一种Redis中主从节点数据同步方法与流程
本发明涉及电子计算机数据存储领域,具体涉及一种Redis中主从节点数据同步方法。
背景技术:
近年来,计算机系统的发展日新月异,对数据存储载体的要求也越来越高,特别是互联网的兴起,由于其服务的用户众多,对数据存储性能的要求非常高,传统的关系型数据库很难满足要求,因此,众多的互联网企业在面向最终用户的服务上放弃使用传统的关系型数据库,而使用了性能更好的KV(键值)数据库存储,开源产品Redis(REmoteDIctionary Server)就是其中之一。
Redis是一个性能极高、数据类型丰富、功能全面的KV(键,值)数据库。根据其官网描述在50个并发的情况下写入速度是11万次/秒,读出速度8.1万次/秒。数据类型除了基本的string数据类型外还有hash,list,set,sorted set等数据结构类型。Redis在集群部署中提供了数据的主从节点复制功能。
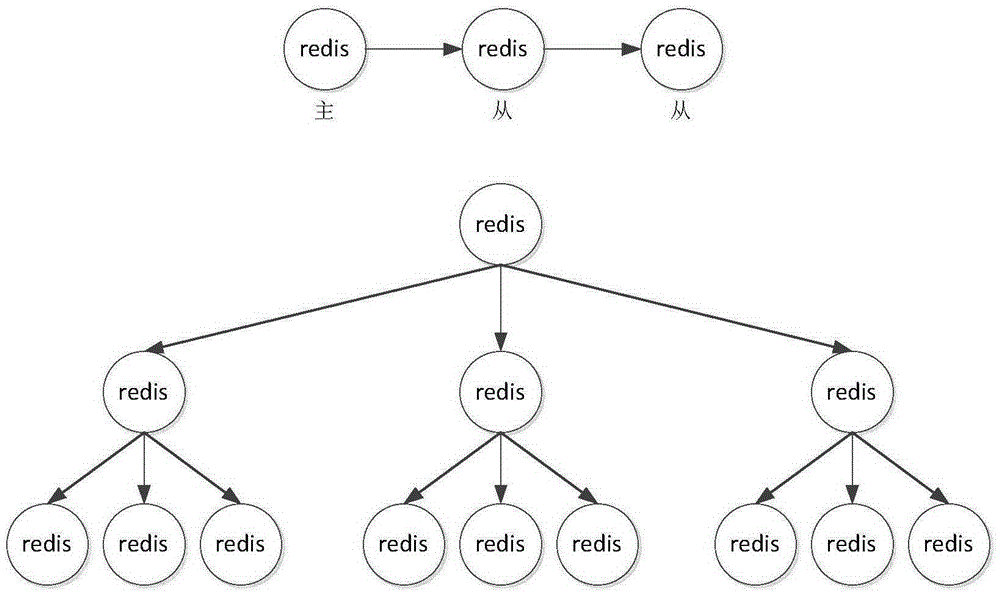
互联网业务应用系统因其提供的服务在性能和实时性响应上的特殊要求大量使用Redis作为数据存储载体,集群部署中也使用了Redis的主从复制功能,出现了主从复制链、主从复制树形结构(复制链的增强版),如图1所示,每个Redis节点都是数据的全量,使用上基本是Redis的“主”节点接受数据写入,数据由“主”节点复制到“从”节点,应用程序在“从”节点读取数据的方式。
在业务系统使用过程中,Redis的这种部署方式对数据一致性、实时性和扩展性上面都给了业务系统不错的支撑。数据实时性、一致性在Redis高效的主从复制上的到了很好的保证。集群扩展性上,扩展集群只是意味着增加复制链(树)型结构的节点即可,十分简单。但是在使用Redis中 仍然碰到了一些问题。
首先,“主”节点存在“单点”问题,一旦“主”节点所在服务器硬件故障或者网络分区导致“主”节点相对“从”节点或应用服务器不可访问就会导致数据无法写入问题,此时必须更换“主”节点进行数据写入,并且“原主”节点所有的“从”节点也要进行主从节点的变更,使其从于“新主”节点接受数据更新,如图2所示,换主期间左右两个Redis子树的数据会被“新主节点”全量覆盖,在数据同步的过程中服务不可用。
其次,在使用过程中会有同城不同机房间的机器调整,此过程中会有手工的“摘掉”节点、“挂”新节点的动作,如图3所示,整个过程数据全量复制一次时间比较长,期间数据全量复制,被调整节点的服务不可用。
再次,如果有异地机房之间的数据需要复制,问题将会更加严重,如图4,一旦全量复制数据,数据同步期间服务不可用。
以上几种情况将会出现一个共同的问题,主从节点之间数据全量复制,并且在全量复制期间不能提供服务,如果节点数据量比较大、复制时间长问题将会加剧。原生态的Redis在主从复制的实现上有全量复制和增量复制两种方式,全量复制由于复制数据量大需要较长的时间才能完成,因此Redis2.8版本后出现了增量复制,但是增量复制只适用于主从节点短时间链接断开,数据更新量不是很大(没有超过主节点日志范围)的情况。全量复制由于其耗时较长(复制期间会出现服务不可用)应该被尽量的避免,而在上述示例的几种情况下都会出的全量复制,如果网络环境不好导致复制时间较长的话这一缺点将更加突出。实际上在“复制树”结构中由于Redis的主从复制机制,各个节点数据更新相差不大,在调整结构过程中即便不是直接的主从节点关系,理论上也可以通过拷贝差异数据来实现增量复制。
技术实现要素:
(一)要解决的技术问题
鉴于上述问题,本发明的目的在于,提供一种Redis中主从节点数据同步方法,解决现有Redis主从节点之间所提供的数据同步方式的低效问题,最大限度的减少了服务不可用的时间和由此带来的运维不便。
(二)技术方案
