sigmoid,hardswish的任一种。
[0039]
在一种实施例中,上述步骤s11所述的常规损失函数是softmax loss,sphereface,large margin cosine loss,arcface中的任一种。
[0040]
本发明的有益效果是在骨架拓扑的每个通道上,同时形成了时间维度和空间维度的细化,感受了时空高级特征,打破了传统方法只能利用空间连接信息和时间连接信息的局限。同时,角弦损失函数改善了特征在向量空间中的分布,使不同类别的分类边界更加清晰。通过多维度细化的图卷积机制和角弦损失函数,可以对粗粒度的动作数据和细粒度的动作数据都进行准确分类,满足了分类任务中对准确性的要求,该方法具有较大的发展前景。
附图说明
[0041]
图1为多维度细化图卷积模块的结构图。
[0042]
图2为一层多维度细化图卷积网络的结构图。
[0043]
图3为完整的多维度细化图卷积的结构图。
具体实施方式
[0044]
下面,将结合附图1~3进一步详细说明本发明的具体实施方式。
[0045]
实施例1:如图1~3所示,一种基于图卷积网络的多粒度人体动作分类方法,包括
[0046]
s1:通过深度传感器或骨骼点提取算法获取目标动作的骨骼点数据集,划分为训练集t1和测试集t2;
[0047]
s2:将骨骼点划分为骨骼点本身、靠近重心的一近邻节点、远离重心的一近邻节点三个子集;
[0048]
使用v表示骨骼点数量,每个子集是v
×
v的矩阵,划分得到形状为3
×v×
v的邻接矩阵,再对该邻接矩阵进行标准化得到骨架拓扑矩阵a,不同的数据集提取的骨骼关键点不同,邻接关系不同,得到的邻接矩阵也不相同,为了给后续训练提供多种不同类型的特征。
[0049]
现有分类方法中,输入数据是形状为c
×
t
×
v的输入数据,c特征数量,t是全部帧数,大小是不固定的,v骨骼点数量。在本发明中,根据三个不同的子集邻接矩阵划分为三个通道,用ai表示第i个通道的骨架拓扑矩阵a的子集。s3:对训练集t1进行抽帧,抽帧策略与设定的时间窗大小t和视频的实际帧数有关,视频的实际帧数即为去除补0的视频帧后的含
有有效数据的全部帧数;如果时间窗的长度大于或等于实际帧数,则随机选择起始点,将实际视频帧整体放入,其余位置补0;如果时间窗的长度比实际帧数小,则将视频划分为时间窗大小个区间,每个区间随机抽取,最终得到形状为c
×
t
×
v的输入数据x
in
。该步骤的目的是将输入数据的时间窗大小固定。
[0050]
s4:在骨架拓扑的每个通道上,三个子集对应的三个通道,将x
in
通过cr维度的1
×
1卷积、不同维度的均值压缩和维度扩展,提取空间的特征矩阵x1、x2和时间特征矩阵x3,其形状为cr×
t
×
1、cr×1×
t和cr×
t
×
1同时,对x
in
进行c
out
维度的1
×
1卷积,得到形状为c
out
×
t
×
v的时空向量x4;
[0051]
s5:x1和x2通过减法运算进行空间关系建模,通过激活函数φ1和c
out
维度的1
×
1卷积f1,生成空间向量x5;x2和x3通过乘法运算融合建立时空关系,通过激活函数φ2和c
out
维度的1
×
1卷积f2,生成时空权重向量x6。x5和x6通过如下公式计算;
[0052]
x5=f1(φ1(x
1-x2))
ꢀꢀꢀ
(1)
[0053]
x6=f2(φ2(x2·
x3))
ꢀꢀꢀ
(2)
[0054]
s6:x5和每个通道的骨架拓扑子集ai通过融合函数构建细化的空间向量x7,x5和ai之间的数值关系是可学习的,权重系数为α;x6通过为样本本身的时空向量x4提供权重,产生细化的时空向量x8,和由如下公式表示;
[0055][0056][0057]
每个帧中每个关节点应该具有不同关注度,在每个帧中给不同的关节点提取不同的权重产生细化的时空向量。
