基于同向流的调度方法和服务器与流程
本发明涉及通信领域,尤其涉及一种基于同向流的调度方法和一种服务器。
背景技术:
不同于传统的流抽象,coflow(同向流)捕捉在连续的计算阶段中两组机器之间的网络流的集合,其中通信阶段在所有流都完成后才结束。同向流(coflow)也可以简单定义为由同一个计算任务产生的网络流量。越来越多的文献证明利用使用同向流(coflow)的应用级别需求可以显著改善并行数据集群中应用级别的通信效果。
同向流的注解或者识别不能保证100%的准确度,同向流的注解/识别过程有时会错误地将一个网络流应该属于的同向流识别为另一个同向流。而现有的同向流调度算法对这种错误又都是极其敏感的。一旦出现错误就会造成严重的影响。一个被错误归类的网络流可明显地影响其父亲同向流的CCT(Coflow Completion Time,同向流完成时间)。
为了评估由于识别错误而造成的影响,可以根据调度时间将所述被错误识别的网络流分为两类。
第一类称为先驱者(pioneers),指那些由于错误识别而造成其调度时间早于其父亲同向流的网络流。
第二类称为掉队者(stragglers),指那些由于错误识别而造成其调度时间晚于其父亲同向流的网络流。
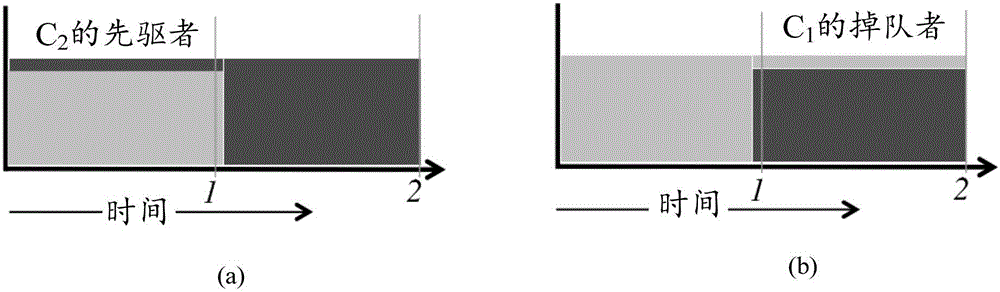
这两类网络流对平均CCT(Coflow Completion Time,同向流完成时间)的影响是不同的。参见图1,两个一样的同向流C1(颜色较浅)和C2(颜色较深),共用同样的瓶颈链路,并且同时到达。每个同向流包含10个相同的网络流。进一步假设给C1分配更高级别的优先级,每个同向流都需要1个 单位时间才能完成。在没有识别错误的时候,可以得到最优CCT为1.5个单位时间。
然而,参见图1a,一个先驱者的出现会造成C1的CCT增加10%,并且平均CCT也会增加3%(平均CCT为1.55个时间单位)。而一个掉队者的出现造成的影响更大,参见图1b,几乎加倍了C1的CCT,并且导致平均CCT增加33%(平均CCT为2个时间单位)。由此可以得到一个结论:相比于先驱者,掉队者对平均CCT的影响更大。
为了更高效地调度,很多现有的同向流调度算法都假设预先知道同向流信息。然而,这些算法在出现识别错误时都变得非常不高效。
考虑MADD(Minimum-Allocation-for-Desired-Duration,期望持续时间的最小资源分配),该最优算法用于网络流大小已知的同向流内部的调度。MADD算法改变一个同向流内部各网络流的速率,令所有网络流在最长的网络流完成时完成。由于使用MADD所有网络流都同时完成,因此一个错误识别的网络流(特别是一个掉队者)将会严重地影响CCT(参见图1b)。
与上述算法不同,Aalo使用D-CLAS(Discretized Coflow-Aware Least-attained Service,离散化的同向流知晓最少获得服务)。它将同向流分为具有不同优先级的队列,并按照FIFO(First Input First Output,先入先出)的顺序在每个队列中进行调度,从而不需要预先知道网络流的大小就可以减小平均CCT。然而,Aalo在有识别错误出现时表现地更加糟糕。这是由于被错误识别的网络流可能会掉入低优先级的大同向流中,然后成为一个超级掉队者,参见图2。图2所示并非个例。由于占17%的大同向流产生了99%的网络流量,于是在占83%的小同向流中的网络流是很容易被错误识别到大同向流中,从而影响性能。
因此我们需要一种具有容错能力的同向流调度方法。所述同向流调度方法要能在有个别识别错误时依然保持稳健。
技术实现要素:
本发明实施例所要解决的技术问题在于,提供一种网络流调度方法,可以减少掉队者的数量。
为了解决上述技术问题,本发明实施例提供了一种基于同向流的调度方法,包括:
步骤1:依据预定条件对各同向流进行扩展获得相应的扩展同向流,所述扩展同向流中至少有两个扩展同向流包含相同的网络流;
步骤3:对所述扩展同向流进行优先级排序;
其特征在于,
