基于k段分解的低复杂度极化码折叠硬件构架的实现方法与流程
本发明涉及极化码折叠硬件构架的实现方法,特别是涉及基于k段分解的低复杂度极化码折叠硬件构架的实现方法。
背景技术:
Ar1kan提出,极性码是信道编码的第一类,几乎可实现对称的二进制输入离散无记忆信道的容量(B-DMCs)。由于其较低的计算复杂度为O(NlogN),其中N为极化码长度;以及快速傅氏变换Fast Fourier Transformation(FFT)形式的译码结构,串行抵消译码successive cancellation(SC)算法已经成为最有效的极化译码算法之一。大多数极化码译码方案都已SC为基础进行译码处理。
然而SC译码算法遵循的基本译码原则是利用以译出的比特信息最为反馈信息按照顺序逐个比特进行译码,这样的译码操作带来了巨大的硬件资源消耗问题。对于N比特码长的极化码,其所需的计算单元为N log2N,经过现有的时序硬件优化设计,在带有预计算的混合节点硬件构架中,共需要的硬件处理单元数为N-1。由此可以看出,当极化码的码长数量级较大时,译码所需的硬件处理单元与码长处于同一数量级。这样的硬件配置消耗了大量的硬件资源。根据极化码本身的性质,极化码在码长趋于无穷的时候才能达到逼近香浓线的性质。当我们的硬件平台资源占有限的时候,传统的SC译码硬件设计成为了制约极化码码长的致命因素。
技术实现要素:
发明目的:本发明的目的是提供一种能够有效降低硬件资源消耗的基于k段分解的低复杂度极化码折叠硬件构架的实现方法。
技术方案:为达到此目的,本发明采用以下技术方案:
本发明所述的基于k段分解的低复杂度极化码折叠硬件构架的实现方法,包括以下步骤:
S1:将n级SC译码算法分解为k段,k是n的因子,满足n=kp的关系式,p为整数,极化码的码长为N,且N=2n;
S2:对于已分解的k段SC译码算法,配置(k-1)个次级译码器,每个译码器的译码级数为p级,根据式(1)计算各段的折叠集:
......
式(1)中,Si为第i段的折叠集,1≤i≤(k-1),令w为各折叠集的总操作数,即Si中具有w个元素,则x1=w/2p-1-2n-p,为每段的折叠操作向量,表示第i段的第m个折叠操作,
S3:根据步骤S2得到的各段折叠集搭建极化码折叠硬件构架。
进一步,所述步骤S1包括以下步骤:
S1.1:确定输入:对于一帧极化码的N个输入数据[y1,y2,...,yN],求得对应的LLR值,记为其中为中q=0、r=1的情况,1≤t≤N,q表示译码器第i级输出的LLR,r表示原始译码器中第r次并进节点计算结果;确定待译码的码长为N,所需分段的段数为k;
S1.2:按照以下步骤建立分段解码函数:
S1.2.1:设n=log2N,且p=n/k;
S1.2.2:判断段数k是否为1:若k=1,则将输入进码长为2p的解码器进行传统的解码计算,得到2p比特译码结果并将作为解码函数的输出,结束本轮的操作;否则,设变量h=1,然后进入步骤S1.2.3;
S1.2.3:如果h≤2p/2,则令变量j=2h-1,i=1,然后进入步骤S1.2.4;否则,进入步骤S1.2.9;
S1.2.4:如果i≤2n-p,则将输入码长为2p的解码器进行传统的解码计算,计算第j位对应的LLR值然后进入步骤S1.2.5;否则,进入步骤S1.2.6;
S1.2.5:变量i的数值加一,并进入步骤S1.2.4;
S1.2.6:调用分段解码函数将分段解码函数的输出赋给变量
S1.2.7:调用分段解码函数将分段解码函数的输出赋给变量
S1.2.8:变量h的数值加一,并进入步骤S1.2.3;
S1.2.9:得到N比特译码结果并将作为分段解码函数的输出,结束本轮操作。
有益效果:本发明公开了一种基于k段分解的低复杂度极化码折叠硬件构架的实现方法,针对原本长码极化码硬件资源消耗高的问题,首先将SC译码算法分解为k段,每一段都可以通过码长为2p的短码译码步骤组合完成。然后在相对应的硬件构架设计上,通过短码极化码构架的迭代折叠,实现长码译码。极大降低了硬件复杂度,降低了硬件资源消耗,提升了节点资源利用率。
