一种FPGA编码的方法、装置及存储介质与流程
本发明涉及计算机技术领域,特别是涉及一种fpga编码的方法、装置及存储介质。
背景技术:
ldpc码具有逼近香农限的良好译码性能,gallager在提出ldpc码后,设计了bf算法用于ldpc码的译码,目前已经被推荐5g物理层的主要码型。ldpc码利用fpga等并行计算平台构造并行编译码器实现快速译码。为了获取更好的译码性能,ldpc码的各种译码算法得到广泛研究。
目前比较常用的ldpc编码方法是加权比特翻转算法(weightedbf,wbf)和改良加权比特翻转算法(mwbf,modifiedwbf),但是上述方法均存在伪零值现象,从而影响fpga平台的性能。
技术实现要素:
本发明提供了一种fpga编码的方法、装置及计算机可读存储介质,以解决现有技术中ldpc码中出现的伪零值而影响fpga平台的性能的问题。
第一方面,本发明提供了一种fpga编码的方法,该方法包括:
步骤一、根据
步骤二、根据每个校验节点m的校验值wm计算伴随向量重量σm;
如果σm=0,则停止译码并且输出译码输出值zk;
否则计算变量节点数q=η/dc,并执行步骤三,其中,k是迭代次数,η检验矩阵的列重,dc是码字的列重;
步骤三、计算每个比特节点n的品质因素
步骤四、翻转q个最小品质因素的变量节点的初始硬判决值,根据该初始硬判决值计算比特节点n的信道接收值yn,并重新执行步骤一。
优选地,根据
计算每个变量节点n的初始硬判决值zn=(1-sgn(yn))/2,并根据该初始硬判决值计算比特节点n的信道接收值yn。
优选地,如果迭代次数k大于预设的迭代次数阈值,则直接输出当前的译码输出值zk。
第二方面,本发明提供了一种fpga编码的装置,该装置包括:
第一计算单元,用于根据
第二计算单元,用于计算伴随向量重量σm,如果σm=0,则停止译码并且输出译码输出值zk,否则计算变量节点数q=η/dc,并计算每个比特节点n的品质因素
其中,yn为比特节点n的信道接收值,f为系统的数字识别精度最小值,b(m)比特节点m的比特节点集,m∈[1,m],n∈[1,n],m和n均为自然数k是迭代次数,η检验矩阵的列重,dc是码字的列重,a(n)为比特节点n的校验节点集,sm是第m校验节点的校验值,α是常数。
优选地,该装置还包括:第三计算单元,用于计算每个变量节点n的初始硬判决值zn=(1-sgn(yn))/2,并根据该初始硬判决值计算比特节点n的信道接收值yn;
优选地,所述第二计算单元还用于,判断迭代次数k是否大于预设的迭代次数阈值,如果是,则直接输出当前的译码输出值zk,否则触发重新执行所述第一计算单元。
第三方面,本发明提供了一种计算机可读存储介质,所述计算机可读存储介质存储有信号映射的计算机程序,所述计算机程序被至少一个处理器执行时,以实现上述任一种所述的fpga编码的方法。
本发明有益效果如下:
本发明通过根据伴随向量重量估计每次迭代合适的翻转比特个数,进而实现在获取较好译码速度的同时,有效消除传统译码算法出现的错误平层问题。
附图说明
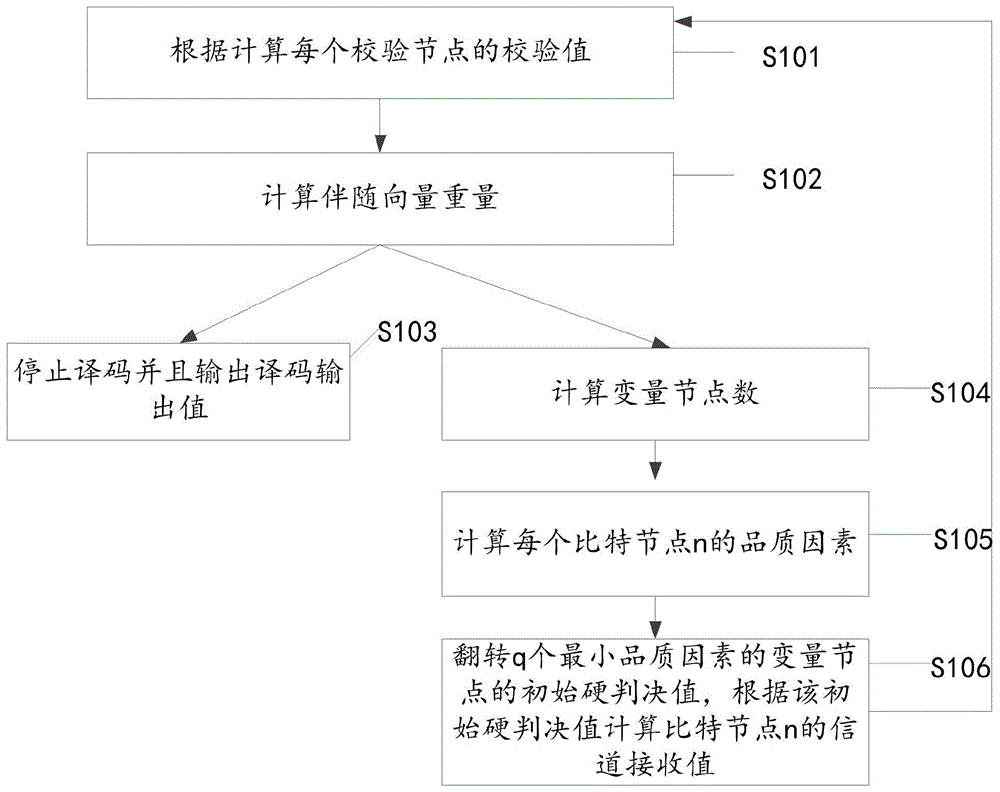
图1是本发明第一实施例提供的一种fpga编码的方法的流程示意图;
图2是本发明第一实施例提供的eg(255,173)码在mwbf(hard)、flwbf(hard)、siwbf(hard)算法译码下性能比较示意图;