步骤4:按照排序后的扩展同向流的顺序执行调度,其中,包含于多个扩展同向流的网络流在随所述多个扩展同向流中优先级最高的扩展同向流调度之后不再随所述多个扩展同向流中其他的扩展同向流调度。
进一步地,在步骤1之后还包括:
步骤2:对所述扩展同向流内部的各网络流进行优先级排序。
进一步地,所述步骤3进一步包括:按照先入先出算法对所述扩展同向流进行优先级排序。
进一步地,所述步骤2进一步包括:按照最小优先启发法对所述扩展同向流内部的各个网络流进行优先级排序。
进一步地,所述最小优先启发法进一步包括:
在网络流队列之间使用多级反馈调度,对网络流队列中的各个网络流按照最大-最小公平的策略分配带宽。
相应地,本发明还提供一种服务器,所述服务器包括:
扩展模块,用于依据预定条件对各同向流进行扩展,获得相应的扩展同向流,所述扩展同向流中至少有两个扩展同向流包含相同的网络流;
排序模块,用于对所述扩展同向流进行优先级排序;
执行模块,用于按照排序后的扩展同向流的顺序执行调度,其中,包含于多个扩展同向流的网络流在随所述多个扩展同向流中优先级最高的扩展同向流调度之后不再随所述多个扩展同向流中其他的扩展同向流调度。
进一步地,所述排序模块还用于在对各扩展同向流进行优先级排序之前对所述扩展同向流内部的各网络流进行优先级排序。
进一步地,所述排序模块按照先入先出算法对所述扩展同向流进行排序。
进一步地,所述排序模块按照最小优先启发法对所述扩展同向流内部的各个网络流进行优先级排序。
进一步地,所述排序模块在网络流队列之间使用多级反馈队列调度,对网络流队列中的各个网络流按照最大-最小公平的策略分配带宽。
实施本发明实施例,具有如下有益效果:
(1)减少掉队者的数量;
(2)不需要先验知识;
(3)改善CCT。
附图说明
图1(a)是由于先驱者而造成的影响的示意图;
图1(b)是由于掉队者而造成的影响的示意图;
图2是现有技术Aalo在发生识别错误时的示意图;
图3是本发明调度方法的一个实施例的示意图;
图4是本发明调度方法的另一个实施例的示意图;
图5是本发明服务器的一个实施例的示意图;
图6是位于多个同向流之间的网络流容易被错误识别的示意图;
图7(a)是本发明后期绑定策略的示意图;
图7(b)是本发明同向流内部优先级排序策略的示意图;
图8是工作负载的一些与时间相关的特征的示意图;
图9是本发明与每流平均共享、Aalo算法在CCT和JCT方面的比较示意图;
图10(a)是有关本发明伸缩性的仿真结果示意图;
图10(b)是有关协调周期的影响的仿真结果示意图;
图11(a)是有关本发明在正常工作负载下的标准化CCT的仿真示意图;
图11(b)是有关本发明在正常工作负载下的CCT分布仿真示意图;
图12(a)是有关本发明在成批到达场景下的仿真示意图(Hadoop);
图12(b)是有关本发明在展开到达场景下的仿真示意图;
图13(a)是有关本发明在成批到达场景下的效果的仿真示意图;
图13(b)是有关本发明在展开到达场景下的效果的仿真示意图;
图14是有关本发明后期绑定策略在展开到达场景下的效果的仿真示意图;
图15(a)是有关本发明同向流内部优先级排序在成批到达场景下的效果的仿真示意图(Hadoop);
图15(b)是有关本发明同向流内部优先级排序在展开到达场景下的效果的仿真示意图;
图16是本发明另一实施例的软件框架示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步地详细描述。
如图3所示,为本发明一个实施例。在该实施例中,本发明一种基于网络流的调度方法包括:
S1:依据预定条件对各同向流进行扩展获得相应的扩展同向流,所述扩展同向流中至少有两个扩展同向流包含相同的网络流;
S3:对所述扩展同向流进行优先级排序;
S4:按照排序后的扩展同向流的顺序执行调度,其中,包含于多个扩展同向流的网络流在随所述多个扩展同向流中优先级最高的扩展同向流调度之后不再随所述多个扩展同向流中其他的扩展同向流调度。