[0058]
对于多粒度系列动作只有一帧或几帧的差别,通过权重分配产生细化的时空向量能够对细微动作进行准确捕捉。
[0059]
s7:将两个向量x7和x8在每个通道上进行矩阵乘法运算和通道拼接得到时空细化的拓扑
[0060]
s8.将所有通道的输出相加进行融合,通过归一化和relu函数激活,得到通道细化拓扑xc;
[0061]
s9:将xc输入到时域卷积网络,每个时域卷积网络由卷积核为3和卷积核为5的两个时间卷积模块构成,以感受临近帧之间的相关性,时域卷积网络能够帮助捕捉相邻帧之间的关系,能够捕获动作的连贯过程。由此得到一层多维度细化图卷积网络的输出x
out
,由上述,步骤s4-s8为构建多维度细化图卷积网络的步骤。
[0062]
s10:将输出x
out
作为下一层的多维度细化图卷积网络的输入(x
in
),循环进行九层多维度细化图卷积网络,即循环执行步骤s4-s9共9轮,每轮循环的输入x
in
是上一轮的输出x
out
。
[0063]
其中前三层有64个输出通道;中间三层有128个输出通道。最后三层有256个输出通道;最后将九层多维度细化图卷积网络的输出输入全连接层,进行最大池化降低特征维度,得到维度为256的特征f
out
,表示从输入骨骼点数据中提取的动作特征,最后将特征f
out
输入softmax层得到多粒度人体动作分类标签。层数选择在精度达到比较高,效率和精度在9层比较平衡。
[0064]
s10:通过f
out
和训练集的标签y计算角弦损失函数l
al
,并根据损失函数结果进行优化,迭代训练,直到达到预设的迭代轮次;l
al
由常规损失函数ls、角度损失函数l
in
、角度补偿损失函数l
out
和弦长损失函数l
l
组成;l
al
通过训练得到中心特征矩阵c,c的形状为类别数k
×
特征数f,类别y在c上的特征向量表示为cy;l
l
和l
out
通过权重常量λ与ls和l
in
联合作用得到l
al
,通过如下公式表示。
[0065][0066][0067][0068]
l
al
=ls+l
in
+λ(l
l-l
out
)
ꢀꢀꢀ
(8)
[0069]
本发明使用所述损失函数,lin在角度上使得类内的分布比较集中,l
l
是在距离上使得类内的分布比较集中,l
out
扩大类间的距离。
[0070]
进一步地,上述步骤s5所述的激活函数可以是tanh,sigmoid,hardswish的一种。
[0071]
进一步地,上述步骤s10所述的常规损失函数可以是softmax loss,sphereface,large margin cosine loss,arcface的一种。
[0072]
实施例2:本实施例使用具体花样滑冰动作数据集fsd-10对本发明的方法的具体实施进行详细说明,如图1~3所示,本发明基于图卷积网络的多粒度人体动作分类方法,具体实施步骤如下:
[0073]
s1:使用openpose25骨骼点提取算法从花样滑冰动作数据集fsd-10中提取骨骼点数据集,划分为训练集t1和测试集t2。
[0074]
s2:将骨骼点划分为骨骼点本身、靠近重心的一近邻节点、远离重心的一近邻节点三个子集,得到形状为3
×
25
×
25的邻接矩阵,再对该邻接矩阵进行标准化得到骨架拓扑矩阵a。
[0075]
s3:对t1进行抽帧,抽帧策略与设定的时间窗大小t设定为256;时间窗的长度大于或等于实际帧数,则随机选择起始点,将实际视频帧整体放入,其余位置补0,最终得到形状为3
×
256
×
25的输入数据x
in
。
[0076]
s4:在骨架拓扑的每个通道上,将x
in
通过cr维度的1
×
1卷积、不同维度的均值压缩和维度扩展,提取空间的特征矩阵x1、x2和时间特征矩阵x3,其形状为cr×
25
×
1、cr×1×
