一种录音标记显示方法及装置与流程
本发明属于录音识别领域,尤其涉及一种录音标记显示方法及装置。
背景技术:
录音技术广泛应用于数码设备中,手机、MP3、MP4、数码摄像机等数码设备均具有录音机功能。用户通过数码设备的录音功能,可随时随地对身边的事情进行记录,以便于更清晰地恢复记录现场。
然而,现有的音频文件处理技术,在录音标记的显示上不够完善,不利于音频的定位播放。其原因在于,现有的音频文件处理技术,无法显示录音标记中的关键语句,也不能显示关键语句的相关内容,需要用户在一段很长的音频文件中,通过反复播放关键语句定位音频,耗时长,不利于音频的定位播放。
技术实现要素:
本发明实施例的目的在于提供一种录音标记显示方法,旨在解决现有的音频文件处理技术,在录音标记的显示上不够完善,不利于音频的定位播放的问题。
本发明实施例是这样实现的,一种录音标记显示方法,包括:
将识别到的关键语句所在的时间点前后预设时间段内的音频转换成文字;
通过关联所述时间点与转换的文字,建立时间点与文字的关联关系;
当检测到点击或者触摸所述时间点的操作时,根据所述关联关系,显示与所述时间点相对应的文字。
本发明实施例的另一目的在于提供一种录音标记显示装置,包括:
转换模块,用于将识别到的关键语句所在的时间点前后预设时间段内的音频转换成文字;
关联模块,用于通过关联所述时间点与转换的文字,建立时间点与文字的关联关系;
显示模块,用于当检测到点击或者触摸所述时间点的操作时,根据所述关联关系,显示与所述时间点相对应的文字。
在本发明实施例中,根据所述关联关系,显示与所述时间点相对应的文字,完善了录音标记的显示,有利于音频的定位播放。
附图说明
图1是本发明实施例提供的录音标记显示方法的实现流程图;
图2是本发明实施例提供的识别关键语句录音标记显示方法的实现流程图;
图3是本发明实施例提供的录音标记显示方法步骤S202的实现流程图;
图4是本发明实施例提供的识别设定的关键语句的实现流程图;
图5是本发明实施例提供的步骤S301的实现流程图;
图6是本发明实施例提供的录音标记显示装置的结构框图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
实施例一
图1是本发明实施例提供的录音标记显示方法的实现流程图,详述如下:
在步骤S101中,将识别到的关键语句所在的时间点前后预设时间段内的音频转换成文字;
预设时间段为系统默认或用户指定。
指定的方式如下:
显示时间段列表,所述时间段列表中包括多个时间段;
检测在时间段列表中指定的时间段;
将指定的时间段作为指定的前后预设时间段。
在步骤S102中,通过关联所述时间点与转换的文字,建立时间点与文字的关联关系;
根据时间先后的顺序,将时间点与转换的文字逐一关联,建立时间点与文字的关联关系。
在步骤S103中,当检测到点击或者触摸所述时间点的操作时,根据所述关联关系,显示与所述时间点相对应的文字。
当检测到点击或者触摸所述时间点的操作时,根据所述关联关系以及预先设的字体样式,显示与所述时间点相对应的文字;或,
当检测到点击或者触摸所述时间点的操作时,根据所述关联关系以及预先设的字体位置,显示与所述时间点相对应的文字;或,
当检测到点击或者触摸所述时间点的操作时,根据所述关联关系、预设的字体样式以及预设的字体位置,显示与所述时间点相对应的文字。
为便于说明,举例如下:
识别到关键语句后,将该识别到的关键语句的对应时间点前后的一段时间的音频转换成文字保存在数据库中。
