一种基于情境信息的交通状况预测方法、系统及装置与流程
本发明涉及智能交通领域,尤其是一种基于情境信息的交通状况预测方法、系统及装置。
背景技术:
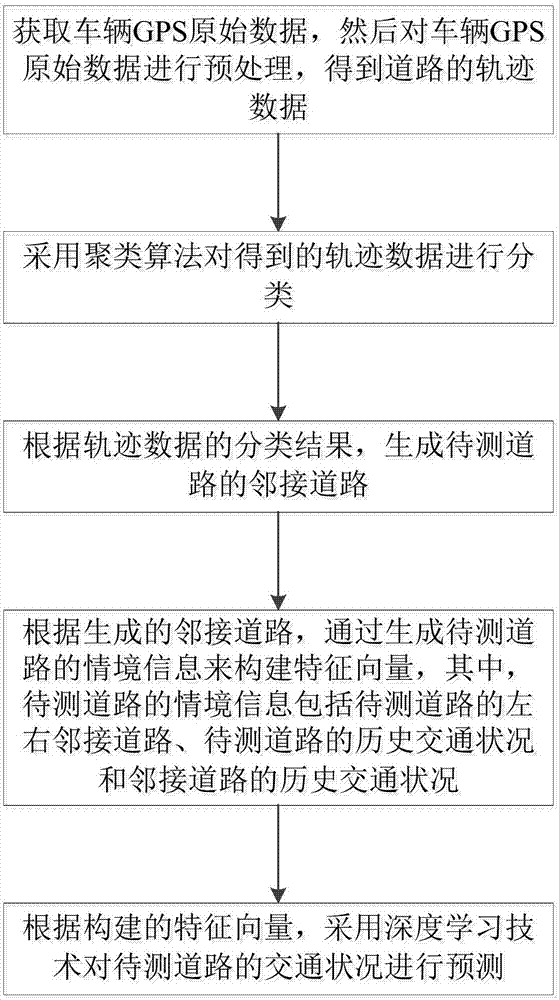
随着技术的发展,大数据应用于许多方面。例如,随着全球定位系统gps的广泛采用,产生了大量的轨迹数据,这些数据不仅能够用来描述移动物体的移动历史,而且还可用来预测道路交通状况,尤其是在实时数据计算成本过于高昂,或缺少实时数据的时候。通常,地图服务提供商会用不同色彩来标注不同的路况,例如,红色表示实时路况拥堵,绿色表示实时路况畅顺,橙色表示实时行车缓慢。但是,这种只能显示实时路况的服务显然不够实用,人们亟需一种能够成功预测道路的未来交通状况的方法,比如预测未来十分钟该路段是否会发生拥堵,以方便人们作出最合理的路线规划,减少道路拥堵带来的时间浪费。技术实现要素:为解决上述技术问题,本发明的目的在于:提供一种基于情境信息的交通状况预测方法、系统及装置,以预测道路的未来交通状况,进而方便人们作出最合理的路线规划,减少道路拥堵带来的时间浪费。本发明所采取的第一技术方案是:一种基于情境信息的交通状况预测方法,包括以下步骤:获取车辆gps原始数据,然后对车辆gps原始数据进行预处理,得到道路的轨迹数据;采用聚类算法对得到的轨迹数据进行分类;根据轨迹数据的分类结果,生成待测道路的邻接道路;根据生成的邻接道路,通过生成待测道路的情境信息来构建特征向量,其中,待测道路的情境信息包括待测道路的左右邻接道路、待测道路的历史交通状况和邻接道路的历史交通状况;根据构建的特征向量,采用深度学习技术对待测道路的交通状况进行预测。进一步,所述获取车辆gps原始数据,然后对车辆gps原始数据进行预处理,得到道路的轨迹数据这一步骤,包括以下步骤:对车辆gps原始数据中的异常车速进行取代处理;对车辆gps原始数据中的异常数据进行过滤处理;对车辆gps原始数据中的遗失数据进行补零处理;对车辆gps原始数据中的时间戳进行均值处理。进一步,所述采用聚类算法对得到的轨迹数据进行分类这一步骤,包括以下步骤:基于预设的时间段和轨迹数据中的时间戳,将得到的轨迹数据划分成一系列轨迹线段;采用层次聚类法对轨迹线段进行分类。进一步,所述根据轨迹数据的分类结果,生成待测道路的邻接道路这一步骤,包括以下步骤:获取每个簇的最小外接矩形;根据各个最小外接矩形之间的最短距离,得到待测道路与其它道路之间的距离;对待测道路与其它道路之间的距离进行排序;根据排序的结果,将若干条其它道路确定为邻接道路。进一步,所述根据生成的邻接道路,通过生成待测道路的情境信息来构建特征向量这一步骤,具体为:根据生成的邻接道路,获取待测道路的左情境信息和右情境信息,其中,所述左情境信息是指位于待测道路左边的邻接道路的历史交通状况,右情境信息是指位于待测道路右边的邻接道路的历史交通状况。进一步,所述根据构建的特征向量,采用深度学习技术对待测道路的交通状况进行预测这一步骤,包括以下步骤:采用定向递归神经网络来分别对左情境信息和右情境信息的情境向量进行捕捉;采用双曲正切函数对捕捉的结果进行线性变换;采用平均函数对线性变换的结果进行特征强化处理;通过下采样层减少模型训练数据的过拟合;通过全连接层将特征与激活函数进行结合;采用softmax函数对待测道路的交通状况进行预测。进一步,还包括对道路交通状况的预测结果进行评价的步骤。进一步,所述对道路交通状况的预测结果进行评价这一步骤,包括以下步骤:对深度学习架构的性能进行评价;对情境信息的捕捉能力进行评价。