一种基于LZ77的编码方法与流程
本发明涉及数据压缩技术领域,尤其涉及一种基于LZ77的编码方法。
背景技术:
LZ77编码是一种开源的字典压缩算法,属于无损压缩,广泛应用于gzip、LZMA等常用压缩工具。字典压缩的原理是构建一个字典,存储已编码窗口中出现的重复字符串,然后用相应的编码代替文件中与字典内字符串相匹配的字符串。其中,字典存储的重复字符串最大长度是字典容量与压缩质量的重要影响因素之一。字典内重复字符串的最大长度越大,字典容量越大,耗内存越多,搜索匹配过程越长,压缩速度越慢,压缩质量越高。
当前,随着互联网、物联网的飞速发展,数据文件规模越来越大,压缩文件所需的压缩时间越来越长,占用的CPU资源也越来越多,需要采用FPGA等硬件加速手段,以降低CPU占用率,减少数据中心功耗。但是,FPGA内存资源有限,不能构建大容量的压缩字典,压缩质量受限。
因此,对于本领域技术人员而言,如何在不增加字典容量的基础上提升压缩质量为亟需解决的技术问题。
技术实现要素:
为了便于理解,对本申请文件中出现的部分词语,澄清如下:
LZ77:基于字典的、“滑动窗”的无损压缩算法,在本申请文件中为具有一种编码理论的算法集合,其中所述编码理论的特征为:总会包含一个动态窗口和预读缓冲器,并在动态窗口中寻找与预读缓冲器中最匹配的数据,如果匹配的数据长度大于最小匹配长度,那么就输出一对(长度(length),距离(distance))数组,长度(length)是匹配的数据长度,距离(distance)说明了在输入流中向后多少字节这个匹配数据可以被找到;
重复字符串编码:在LZ77中输出的(长度(length),距离(distance))数组,其中长度(length)为重复字符串长度编码,距离(distance)为重复字符串偏移量编码。
基于背景技术存在的技术问题,本发明提出了一种基于LZ77的编码方法,包括以下步骤:
对字符进行LZ77编码;
读入LZ77编码;
判断当前字符编码结果,若当前字符编码结果为重复字符串编码,则判断相邻之前的字符编码结果,若相邻之前的字符编码结果为重复字符串编码,则判断当前字符编码结果与相邻之前的字符编码结果的距离是否相同,若相同,则将当前字符编码结果与相邻之前的字符编码结果进行合并。
优选地,包括以下步骤:
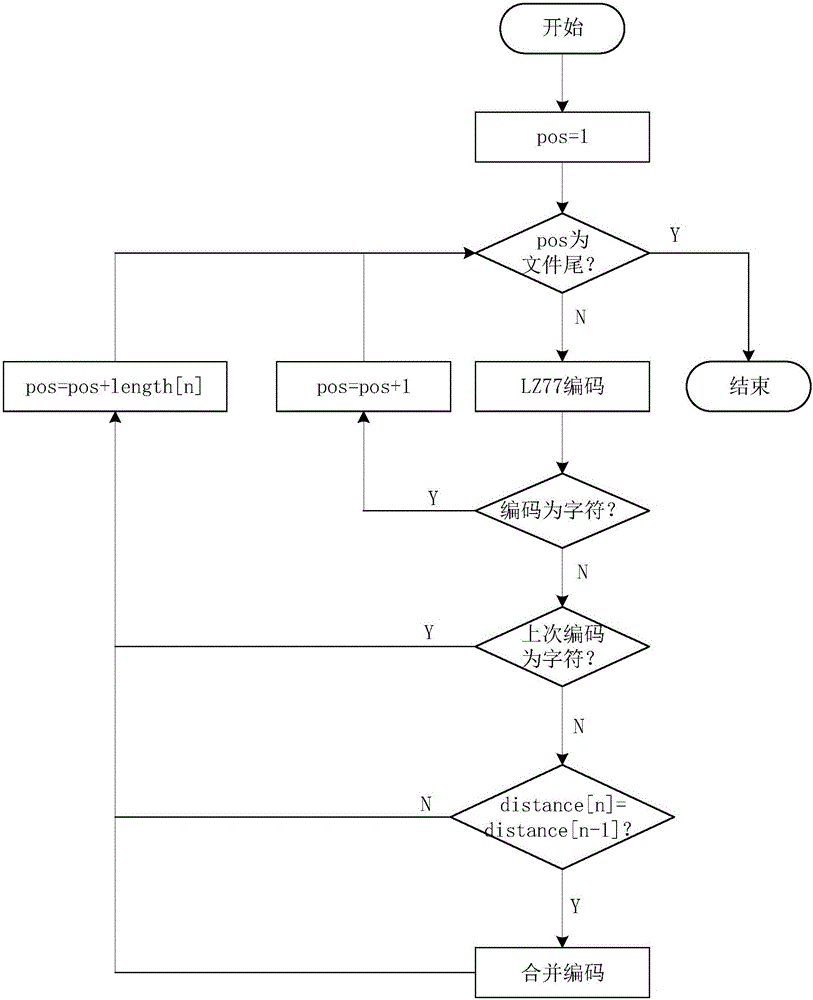
S1:初始化编码位置;
S2:对当前位置字符进行LZ77编码;
S3:读入上述LZ77编码;
S4:若当前位置编码结果为字符,编码位置右移1位,转入S2;若当前位置编码结果为重复字符串编码(length[n],distance[n]),转入S5;
S5:判断上次编码结果,若上次编码结果为字符,编码位置右移length[n]位,转入S2;若上次编码结果为重复字符串编码(length[n-1],distance[n-1]),转入S6;
S6:比较distance[n-1]与distance[n],若distance[n-1]与distance[n]不相等,则编码位置右移length[n]位,转入S2;若distance[n-1]与distance[n]相等,则将重复字符串编码(length[n],distance[n])和重复字符串编码(length[n-1],distance[n-1])合并为(length[n]+length[n-1],distance[n]),编码位置右移length[n]位,转入S2。
优选地,包括以下步骤:判断编码位置是否为文件尾,当编码位置为文件尾时,编码结束。
优选地,包括以下步骤:
S1:对所有字符进行LZ77编码;
S2:初始化编码结果位置;
S3:读入当前位置LZ77编码结果;
S4:若当前位置编码结果为字符,编码结果位置右移一位,转入S3;若当前位置编码结果为重复字符串编码(length[n],distance[n]),转入S5;
S5:判断上次位置编码结果,若上次位置编码结果为字符,编码结果位置右移length[n]位,转入S3;若上次位置编码结果为重复字符串编码(length[n-1],distance[n-1]),转入S6;