时间可由使用者自行设定,如5秒、10秒。
在用户使用时点击或者触摸某个关键字的时间点时将这段时间点对应的文字也显示给用户,让用户获得更好的体验,结构大致如下:
开始-1:30----------------------------40:15--
|(点击、触摸或者其他操作显示)|
1:30前后一段时间内容 40:15前后一段时间内容
结束-55:20
|(点击、触摸或者其他操作显示)
55:20前后一段时间内容;
以设置关键字为“开始”和“结束”为例。“开始”出现的时间在1:30和40:15,“结束”出现在55:20。
这里当手动点击被标记的地方时,可以显示被标记时间点前后5秒的内容(直接显示通过语音识别出来的文字),以使用户在无需前后拖动进度条的前提下,可以直接确认所需内容,从而提高了挑选的效率。
在第二步中识别到关键词后,直接将关键词所在那段语音识别出的文字保留下来和标记一起保存。当检测到手动点击时,直接显示文字和标记。
在本发明实施例中,根据所述关联关系,显示与所述时间点相对应的文字,完善了录音标记的显示,节省了定位时间,提高了音频的定位播放效率。
实施例二
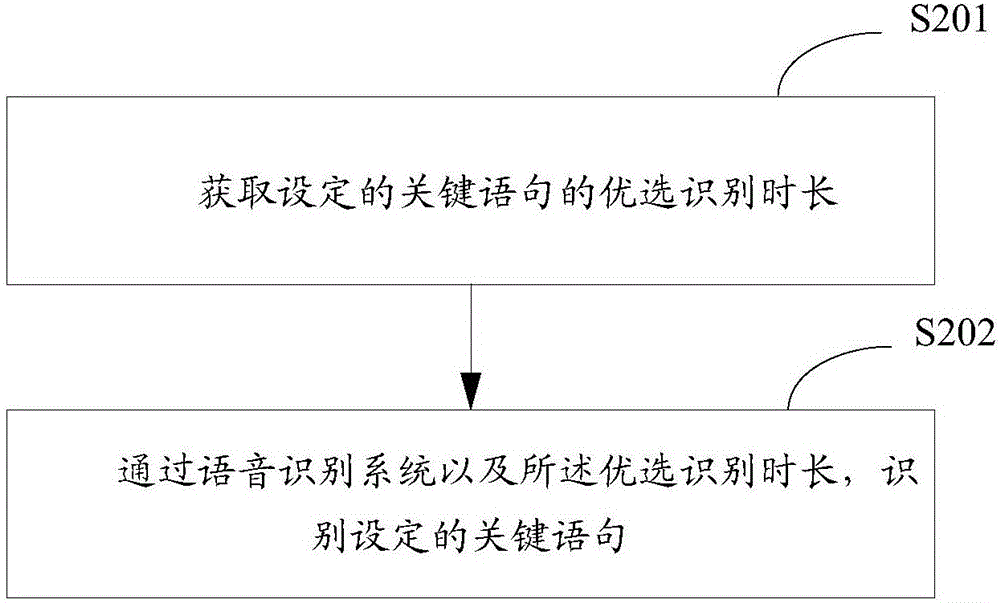
图2是本发明实施例提供的识别关键语句录音标记显示方法的实现流程图,详述如下:
在步骤S201中,获取设定的关键语句的优选识别时长;
输入识别时长,将输入的识别时长作为设定的关键语句的优选识别时长。
在步骤S202中,通过语音识别系统以及所述优选识别时长,识别设定的关键语句。
其中,录音或者播放录音文件时,可运行步骤S202。即,步骤S202的应用场景包括但不限于录音场景、播放音频场景。
判断识别到的关键语句所在的时间点是否处于优选识别时长内;
若不处于优选识别时长内,丢弃识别到的关键语句。
为便于说明,举例如下:
通过语音识别系统识别特定的语句,比如“开始”,“结束”等关键语句,也可以自己设定关键语句,可设置多个关键语句并通过语言识别系统获取关键语句的优选识别时长。
假设某款语音识别系统“开始”,“结束”的优选识别时长为3秒(即识别单个语句时若该音频超过3秒后这个语句再也不会被识别为“开始”或者“结束”。
在本发明实施例中,将识别到的关键语句和识别到的关键语句所在的时间点保存到数据库或者录音文件中,避免了出现关键语句识别错误后,重新识别的情况,从而大大提高了后期处理音频文件的效率,如在一段开幕式的录音音频文件中标记了“开始”能跳过冗长的开幕词直接跳转到开幕式正式开始的地方,如而不必一点点的拖动进度条找到“开始”关键词这在一段非常长的音频文件中尤为有效,而标记多个关键语句则让录音的结构清晰,非常方便的提取想要获得的音频文件内容。
实施例三
图3是本发明实施例提供的录音标记显示方法步骤S202的实现流程图,详述如下:
在步骤S301中,将录音文件拆分成指定的长度;
其中,录音或者播放录音文件时,可运行步骤S301。即,步骤S301的应用场景包括但不限于录音场景、播放音频场景。
录音文件为:录音得到的音频文件。
为便于说明,将音频文件按需求拆分成指定的长度,举例如下:
在以对应的关键语识别速度为第一优先级的情况下,可以将该长度设置长一点,如1分钟或者更久;
若要有一定的识别精度和识别速度时可以将改长度设置为短点,如30秒;
若对精度有较高的要求时,可以将长度设置为10秒或者更少;
长度不能小于关键语句的优选识别时长。
在步骤S302中,每次拆分完成,通过语音识别系统以及所述优选识别时长,识别设定的关键语句。
