低密度奇偶校验码的编码方法、装置、电子设备及介质与流程
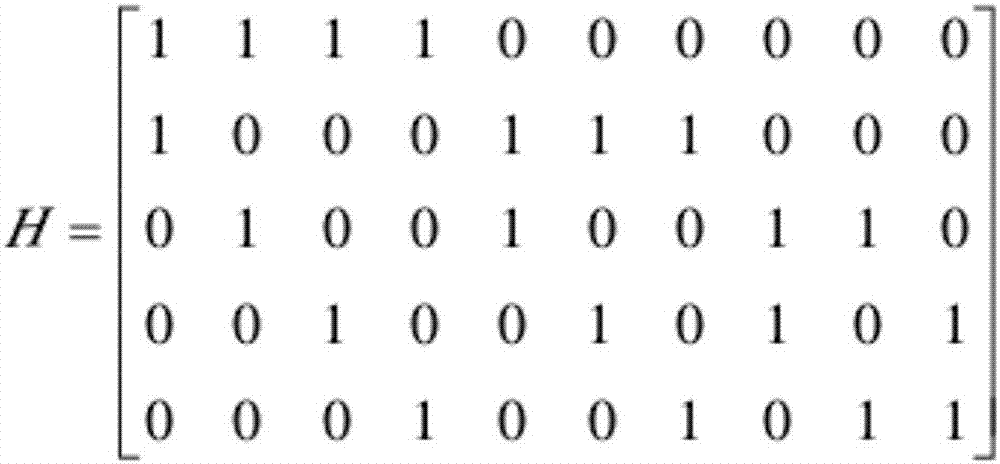
本发明涉及信道编解码技术领域,特别是涉及一种低密度奇偶校验码的编码方法、装置、电子设备及介质。
背景技术:
低密度奇偶校验码(ldpc,lowdensityparitycheckcode)是线性分组码的一种,可以由生成矩阵g或者校验矩阵h唯一确定,ldpc码包括规则码和非规则码两类,规则码可以表示为{dv,dc}(n,k),其中,n,k分别表示经过编码之后的码长和编码之前的信息位长度,dv,dc分别表示校验矩阵h每列非零元素的个数和每行非零元素的个数。通常,一个二进制的线性分组码可以用tanner图(又称编码二分图)来表示,如图1所示为一个{2,4}(10,5)规则码的校验矩阵,图2为图1所示校验矩阵对应的tanner图。其中,校验矩阵每列代表变量节点,每行代表校验节点,连接变量节点和校验节点的边对应于校验矩阵中的非零元素,如果变量节点i和校验节点j之间有边相连,则对应于校验矩阵第i行和第j列元素为1,即hi,j=1,vj为校验矩阵中的第j列变量节点,ci为校验矩阵中的第i行校验节点,i,j均为大于或等于1的正整数。
现有技术中,通常采用ldpc码迭代算法进行译码,来降低误码率。但是,由于tanner图中存在短环,如图3所示,短环为v1到c1,c1再到v3,v3再到c2,c2又回到了v1,这样,重叠的短环容易构成陷阱集t(a,b),其中,a表示译码后错误的变量节点的个数,b表示译码后码字不满足校验方程的校验节点的个数,且b个校验节点在陷阱集中与奇数个变量节点相连,一旦译码器陷入陷阱集,陷阱集里的变量节点就不能正确译码,就算多次采用ldpc码迭代算法,误码率也不下降,误码率基本保持不变(即,误码平台)。可见,陷阱集是造成误码平台的主要原因,误码平台的存在使得误码率保持在一定水平。
技术实现要素:
本发明实施例的目的在于提供一种低密度奇偶校验码的编码方法、装置、电子设备及介质,以打破ldpc码迭代算法进行译码中的陷阱集,降低误码平台,降低误码率。具体技术方案如下:
第一方面,本发明实施例提供了一种低密度奇偶校验码的编码方法,包括:
获取预设码长码字,对所述预设码长码字进行预设次数的译码,得到所述预设码长码字的错误水平列表;所述预设码长码字的一个码字为校验矩阵的一个变量节点;
根据所述预设码长码字的长度,确定所述错误水平列表中第一预设个数的出错码字比特及第二预设个数的可信度码字比特;其中,所述出错码字比特的出错次数大于所述可信度码字比特的出错次数;
在所述预设码长码字对应的校验矩阵中添加第一预设个数的校验节点,并根据所述第一预设个数的出错码字比特及第二预设个数的可信度码字比特,生成所述校验矩阵对应的第一预设个数的扩展校验矩阵;
根据所述扩展校验矩阵,对原始信息比特进行编码,得到所述扩展校验矩阵对应的码字,所述原始信息比特为所述预设码长码字在未编码前的信息比特减去第一预设个数信息比特的信息比特,且所述原始信息比特个数为所述预设码长码字在未编码前的信息比特个数减去第一预设个数的差。
可选的,所述对所述预设码长码字进行预设次数的译码,得到所述预设码长码字的错误水平列表的步骤包括:
通过预设算法对所述预设码长码字进行预设次数译码,得到所述预设码长码字的错误水平列表;所述预设算法包括:蒙特卡洛算法及最小和译码算法。
可选的,所述通过预设算法对所述预设码长码字进行预设次数译码,得到所述预设码长码字的错误水平列表的步骤包括:
在预设信噪比时,通过最小和译码算法对所述预设码长码字进行预设次数迭代译码,得到所述预设码长码字中每个码字对应的码字比特的错误水平;
根据所述预设码长码字中每个码字对应的码字比特的错误水平,通过蒙特卡洛算法,估计所述每个码字对应的码字比特的错误水平,生成所述预设码长码字的错误水平列表。
可选的,所述根据所述预设码长码字的长度,确定所述错误水平列表中第一预设个数的出错码字比特及第二预设个数的可信度码字比特的步骤包括:
针对所述错误水平列表中的码字比特,按每个码字比特出错次个数对所述错误水平列表中的码字比特进行降序排列,并获得降序排列后所述错误水平列表中的第一预设个数的出错码字比特;
针对所述错误水平列表中的码字比特,按每个码字比特出错次数对所述错误水平列表中的码字比特进行升序排列,并获得升序排列后所述错误水平列表中的第二预设个数的可信度码字比特;所述第二预设个数为所述预设码长码字对应的校验矩阵中每行中非零元素的个数减去1之后的差,所述预设码长码字对应的校验矩阵为编码所述预设码长码字的校验矩阵。
可选的,所述在所述预设码长码字对应的校验矩阵中添加第一预设个数的校验节点,生成包括所述第一预设个数的出错码字比特及第二预设个数的可信度码字比特的第一预设个数的扩展校验矩阵的步骤包括:
获取所述所述预设码长码字对应的校验矩阵的编码二分图,其中,所述编码二分图包括:校验节点、变量节点及连接所述校验节点和所述变量节点的边;
将所述编码二分图中的变量节点按照每个变量节点在所述错误水平列表中的每个变量节点出错次数进行升序或者降序排列;
在排列后的编码二分图中的校验节点之后添加所述所述第一预设个数的校验节点;
将所述第一预设个数的校验节点中的每个校验节点连接至所述第一预设个数的出错码字比特和所述第二预设个数的可信度码字比特中的每个码字比特,生成所述编码二分图对应的扩展二分图;
根据所述扩展二分图中各校验节点和变量节点的连接关系,生成第一预设个数的扩展校验矩阵。
第二方面,本发明实施例提供了一种低密度奇偶校验码的编码装置,包括:
获取单元,用于获取预设码长码字,对所述预设码长码字进行预设次数的译码,得到所述预设码长码字的错误水平列表;所述预设码长码字的一个码字为校验矩阵的一个变量节点;
确定单元,用于根据所述预设码长码字的长度,确定所述错误水平列表中第一预设个数的出错码字比特及第二预设个数的可信度码字比特;其中,所述出错码字比特的出错次数大于所述可信度码字比特的出错次数;
添加单元,用于在所述预设码长码字对应的校验矩阵中添加第一预设个数的校验节点,并根据所述第一预设个数的出错码字比特及第二预设个数的可信度码字比特,生成所述校验矩阵对应的第一预设个数的扩展校验矩阵;
编码单元,用于根据所述扩展校验矩阵,对原始信息比特进行编码,得到所述扩展校验矩阵对应的码字,所述原始信息比特为所述预设码长码字在未编码前的信息比特减去第一预设个数信息比特的信息比特,且所述原始信息比特个数为所述预设码长码字在未编码前的信息比特个数减去第一预设个数的差。
可选的,所述获取单元具体用于,通过预设算法对所述预设码长码字进行预设次数译码,得到所述预设码长码字的错误水平列表;所述预设算法包括:蒙特卡洛算法及最小和译码算法。
可选的,所述获取单元具体用于:
在预设信噪比时,通过最小和译码算法对所述预设码长码字进行预设次数迭代译码,得到所述预设码长码字中每个码字对应的码字比特的错误水平;
根据所述预设码长码字中每个码字对应的码字比特的错误水平,通过蒙特卡洛算法,估计所述每个码字对应的码字比特的错误水平,生成所述预设码长码字的错误水平列表。