本发明所采取的第二技术方案是:一种基于情境信息的交通状况预测系统,包括:获取模块,用于获取车辆gps原始数据,然后对车辆gps原始数据进行预处理,得到道路的轨迹数据;分类模块,用于采用聚类算法对得到的轨迹数据进行分类;生成模块,用于根据轨迹数据的分类结果,生成待测道路的邻接道路;构建模块,用于根据生成的邻接道路,通过生成待测道路的情境信息来构建特征向量,其中,待测道路的情境信息包括待测道路的左右邻接道路、待测道路的历史交通状况和邻接道路的历史交通状况;预测模块,用于根据构建的特征向量,采用深度学习技术对待测道路的交通状况进行预测。本发明所采取的第三技术方案是:一种基于情境信息的交通状况预测装置,包括:存储器,用于存储程序;处理器,用于加载程序,以执行如第一技术方案所述的一种基于情境信息的交通状况预测方法。本发明的有益效果是:本发明采用聚类算法对轨迹数据进行分类,能够分别对不同类别的道路进行预测处理,适用范围广;本发明采用基于情境信息来构建特征向量的方法,能够充分结合待测道路的情境条件,提高交通状况预测的准确度,能够方便人们作出最合理的路线规划,减少道路拥堵带来的时间浪费。附图说明图1为本发明一种基于情境信息的交通状况预测方法的步骤流程图;图2为本发明的实施例中道路分布的示意图;图3为本发明的深度学习架构示意图;图4为本发明实施例中四种道路状况的数据分布示意图。具体实施方式下面结合说明书附图和具体实施例对本发明作进一步解释和说明。对于本发明实施例中的步骤编号,其仅为了便于阐述说明而设置,对步骤之间的顺序不做任何限定,实施例中的各步骤的执行顺序均可根据本领域技术人员的理解来进行适应性调整。参照图1,本发明一种基于情境信息的交通状况预测方法,包括以下步骤:获取车辆gps原始数据,然后对车辆gps原始数据进行预处理,得到道路的轨迹数据;采用聚类算法对得到的轨迹数据进行分类;根据轨迹数据的分类结果,生成待测道路的邻接道路;根据生成的邻接道路,通过生成待测道路的情境信息来构建特征向量,其中,待测道路的情境信息包括待测道路的左右邻接道路、待测道路的历史交通状况和邻接道路的历史交通状况;根据构建的特征向量,采用深度学习技术对待测道路的交通状况进行预测。进一步作为优选的实施方式,所述获取车辆gps原始数据,然后对车辆gps原始数据进行预处理,得到道路的轨迹数据这一步骤,包括以下步骤:对车辆gps原始数据中的异常车速进行取代处理;对车辆gps原始数据中的异常数据进行过滤处理;对车辆gps原始数据中的遗失数据进行补零处理;对车辆gps原始数据中的时间戳进行均值处理。进一步作为优选的实施方式,所述采用聚类算法对得到的轨迹数据进行分类这一步骤,包括以下步骤:基于预设的时间段和轨迹数据中的时间戳,将得到的轨迹数据划分成一系列轨迹线段;采用层次聚类法对轨迹线段进行分类。进一步作为优选的实施方式,所述根据轨迹数据的分类结果,生成待测道路的邻接道路这一步骤,包括以下步骤:获取每个簇的最小外接矩形;根据各个最小外接矩形之间的最短距离,得到待测道路与其它道路之间的距离;对待测道路与其它道路之间的距离进行排序;根据排序的结果,将若干条其它道路确定为邻接道路。进一步作为优选的实施方式,所述根据生成的邻接道路,通过生成待测道路的情境信息来构建特征向量这一步骤,具体为:根据生成的邻接道路,获取待测道路的左情境信息和右情境信息,其中,所述左情境信息是指位于待测道路左边的邻接道路的历史交通状况,右情境信息是指位于待测道路右边的邻接道路的历史交通状况。进一步作为优选的实施方式,所述根据构建的特征向量,采用深度学习技术对待测道路的交通状况进行预测这一步骤,包括以下步骤:采用定向递归神经网络来分别对左情境信息和右情境信息的情境向量进行捕捉;采用双曲正切函数对捕捉的结果进行线性变换;采用平均函数对线性变换的结果进行特征强化处理;通过下采样层减少模型训练数据的过拟合;通过全连接层将特征与激活函数进行结合;采用softmax函数对待测道路的交通状况进行预测。