实施例四
图4是本发明实施例提供的识别设定的关键语句的实现流程图,详述如下:
在步骤S401中,将拆分后的录音文件识别为多个单词;
在步骤S402中,在多个单词中,将单词时长超过所述优选识别时长的单词排除,得到剩余的单词;
获取单词的播放起点和播放终点,根据播放起点和播放终点之间的时间长度,得到该单词的单词时长;
在多个单词中,将每个单词的单词时长与每个单词的优选识别时长进行比较,若单词的单词时长超过该单词的优选识别时长,则排除该单词,得到剩余的单词。
举例如下:
拆分后的录音文件的内容识别为ABCDE,C为单个词语,C播放起点为1:30,播放终点为1:32,由1:30和1:32,得到C的单词时长为2秒。
若C的优选识别时长为2.5秒,C的单词时长没有超过C的优选识别时长,则保留C;
若C的优选识别时长为1.9秒,C的单词时长超过C的优选识别时长,则排除C。
同理地,D为单个词语,D播放起点为1:33,播放终点为1:34,由1:33和1:34,得到C的单词时长为1秒。
若D的优选识别时长为1.5秒,D的单词时长没有超过D的优选识别时长,则保留D;
若D的优选识别时长为0.9秒,D的单词时长超过D的优选识别时长,则排除D。
采用上述操作,排除其它单词后,即可得到剩余的单词。
在步骤S403中,通过语音识别系统对剩余的单词进行识别。
可选地,作为本发明实施例的另一实施方式,可获取待识别的关键语句出现的时间点,若所述时间点处于所述优选识别时长内,则识别设定的关键语句。
举例如下:
某款语音识别系统“开始”,“结束”的优选识别时长为3秒,即识别单个语句时若该音频处于3秒内,这个语句可以被识别为“开始”或者“结束”。
实施例五
图5是本发明实施例提供的步骤S301的实现流程图,详述如下:
在步骤S501中,根据预先建立的识别速度与拆分长度的匹配关系,在预存的拆分长度中,匹配与当前的识别速度相对应的拆分长度;
其中,录音或者播放录音文件时,可运行步骤S501。即,步骤S501的应用场景包括但不限于录音场景、播放音频场景。
其中,通过将识别速度与拆分长度逐一对应,建立识别速度与定的关键语句匹配关系。
其中,显示识别速度列表,所述识别速度列表中包括多个识别速度;
检测在识别速度列表中指定的识别速度;
将指定的识别速度作为当前的识别速度。
在步骤S502中,根据匹配的拆分长度,每次拆分完成,且将指定的长度回退要识别的关键语句的优选识别时长后,再进行下一次拆分,直至录音结束或录音文件读取结束。
其中,在拆分时为了保证不会漏掉关键语句不识别,需要在每次拆分完之后再回退要识别的关键语句的优选识别时长后再进行下一次拆分。
举例如下:
以“开始”,“结束”作为关键字,若设置拆分长度为30秒,第一次拆分为0秒到30秒,第二次回退优选识别时长3秒在拆分则为27到57秒,第三次54秒到1分24秒,依此拆分方式一直到录音结束,在每段拆分完成后就对通过语音识别系统进行识别,以提高识别的效率。
如果没有回退要识别的关键语句的优选识别时长,设置拆分长度为30秒时,第一次拆分为0秒到30秒,第二次31秒到60秒,第三次1分1秒到1分30秒,依此拆分方式一直到录音结束。每段拆分完成后,由于没有回退要识别的关键语句的优选识别时长,关键语句可能存在于两段音频之间,如,存在于第一次的30秒和第二次31秒之间,存在于第二次的60秒和第三次1分2秒之间。这样即使通过语音识别系统进行识别,也会存在漏掉关键语句的情况,也就无法保证识别每一条关键语句,因此需要在每次拆分完之后再回退要识别的关键语句的最大识别时长后再进行下一次拆分,以提高识别的效率。