本发明提供一种Redis中主从节点数据同步方法,用于将Redis树型结构中主节点和从节点的数据进行同步,同一树型结构中的节点具有相同的基因ID,不同树型结构间的节点具有不同的基因ID,方法包括:
S1,从节点向主节点发送数据同步请求,其中,该数据同步请求包含有从节点的基因ID;
S2,主节点接收到该数据同步请求后,判断从节点的基因ID与主节点的基因ID是否一致,若一致,则通过增量复制的方式将主节点上的数据复制到所述从节点,否则,通过全量复制的方式将主节点上的数据复制到所述从节点。
(三)有益效果
本发明提供的Redis中主从节点数据同步方法,在同一颗树中,将数据相差不大的主从节点进行增量同步,解决现有Redis主从节点之间所提供的数据同步方式的低效问题,使得业务应用客户端在数据存储故障或手工数据迁移过程中最大限度的减少了服务不可用的时间,带来了较好的用户体验。
附图说明
图1-图4是现有技术Redis中主从复制树形结构的示意图。
图5是本发明实施例提供的Redis节点复制树型结构。
图6是本发明实施例提供的主从节点进行增量复制的判定示意图。
图7是现有技术和本发明实施例提供的主从节点断开重连时进行数据同步的示意图。
图8是本发明实施例提供的主从节点断开后命令执行的示意图。
图9是现有技术和本实施例的写性能压力测试的对比图。
图10是现有技术和本实施例的读性能压力测试的对比图。
具体实施方式
本发明提供一种Redis中主从节点数据同步方法,通过主从节点基因ID,判断其是否处于同一颗树上,若是,则进行数据增量复制;另外,主 从节点建立连接并进行全量同步数据时,主节点将基准偏移量传递给从节点,保证主从节点断开重连后对应的命令保持一致;再者,在从节点连接新主节点时,先断开连接,再在从节点中增加标志位,避免从节点自动重新跟原主节点建立连接,解决了主从日志数据顺序不一致的问题。
根据本发明的一种实施方式,Redis中主从节点数据同步方法包括:
S1,从节点向主节点发送数据同步请求,其中,该数据同步请求包含有从节点的基因ID,所述基因ID是标识不同Redis树型结构的ID;
S2,主节点接收到该数据同步请求后,判断从节点的基因ID与主节点的基因ID是否一致,若一致,则通过增量复制的方式将主节点上的数据复制到所述从节点,否则,通过全量复制的方式将主节点上的数据复制到所述从节点。
根据本发明的一种实施方式,主从节点采用环形队列存储日志,并且,数据同步请求包括从节点的偏移量,其中,在步骤S2中,若从节点的基因ID与主节点的基因ID一致,则判断偏移量是否存在于所述日志,若是,则通过增量复制的方式将主节点上的数据复制到所述从节点,否则,通过全量复制的方式将主节点上的数据复制到从节点。
根据本发明的一种实施方式,通过全量复制的方式将主节点上的数据复制到从节点时,将主节点的基准偏移量传递给从节点,以使得主从节点中日志对应的命令相同。
根据本发明的一种实施方式,在数据同步期间,禁止ping命令写入日志。
根据本发明的一种实施方式,当从节点欲与新主节点连接时,首先断开从节点与原主节点的连接,然后在从节点中增加标志位,以避免从节点自动重新与所述原主节点建立连接。
为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明进一步详细说明。
图5是本发明实施例提供的Redis节点复制树型结构,如图5所示,同一棵Redis复制树型结构上的所有节点如同一个家族的成员,节点(父子节点,兄弟姐妹节点)之间是有血缘关系的或者说是有相同的“基因”的。具有相同“基因”的节点时能够进行增量复制的前提,因此,在本实施例 中,每个节点都会继承父节点的“基因ID”,凡是具有“血缘”关系或说有相同“基因ID”的节点之间原则上都可以做增量同步。因此在从节点通过psync(partial sync)命令向主节点进行数据同步时应先检查是否有相同的“基因ID”,具有相同”基因ID“的节点可以接受增量复制的请求。
