纵横相似的高速公路短时交通量预测方法与流程
本发明涉及一种纵横相似的高速公路短时交通量预测方法,属于计算机数据挖掘技术领域。
背景技术:
目前,交通预测已经被认为是不同角度上的问题:如时间序列问题,回归和函数逼近问题,聚类或模式识别问题,甚至包含以上所有。Cheng等利用公路网络的时空自相关结构建立时空预测模型。Thomas等在对荷兰阿尔梅罗市20个交叉路口进行广泛学习后,利用单时间序列进行短期和长期预测。Qi等提出一种自适应单指数平滑法,通过近似动态规划优化指数平滑系数对短期交通流进行预测。Jiang等引入一种多元线性回归最小绝对收缩和选择算子方法(Lasso)结合神经网络(NN)的非线性特征,提出Lasso-NN组合模型。Xu等提出空间聚类的短时交通量预测Cluster-NN模型。Wang等提出基于k最近邻非参数回归的预测方法。Xu等提出了自适应权重粒子群神经网络交通流预测(PSOA-NN)模型。Li等使用带有时间依赖结构的支持向量机(SVM)提出一种模式来预测短期交通流量。Castillo等利用广义Beta-Gaussian贝叶斯网络提出适应于随机动态需求的交通模型。Vlahogianni等将自回归时间序列模型与神经网络结合对短期交通进行测试。
综上所述,在现有短时交通量预测中,通常要求操作人员对相关知识有较深的理解和掌握,不利于大范围推广应用。
技术实现要素:
本发明的目的在于提供一种纵横相似的高速公路短时交通量预测方法,是根据交通量序列的同期相似和近期相似结合历史分布规律进行预测。首先将交通量数据按照一年内的第几周和每周的第几天的规则进行标定周数和天数,并将数据按照标定的天数进行分类。将不同年相同周数相同天数的交通量数据构建为纵向数据序列矩阵、相同年内被预测天前一周的交通量数据构建为横向数据序列矩阵,分别计算纵向序列和横向序列的平均合向量,通过纵向序列和横向序列平均合向量序列的加权求和获得纵横序列合向量。然后通过预测单天总体交通量,结合单天内的交通量分布规律得到分布规律数据序列向量,根据纵横序列合向量和分布规律数据序列向量加和平均确定最终的交通量预测数据序列向量,由此完成短时交通量的预测过程;其提高了交通量预测中季节性的抗干扰能力,扩大短时交通量预测方法的应用范围。
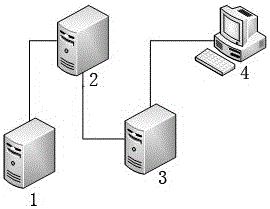
本发明的技术方案是这样实现的:纵横相似的高速公路短时交通量预测方法,其特征在于所采用设备为服务器A、服务器B、服务器C、计算机;其中服务器A为现有系统服务器、服务器B为数据ETL服务器、服务器C为数据仓库服务器;服务器A中的原始数据通过服务器B进行相应规则的清洗转换最终加载到服务器C中,计算机通过报表展示系统获取数据进行展现和分析;其具体的步骤如下:
步骤1、将高速公路收费数据按半小时分段以及日期进行汇总统计半小时交通量和单天交通量数据;
步骤2、根据半小时交通量数据构建纵向数据序列矩阵为,其中表示交通序列向量,a=1,2,…,n表示从最早一年开始的第几年,b =1,2,…,n,表示第a年中的第几周,c =1,2,3,4,5,6,7表示a年b周中的第几天,k=1,2,…,48 ,表示a年b周中第c天的序列向量中的第几维,即第几个数据;
步骤3、根据不同的k值将步骤2中的纵向数据序列矩阵中分为k个序列,每个序列分别利用线性回归中的最小二乘法进行规划求解,得出下一个求解结果,将这k个结果按k值从小到大组合成纵向序列平均合向量;
步骤4、构建横向数据序列矩阵,在构建横向数据序列矩阵时选取被预测日前一周的数据;
步骤5、计算横向序列平均合向量,根据横向数据序列矩阵中的7天数据加权求和获得,其中,因第1天的数据与被预测日的数据同为一类,故赋予较大权值,其余平均分配;
步骤6、确定纵向平均合向量和横向平均合向量的权值分配, 通过计算向量相似系数来确定加权系数, 设纵向平均合向量的加权系数为,因两者的加权系数之和为1,则横向平均合向量的加权系数为,利用下式求取值;
步骤7、根据步骤6中计算出的权值计算纵向平均合向量和横向平均合向量加权求和所获得纵横序列合向量;