第三方面,本发明实施例提供了一种电子设备,包括处理器、通信接口、存储器和通信总线,其中,处理器,通信接口,存储器通过通信总线完成相互间的通信;
存储器,用于存放计算机程序;
处理器,用于执行存储器上所存放的程序时,实现本发明所述的低密度奇偶校验码的编码方法步骤。
第四方面,本发明实施例提供了一种计算机可读存储介质,所述计算机可读存储介质内存储有计算机程序,所述计算机程序被处理器执行时实现本发明所述的低密度奇偶校验码的编码方法步骤。
本发明实施例提供的一种低密度奇偶校验码的编码方法、装置、电子设备及介质,可以获取预设码长码字,对该预设码长码字进行预设次数的译码,得到该预设码长码字的错误水平列表;根据预设码长码字的长度,确定错误水平列表中第一预设个数的出错码字比特及第二预设个数的可信度码字比特;在预设码长码字对应的校验矩阵中添加第一预设个数的校验节点,并根据第一预设个数的出错码字比特及第二预设个数的可信度码字比特,生成所述校验矩阵对应的第一预设个数的扩展校验矩阵,进一步,基于扩展校验矩阵,对原始信息比特进行编码,得到该扩展校验矩阵对应的码字。
本方案中,通过在预设码长码字对应的校验矩阵中添加预设个数的校验节点,生成扩展校验矩阵。这样,可以通过该扩展矩阵对预设码长码字在未编码前的码字进行编码的过程,打破ldpc码迭代算法进行译码中的陷阱集,降低误码平台,进一步,生成的码字相对于通过校验矩阵对预设码长码字在未编码前的码字进行编码生成的码字,误码率低,可见,本发明实施例降低了误码率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为规则码的校验矩阵的一种示意图;
图2为图1所示的校验矩阵对应的tanner图;
图3为tanner图中存在的短环示意图;
图4为tanner图中存在的陷阱集的示意图;
图5为本发明实施例提供的低密度奇偶校验码的编码方法的一种流程图;
图6为本发明实施例提供的确定错误的码字比特的示意图;
图7为本发明实施例提供的各码字的错误水平示意图;
图8为本发明实施例提供的扩展二分图的示意图;
图9为本发明实施例提供的添加不同数量的校验节点后误码率的仿真图;
图10为本发明实施例提供的低密度奇偶校验码的编码装置的结构示意图;
图11为本发明实施例还提供了一种电子设备的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本发明。
实际应用中,低密度奇偶校验码ldpc的校验矩阵h一定是稀疏矩阵,即h中0的个数远比1的个数多,所以低密度奇偶校验码ldpc可以实现快速线性编码。通常,在对ldpc译码过程中,陷阱集的形成是由于tanner图中存在短环,而导致译码失败的错误变量节点的集合成为陷阱集,其中,陷阱集可以表示为t(a,b),如图4所示,圆形表示变量节点,正方形表示校验节点,当译码器进入陷阱状态时,陷阱集中的变量节点vt=[v1,v2,v3,v4]同时处于错误状态,并且,具有偶数度(与vt=[v1,v2,v3,v4]连接的边的数目为偶数)的校验节点ct=[c2,c3,c4,c5,c6]均满足校验方程,校验节点ct=[c2,c3,c4,c5,c6]在迭代译码过程中向vt=[v1,v2,v3,v4]传播错误消息,具有奇数度的校验节点[c1,c7]不满足校验方程,接收陷阱集以外其他变量节点的消息,阻止错误消息传播,但由于数量较少不足以纠正校验节点vt=[v1,v2,v3,v4]的错误,在迭代过程中,错误消息不断得到增强,最终导致译码失败。