25和cr×
256
×
1同时,对x
in
进行c
out
维度的1
×
1卷积,得到形状为c
out
×
256
×
25的时空向量x4;
[0077]
s5:x1和x2通过减法运算进行空间关系建模,通过激活函数sigmoid和c
out
维度的1
×
1卷积f1,生成空间向量x5;x2和x3通过乘法运算融合建立时空关系,通过激活函数tanh和c
out
维度的1
×
1卷积f2,生成时空权重向量x6。x5和x6通过如下公式计算。
[0078]
x5=f1(sigmoid(x
1-x2))
ꢀꢀꢀ
(1)
[0079]
x6=f2(tanh(x2·
x3))
ꢀꢀꢀ
(2)
[0080]
s6:x5和对应通道的骨架拓扑子集ai通过融合函数构建细化的空间向量x7,x5和ai之间的数值关系是可学习的,权重系数为α;x6通过为样本本身的时空向量x4提供权重,
产生细化的时空向量x8,和由如下公式表示。
[0081][0082][0083]
s7:将两个向量x7和x8在每个通道上进行矩阵乘法运算和通道拼接得到时空细化的拓扑将所有通道的输出相加进行融合,通过归一化和relu函数激活,得到通道细化拓扑xc,完整的时空细化过程如图1所示。
[0084]
s8:将xc输入到时域卷积网络,每个时域卷积网络由卷积核为3和卷积核为5的两个时间卷积模块构成,以感受临近帧之间的相关性,得到一层多维度细化图卷积网络的输出x
out
,一层多维度细化图卷积网络的过程如图2所示。
[0085]
s9:将输出作为下一层的输入,循环进行九层多维度细化图卷积网络,其中前三层有64个输出通道;中间三层有128个输出通道。最后三层有256个输出通道;最后将特征输入全连接层,进行最大池化降低特征维度,得到维度为256的特征f
out
,完整的模型结构如图3所示。
[0086]
s10:通过f
out
和训练集的标签y计算角弦损失函数l
al
,并根据损失函数结果进行优化,迭代训练,直到达到预设的迭代轮次;l
al
由常规损失函数ls、角度损失函数l
in
、角度补偿损失函数l
out
和弦长损失函数l
l
组成;l
al
通过训练得到中心特征矩阵c,c的形状为10
×
256,类别y在c上的特征向量表示为cy;l
l
和l
out
通过权重常量λ与ls和l
in
联合作用得到l
al
,λ设定为0.1,l
al
通过如下公式表示。
[0087][0088][0089][0090]
l
al
=ls+l
in
+λ(l
l-l
out
)
ꢀꢀꢀ
(8)
[0091]
s11:保存训练的参数,将测试集t2输入模型,得到预测的分类结果,以分类的准确率为评价标准,和标签进行对比,并和其他主流方法进行对比,经过反复测试,具体结果如表1所示。
[0092]
表1本发明与其他对比算法的测试结果
[0093]
算法准确率算法184.24%算法288.72%算法390.58%实施例192.94%实施例293.17%
[0094]
附:算法1:st-gcn;算法2:ms-g3d;算法3:ctr-gcn;实施例1:sigmoid+tanh;实施例2:tanh+tanh;
[0095]
与对比算法相比,本发明所提出的实施例2对应的方法在分类精度上明显提高,基
本符合多粒度动作数据的分类准确性要求。
[0096]
实施例3:本实施例与实施例1或2的区别仅在于,使用了不同的激活函数,即步骤s5中激活函数φ1和φ2都使用了tanh。本实施例s11:仍使用分类准确率精度作为指标对所提方法进行了验证,测试结果如表1。与对比算法相比,本本发明所提出的实施例2对应的方法具有较高的精度,较好地满足了多粒度动作数据的分类准确性要求。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1