S6:比较distance[n-1]与distance[n],若distance[n-1]与distance[n]不相等,则编码结果位置右移length[n]位,转入S3;若distance[n-1]与distance[n]相等,则将重复字符串编码(length[n],distance[n])和重复字符串编码(length[n-1],distance[n-1])合并为(length[n]+length[n-1],distance[n]),编码结果位置右移length[n]位,转入S3。
优选地,包括以下步骤:判断编码结果是否为文件尾,当编码结果位置为文件尾时,编码结束。
本发明中提供的一种基于LZ77的编码方法,在对字符进行LZ77编码后,对相邻匹配串编码进行合并,具体为相邻的重复字符串编码,若是偏移量编码相同,则进行合并;上述方法至少具有以下优点:
1、通过对相邻匹配串编码的合并,在不增加字典存储的字符串长度,不增加字典内字符串搜索匹配的复杂度的前提下,可以降低压缩文本容量,提升压缩质量,并能保持较快的压缩速率;
2、既可以在LZ77编码过程中将符合要求的相邻匹配串编码进行合并,也可以完成整个文本完成LZ77编码后将符合要求的相邻匹配串编码进行合并,同时,可以将符合要求的相邻匹配串编码均进行合并从而最大限度的提升压缩质量,也可以限定相邻匹配串编码的合并次数或限定合并后匹配串编码的最大长度,因此,具有良好的灵活性。
附图说明
图1为本发明提出的一种基于LZ77的编码方法中一种实施例的流程示意图;
图2为本发明提出的一种基于LZ77的编码方法中另一种实施例的流程示意图。
具体实施方式
如图1-2所示,图1为本发明提出的一种基于LZ77的编码方法中一种实施例的流程示意图;图2为本发明提出的一种基于LZ77的编码方法中另一种实施例的流程示意图。
下面结合附图和实施例对本发明进行详细的描述。
实施例1
参考图1,假设待压缩字符串为:ABCDEFGHIJKABCDEFGHIJK,重复字符串最大长度为4,本发明所公开的一种基于LZ77的编码方法,包括以下步骤:
S1:初始化,pos=1;
S2:当前位置编码结果为字符,无重复字符串,编码结果为:A,pos=2;
S3:当前位置编码结果为字符,无重复字符串,编码结果为:AB,pos=3;
S4:当前位置编码结果为字符,无重复字符串,编码结果为:ABC,pos=4;
S5:当前位置编码结果为字符,无重复字符串,编码结果为:ABCD,pos=5;
S6:当前位置编码结果为字符,无重复字符串,编码结果为:ABCDE,pos=6;
S7:当前位置编码结果为字符,无重复字符串,编码结果为:ABCDEF,pos=7;
S8:当前位置编码结果为字符,无重复字符串,编码结果为:ABCDEFG,pos=8;
S9:当前位置编码结果为字符,无重复字符串,编码结果为:ABCDEFGH,pos=9;
S10:当前位置编码结果为字符,无重复字符串,编码结果为:ABCDEFGHI,pos=10;
S11:当前位置编码结果为字符,无重复字符串,编码结果为:ABCDEFGHIJ,pos=11;
S12:当前位置编码结果为字符,无重复字符串,编码结果为:ABCDEFGHIJK,pos=12;
S13:当前位置发现与已编码窗口相匹配的最大长度重复字符串“ABCD”,编码结果为:ABCDEFGHIJK(4,11);
S14:判断上次编码结果,上次编码结果为字符,无需合并,编码位置右移4位,pos=16;
S15:当前位置发现与已编码窗口相匹配的最大长度重复字符串“EFGH”,编码结果为:ABCDEFGHIJK(4,11)(4,11);
S16:判断上次编码结果,上次编码结果为重复字符串编码(4,11),本次编码结果为重复字符串编码(4,11),判断两者的偏移量编码均为11,进行编码合并,得到编码结果为:ABCDEFGHIJK(8,11),编码位置右移4位,pos=20;