附图说明
图1为传统的SC译码算法的8比特SC译码流程图;
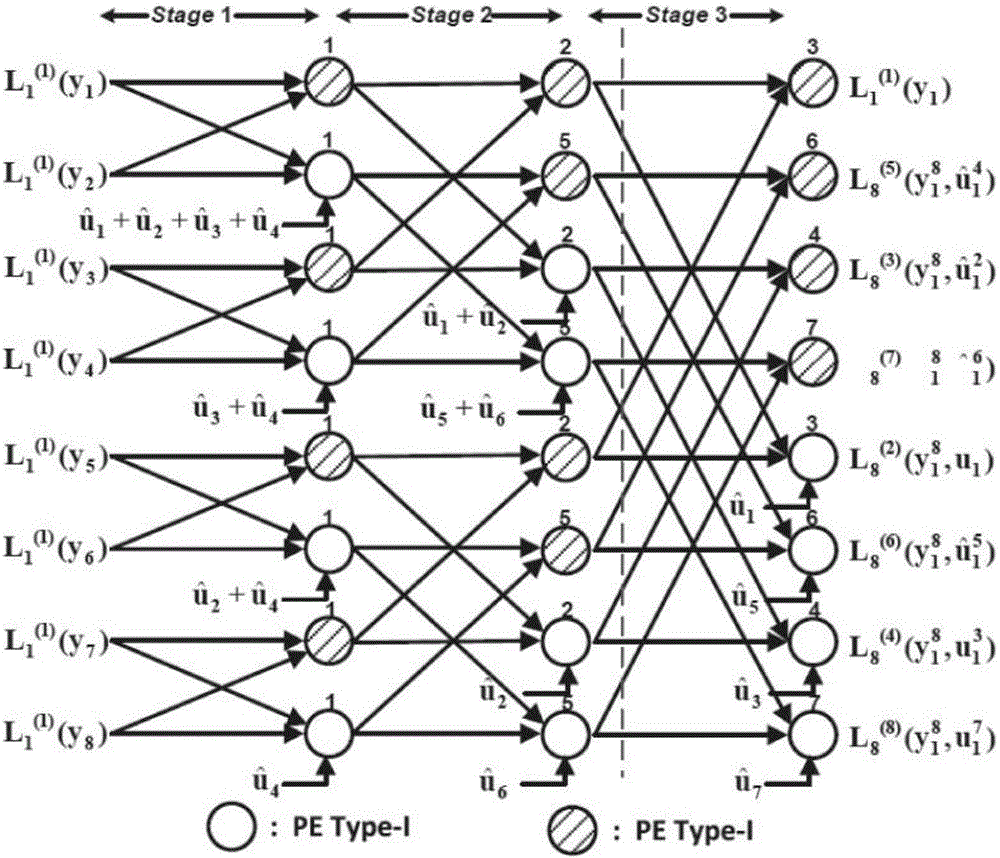
图2为本发明具体实施方式的基于k=3段分解的8比特SC译码折叠硬件构架的示意图;
图3为本发明具体实施方式的基于k=3段分解的64比特SC译码折叠硬件构架的示意图。
具体实施方式
下面结合具体实施方式对本发明的技术方案作进一步的介绍。
首先介绍一下传统的SC译码算法。
考虑一个极化码(N,K,A),其中N表示极化码的码长,K表示极化码中有效信息数,A表示有效信息比特集合。设接收端接收到的待译码向量为yi=(y1,...,yN),接收端的译码结果表示为如果ui不是有效信息比特,我们将置零。否则译码比特可以表示为:
其中,定义了信道传输概率。解码运算中使用LLR(log-likelihood ratio)来计算,LLR的定义如下:
LLR的运算法则满足下列递推关系式:
传统的SC译码器符合FFT碟形译码规则。
蝶形译码流程度见图1。图1给出了一个8比特SC译码流程图,在这个译码流程一共包含了3级(3=log8)。
下面介绍一下本具体实施方式的基于k段分解的低复杂度极化码折叠硬件构架的实现方法,包括以下步骤:
S1:将n级SC译码算法分解为k段,k是n的因子,满足n=kp的关系式,p为整数,极化码的码长为N,且N=2n;
步骤S1包括以下步骤:
S1.1:确定输入:对于一帧极化码的N个输入数据[y1,y2,...,yN](即译码器的输入数据),求得对应的LLR值,记为其中为中q=0、r=1的情况,1≤t≤N,q表示译码器第i级输出的LLR,r表示原始译码器中第r次并进节点计算结果;确定待译码的码长为N,所需分段的段数为k;
S1.2:按照以下步骤建立分段解码函数:
S1.2.1:设n=log2N,且p=n/k;
S1.2.2:判断段数k是否为1:若k=1,则将输入进码长为2p的解码器进行传统的解码计算,得到2p比特译码结果并将作为解码函数的输出,结束本轮的操作;否则,设变量h=1,然后进入步骤S1.2.3;
S1.2.3:如果h≤2p/2,则令变量j=2h-1,i=1,然后进入步骤S1.2.4;否则,进入步骤S1.2.9;
S1.2.4:如果i≤2n-p,则将输入码长为2p的解码器进行传统的解码计算,计算第j位对应的LLR值然后进入步骤S1.2.5;否则,进入步骤S1.2.6;
S1.2.5:变量i的数值加一,并进入步骤S1.2.4;
S1.2.6:调用分段解码函数将分段解码函数的输出赋给变量
S1.2.7:调用分段解码函数将分段解码函数的输出赋给变量
S1.2.8:变量h的数值加一,并进入步骤S1.2.3;
S1.2.9:得到N比特译码结果并将作为分段解码函数的输出,结束本轮操作。
S2:对于已分解的k段SC译码算法,配置译码器。如果每一段都分配一个译码器硬件构架,那么一共需要k个p级译码器完成原本的n级译码器设计。在每一段中,由于只分配一个译码器,则要完成该段原本的译码任务需要进行不同次数的折叠复用。下表给出了每一段完成一次原始操作所需p级译码器的折叠次数。
表1各段完成一次原始操作所需p级译码器的折叠次数
从上表的折叠次数可以发现,隔段之间存在并行操作的可能。例如,第i段译码输出了第一组2p个LLR的译码结果,则第i+1段可以开始工作,与此同时,第i段依旧在工作状态进行着下一组2p个LLR的译码。由此我们在每段上都设定一个短码译码器是合理的。但需要注意的是,最后一段的折叠次数是一,也就是说最后两段之间是不存在并行计算的,那么我们将最后两段合并为一个p级译码器。这样本具体实施方式最终的译码器设定为(k-1)个p级译码器。根据式(4)计算各段的折叠集:
......