正如之前所讨论的,一个具有容错能力的调度方法的关键点在于避免掉队者。为了减少掉队者的数量,本发明采取后期绑定的策略。举例来说,假如有一个网络流它即可以被分为同向流C1也可以被分为同向流C2,换句话说,所述网络流是聚类过程中处于C1和C2的边界处(参考图6)。此时本发明不是强制为所述网络流指定C1或C2中的一个,而是暂时先不做出决定,直到真的要调度时,再将所述网络流分配给C1和C2中优先级高的同向流。这样的话,无论所述网络流是属于C1还是C2都不会成为一个掉队者。
这样做会造成两点影响。首先,最坏的情况下,也就是说初始的分类是正确的,那么这么做会引进了一个先驱者。其次,如果初始的分类是错的,那么这么做可以有效地阻止一个网络流成为掉队者。为了不让所有的网络流都成为先驱者,本发明只处理那些处于两个同向流之间的网络流。
参考图2和图7a,不是生成C1的掉队者,而是引入C2的先驱者,从而减小了平均CCT。通过本申请后面段落的介绍可以知道通过后期绑定本发明可以在有识别错误的情况下依旧改善CCT至少10%,降低由于识别错误导致的减速至少30%。
总之,本发明实施例通过将一个网络流分配给多个扩展同向流,再在调度过程中使所述分配至多个扩展同向流的网络流仅随优先级最高的扩展同向流调度,可以在不需要先验知识的情况下有效减少掉队者的数量,从而减小平均CCT。
如图4所示,在本发明的另一个实施例中,步骤S1之后,步骤S3之前,还包括步骤S2:对所述扩展同向流内部的各网络流进行优先级排序。
即便是实施了后期绑定,也还是难免有些网络流被错误的识别。一个更棘手的情况发生在C1和C2被聚类成一个同向流时。现有技术MADD或者每网络流公平共享,都是将网络流伸长直至整个同向流的末端。然而,如果将每个同向流中的网络流按优先级排序,那么被错误识别的网络流就更有可能早些完成。这样可以减小由于错误识别而造成的影响。例如,在图1b中,如果我们对C1中的网络流进行优先级排序,则期望的平均CCT将从2变为1.75个时间单位。这里,由于C1掉队者被调度的时刻并不知道,因此C1的CCT应该是介于1和2个时间单位的一个值,因此我们说期望的平均CCT为1.75个时间单位。
正如我们上面讨论过的,同向流内部优先级排序在有识别错误的情况下能够有效地减少由于识别错误而造成的影响。
考虑到这一点,本发明在不知道任何先验知识的情况下依据已经发送的字节数对扩展同向流内部的每个网络流进行优先级排序。这个对小同向流中的网络流掉入大的同向流中成为掉队者的情况很有效。并且大多数的情况下普遍存在的都是小同向流,因此前述小同向流中的网络流掉入大的 同向流中成为掉队者的情况也是经常发生的。参考图2和图7b,图2中C1(Q1中浅色)的掉队者(Q3中浅色)需要持续和C2(Q3中深色)的网络流一样长的时间,而图7b中却可以因为其本身的大小比较小而可以提早很多就完成。
这样的策略在相反的情况下也是有效的。即,当来自大同向流C2中的一个网络流加入到一个小同向流C1成为先驱者时。由于小的网络流更受到优待,因此C1的网络流更可能比来自C2的先驱者提早完成。
总之,本发明实施例通过对所述扩展同向流内部的各网络流进行优先级排序可以在有识别错误的情况发生时进一步减少CCT。通过本申请后面段落有关仿真部分的介绍可以知道通过同向流内部优先级排序可以在低识别准确度时为小同向流带来高达40%的提速。
下面将用伪代码的形式对本发明实施例进行描述。
其中,CoflowExtention(.)为每个识别的同向流生成一个扩展同向流所述扩展同向流是通过将所述同向流的边界向外扩展直径d的距离而得到的(参见伪代码第4行)。这就是说,C*进一步包括距离C小于d的所有网络流。需要注意的是,经过此步骤之后,一个网络流可能同时属于两个或者更多的扩展同向流。之后,所述属于多个扩展同向流的网络流会在它首次被调度时绑定至一个优先级最高的扩展同向流。
InterCoflow(.)利用D-CLAS对各个扩展同向流进行优先级排序。具体地讲,就是自动将扩展同向流安排到不同的队列QC中,对各扩展同向流队列流进行优先级排序(参见伪代码第9行)。本实施例中使用FIFO对各扩展同向流进行排序(参见伪代码第10行),所述扩展同向流将会保持运行直到其任务完成或者队列满了。使用FIFO可以减少同一个队列中扩展同向流之间的交错,从而减小CCT。