实施例六
本发明实施例描述了保存关键语句的实现流程,详述如下:
将识别到的关键语句和识别到的关键语句所在的时间点保存到数据库或者录音文件中。
为便于说明,举例如下:
关键语句为“开始”和“结束”。“开始”出现的时间在1:30和40:15,“结束”出现在55:20。
当1:30时语音识别系统识别出“开始”时通知程序开始保存该时间到“开始”对应的条目。
40:15和55:20时都执行相同步骤,最后保存的录音标记数据结构大致如下:
开始-1:30-40:15;
结束-55:20
实施例七
本发明实施例描述了标记颜色功能的实现流程,详述如下:
在显示或者播放音频文件时,通过列表将保存的关键语句和对应的时间点列出来,通过点击的方式让音频文件跳转到对应的时间点开始播放;或者,
通过在进度条中设置关键词的颜色,比如将“开始”设置为绿色将“结束”设置为红色,给进度条中对应的时间点标上颜色;或者,
将任意两个时间点之间的进度条设置为与普通进度条不同的颜色,如将第二个“开始”的时间点与“结束”的时间点之间的进度条标记为蓝色,通过拖动进度条开始从对应的时间点播放。
实施例八
图6是本发明实施例提供的录音标记显示装置的结构框图,该装置可以运行于电子设备中。为了便于说明,仅示出了与本实施例相关的部分。
参照图6,该录音标记显示装置,包括:
转换模块61,用于将识别到的关键语句所在的时间点前后预设时间段内的音频转换成文字;
关联模块62,用于通过关联所述时间点与转换的文字,建立时间点与文字的关联关系;
显示模块63,用于当检测到点击或者触摸所述时间点的操作时,根据所述关联关系,显示与所述时间点相对应的文字。
作为本实施例的一种实现方式,所述关键语句识别模块,包括:
拆分单元,用于将录音文件拆分成指定的长度;
识别单元,用于每次拆分完成,通过语音识别系统以及所述优选识别时长,识别设定的关键语句。
作为本实施例的一种实现方式,所述识别单元,具体包括:
第一识别子单元,用于将拆分后的录音文件识别为多个单词;
排除子单元,用于在多个单词中,将单词时长超过所述优选识别时长的单词排除,得到剩余的单词;
第二识别子单元,用于通过语音识别系统对剩余的单词进行识别。
作为本实施例的一种实现方式,所述拆分单元,包括:
匹配子单元,用于根据预先建立的识别速度与拆分长度的匹配关系,在预存的拆分长度中,匹配与当前的识别速度相对应的拆分长度;
回退子单元,用于根据匹配的拆分长度,每次拆分完成,且将指定的长度回退要识别的关键语句的优选识别时长后,再进行下一次拆分,直至录音结束或录音文件读取结束。
作为本实施例的一种实现方式,所述的录音标记显示装置,还包括:
优选识别时长获取模块,用于获取设定的关键语句的优选识别时长;
关键语句识别模块,用于通过语音识别系统以及所述优选识别时长,识别设定的关键语句。
本发明实施例提供的装置可以应用在前述对应的方法实施例中,详情参见上述实施例的描述,在此不再赘述。
通过以上的实施方式的描述,所属领域的技术人员可以清楚地了解到本发明可借助软件加必需的通用硬件的方式来实现。所述的程序可以存储于可读取存储介质中,所述的存储介质,如随机存储器、闪存、只读存储器、可编程只读存储器、电可擦写可编程存储器、寄存器等。该存储介质位于存储器,处理器读取存储器中的信息,结合其硬件执行本发明各个实施例所述的方法。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!