式(4)中,Si为第i段的折叠集,1≤i≤(k-1)令w为各折叠集的总操作数,即Si中具有w个元素,则x1=w/2p-1-2n-p,为每段的折叠操作向量,表示第i段的第m个折叠操作,
S3:根据步骤S2得到的各段折叠集搭建极化码折叠硬件构架。
除此之外,对于每一段的折叠操作,可以采用流水线的形式来计算。因为段内的折叠不涉及到互相反馈信息,所以段内折叠操作可以采用流水线形式来大大缩短因折叠而带来的延时增长。
采用带有预计算功能的极化码SC译码构架作为折叠的基础。每个次级译码器遵从该构架的设计基础。图2给出了基于三段分解的8-比特译码器硬件构架图。原始的带有预计算功能的8比特译码器需要7个混合节点模块。8比特对应了3级译码。在本具体实施方式中,我们先将原始的三级译码算法分为三段,则每段由级数为1的次级译码器完成,再根据硬件设计中后两段折叠合并的规则,最终通过两个次级译码器完成所有操作。每个次级译码器为2-比特译码器。则最终的折叠构架只需要两个混合节点模块,相比于原来的7个混合节点模块,本设计大大缩短了原始的硬件复杂度。
图3给出了基于三段分解的64-比特译码器硬件构架图。原始的带有预计算功能的64比特译码器需要63个混合节点模块。64比特对应了6级译码。在本设计中,我们先将原始的六级译码算法分为三段,则每段由级数为2的次级译码器完成,再根据硬件设计中后两段折叠合并的规则,最终通过两个次级译码器完成所有操作。每个次级译码器为4-比特译码器。则最终的折叠构架只需要6个混合节点模块,相比于原来的63个混合节点模块,本具体实施方式大大缩短了原始的硬件复杂度。
为了更好的对比分析本设计带来的硬件优势,定义指标“硬件资源利用率”为译码所需计算单元数与硬件实际提供的计算单元数之比。在SC译码算法中,译码所需的计算单元数为N log2N,而不同的硬件设计下,实际的计算单元数为硬件架构本身包括的计算模块数量乘以译完一帧所消耗的延时周期。
根据本具体实施方式(k-1)个次级译码器的设计思路,很容易得到本设计构架所消耗的计算单元数M如下:
根据折叠集的分布,以及各段中的流水线操作,可以计算出本设计所消耗的延时数量L如下:
由此可以计算出本设计的硬件资源利用率(HUR):
根据HUR的计算公式,可以对不同的码长N与不同的分段情况k进行构架分析,分析结果列表如下:
表2不同N与k取值下的HUR对比表
当k=1时,表示一共只有1段,也就是没有进行段分解操作,换句话说就是原始的译码构架没有进行段内折叠。从上表中看出,当k不为1时本具体实施方式提出的折叠架构在硬件资源利用率上有了明显的提高,这说明本具体实施方式的设计是有效的。
下面进行硬件资源消耗分析:
本具体实施方式的核心旨在降低SC译码的硬件复杂度。换句话说,本具体实施方式的核心是保证了硬件资源有限的情况下依旧能够完成长码的SC译码需求。本具体实施方式主要针对译码计算单元进行了折叠。折叠后,根据译码计算单元数来表达硬件资源消耗。下表分析展示了本具体实施方式所需的译码计算单元数:
表3不同N与k取值下的硬件架构计算单元资源对比表
从表3可以看出,当k=1时,表示一共只有1段,也就是没有进行段分解操作,换句话说就是原始的译码构架没有进行段内折叠。从表3可以看出,当k不为1时本具体实施方式提出的折叠架构在硬件资源消耗上有了明显的降低,这说明本具体实施方式的设计是有效的。
下面进行VLSI实测分析:
根据本具体实施方式的思想,发明人在Altera Stratix V上实现了不同N与k的各规格译码器,其资源消耗如下:
表4不同极化码规格下的译码器硬件实现资源消耗对比
表4给出了两组码长的对比。对于8-比特的译码器,进行了2段分解后的译码器的资源消耗是未进行分段的一半。对于024-比特的译码器,进行了3段分解后的译码器的资源消耗是未进行分段的十分之一。硬件实现的真实数据再次证明了本具体实施方式的有效性。
- 还没有人留言评论。精彩留言会获得点赞!