图3是本发明第一实施例提供的eg(1023,781)码在mwbf(hard)、flwbf(hard)、siwbf(hard)算法译码下性能比较示意图;
图4是本发明第一实施例提供的一种fpga编码装置的结构示意图。
具体实施方式
为了解决现有的加权比特翻转算法(weightedbf,wbf)和改良加权比特翻转算法(mwbf,modifiedwbf)的译码过程由于“伪零值”现象造成译码平层的问题,本发明通过修正校验式的权值有效解决“伪零值”问题,并根据伴随向量重新估计每次迭代合适的翻转比特个数,进而使得改进算法利用硬件时实现时,在获取较好译码速度的同时,有效消除传统译码算法出现的错误平层问题。以下结合附图以及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不限定本发明。
本发明第一实施例提供了一种fpga编码的方法,参见图1,该方法包括:
s101、根据
s102、计算伴随向量重量σm,如果σm=0,则进步s103,否则进入s104;
s103、停止译码并且输出译码输出值zk;
s104、计算变量节点数q=η/dc,并执行s105,其中,k是迭代次数,η检验矩阵的列重,dc是码字的列重;
s105、计算每个比特节点n的品质因素
s106、翻转q个最小品质因素的变量节点的初始硬判决值,根据该初始硬判决值计算比特节点n的信道接收值yn,并重新执行s101。
本发明实施例通过根据伴随向量重量估计每次迭代合适的翻转比特个数,进而实现在获取较好译码速度的同时,有效消除传统译码算法出现的错误平层问题。
具体实施时,本发明实施例中,根据
具体来说,本发明实施例是使用二进制(n,k)ldpc码字作为研究对象,记为c=[c0,c1,…,cn-1],经调制后的信息序列为x=[x0,x1,…,xn-1],xn=2cn-1,n∈[1,n]。过信道后信息序列变为y=[y0,y1,…,yn-1],yn=xn+vn,n∈[0,n-1],vn为高斯白噪声。第k步迭代译码的硬判向量定义为zk(0≤k≤kmax)。η为伴随向量sk=zk×ht的重量,kmax是译码的迭代次数。wm为校验节点m提供给与之相连的比特节点的可靠性度量值。a(n)={m:hmn=1}表示与比特节点n相连的校验节点集合,该校验节点集合提供给比特节点n的可靠性度量值之和记为φn。b(m)={n:hmn=1}表示与校验节点m相连的比特节点集合。比特节点n的品质因素en用来衡量该比特节点的可靠性,从而决定该比特节点的硬判结果在译码过程中是否需要翻转。
翻转函数的计算尤为关键,翻转函数值的大小决定着比特是否翻转,比特的正确翻转直接决定译码是否正确。理论分析证明,wbf算法和mwbf算法译码过程中出现的“伪零值”现象使得比特节点的品质因素无法利用每次迭代的校验信息进行正确的更新演化,即sm取不同值时,若wm=0将会导致φn的值始终为0,进而影响该比特节点的翻转译码,甚至导致整个码字的译码失败。因此,本发明实施例通过限定校验可靠度最小值的方式消除“伪零值”现象。另外,为了提高算法的译码收敛速度,本发明选取品质因素最大的q个比特同时进行翻转来实现ldpc码的快速译码。
下面将通过一个具体例子对本发明所述方法进行详细说明:
step1:k=0;对于每个变量节点计算初始硬判决值zn=(1-sgn(yn))/2。利用式1计算每个校验节点m的校验值;
step2:计算伴随向量重量wm,如果wm=0,停止译码并且输出zk,否则计算q=η/dc,式中dc是码字的列重。