进一步作为优选的实施方式,还包括对道路交通状况的预测结果进行评价的步骤。进一步作为优选的实施方式,所述对道路交通状况的预测结果进行评价这一步骤,包括以下步骤:对深度学习架构的性能进行评价;对情境信息的捕捉能力进行评价。与图1的方法相对应,本发明一种基于情境信息的交通状况预测系统,包括:获取模块,用于获取车辆gps原始数据,然后对车辆gps原始数据进行预处理,得到道路的轨迹数据;分类模块,用于采用聚类算法对得到的轨迹数据进行分类;生成模块,用于根据轨迹数据的分类结果,生成待测道路的邻接道路;构建模块,用于根据生成的邻接道路,通过生成待测道路的情境信息来构建特征向量,其中,待测道路的情境信息包括待测道路的左右邻接道路、待测道路的历史交通状况和邻接道路的历史交通状况;预测模块,用于根据构建的特征向量,采用深度学习技术对待测道路的交通状况进行预测。与图1的方法相对应,本发明一种基于情境信息的交通状况预测装置,包括:存储器,用于存储程序;处理器,用于加载程序,以执行本发明的一种基于情境信息的交通状况预测方法。下面根据从出租车上安装的gps设备获取到的gps原始数据,详细描述本发明一种基于情境信息的交通状况预测方法的具体步骤流程:s1、获取车辆gps原始数据,然后对车辆gps原始数据进行预处理,得到道路的轨迹数据;其中,步骤s1具体包括以下步骤:步骤s11、对车辆gps原始数据中的异常车速进行取代处理;步骤s11具体为:如果在一辆出租车上采集到的车速比同一时段所有出租车的平均车速快50%以上,则本发明采用所有出租车的平均车速来取代这个异常车速。步骤s12、对车辆gps原始数据中的异常数据进行过滤处理;步骤s12具体为:如果一个gps采集点(一辆出租车)在一天之内不存在持续三小时的gps数据,则本发明将删除该gps采集点在当天的全部数据。步骤s13、对车辆gps原始数据中的遗失数据进行补零处理;步骤s13具体为:如果出租车在某个时间戳的数据遗失,本发明会对该出租车在这个时间戳前后的数据进行平均,然后将这个平均后的结果作为遗失数据的补充值。步骤s14、对车辆gps原始数据中的时间戳进行均值处理;步骤s14具体为:本发明将gps取样点(即出租车)每三个时间戳的车速值进行平均。s2、采用聚类算法对得到的轨迹数据进行分类;由于实际地图上的每条道路都是由许多路段组成的,而为了提高预测的准确度,在本发明中的每一条道路实际指的是每一个路段,而一天中每个路段有不同的交通状况,所以本发明基于交通的相似性,采取聚类的方法产生每路段每天每时段的预测模型。其中,步骤s2具体包括以下步骤:步骤s21、基于预设的时间段和轨迹数据中的时间戳,将得到的轨迹数据划分成一系列轨迹线段;步骤s22、采用层次聚类法对轨迹线段进行分类。本实施例定义一个时间段为5分钟,定义deuclid(p1…n,q1…n)是轨迹线段p1…n和轨迹线段q1…n在每一取样时间t的点距离的总和,即:其中,n代表轨迹线段上的n个点;‖pt—qt‖代表轨迹线段pt和轨迹线段qt之间的欧几里得距离,其定义式为:其中,pt*x代表轨迹线段pt上的点的横坐标;qt*x代表轨迹线段qt上的点的横坐标;pt*y代表轨迹线段pt上的点的纵坐标;qt*y代表轨迹线段qt上的点的纵坐标。另外,本发明为了使聚类得到的簇可以为任何形状和尺寸,因此采用基于密度的dbscan聚类算法来实现,然后对每个簇中的轨迹线段的长度和角度进行平均,得到对应每个簇的代表轨迹数据。s3、根据轨迹数据的分类结果,生成待测道路的邻接道路;在现代城市的道路网络里,道路的交通状况总是受到与其相接的其它道路影响。