一种基于K‑means聚类的全脉冲数据无损压缩方法与流程
本发明属于数据压缩领域,具体涉及到一种基于K-means聚类的数据压缩方法,实现对电子对抗领域全脉冲数据的无损压缩。
背景技术:
在现代军事中,电子对抗在战略攻防中起着至关重要的作用。电子对抗是敌我双方采取各种电子措施和行动,用以削弱或破坏对方电子设备使用效能、保障己方电子设备发挥效能的一种作战方式。电子对抗侦察是电子对抗的重要组成部分,优良的电子对抗侦察技术是电子战中赢得先机的关键所在。
全脉冲数据是将侦察机中频脉冲所包含的关键特征参数以二进制进行存储的一种数据类型。全脉冲数据的特点为:(1)每个数据点包含五个参数,分别是脉冲到达时间(TOA)、脉冲宽度(PW)、脉冲幅值(PA)、脉冲载频(CF)和脉冲到达角(DOA);(2)数据以二进制格式表示,每个参数占用4个字节;(3)全脉冲数据量很大,不便于存储和传输;(4)全脉冲数据由于包含来自同一雷达发射源的大量重复脉冲的特征参数值,这些数据具有较强的相关性,因此存在大量的冗余。由于全脉冲数据量大,有必要对其进行压缩,以降低数据的大小,便于存储和传输;并且因为数据存在冗余,所以能够被压缩。全脉冲数据包含侦察机中频脉冲的关键特征信息,压缩和解压过程不能丢失任何信息,因此需要采用无损压缩。
聚类分析作为统计学的一个分支,主要用于数据挖掘领域。聚类算法包括K-means聚类、FCM聚类、Canopy聚类等等。K-means聚类算法易于描述,具有速度快且适用于处理大规模数据等优点。本发明首次提出将K-means聚类算法用于全脉冲数据的无损压缩。全脉冲数据记录了来自多个发射源的不同时刻的脉冲数据参数。来自同一发射源的多个脉冲,其特征参数值差异较小,具有很强的相关性,通过K-means聚类将其归于同一类簇中。对每个类簇中的数据,用数据点相对中心点的差值替代原数据值,得到的差值与原值相比数值较小。对差值编码后,输出码流占用的信息位较少,从而达到数据压缩的目的。
技术实现要素:
目前在数据压缩领域,通用的无损压缩算法(例如LZ系列编码)通常针对文本数据进行压缩,而对二进制格式的数据源压缩效果并不好。本发明提出一种基于K-means聚类的全脉冲数据无损压缩方法,该方法压缩效果好,可靠性高,能较好地将全脉冲数据进行无损压缩。
本发明采用的技术方案为先将数据做K-means聚类处理,数据相似性较大的点形成同一类簇,在每个类簇中保留中心点的数值,并用数据点与中心点的差值代替原数据,处理后差值会比原数据值小很多。然后将差值先做行程编码,再做区间编码。由于编码后的码流占用的信息位较少,能够取得较好的压缩效果。
为实现上述目的,本发明主要包括以下步骤:
步骤一:对包含侦察机中频数据关键参数信息的全脉冲数据进行K-means聚类,得到多个类簇及每个类簇的中心点。
K-means聚类需要事先指定聚类数K。一般情况下,聚类数K取值在之间,其中n为数据集的样本个数。实际应用中,真实的聚类数未知。经验表明,聚类数K在大于真实值情况下,压缩效果变化不大,而在聚类数K小于真实值时,压缩效果较差。一般电子战中,目标个数(即聚类数)在二十以内,所以本发明选择聚类数此种K值选择方法在时间复杂度与压缩效果上都有良好表现。
