一种基于人工智能算法的视频数据边缘计算方法
本发明涉及一种基于人工智能算法的视频数据边缘计算方法,属于工业物联网安全领域。
背景技术:
随着汽车保有量的增加,有效、快速地检测和识别道路交通场景下的车辆、自行车和行人目标,对减少交通事故、保证人们的出行安全具有重要的研究价值与现实意义。因此基于图像视频序列中的场景目标检测一直是计算机视觉领域的研究热点。
随着人工智能快速发展,基于卷积神经网络的目标检测算法逐步取代了采用机器学习的传统目标检测的方法,显著提升了目标检测的精确度和鲁棒性。目前基于深度学习的目标检测任务主要有以下两类检测方法:一类是基于区域建议提取目标候选区域的两步检测网络,通常具有较高的检测精度,如fast-rcnn,faster-rcnn,mask-rcnn等;另一类是基于回归思想的单步检测模型,如yolo(youonlylookonce),ssd以及在此基础上改进的检测模型。通过在coco,voc等公开数据集上的测试分析,单步检测网络虽然在精度上稍逊色,但是,单步检测网络能实现实时检测。相比通用的目标检测任务,交通场景下的车辆行人川流不息,行车安全至关重要,需要快速将车辆、自行车以及行人等目标准确地检测出来,这对目标检测算法的检测速度、精度提出了更高的要求。
对道路交通场景下的车辆、行人等目标的检测任务,采用同时兼顾检测速度和精度的yolo算法。
技术实现要素:
为解决现有技术中的不足,本发明提供一种基于人工智能算法的视频数据边缘计算方法,能在汽车行驶中进行车辆、行人、自行车等物体的实时检测,计算出大致的距离,并在近距离时给出声音报警以辅助驾驶,通过边缘计算实现实时监测、并给出文字信息的提示、计算距离并给出报警等一系列操作,无需将数据上传服务器,以保障所需的实时性。
本发明中主要采用的技术方案为:
一种基于人工智能算法的视频数据边缘计算方法,具体步骤如下:
s1:采用摄像头采集行车视频流,利用激光测距传感器采集行人、车辆与使用者所在车辆之间的距离;
s2:开发板采用yolo算法对采集到的数据进行处理,将目标物体标注出来,具体方法如下:
s2-1:读取所述摄像头采集到的行车视频流的第一帧;
s2-2:对当前帧图像进行预处理;
s2-3:将预处理后的图像送入yolov4神经网络进行正向传播,本发明采用的;
s2-4:接收神经网络的正向传播结果,得到预测物体所在坐标以及置信度;
s2-5:将置信度大于0.5的预测物体筛选出来后,通过坐标绘制矩形框对筛选出来的预测物体的图像进行标注;
s2-6:根据矩形框的位置估算出预测物体与车的距离,根据距离的远近给矩形框上色;
s2-7:读取行车视频流的下一帧,重复上述阶段。
s3:将s1中摄像头采集激光测距传感器检测到的数据以及经s2数据处理后的结果反馈至显示屏和报警装置进行处理。
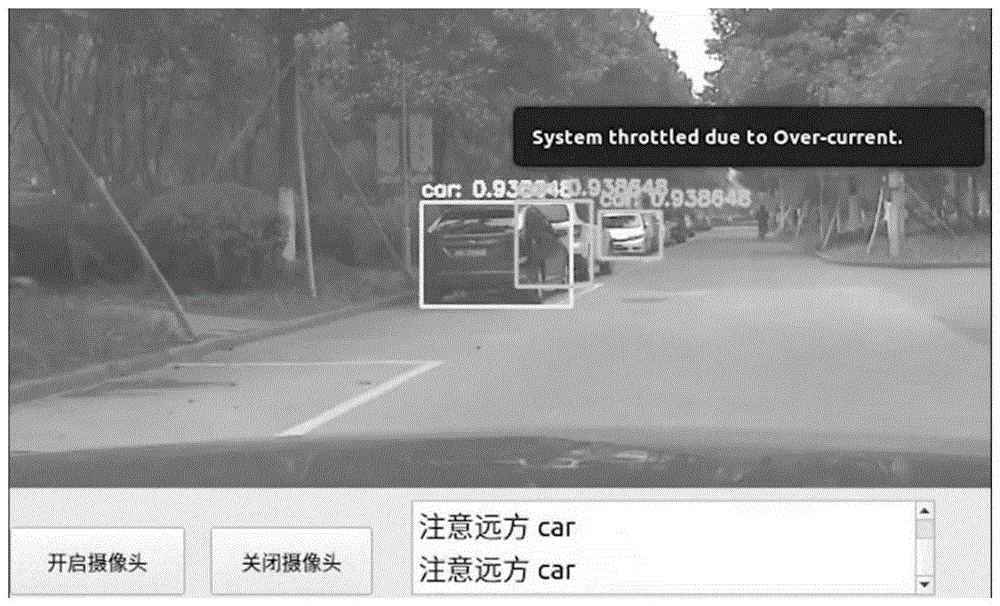
优选地,所述s2-6中,矩形框上色的具体方案如下:
记帧的高度为h,矩形框的高度为h,则当满足0<h<0.6h时,矩形框颜色为绿,显示屏的提示词为:注意远方;当满足0.6h≤h<0.7h时,,矩形框颜色为黄,显示屏提示词为:注意前方;当满足0.7h≤h时,矩形框颜色为红,显示屏出现红色闪烁,提示词为:请刹车!前方,同时播放语音警报。
有益效果:本发明提供一种基于人工智能算法的视频数据边缘计算方法,能在汽车行驶中进行车辆、行人、自行车等物体的实时检测,计算出大致的距离,并在近距离时给出声音报警,以辅助驾驶,通过边缘计算实现实时监测、并给出文字信息的提示、计算距离并给出报警等一系列操作,无需将数据上传服务器,以保障所需的实时性。
附图说明
图1是该发明的运行界面示意图;
图2是该发明的系统结构框图;
图3是该发明中yolo算法的网络结构图。
具体实施方式
为了使本技术领域的人员更好地理解
本技术:
中的技术方案,下面对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本申请保护的范围。
本发明的硬件装置结构具体如下:
如图2所示,采用jetsonnano作为开发板,视频数据由imx219摄像头采集,该摄像头具有800万像素,77度视场角,分辨率为3280×2464,目标物体与车辆的距离由vl53l1x激光测距传感器采集,该激光测距传感器精确测距范围可达4米,快速测距频率可达50hz,行车视频及算法标注的警报目标会一同在显示屏上传回给使用者;摄像头通过csi接口连接到jetsonnano开发板上,vl53l1x激光测距传感器通过杜邦线连接到jetsonnano开发板的40pingpio扩展接口上。
