一种融合神经种群编码模型的3D主观质量预测方法与流程
本发明涉及计算机视觉领域,特别涉及一种融合神经种群编码模型的3D主观质量预测方法。
背景技术:
在MPEG标准下,3D视频是以MVD(Multiview Video plus Depth,多视点视频加深度)格式表示的。在这种格式下,有限视点的纹理图及对应深度图在视频发送端被编码传输,在视频接收端被解码后,通过视点合成技术,利用有限视点的纹理图和深度图合成无限多视点的纹理图。视点合成技术通常具有非常大的计算量,所以怎样基于深度图的质量去预测合成视点的3D质量成为非常有意义同时也具有挑战性的工作。
为了建立基于深度图的合成视点质量预测模型,很多研究就此展开。但是更多的研究工作只面向合成图的客观质量和深度图质量的关系,并没有考虑合成视点的3D主观质量。或者从丢包率引起的深度图失真对合成图的质量做了探究。并未有模型从深度图的纹理特征出发考虑其对合成视点的影响。深度图有着不同于纹理图的纹理特征,深度图是由一些尖锐的边界区和一些大面积相似值的平坦区组成,两者的失真对合成视点的影响必然有所不同。
另外,计算神经学理论中,人眼在观看3D图像时,视觉神经细胞对视差的不同响应很好反映了人眼对3D多媒体的体验效果,因此,建立一种融合神经种群编码模型的3D主观质量预测方法是亟待解决的问题。
技术实现要素:
本发明目的就是为解决融合神经种群编码模型的3D主观质量预测的问题。
本发明的技术问题通过以下的技术方案予以解决:
一种融合神经种群编码模型的3D主观质量预测方法,包括如下步骤:
S1、建立基于支持向量回归的3D主观质量预测模型;
S2、基于失真深度图得到视差图;
S3、计算视差图在神经种群编码模型下的13维响应;
S4、将所述13维响应联合失真深度图的纹理特征和失真特征参数作为3D主观质量预测模型的输入,得到3D图像体验质量值。
根据本发明的另一个具体方面,步骤S1中所述3D主观质量预测模型的数学形式为:
其中p为预测得到的主观质量分数,该分数为平均主观意见分MOS(Mean Opinion Score)值,取值范围为1-5,其中1代表3D体验非常不舒服,5代表3D体验非常舒服。xv为深度图中提取的特征向量,xj为训练集中的特征向量。l为训练集的大小,αj,σ2和b是在训练集上训练得到的参数。
根据本发明的另一个具体方面,训练集上训练过程包括如下步骤:
S11、建立数据库;
S12、进行支持向量回归SVR(Support Vector Regression,)训练,对数据做归一化;
S13、应用高斯核函数;
S14、用交叉验证和网格搜索法得到最优的参数。
根据本发明的另一个具体方面,步骤S11中,在高码率与低码率两种码率下,分别选取MPEG标准测试序列M个场景的图片,每个场景变化N个平坦块的编码参数得到纹理平坦失真比变化的深度图;利用失真深度图和固定质量的纹理图合成3D图片在标准测试环境下进行主观实验评分得到图像的主观质量值;最终得到一个大小为M×N×2的3D图像数据集。
根据本发明的另一个具体方面,步骤S12中,运用开发软件matlab的支持向量机svm(Support Vector Machine)工具箱可以非常便捷的完成SVR训练,归一化就是指把数据都按比例转成0—1之间的数字。
根据本发明的另一个具体方面,步骤S2中
失真深度图中的深度值到世界坐标系中的深度值转化关系如下,
其中v是失真深度图中的深度值,znear是图中最靠近相机的深度值,zfar是最远离相机坐标点的实际深度值。
根据本发明的另一个具体方面,步骤S3中,视觉神经细胞对于视差的响应由以下公式拟合:
其中,i代表第i种神经细胞的d是每个像素点以角度定义的视差;是基本响应;Ai是高斯核的振幅;是高斯函数的中心;σi是高斯函数的标准差;fi是频率;Φi是相位。
根据本发明的另一个具体方面,步骤S3中神经种群编码模型下的13维响应,其中第i种神经细胞反应的期望以下列公式拟合:
其中,P[d]是视差d的概率。
根据本发明的另一个具体方面,步骤S4中所述纹理特征和失真特征,包括:失真深度图的纹理块个数占比、纹理块的平均块失真、纹理块与平坦块的失真比。
根据本发明的另一个具体方面,所述纹理块指在深度图中纹理复杂度大于纹理复杂度阈值的编码块;
所述平坦块指在深度图中纹理复杂度小于所述纹理复杂度阈值的编码块;
所述纹理块个数占比指在深度图中纹理块的个数与编码块总数之比;
所述纹理块的平均块失真指在失真深度图中每个纹理块相对于对应的参考深度图的纹理块的失真之和的算术平均值;
所述平坦块的平均块失真指在失真深度图中每个平坦块相对于对应的参考深度图中的平坦块的失真之和的算术平均值;