S17:当前位置发现与已编码窗口相匹配的最大长度重复字符串“IJK”,编码结果为:ABCDEFGHIJK(8,11)(3,11);
S18:判断上次编码结果,上次编码结果为重复字符串编码(8,11),本次编码结果为重复字符串编码(3,11),判断两者的偏移量编码均为11,进行编码合并,得到编码结果为:ABCDEFGHIJK(11,11),编码位置右移3位,pos=23;
S19:pos为文件尾,编码结束,最终编码结果为ABCDEFGHIJK(11,11)。
在上述实施例1中,我们可以获知,实施例1采用的在LZ77编码过程中将符合要求的相邻匹配串编码进行合并,并将将符合要求的相邻匹配串编码均进行合并从而最大限度的提升压缩质量;在实施例1中,假设待压缩字符串为:ABCDEFGHIJKABCDEFGHIJK,重复字符串最大长度为4,得到的编码结果为ABCDEFGHIJK(11,11),而若采用LZ77进行编码,获得的编码结果为ABCDEFGHIJK(4,11)(4,11)(3,11),通过对比可知,通过对相邻匹配串编码的合并,在不增加字典存储的字符串长度,不增加字典内字符串搜索匹配的复杂度的前提下,可以降低压缩文本容量,提升压缩质量,并能保持较快的压缩速率。
实施例2
参考图2,假设待压缩字符串为:ABCDEFGHIJKABCDEFGHIJK,重复字符串最大长度为4,本发明所公开的一种基于LZ77的编码方法,包括以下步骤:
S1:对待压缩字符串ABCDEFGHIJKABCDEFGHIJK进行LZ77编码,编码结果为:ABCDEFGHIJK(4,11)(4,11)(3,11);
S2:读入编码“A”,其为字符编码,无需合并,继续读入编码;
S3:读入编码“B”,其为字符编码,无需合并,继续读入编码;
S4:读入编码“C”,其为字符编码,无需合并,继续读入编码;
S5:读入编码“D”,其为字符编码,无需合并,继续读入编码;
S6:读入编码“E”,其为字符编码,无需合并,继续读入编码;
S7:读入编码“F”,其为字符编码,无需合并,继续读入编码;
S8:读入编码“G”,其为字符编码,无需合并,继续读入编码;
S9:读入编码“H”,其为字符编码,无需合并,继续读入编码;
S10:读入编码“I”,其为字符编码,无需合并,继续读入编码;
S11:读入编码“J”,其为字符编码,无需合并,继续读入编码;
S12:读入编码“K”,其为字符编码,无需合并,继续读入编码;
S13:读入编码“(4,11)”,其为重复字符串编码,判断上次位置编码结果为字符编码,无需合并,继续读入编码;
S14:读入编码“(4,11)”,其为重复字符串编码,判断上次位置编码结果为重复字符串编码(4,11),判断两者的偏移量编码均为11,将编码(4,11)和(4,11)合并为(8,11),继续读入编码;
S15:读入编码“(3,11)”,其为重复字符串编码,判断上次位置编码结果为重复字符串编码(8,11),判断两者的偏移量编码均为11,将编码(8,11)和(3,11)合并为(11,11),继续读入编码;
S16:处于编码结果尾端,结束合并,获得最终编码结果为ABCDEFGHIJK(11,11)。
在上述实施例2中,我们可以获知,实施例2采用的是完成整个文本完成LZ77编码后将符合要求的相邻匹配串编码进行合并,并将将符合要求的相邻匹配串编码均进行合并从而最大限度的提升压缩质量;在实施例2中,假设待压缩字符串为:ABCDEFGHIJKABCDEFGHIJK,重复字符串最大长度为4,将采用LZ77进行编码,获得的编码结果为ABCDEFGHIJK(4,11)(4,11)(3,11)最终合并为ABCDEFGHIJK(11,11),通过对比可知,通过对相邻匹配串编码的合并,在不增加字典存储的字符串长度,不增加字典内字符串搜索匹配的复杂度的前提下,可以降低压缩文本容量,提升压缩质量,并能保持较快的压缩速率。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!