step3:k=k+1,如果k>kmax,译码失败并且输出zk;
即,如果迭代次数k大于预设的迭代次数阈值kmax,则直接输出当前的译码输出值zk。
step4:对于每个变量节点n,计算其品质因素en,计算公式如下:
step5:翻转具有q个最小品质因素的变量节点的硬判决值,然后转到step2。
分析可知,在加权比特翻转类算法比特节点品质因素出现“伪零值”时,会造成每次迭代的校验信息无法正确更新演化,使得相应比特节点译码值被困在当前状态无法收敛于正确值,进而导致译码失败。因此,本发明实施例通过校验可靠度,以量化精度为基准向上取整的方式消除“伪零值”现象。即某个校验方程的校验可靠度为零时,直接取值为量化精度。在利用fpga等硬件设备实现的时候,将所有校验可靠度初始化为量化精度的方式实现,从而减少因为引入判断逻辑导致的硬件资源开销。
另外,为了提高算法的译码收敛速度,本发明通过选取品质因素最大的q个比特同时进行翻转来实现ldpc码的快速译码。仿真发现,当q过大时,算法收敛较快但译码性能差;当q值过小时,算法译码仿真性能较好但收敛慢。因为实际译码过程中,错误比特的个数与校验方程伴随向量的重量正相关,所以本发明利用伴随向量的重量来计算每次迭代需要翻转的比特个数。
通过对现有wbf算法以及发明的算法的仿真性能进行比较分析,仿真使用的码字分别为:eg(255,173)和eg(1023,781)码,为了方便后续描述分别简记为码1和码2。测试数据经过bpsk调制后经由awgn信道传输。译码器的最大迭代次数为100。每个snr点观察到100帧错误数据停止译码性能统计。测试数据经过bpsk调制后经由awgn信道传输,噪声的均值为0、方差为n0/2。具体如表1和表2所示。
表1eg(255,173)码在flwbf(hard)、siwbf(hard)算法
译码下迭代次数比较
表2eg(1023,781)码在flwbf(hard)、siwbf(hard)算法
译码下迭代次数比较
图1和图2分别给出码1和码2使用mwbf(hard)、flwbf(hard)、siwbf(hard)算法、量化精度分别选择3、5和7比特时的译码性能。由图1和图2可知,wbf译码时,码1和码2在使用7比特量化精度下,使用mwbf(hard)译码,在4.5db时出现10-3级别错误平层。相同条件,flwbf(hard)和siwbf(hard)算法并没有发现译码平层现象。
在各信噪比场景下,采用相同的量化精度时,flwbf(hard)算法都比siwbf(hard)算法的平均迭代次数要小。对于码1,在5和7比特量化精度的情况下,flwbf(hard)算法相较于siwbf(hard)算法,迭代次数减少将近2倍。对于码2,在5和7比特量化精度的情况下,flwbf(hard)算法相较于siwbf(hard)算法,迭代次数减少将近5倍。
总体来说,与传统的wbf算法和mwbf算法相比,本发明可以有效降低上述算法硬件实现时的错误平层,通话四可以提升ldpc码的译码速度。
本发明第二实施例提供了一种fpga编码的装置,参见图4,该装置包括:
第一计算单元,用于根据
第二计算单元,用于计算伴随向量重量σm,如果σm=0,则停止译码并且输出译码输出值zk,否则计算变量节点数q=η/dc,并计算每个比特节点n的品质因素