为了打破ldpc码迭代算法进行译码中的陷阱集,降低误码平台,降低误码率,本发明实施例提供了一种低密度奇偶校验码的编码方法的过程,如图5所示,该过程可以包括以下步骤:
s501,获取预设码长码字,对所述预设码长码字进行预设次数的译码,得到所述预设码长码字的错误水平列表。
本发明实施例所提供的低密度奇偶校验码的编码方法可以应用于低密度奇偶校验码的编译码系统中,具体的,应用于低密度奇偶校验码的编译码系统中的一编码装置对应的应用程序。
实际应用中,校验矩阵的每列代表一个变量节点,每行代表一个校验节点,一个校验矩阵对应一个校验方程组,例如,图1所示的校验矩阵的校验方程可以表示为:
其中,vj表示校验矩阵中第j列的变量节点,
通常,校验矩阵可以用于确定低密度奇偶校验码ldpc码。在规则码校验矩阵h={dv,dc}(n,k)中,校验矩阵h的大小可以为m×n,其中,m≥n-k表示校验节点或校验方程的个数,而且只有当h满秩时,才有m=n-k,当h满秩时,规则码的码率r=k/n=1-dv/dc。
其中,预设码长码字的一个码字为校验矩阵的一个变量节点。预设码长码字是通过校验矩阵编码之后所得到的码字,校验矩阵的变量节点的个数决定预设码长码字中码字的个数。
例如,预设码长码字可以为:{3,6}(96,48),其中,48表示未编码前的信息位比特,96表示编码后的码字(其中,包括48个校验位比特和48个信息位比特),也即96个变量节点。
本发明实施例中,在一定信噪比下,对预设码长码字进行预设次数(例如,100000次)的译码,得到到该预设码长码字的错误水平列表。错误水平列表表示预设码长码字中的每个码字与该码字的错误次数的对应关系表。例如,在4db信噪比下,对预设码长码字进行100000次的迭代译码,可以计算得到该预设码长码字的错误水平列表。
具体的,可以通过预设算法对预设码长码字进行预设次数译码,得到该预设码长码字的错误水平列表。
其中,预设算法包括:蒙特卡洛算法及最小和译码算法。通常,确定译码过程中陷阱集是比较困难的,本发明实施例在打破陷阱集时,采用蒙特卡洛算法搜索最容易出错的码字和可信度最高的码字,由于最容易出错的码字往往包含在很多的陷阱集中,导致误码平台。本发明实施例避免直接去研究复杂的陷阱集,即不需要预先获知陷阱集内部的具体信息,就可以打破陷阱集,进而降低了计算的复杂度,提高算法的可操作性,并且实现了打破陷阱集的有益效果。
本发明实施例中,可以通过蒙特卡洛算法及最小和译码算法对预设码长码字进行预设次数译码,可以获得该预设码长码字的错误水平列表,也就是通过蒙特卡洛算法及最小和译码算法两个算法对编码后的变量节点进行预设次数的译码,得到变量节点的错误水平列表。
其中,通过预设算法对预设码长码字进行预设次数译码,得到预设码长码字的错误水平列表的过程可以为:在预设信噪比时,通过最小和译码算法对预设码长码字进行预设次数迭代译码,得到该预设码长码字中每个码字对应的码字比特的错误水平,进一步,根据预设码长码字中每个码字对应的码字比特的错误水平,通过蒙特卡洛算法,估计每个码字对应的码字比特的错误水平,生成该预设码长码字的错误水平列表。
在对预设码长码字进行预设次数译码时,首先,要选择译码过程所处的信噪比的环境,因为不同信噪比下,每个码字对应的码字比特的错误水平存在差别,所以,可以在预设信噪比时,对预设码长码字进行预设次数的迭代译码,可以得到每个码字对应的码字比特的出错次数。图6为本发明实施例所提供的通过预设算法确定错误的码字比特的示意图,其中,圆形表示变量节点,正方形表示校验节点,圆形中的线条数目越多代表变量节点的错误次数越高。