一种基于人工智能算法的视频数据边缘计算方法,具体步骤如下:
s1:采用摄像头采集行车视频流,利用激光测距传感器采集行人、车辆与使用者所在车辆之间的距离,用于在车后方主要进行盲区检测;
s2:开发板采用yolo算法对采集到的数据进行处理,将目标物体标注出来,具体方法如下:
s2-1:读取所述摄像头采集到的行车视频流的第一帧;
s2-2:对当前帧图像进行预处理,本发明中的预处理方式为:对数据进行翻转变换、旋转/反射变换、噪声注入和移动以此增强数据;
s2-3:将预处理后的图像送入yolov4神经网络进行正向传播,如图3所示为本发明中yolo算法的网络结构图;
s2-4:接收神经网络的正向传播结果,得到预测物体所在坐标以及置信度;
s2-5:将置信度大于0.5的预测物体筛选出来后,通过坐标绘制矩形框对筛选出来的预测物体的图像进行标注;
s2-6:根据矩形框的位置估算出预测物体与车的距离,根据距离的远近给矩形框上色;
s2-7:读取行车视频流的下一帧,重复上述阶段。
s3:将s1中激光测距传感器检测到的数据以及经s2数据处理后的结果反馈至显示屏和报警装置。
优选地,所述s2-6中,矩形框上色的具体方案如下:
如图1所示,记帧的高度为h,矩形框的高度为h,则当满足0<h<0.6h时,矩形框颜色为绿,显示屏的提示词为:注意远方;当满足0.6h≤h<0.7h时,,矩形框颜色为黄,显示屏提示词为:注意前方;当满足0.7h≤h时,矩形框颜色为红,显示屏出现红色闪烁,提示词为:请刹车!前方,同时播放语音警报。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
技术特征:
1.一种基于人工智能算法的视频数据边缘计算方法,其特征在于,具体步骤如下:
s1:采用摄像头采集行车视频流,利用激光测距传感器采集行人、车辆与使用者所在车辆之间的距离;
s2:开发板采用yolo算法对采集到的数据进行处理,将目标物体标注出来,具体方法如下:
s2-1:读取所述摄像头采集到的行车视频流的第一帧;
s2-2:对当前帧图像进行预处理;
s2-3:将预处理后的图像送入yolov4神经网络进行正向传播,本发明采用的;
s2-4:接收神经网络的正向传播结果,得到预测物体所在坐标以及置信度;
s2-5:将置信度大于0.5的预测物体筛选出来后,通过坐标绘制矩形框对筛选出来的预测物体的图像进行标注;
s2-6:根据矩形框的位置估算出预测物体与车的距离,根据距离的远近给矩形框上色;
s2-7:读取行车视频流的下一帧,重复上述阶段;
s3:将s1中摄像头采集激光测距传感器检测到的数据以及经s2数据处理后的结果反馈至显示屏和报警装置进行处理。
2.根据权利要求1所述的一种基于人工智能算法的视频数据边缘计算方法,其特征在于,所述s2-6中,矩形框上色的具体方案如下:
记帧的高度为h,矩形框的高度为h,则当满足0<h<0.6h时,矩形框颜色为绿,显示屏的提示词为:注意远方;当满足0.6h≤h<0.7h时,,矩形框颜色为黄,显示屏提示词为:注意前方;当满足0.7h≤h时,矩形框颜色为红,显示屏出现红色闪烁,提示词为:请刹车!前方,同时播放语音警报。
技术总结
本发明公开了一种基于人工智能算法的视频数据边缘计算方法,具体步骤如下:S1:采用摄像头采集行车视频流,利用激光测距传感器采集行人、车辆与使用者所在车辆之间的距离;S2:开发板采用YOLO算法对采集到的数据进行处理,将目标物体标注出来;将S1中摄像头采集激光测距传感器检测到的数据以及经S2数据处理后的结果反馈至显示屏和报警装置进行处理。本发明能在汽车行驶中进行车辆、行人、自行车等物体的实时检测,计算出大致的距离,并在近距离时给出声音报警,以辅助驾驶,通过边缘计算实现实时监测、并给出文字信息的提示、计算距离并给出报警等一系列操作,无需将数据上传服务器,以保障所需的实时性。
技术研发人员:陈媛芳;钟哲华;施昕辰;孙振宇;万好祎;姚岑
受保护的技术使用者:杭州电子科技大学
技术研发日:2021.04.29
技术公布日:2021.07.30
- 还没有人留言评论。精彩留言会获得点赞!