其中,yn为比特节点n的信道接收值,f为系统的数字识别精度最小值,b(m)比特节点m的比特节点集,m∈[1,m],n∈[1,n],m和n均为自然数k是迭代次数,η检验矩阵的列重,dc是码字的列重,a(n)为比特节点n的校验节点集,sm是第m校验节点的校验值,α是常数。
本发明实施例通过根据伴随向量重量估计每次迭代合适的翻转比特个数,进而实现在获取较好译码速度的同时,有效消除传统译码算法出现的错误平层问题。
具体实施时,本发明实施例所述装置还包括:
第三计算单元,用于计算每个变量节点n的初始硬判决值zn=(1-sgn(yn))/2,并根据该初始硬判决值计算比特节点n的信道接收值yn;
本发明实施例是使用二进制(n,k)ldpc码字作为研究对象,记为c=[c0,c1,…,cn-1],经调制后的信息序列为x=[x0,x1,…,xn-1],xn=2cn-1,n∈[1,n]。过信道后信息序列变为y=[y0,y1,…,yn-1],yn=xn+vn,n∈[0,n-1],vn为高斯白噪声。第k步迭代译码的硬判向量定义为zk(0≤k≤kmax)。η为伴随向量sk=zk×ht的重量,kmax是译码的迭代次数。wm为校验节点m提供给与之相连的比特节点的可靠性度量值。a(n)={m:hmn=1}表示与比特节点n相连的校验节点集合,该校验节点集合提供给比特节点n的可靠性度量值之和记为φn。b(m)={n:hmn=1}表示与校验节点m相连的比特节点集合。比特节点n的品质因素en用来衡量该比特节点的可靠性,从而决定该比特节点的硬判结果在译码过程中是否需要翻转。
翻转函数的计算尤为关键,翻转函数值的大小决定着比特是否翻转,比特的正确翻转直接决定译码是否正确。理论分析证明,wbf算法和mwbf算法译码过程中出现的“伪零值”现象使得比特节点的品质因素无法利用每次迭代的校验信息进行正确的更新演化,即sm取不同值时,若wm=0将会导致φn的值始终为0,进而影响该比特节点的翻转译码,甚至导致整个码字的译码失败。因此,本发明实施例通过限定校验可靠度最小值的方式消除“伪零值”现象。另外,为了提高算法的译码收敛速度,本发明选取品质因素最大的q个比特同时进行翻转来实现ldpc码的快速译码。
在具体实施时,本发明实施例所述第二计算单元还用于,判断迭代次数k是否大于预设的迭代次数阈值,如果是,则直接输出当前的译码输出值zk,否则触发重新执行所述第一计算单元。
本发明实施例的相关内容可参见方法实施例部分进行理解,本发明实施例对此不作详细赘述。
本发明第三实施例提供了一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储有相干脉冲激光测距的计算机程序,所述计算机程序被至少一个处理器执行时,以实现如下方法:
步骤一、根据
步骤二、计算伴随向量重量σm;
如果σm=0,则停止译码并且输出译码输出值zk;
否则计算变量节点数q=η/dc,并执行步骤三,其中,k是迭代次数,η检验矩阵的列重,dc是码字的列重;
步骤三、计算每个比特节点n的品质因素
步骤四、翻转q个最小品质因素的变量节点的初始硬判决值,根据该初始硬判决值计算比特节点n的信道接收值yn,并重新执行步骤一。
本发明实施例的相关内容可参见方法实施例部分进行理解,本发明实施例对此不作详细赘述。
尽管为示例目的,已经公开了本发明的优选实施例,本领域的技术人员将意识到各种改进、增加和取代也是可能的,因此,本发明的范围应当不限于上述实施例。
- 还没有人留言评论。精彩留言会获得点赞!