具体的,可以将编码后的码字和编码后的码字进行比对,定位译码错误的码字比特。例如,编码前有48个信息比特,编码后有96个码字,其中,96个码字中包括48个校验位比特,48个信息位比特,传输后96个码字,译码后是96个码字比特,将编码后和译码后的码字进行比对,定位译码错误的比特。
例如,对预设码长码字{3,6}(96,48),在4db的信噪比下时,采用预设算法进行100000次的迭代译码,得到错误水平列表可以为
s502,根据所述预设码长码字的长度,确定所述错误水平列表中第一预设个数的出错码字比特及第二预设个数的可信度码字比特。
其中,出错码字比特的出错次数大于可信度码字比特的出错次数。
本发明实施例中,可以基于预设码长码字的长度,确定错误水平列表中第一预设个数的出错码字比特以及第二预设个数的可信度码字比特,例如,当预设码长码字的长度在一定范围内时,可以选择第一预设个数的出错码字比特及第二预设个数的可信度码字比特,即当预设码长码字的长度为a值时,可以选择a个出错码字比特,当预设码长码字的长度为b值时,可以选择b个出错码字比特。预设码长码字的长度越长,第一预设个数可以越大。
具体的,针对错误水平列表中的码字比特,按每个码字比特出错次个数对错误水平列表中的码字比特进行降序排列,并获得降序排列后所述错误水平列表中的第一预设个数的出错码字比特,同时,针对错误水平列表中的码字比特,按每个码字比特出错次数对错误水平列表中的码字比特进行升序排列,并获得升序排列后错误水平列表中的第二预设个数的可信度码字比特。
因为每个码字比特对应一个出错次数,将错误水平列表中所有码字比特按出错次数进行排序,并且按照码字比特的出错次数降序排列或者升序排列,在降序排列后的第一错误水平列表中,查找第一预设个数的出错码字比特和第二预设个数的可信度码字比特。
其中,第二预设个数为预设码长码字对应的校验矩阵中每行中非零元素的个数减去1之后的差,预设码长码字对应的校验矩阵为编码预设码长码字的校验矩阵。例如,校验矩阵中的每行非零元素的个数为dc,则第二预设个数为dc-1。
例如,错误水平列表为
又例如,错误水平列表为
s503,在所述预设码长码字对应的校验矩阵中添加第一预设个数的校验节点,并根据所述第一预设个数的出错码字比特及第二预设个数的可信度码字比特,生成所述校验矩阵对应的第一预设个数的扩展校验矩阵。
本发明实施例中,在预设码长码字对应的校验矩阵中的校验节点中添加第一预设个数的校验节点。同时,将第一预设个数的出错码字比特和第二预设个数的可信度码字比特与添加的校验节点连接,可以生成新的校验矩阵。
具体的,可以获取预设码长码字对应的校验矩阵的编码二分图,同时,将编码二分图中的变量节点按照每个变量节点在错误水平列表中的每个变量节点出错次数进行升序或者降序排列,进一步,在排列后的编码二分图中的校验节点之后添加第一预设个数的校验节点,将第一预设个数的校验节点中的每个校验节点连接至第一预设个数的出错码字比特和第二预设个数的可信度码字比特中的每个码字比特,最后可以生成编码二分图对应的扩展二分图,基于所获得的扩展二分图中的各校验节点和变量节点的连接关系,生成第一预设个数的扩展校验矩阵。
其中,编码二分图包括:校验节点、变量节点及连接校验节点和变量节点的边。
每个校验矩阵都对应一个编码二分图,在获得校验矩阵的编码二分图之后,根据错误水平列表中每个变量节点的出错次数对编码二分图中的变量节点进行重新排列,其中,编码二分图中的变量节点即为预设码长码字。