步骤二:将每个类簇内部所有数据点与该类簇中心点做差,得到差值数据。
步骤三:将差值做行程编码。
步骤四:将行程编码后的数据做区间编码。
步骤五:将区间编码后的码流与中心值一起输出得到压缩结果。
采用本发明提出的技术方案能够获得以下有益效果:本发明能够对全脉冲数据进行无损压缩,并且以较小的时间开销获得2倍左右的压缩比。本发明相对于直接将数据进行编码而不进行K-means聚类预处理而言,可以获得约20%左右的压缩倍数提升。这是因为本发明提出的基于K-means聚类的无损压缩方法有以下特点:1)K-means聚类对高维数据有较好的相关性,并且计算速度较快;2)聚类中采用预先确定聚类数目的处理方法,以较小的时间开销获得较好的压缩效果;3)对差值数据进行编码与直接对原始数据编码相比,更有利于提高编码效率。
附图说明
图1是基于K-means聚类的全脉冲数据无损压缩流程图。
图2是K-means聚类算法流程图。
图3是K-means聚类效果示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加明确,下面详述基于K-means聚类的全脉冲数据无损压缩算法的具体实施步骤。
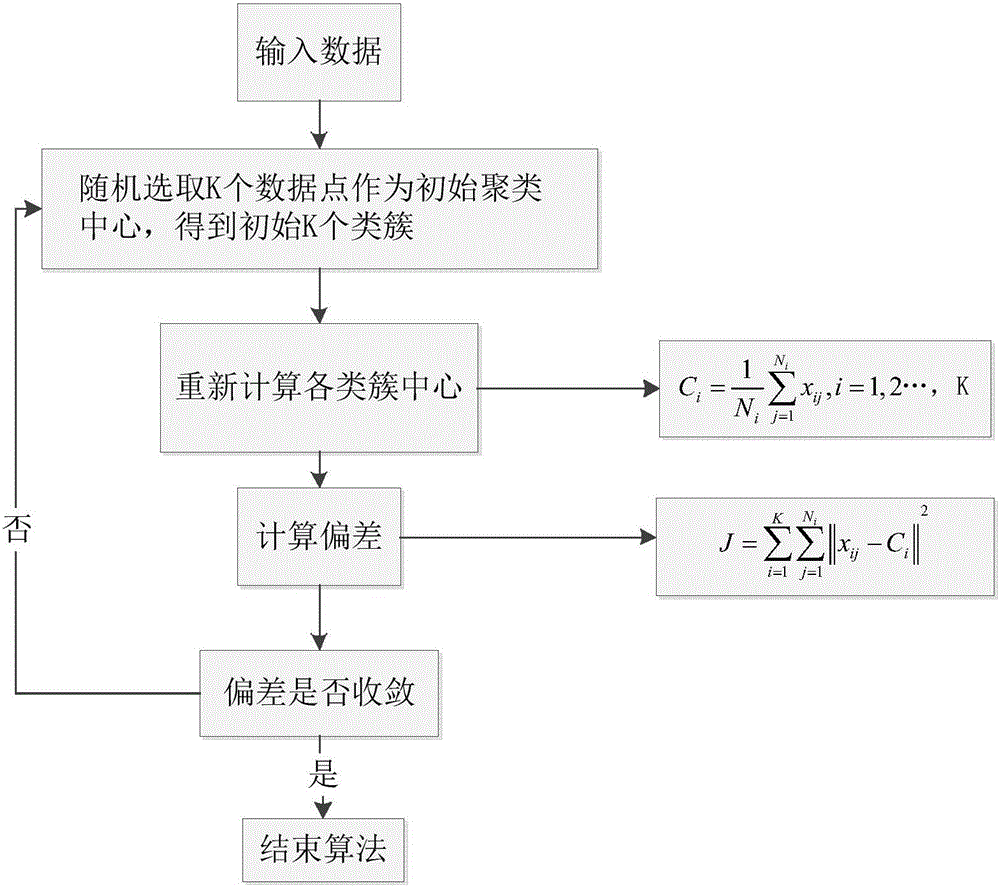
如图1所示,基于K-means聚类的全脉冲数据无损压缩方法包括以下步骤:
步骤一:对输入的全脉冲数据进行K-means聚类变换,将数据源X重新组合成一系列类簇的集合C={C1,C2,……,CK}。其中,C1∪C2∪…∪CK=X,i≠j;i,j=1,2,……,K。
K-means聚类的具体流程如图2所示:
1)输入数据源X包含n个数据点{x1,x2,…,xn},每个数据点为包含p个特征参数的
p维数据。
2)随机选取K个数据点作为各个类簇的初始聚类中心,分别计算每个数据点到K个聚
类中心的欧氏距离,若满足某个数据点与某一类簇中心的距离小于其与所有其他聚类
中心的距离,则把该数据点划分到这一聚类中心所代表的类簇中,得到初始K个聚
类划分;
3)重新计算K个新的聚类中心:
其中,μi表示第i个类簇的中心点,Ni表示第i个类簇中的数据点个数,xij表示第i
个类簇中第j个数据点;
4)计算每个类簇数据点与其中心点的欧氏距离,求出各类簇总的距离和(也即偏差)J。
具体计算公式如下:
5)不断重复步骤3)和4)的计算,对算法的收敛性进行判断:聚类的目标是使各类簇总
的距离和,即偏差J达到最小。若经过反复迭代后求得的偏差J的变化小于某一预设
精度值ε,(假设ε=10-6),则表明算法收敛,计算结束,否则返回2)重新计算。
K-means聚类效果示意图如图3所示。随机生成150个二维数据,每50个随机数据为一类,均值分别为[-1,-1],[1,1],[1,-1],方差均为[1,1]。经过K-means聚类处理后,数据被准确分为三类,每类的中心点与其均值非常接近,聚类效果较好。