步骤8、利用步骤1中汇总的单天交通量数据构建单天总体交通量序列向量,其中表示一个表示a年b周中第c天的总体交通量,其中a=1,2,…,n,表示从最早一年开始的第几年,b=1,2,…,n,表示第a年中的第几周;c=1,2,3,4,5,6,7表示a年b周中的第几天;
步骤9、利用线性回归中的最小二乘法对步骤8中的向量进行规划求解,得出下一个求解结果;
步骤10、分析多组半小时交通量数据可得出每天的交通量分布基本一致,可通过各时段的交通量在总体中的占比得出交通量分布律;
步骤11、将步骤9中得到的求解结果按照步骤10中得到的分布律计算分布规律数据序列向量;
步骤12、将步骤7中得到的纵横序列合向量和步骤11中得到的分布规律数据序列向量按照加和平均进行叠加得到最终的交通量预测数据序列向量;
利用以上步骤可以得到高速公路短时交通量预测数据。
本发明积极效果是根据交通量序列的同期相似和近期相似结合历史分布规律进行预测,大幅度降低交通量预测中季节性干扰;其优点在于:
1. 本发明中的高速公路短时交通量预测方法利用历史同期数据进行预测,能大幅度降低交通量的季节性因素的影响。
2.本发明中的高速公路短时交通量预测方法结合半小时分段的分布规律能更好的使预测结果符合实际情况。
3.本发明中的高速公路短时交通量预测方法对交通量序列的同期相似和近期相似进行分析研究,具有应用的延续性。
附图说明
图1 纵横相似的高速公路短时交通量预测方法所需设备结构图。
具体实施方式
下面结合附图对本发明做进一步的描述:如图1所示,纵横相似的高速公路短时交通量预测方法,采用设备为服务器A1、服务器B2、服务器C3、计算机4;服务器A1为现有系统服务器、服务器B2为数据ETL服务器、服务器C3为数据仓库服务器;服务器A1中的原始数据通过服务器B2进行相应规则的清洗转换最终加载到服务器C3中,计算机4通过报表展示系统获取数据进行展现和分析;其具体的步骤如下:
步骤1、将高速公路收费数据按半小时分段以及日期进行汇总统计半小时交通量和单天交通量数据;
步骤2、根据半小时交通量数据构建纵向数据序列矩阵为,其中表示交通序列向量,a=1,2,…,n表示从最早一年开始的第几年,b =1,2,…,n,表示第a年中的第几周,c =1,2,3,4,5,6,7表示a年b周中的第几天,k=1,2,…,48 ,表示a年b周中第c天的序列向量中的第几维,即第几个数据;
步骤3、根据不同的k值将步骤2中的纵向数据序列矩阵中分为k个序列,每个序列分别利用线性回归中的最小二乘法进行规划求解,得出下一个求解结果,将这k个结果按k值从小到大组合成纵向序列平均合向量;
步骤4、构建横向数据序列矩阵,在构建横向数据序列矩阵时选取被预测日前一周的数据;
步骤5、计算横向序列平均合向量,根据横向数据序列矩阵中的7天数据加权求和获得,其中,因第1天的数据与被预测日的数据同为一类,故赋予较大权值,其余平均分配;
步骤6、确定纵向平均合向量和横向平均合向量的权值分配, 通过计算向量相似系数来确定加权系数, 设纵向平均合向量的加权系数为,因两者的加权系数之和为1,则横向平均合向量的加权系数为,利用下式求取值;
步骤7、根据步骤6中计算出的权值计算纵向平均合向量和横向平均合向量加权求和所获得纵横序列合向量;
步骤8、利用步骤1中汇总的单天交通量数据构建单天总体交通量序列向量,其中表示一个表示a年b周中第c天的总体交通量,其中a=1,2,…,n,表示从最早一年开始的第几年,b=1,2,…,n,表示第a年中的第几周;c=1,2,3,4,5,6,7表示a年b周中的第几天;
步骤9、利用线性回归中的最小二乘法对步骤8中的向量进行规划求解,得出下一个求解结果;
步骤10、分析多组半小时交通量数据可得出每天的交通量分布基本一致,可通过各时段的交通量在总体中的占比得出交通量分布律;
步骤11、将步骤9中得到的求解结果按照步骤10中得到的分布律计算分布规律数据序列向量;
步骤12、将步骤7中得到的纵横序列合向量和步骤11中得到的分布规律数据序列向量按照加和平均进行叠加得到最终的交通量预测数据序列向量;
利用以上步骤可以得到高速公路短时交通量预测数据。
- 还没有人留言评论。精彩留言会获得点赞!