如果周围的道路交通状况都非常繁忙,那本道路的交通绝不可能顺畅。所以,人们在预测一条道路的交通状况时,不仅要考虑该道路的历史交通状况,而且要考虑与其相连的邻接道路的路况,这些邻接道路提供的有用信息,起着类似于文本挖掘中命名排歧或文本分类任务中情境信息的作用。因此,本发明为了提高对道路交通状况的预测准确率,生成了待测道路的邻接道路。其中,步骤s3包括以下步骤:s31、获取每个簇的最小外接矩形;其中,本发明使用基于最小外接矩形(mbrs)获得的轨迹距离度量方法(轨迹距离度量可以提供最快的轨迹距离计算),以一条道路作为中心点,捕捉该道路代表性轨迹与周围某个范围内(如半径3公里内)其它代表性轨迹的相似度,如果相似度大于一定阈值,那么这些代表性轨迹所对应的道路就会作为待测道路的邻接道路。s32、根据各个最小外接矩形之间的最短距离,得到待测道路与其它道路之间的距离;设b1是道路轨迹p1的最小外接矩形,b2为道路轨迹p2的最小外接矩形,则距离dmin(b1,b2)表示b1和b2的任一对点之间的最小距离。s33、对待测道路与其它道路之间的距离进行排序;本发明根据dmin(b1,b2)的大小,排列所有距离,选择与这条道路最近的k条道路作为邻接道路。s34、根据排序的结果,将若干条其它道路确定为邻接道路。s4、根据生成的邻接道路,通过生成待测道路的情境信息来构建特征向量,其中,待测道路的情境信息包括待测道路的左右邻接道路、待测道路的历史交通状况和邻接道路的历史交通状况;本发明选择与待测道路最近的topk条道路作为邻接道路,本实施例中设k=5,设定时间节点t为10:00,以对待测道路在t+15分钟后的交通状况进行预测。参照表1,旗标表示在情境信息条件下特征的位置,其中,“c”表示着该特征为待测道路本身的信息;“l”代表待测道路的左情境信息;“r”代表待测道路的右情境信息,取决于该邻接道路处在待测道路的地理位置(左边或者右边)。如图2所示,每条线代表一条道路。本实施例选取路段“ab”作为中心点,设定k=5,则“bh”、“bg”和“ae”可以被处理为带“l”旗标的特征(因为它们在路段“ab”的左边),而“ac”和“cd”则可处理为带“r”旗标的特征,因为这五个路段都处在圆圈内。至于“ef”,它的部分线段虽然也处在圆圈内,但依照dmin的规则,它到“ab”的距离并不在top5选择范围内;虽然本发明的方法可以支持更多的信息来构建特征向量,例如,更多的邻接道路的历史交通状况,但考虑到计算成本,本实施例只使用6个“c”旗标特征和k个邻接道路来构建特征向量。另外,在实际应用中,由于获取实时交通状况是非常耗费资源的,所以本发明不考虑获取道路在t时间的实时交通状况;表1旗标特征c上周同一天t时间r路段的交通状况c上周同一天t+15时间r路段的交通状况c昨天t时间r路段的交通状况c昨天t+15时间r路段的交通状况c表示该天是否公众假日/周末的标志c表示该天是否工作日的阈值l邻接道路1在t+15时间的历史交通状况l邻接道路2在t+15时间的历史交通状况l邻接道路3在t+15时间的历史交通状况r邻接道路4在t+15时间的历史交通状况r邻接道路5在t+15时间的历史交通状况s5、根据构建的特征向量,采用深度学习技术对待测道路的交通状况进行预测;由步骤s4可知,本发明的特征向量仅是基于历史的轨迹数据而构建,所以,本发明采用深度学习技术,进一步从特征向量中提取深度特征,以提高本发明的预测准确度。其中,步骤s5具体包括以下步骤:s51、采用定向递归神经网络来分别对左情境信息和右情境信息的情境向量进行捕捉;s52、采用双曲正切函数对捕捉的结果进行线性变换;s53、采用平均函数对线性变换的结果进行特征强化处理;s54、通过下采样层减少模型训练数据的过拟合;s55、通过全连接层将特征与激活函数进行结合;s56、采用softmax函数对待测道路的交通状况进行预测。