同时,根据添加的校验节点的个数、第一预设个数的出错码字比特及第二预设个数的可信度码字比特中的每个码字比特,可以生成扩展二分图,其中,每个添加的校验节点只能与第一预设个数的出错码字比特中的一个码字比特相连接,将每个添加的校验节点与第二预设个数的可信度码字比特中的全部或者部分码字比特连接。例如,当添加一个校验节点为cadd1,则将cadd1与出错次数最高的变量节点相连接,并且该校验节点cadd1连接至dc-1个可信度的码字比特。图7结合图8,添加两个校验节点,两个校验节点可以分别连接{91,35,83,8,19,80}和{65,24,40,57,48,53}。
本发明实施例中,通过新添加的校验节点连接最容易出错的码字和一组可信度最高的码字比特,一方面可以直接将争取的信息传递给陷阱集中译码错误的变量节点,另一方面,可以延长并添加外部正确信息通过迭代译码过程积累的路径,加强传输至陷阱集内容正确信息的置信度,使得陷阱集内部的错误码字得以恢复,进而打破整个陷阱集的结构,极大的改善陷阱集对译码性能的不良影响,降低了误码率。
如图8所示,本发明实施例所提供的扩展二分图的示意图,其中,圆形表示变量节点,正方形表示校验节点,圆形内的线条数目越多代表变量节点的错误次数越高,正方形中的c1、c2、...cn为校验矩阵的校验节点,caddi(i=1、2或3)表示添加的校验节点,图中示出了添加的三个校验节点,分别为:cadd1、cadd2、cadd3,但不限于此。可见,添加的校验节点的个数等于第一预设个数的出错码字比特,这样,每个添加的校验节点分别与第一预设个数的出错码字比特中的一个码字比特相连接,且每个添加的校验节点分别和dc-1个可信度的码字比特相连接,进而,可以根据扩展二分图中各校验节点和变量节点的连接关系,生成扩展校验矩阵。
本发明实施例中,对于不同的预设码长码字的ldpc码字,在添加校验节点时,新添加的校验节点的个数应该与预设码长码字的长度基本成正比例,也就是当预设码长码字的长度越长,在校验矩阵中可以添加更多的校验节点,来更好的改善校验矩阵的码字结构,进一步提高译码性能和降低误码率。
s504,根据所述扩展校验矩阵,对原始信息比特进行编码,得到所述扩展校验矩阵对应的码字。
其中,原始信息比特为预设码长码字在未编码前的信息比特减去第一预设个数信息比特的信息比特,且该原始信息比特个数为预设码长码字在未编码前的信息比特个数减去第一预设个数的差。
本发明实施例中,可以将扩展校验矩阵作为新的编码结构,对预设码长码字在为编码前的信息比特减去第一预设个数信息比特的信息比特进行编码,得到该扩展校验矩阵对应的码字。
如图9所示,在加成性高斯白噪声(additivewhitegaussiannoise,awgn)信道下,在校验矩阵中,未添加校验节点前、添加一个校验节点及添加两个校验节点之后,译码误码率的仿真图。
本发明实施例中,通过在预设码长码字对应的校验矩阵中添加预设个数的校验节点,生成扩展校验矩阵。这样,可以通过该扩展矩阵对预设码长码字在未编码前的码字进行编码的过程,打破ldpc码迭代算法进行译码中的陷阱集,降低误码平台,进一步,生成的码字相对于通过校验矩阵对预设码长码字在未编码前的码字进行编码生成的码字,错误平台低,可见,本发明实施例降低了误码率和错误平台。
相应于上面的方法实施例,本发明实施例还提供了相应的装置实施例。图10为本发明实施例提供了一种低密度奇偶校验码的编码装置,该装置包括:
获取单元1010,用于获取预设码长码字,对所述预设码长码字进行预设次数的译码,得到所述预设码长码字的错误水平列表;所述预设码长码字的一个码字为校验矩阵的一个变量节点;