图6是本发明实施例提供的主从节点进行增量复制的判定示意图,如图6所示,Redis数据存储上使用了一种环形队列的结构来存储日志(backlog),环形队列大小可以通过配置项来定制,从节点向主节点请求同步数据的时候会传入“基因ID”和偏移量(offset)。主节点接收到请求的时候会首先判断是否来自相同复制树型结构进而判断是否支持增量同步方式。
图7是现有技术和本发明实施例提供的主从节点断开重连时进行数据同步的示意图,Redis中的Backlog用来缓存主节点传递给从节点的Redis命令,如果主从节点之间出现断开重连的情况,主节点通过传递给从节点缺少的命令来实现部分同步。而偏移量就是用来确定传递命令的范围的。从节点在给主节点发送psync命令时传递的偏移量是从主节点接收到的最新命令对应在主节点Backlog的偏移量。由于Backlog的大小固定并且是滚动使用的,所以偏移量实际上是所有写入过Backlog的命令的累加值。当从节点创建Backlog时,偏移量从0开始计算,如图7中左图所示,虽然数据Backlog最后一条命令是相同的,但是对应的偏移量不一致。为了支持同一复制树内任意两个节点的部分同步,需要通过传递基准偏移量(base offset)来保证相同的偏移量在复制树内任意节点所对应的命令相同,如图7中右图所示。因此,本实施例主从节点建立连接首次全量同步数据时,将基准偏移量传递给从节点,这样在复制树内同一偏移量在任意两个节点所对应的命令就能保持一致了。
此外,为了保持backlog数据的一致性,对一些Redis命令还需要做一些特殊处理。例如,Redis会根据配置文件周期性的向backlog内写入ping命令并传递给所有从节点,为了保持数据一致性我们将禁止ping命令写入backlog。
从节点连接新主节点的过程中应该避免接收到原主节点的数据。虽然Redis的slaveof no one可以实现类似的功能,但是如果从节点有当前包含 标记为expire但还没有释放的数据,一旦expire时间到达会在从节点触发del命令同时将del命令写入backlog。这种从节点自发修改(不是由主节点触发)backlog的行为,会产生主从backlog数据顺序不一致的问题。如图8所示,主从断开前有“EXPIRE a 60”执行,代表60秒后a将被清除(主节点60秒后自动调用DEL),如果清除前主从断开(通过从节点执行slaveof no one命令),同时主节点有新数据写入“SET b 2”,60秒后断开的主从会分别执行DEL命令,这就导致主从相同的offset对应的命令不同。
为了避免这类问题,本实施例采用“暂停主从同步”的Redis命令,该命令首先断开主从连接阻止主从数据复制,然后增加标志位避免从节点自动重新跟主节点建立连接。
图9是现有技术和本实施例的写性能压力测试的对比图。相比现有技术,本实施例的Redis从节点在作为叶子时也需要创建并维护backlog,所以在写入的最大TPS要低,但由于差异比例小,对实际性能影响不大。
图10是现有技术和本实施例的读性能压力测试的对比图。相比现有技术,本实施例的Redis从节点需要对一些影响backlog offset的命令进行过滤,所以最大TPS略低。但由于差异比例小,对性能影响不大。
综上所述,本发明通过主从节点基因ID,判断其是否处于同一颗树上,若是,则进行数据增量复制;另外,主从节点建立连接并进行全量同步数据时,主节点将基准偏移量传递给从节点,保证主从节点断开重连后对应的命令保持一致;再者,在从节点连接新主节点时,先断开连接,再在从节点中增加标志位,避免从节点自动重新跟原主节点建立连接,解决了主从日志数据顺序不一致的问题,提高了数据同步效率,基本消除了暂停服务,方便了对Redis集群的运维。
以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!