具体地,本发明定义为待测道路r的左情境信息,定义为待测道路r的右情境信息,和的值是相应的邻接道路转换后的交通状况特征向量;r也是一个向量,其包含了待测道路本身的特征。本发明基于非线性激活函数计算和的值,其计算公式具体为:其中,代表位于待测道路的左侧的第i条邻接道路;代表位于待测道路的右侧的第j条邻接道路;l代表邻接道路位于待测道路的左侧;r代表邻接道路位于待测道路的右侧;f是一个非线性激活函数;w(l)是将隐含层(左情境信息)转换为下一个隐含层的矩阵;w(r)是将隐含层(右情境信息)转换为下一个隐含层的矩阵。如图3所示,本发明的深度学习架构由递归卷积层、平均池化层、下采样层、全连接层和输出层组成,根据表1所示的特征,本架构中代表位于待测道路左侧第一近位置的邻接道路(即邻接道路1)的情境信息;代表位于待测道路左侧第二近位置的邻接道路(即邻接道路2)的情境信息;代表位于待测道路左侧第三近位置的邻接道路(即邻接道路3)的情境信息;代表位于待测道路右侧第一近位置的邻接道路(即邻接道路4)的情境信息;代表位于待测道路右侧第二近位置的邻接道路(即邻接道路5)的情境信息。将得到的左情境信息、待测道路本身的特征信息以及右情境信息进行级联,所述级联的表达式为:其中,n+m=k,本发明用一个逆向的lstm(长短期记忆网络)来处理左右邻接道路互换后的情况,然后再把两个lstm链接起来,从而形成双向lstm。得到x1和x2之后,本发明采用双曲正切函数对捕捉的结果进行线性变换得到y,线性变换的公式具体为:y=tanh(wx1+wx2+b),其中,y是一个矩阵,其包含了线性变换后得到的各种特征信息;tanh代表激活函数;w用于确定对应分割平面的方向;b用于确定竖直平面沿着垂直于直线方向移动的距离;本发明通过线性变换对x1和x2中的每一个因子加以分析,以得到最有用的因子。本发明通过深度学习架构中的递归卷积层来表述待测道路的特征,然后应用平均池化层来对特征进行强化,所述对特征进行强化的公式为:y*=average(y),其中,y*代表特征强化的结果;average()代表平均函数。本发明的平均函数是一个元函数,本实施例中取y中的每个特征信息的平均值作为到下一层的输入值,以减少模型训练数据的过拟合。本发明不使用最大池化层是因为本发明的深度学习架构中只有一个卷积层,平均池化更适合捕捉信息。池化层使用递归结构的输出作为输入,池化层的时间复杂度为o(n)。而整体架构是递归结构和平均池化层的级联,所以,整体时间复杂度仍为o(n)。然后,本发明使用下采样层来减少模型训练数据的过拟合,使用全连接层来将特征与激活函数进行结合,以便后续进行预测。最终,类似于传统神经网络,采用softmax函数对待测道路的交通状况进行预测,该函数可以将输出数转换为概率,本实施例中softmax函数的定义式为y**=wy*+b,其中,y**代表待测道路的交通状况的预测结果,它是是经过全链接层后最后的输出。本发明引入基于情境信息的交通状况预测概念,结合了rnn和cnn的深度学习架构。其中,rnn是在解决包含序列输入的困难的机器学习问题中占有重要地位的神经网络;cnn是强大的人工神经网络技术,可以保持问题的空间结构。在本发明中,我们在rnn中选用能够处理序列依赖的长短时记忆网络(lstm)。另外,相较于传统的神经网络架构,本发明的架构使用了情境信息,能够学习待测道路的隐含信息。s6、对道路交通状况的预测结果进行评价。在本实施例中采用数据组来对预测模型进行评价,该数据组取自北京市33条主要道路2013年5月份的30分钟时段。