确定单元1020,用于根据所述预设码长码字的长度,确定所述错误水平列表中第一预设个数的出错码字比特及第二预设个数的可信度码字比特;其中,所述出错码字比特的出错次数大于所述可信度码字比特的出错次数;
添加单元1030,用于在所述预设码长码字对应的校验矩阵中添加第一预设个数的校验节点,并根据所述第一预设个数的出错码字比特及第二预设个数的可信度码字比特,生成所述校验矩阵对应的第一预设个数的扩展校验矩阵;
编码单元1040,用于根据所述扩展校验矩阵,对原始信息比特进行编码,得到所述扩展校验矩阵对应的码字,所述原始信息比特为所述预设码长码字在未编码前的信息比特减去第一预设个数信息比特的信息比特,且所述原始信息比特个数为所述预设码长码字在未编码前的信息比特个数减去第一预设个数的差。
本发明实施例中,通过在预设码长码字对应的校验矩阵中添加预设个数的校验节点,生成扩展校验矩阵。这样,可以通过该扩展矩阵对预设码长码字在未编码前的码字进行编码的过程,打破ldpc码迭代算法进行译码中的陷阱集,降低误码平台,进一步,生成的码字相对于通过校验矩阵对预设码长码字在未编码前的码字进行编码生成的码字,错误平台低,可见,本发明实施例降低了误码率和错误平台。
可选的,所述获取单元具体用于,通过预设算法对所述预设码长码字进行预设次数译码,得到所述预设码长码字的错误水平列表;所述预设算法包括:蒙特卡洛算法及最小和译码算法。
可选的,所述获取单元具体用于:
在预设信噪比时,通过最小和译码算法对所述预设码长码字进行预设次数迭代译码,得到所述预设码长码字中每个码字对应的码字比特的错误水平;
根据所述预设码长码字中每个码字对应的码字比特的错误水平,通过蒙特卡洛算法,估计所述每个码字对应的码字比特的错误水平,生成所述预设码长码字的错误水平列表。
可选的,所述确定单元包括:
降序子单元(图中未示出),用于针对所述错误水平列表中的码字比特,按每个码字比特出错次个数对所述错误水平列表中的码字比特进行降序排列,并获得降序排列后所述错误水平列表中的第一预设个数的出错码字比特;
升序子单元(图中未示出),用于针对所述错误水平列表中的码字比特,按每个码字比特出错次数对所述错误水平列表中的码字比特进行升序排列,并获得升序排列后所述错误水平列表中的第二预设个数的可信度码字比特;所述第二预设个数为所述预设码长码字对应的校验矩阵中每行中非零元素的个数减去1之后的差,所述预设码长码字对应的校验矩阵为编码所述预设码长码字的校验矩阵。
可选的,所述添加单元包括:
获取子单元(图中未示出),用于获取所述所述预设码长码字对应的校验矩阵的编码二分图,其中,所述编码二分图包括:校验节点、变量节点及连接所述校验节点和所述变量节点的边;
排序子单元(图中未示出),用于将所述编码二分图中的变量节点按照每个变量节点在所述错误水平列表中的每个变量节点出错次数进行升序或者降序排列;
添加子单元(图中未示出),用于在排列后的编码二分图中的校验节点之后添加所述所述第一预设个数的校验节点;
生成子单元(图中未示出),用于将所述第一预设个数的校验节点中的每个校验节点连接至所述第一预设个数的出错码字比特和所述第二预设个数的可信度码字比特中的每个码字比特,生成所述编码二分图对应的扩展二分图;
扩展子单元(图中未示出),用于根据所述扩展二分图中各校验节点和变量节点的连接关系,生成第一预设个数的扩展校验矩阵。