步骤二:经过K-means聚类算法处理过的数据形成K个类簇,对于每个类簇,求数据点与中心点的差值。
步骤三:将每个点的差值数据看成字节流,对其进行行程编码。
步骤四:将行程编码后的数据进行区间编码。
为了获得较好的压缩效果,本发明采用了区间编码算法。区间编码是将所输入数据映射到某一整数区间内,最终输出一个属于该区间的整数作为输出编码。区间编码能够实现比霍夫曼编码一个符号一位这个压缩上限还要高的压缩率。
区间编码主要包括以下步骤:
1)以字节为单位对行程编码后的数据进行读取,每个字节数据看作一个符号,统计符号的种类数N,作为所有符号的总计频度T的初始值。
2)设定一个初始整数区间[L,H],并初始化区间的上、下界:上界H=0xf0000000,下界L=0x00000000,则初始区间的范围R=0xf0000000。另外,设定区间正规化的最小范围Rmin=0x00010000。
3)计算不同符号所对应的初始映射区间。根据某一符号S当前的频度fs、累积频度Fs以及所有符号的总计频度T,计算出符号S的初始映射区间[L',H']。
符号S的累积频度Fs是指符号值小于S的其它符号(x<S)的频度总和,可利用公式(3)进行计算:
初始映射区间[L',H']的上、下界H'、L'及范围R'具体见公式(4)、(5)、(6)。其中,div表示整除运算。
R'=RdivT×fs (4)
L'=L+RdivT×Fs (5)
H'=L'+R'-1=L+RdivT×(Fs+fs)-1 (6)
4)对含有多个符号的数据进行编码时,根据当前输入的符号不断更新其映射区间。更新原则是下个输入符号映射区间的计算是基于上个符号的映射区间进行的。具体计算仍采用公式(4)至(6),公式中的参数采用自适应的方法进行更新。即当前输入符号S后,其频度fs加1,累积频度Fs和所有符号的总计频度T也相应地进行计算更新。根据更新后的频度fs、累积频度Fs以及所有符号的总计频度T,得到更新后的符号S的映射区间[L',H']。
5)当更新后的映射区间范围R'<Rmin(Rmin表示最小区间范围)或以字节为单位比较新区间的上、下界,当上下界的高位字节相等时,移出相同的高位字节作为输出码流,并对区间进行正规化处理。
6)按照以上步骤对所有输入数据进行编码。编码结束时,移出映射区间内所有的位作为输出码流,并保存为二进制文件。
步骤五:将区间编码后形成的二进制文件与中心值一起保存为输出文件。
应用实例:
选用一段全脉冲数据作为样本,大小为3721KB,数据点个数n=10000,每个数据点包含5个特征参数。数据源为6类,聚类数K选为50,经过K-means聚类压缩后,大小为1868KB,压缩率为50.2%。全脉冲数据的无损压缩效果与具体的数据样本有密切关系,对有些全脉冲数据,压缩率可以达到30%左右。
本发明提出的方法不限于具体实施方式中所述的实例,本领域技术人员根据本发明的技术方案得出其他的实施例,只要是利用K-means聚类变换对全脉冲数据进行无损压缩的算法,包括实现相应功能的装置,也同样属于本发明的创新范围,需要受到保护。
- 还没有人留言评论。精彩留言会获得点赞!