如图4所示,在该数据组里,每条道路都有最多四种交通状况,其中,1表示该路段交通状况严重拥堵,2表示该路段交通状况比较拥堵,3表示该路段交通状况一般拥堵,4表示该路段交通状况顺畅。由于道路交通状况预测是给驾驶员的推荐,需要保证预测结果尽可能接近实际路况,因此,本发明将预测任务处理为多级分类任务,具体采用普通的基于准确率和召回率的f值综合评价指标来进行路况评价,所述f值综合评价指标的计算公式为:其中,准确率=tp/tp+fp,召回率=tp/tp+fn;tp代表truepositive(真正),是正确标识属于正类的项目数;fp代表falsepositive(假正),是不正确标识属于正类的项目数;fn代表falsenegative(假负),是不正确标识属于正类但实际上也是正类的项目数。本发明的路况按拥堵程度分为4类,如果预测和真实情况相符则预测准确,由于本发明涉及多类的问题,所以使用正类来表示该条数据真实的类,使用假类来表示其他其中,步骤s6具体包括以下步骤:s61、对深度学习架构的性能进行评价;步骤s61具体为:通过采用传统的机器学习技术(比如c4.5算法、支持向量机(svm)、多层感知机(mlp)及cnn等)来对交通状况进行预测,进而实现对本发明的深度学习架构的性能评价。其中,对于svm,本实施例使用径向基函数(rbf)来对交通状况进行预测。对于cnn内核,本实施例将所有特征连接后,在预设窗口内执行嵌入。对于mlp、cnn和本发明的方法,本实施例均通过100次迭代去训练神经网络,最终使用softmax函数来输出预测的结果。通过本发明的道路交通状况预测方法与传统机器学习方法进行预测的比较结果如表2所示。表2方法准确率召回率f值c4.50.580.460.51svm0.60.550.57mlp0.750.70.72cnn0.830.870.85本发明0.880.910.895从表2可见,c4.5的准确率值只有0.58,而本发明准确率值高达0.88,比c4.5改进了超过50%,也比第二好的cnn法改进了大约5%。类似的,召回率和f值也可以看到相似的结果。s62、对情境信息的捕捉能力进行评价。本实施例中分别设定k=1,5,10,15,20,来对cnn法和本发明的方法进行比较。其中,当k=10时,两种方法的表现都达到最高峰值,但本发明的变化度不如cnn法明显,进一步说明了本发明的方法对k值的依赖程度较低,因为本发明的递归结构可以保存更久的情境信息,进而减少了噪音的导入。综上所述,本发明一种基于情境信息的道路交通状况预测方法、系统及装置具有以下优点:1)、本发明采用聚类算法对轨迹数据进行分类,能够分别对不同类别的道路进行预测处理,适用范围广;2)、本发明采用基于情境信息来构建特征向量的方法,能够充分结合待测道路的情境条件,提高交通状况预测的准确度,能够方便人们作出最合理的路线规划,减少了道路拥堵带来的时间浪费;3)、本发明的递归结构可以保存更久的情境信息,进而减少了噪音的导入,提高了道路状况预测的准确率;4)、本发明通过深度学习技术,将基于历史轨迹数据构建而来的特征向量进行深度特征提取,进一步提高了道路状况的预测准确度;5)、本发明在对待测道路的交通状况进行预测时,还考虑了与其相连的邻接道路的路况,提高了对道路交通状况的预测准确率。以上是对本发明的较佳实施进行了具体说明,但本发明并不限于所述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可做作出种种的等同变形或替换,这些等同的变形或替换均包含在本申请权利要求所限定的范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1