所述纹理块与平坦块的失真比指纹理块的平均块失真与平坦块的平均块失真之比。
本发明与现有技术对比的有益效果是:
本发明的方法,提供了一种融合神经种群编码模型的3D主观质量预测方法,将深度图转化为视差图,根据神经种群编码理论,该3D主观质量预测模型对视差的输出响应作为一部分特征,再融合深度图独特的纹理特征,找到深度图特征与3D图像主观感知质量的关系模型,从而根据失真深度图的质量预测合成视点的3D主观质量。
附图说明
图1是一种本发明的流程图;
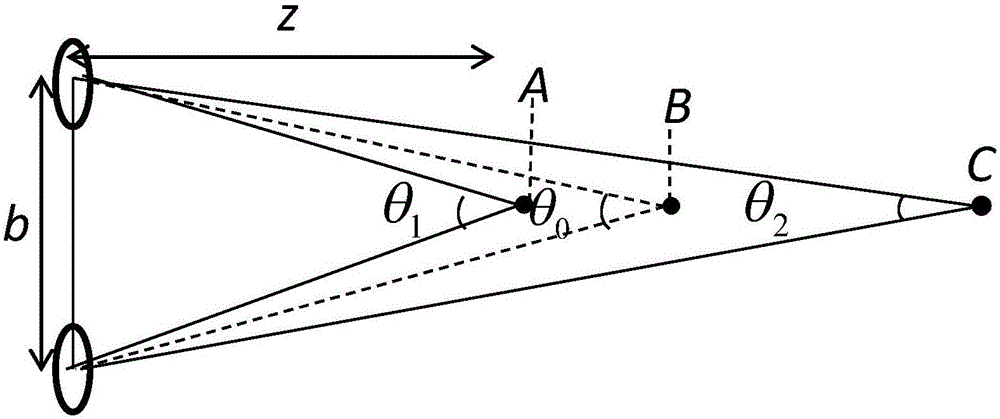
图2是角度定义视差示意图。
具体实施方式
如图1是融合神经种群编码模型的3D主观质量预测方法的流程图,不同于客观质量,3D主观质量涉及因素太多,主观因素很大,人类感知3D以及图像的机理复杂。
其中建立基于支持向量回归的3D主观质量预测模型包括:
应用机器学习的模型自学习的能力建模,模型采用支持向量回归,模型的具体数学形式为
其中p为预测得到的主观质量分数,该分数为MOS(Mean Opinion Score)值,取值范围为1-5,其中1代表非常不舒服,5代表3D体验非常舒服。xv为深度图中提取的特征向量,xj为训练集中的特征向量。l为训练集的大小,αj,σ2和b是在训练集上训练得到的参数。
在模式识别领域,数据集分为训练集和测试集,训练集用来训练建立模型,测试集不参与训练,用来检验模型准确性。
模型的建立步骤如下:
1.选取MPEG标准测试序列M个场景的图片,每个场景变化N个平坦块的编码参数得到纹理平坦失真比变化的深度图,在高码率与低码率两种码率情况下重复上述操作。利用失真深度图和固定质量的纹理图合成3D图片在标准测试环境下进行主观实验评分得到图像的主观质量值。最终得到一个大小为M×N×2的3D图像数据集。每一条数据包括失真的深度图,以该深度图为输入合成的3D图像,以及图像的主观质量值。
在3D视频图像领域,有深度图和纹理图,纹理图也就是彩色图,与深度图一起可以用来合成3D图片。
2、根据深度图得到视差图。
深度图中的深度值到世界坐标系中的深度值转化关系如下,
其中v是深度图中的深度值,znear是图中最靠近相机的深度值,zfar是最远离相机坐标点的实际深度值.如图2所示为角度定义视差的示意图,b是相机的基线,z是世界坐标系的实际深度值.点A,B,C分别代表聚焦在屏幕前,聚焦在屏幕上,和聚焦在屏幕后的像素点。θ0,θ1,θ2是对应的聚焦角度.所以用角度表示A,C的视差,公式如下:
dA=θ0-θ1,dC=θ2-θ1,
其中θ0,θ1,θ2可以通过b和z的关系计算。
3、计算视差图在神经种群编码模型下的13维响应;得到以角度表示的视差图之后,代入神经种群编码模型,13种视觉神经细胞的对于视差的响应被以下公式拟合:
其中,i代表第i种神经细胞的d是每个像素点以角度定义的视差;是基本响应;Ai是高斯核的振幅;是高斯函数的中心;σi是高斯函数的标准差;fi是频率;Φi是相位.第i种神经细胞反应的期望E[ri]计算公式如下:
P[d]是视差d的概率.13个E[ri]值即为视差图在神经种群编码模型下的13维响应。
4.计算3维深度图的纹理特征和失真特征。其中深度图的纹理特征和失真特征包括失真深度图的纹理块个数占比、纹理块的平均块失真、纹理块与平坦块的失真比;
其中,所述纹理块指在深度图中纹理复杂度大于纹理复杂度阈值的编码块,所述平坦块指在深度图中纹理复杂度小于所述纹理复杂度阈值的编码块,所述纹理块个数占比指在深度图中纹理块的个数与编码块总数之比,所述纹理块的平均块失真指在失真深度图中每个纹理块相对于对应的参考深度图的纹理块的失真之和的算术平均值,所述平坦块的平均块失真指在失真深度图中每个平坦块相对于对应的参考深度图中的平坦块的失真之和的算术平均值,所述纹理块与平坦块的失真比指纹理块的平均块失真与平坦块的平均块失真之比。
5、对数据集进行SVR训练。数据集每一条数据包括13维响应联合深度图的纹理特征和失真特征等16维参数,以及主观质量值。对该数据集进行SVR训练,首先对数据做归一化,在此应用高斯核函数RBF kernel,具体公式形式见公式(1),用交叉验证(cross-validation)和网格搜索法(grid-search)选取公式中最优的参数,得到3D主观质量预测模型的具体形式。
以上内容是结合具体的/优选的实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,其还可以对这些已描述的实施例做出若干替代或变型,而这些替代或变型方式都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!