本发明实施例还提供了一种电子设备,如图11所示,包括处理器111、通信接口112、存储器113和通信总线114,其中,处理器111,通信接口112,存储器113通过通信总线114完成相互间的通信,
存储器113,用于存放计算机程序;
处理器111,用于执行存储器113上所存放的程序时,实现如下步骤:
获取预设码长码字,对所述预设码长码字进行预设次数的译码,得到所述预设码长码字的错误水平列表;所述预设码长码字的一个码字为校验矩阵的一个变量节点;
根据所述预设码长码字的长度,确定所述错误水平列表中第一预设个数的出错码字比特及第二预设个数的可信度码字比特;其中,所述出错码字比特的出错次数大于所述可信度码字比特的出错次数;
在所述预设码长码字对应的校验矩阵中添加第一预设个数的校验节点,并根据所述第一预设个数的出错码字比特及第二预设个数的可信度码字比特,生成所述校验矩阵对应的第一预设个数的扩展校验矩阵;
根据所述扩展校验矩阵,对原始信息比特进行编码,得到所述扩展校验矩阵对应的码字,所述原始信息比特为所述预设码长码字在未编码前的信息比特减去第一预设个数信息比特的信息比特,且所述原始信息比特个数为所述预设码长码字在未编码前的信息比特个数减去第一预设个数的差。
上述电子设备提到的通信总线可以是外设部件互连标准(peripheralpomponentinterconnect,简称pci)总线或扩展工业标准结构(extendedindustrystandardarchitecture,简称eisa)总线等。该通信总线可以分为地址总线、数据总线、控制总线等。为便于表示,图中仅用一条粗线表示,但并不表示仅有一根总线或一种类型的总线。
通信接口用于上述电子设备与其他设备之间的通信。
存储器可以包括随机存取存储器(randomaccessmemory,简称ram),也可以包括非易失性存储器(non-volatilememory),例如至少一个磁盘存储器。可选的,存储器还可以是至少一个位于远离前述处理器的存储装置。
上述的处理器可以是通用处理器,包括中央处理器(centralprocessingunit,简称cpu)、网络处理器(networkprocessor,简称np)等;还可以是数字信号处理器(digitalsignalprocessing,简称dsp)、专用集成电路(applicationspecificintegratedcircuit,简称asic)、现场可编程门阵列(field-programmablegatearray,简称fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。
本发明实施例还提供了一种计算机可读存储介质,该计算机可读存储介质内存储有计算机程序,该计算机程序被处理器执行时实现本发明所述的低密度奇偶校验码的编码方法步骤。
对于装置/电子设备/存储介质实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
本说明书中的各个实施例均采用相关的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于系统实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
以上所述仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内所作的任何修改、等同替换、改进等,均包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!