IntraCoflow(.)使用最小优先启发法(smallest-first heuristic)来对一个扩展同向流内部的各个网络流进行优先级排序。具体地,本发明用具有指数增长的阈值对网络流队列QF实施MLFQ(multi-level feedback queue scheduling,多级反馈队列调度)。这样的策略可以在没有先验知识的条件下令小的网络流具有比大的网络流更高的优先级。对于每个网络流队列中的各个网络流采用最大-最小公平(max-min fairness)分配带宽。(参见伪代码第18行)。
直径d反映了掉队者和先驱者之间的平衡。能够获得最优平均CCT的直径d跟同向流的识别半径∈密切相关,并且根据网络中流量分布的不同而变化。毫无疑问的是,极端的d值(例如,无穷大)肯定会得到一个差的CCT。然而,如前面提到的,掉队者造成的影响要远大于先驱者。因此,一个大的d值将有益于后期绑定。
此外,本发明实施例还提供一种服务器。如图5所示,所示服务器包括扩展模块、排序模块和执行模块。所述扩展模块用于依据预定条件对各同向流进行扩展,获得相应的扩展同向流,所述扩展同向流中至少有两个扩展同向流包含相同的网络流。所述排序模块用于对所述扩展同向流进行 优先级排序。所述执行模块用于按照排序后的扩展同向流的顺序执行调度,其中,包含于多个扩展同向流的网络流在随所述多个扩展同向流中优先级最高的扩展同向流调度之后不再随所述多个扩展同向流中其他的扩展同向流调度。
进一步的,在另一个实施例中,所述排序模块还用于在对各扩展同向流进行优先级排序之前对扩展同向流内部的各网络流进行优先级排序。
进一步地,所述排序模块按照先入先出算法对所述扩展同向流进行排序。
进一步地,所述排序模块按照最小优先启发法对所述扩展同向流内部的各个网络流进行优先级排序。
进一步地,所述排序模块在网络流队列之间使用多级反馈队列调度,对网络流队列中的各个网络流按照最大-最小公平的策略分配带宽。
前述实施例提供了一种基于同向流信息的调度方法,要实现所述调度方法,首先需要实现对所述同向流信息的采集。然而现有的基于同向流的解决方案都需要对应用进行改动才能提取同向流,而这在很多实际的情境下无法使用。为此本发明对现有软件框架进行了改造,造后的软件框架不再需要对应用进行改动就可以采集同向流信息以供使用。
在现有技术中,客户机和服务机之间通过远程过程调用(Remote Procedure Call,RPC)进行数据交换。参与远程过程调用(RPC)的软件框架至少包括应用、分布式计算框架和Java虚拟机。所述应用调用所述分布式计算框架发送RPC消息,但所述RPC消息中不包含同向流信息。所述应用和所述分布式计算框架都通过所述Java虚拟机进行编译。所述分布式计算框架可以是Apache Hadoop或者Apache Spark等。所述分布式计算框架进一步可以包括Netty框架等用于RPC发送的子框架。此时,所述应用通过所述分布式计算框架中的Netty框架发送RPC消息。一个RPC消息通过一个TCP链接进行发送,一个TCP链接对应一个网络流,一个或多个网络流构成一个同向流,一个应用对应一个Java虚拟机。
本发明的一个实施例中对现有技术中的软件框架做出的改造如下:
步骤A1,修改所述分布式计算框架,修改后的分布式计算框架在发送 RPC消息时将所述RPC消息所属同向流的同向流信息加入所述RPC消息中。
步骤A2,通过java字节码插装机制在所述Java虚拟机中增加一个解析模块,所述解析模块在所述Java虚拟机启动时加载,所述解析模块在RPC消息发送前解析所述RPC消息并获取所述同向流信息。
具体的,在Hadoop框架下,我们可以简单的认为属于一个job ID的RPC消息属于同一个同向流。因此,在本发明的一个实施例中,修改后的分布式计算框架,或者更具体的,修改后的Netty框架在发送RPC消息时将job ID加入RPC消息的消息格式中。
由于RPC消息通常在进入网络级之前就被序列化成字节流,因此需要进一步增加所述模块来解析所述RPC消息,从而获取所述同向流信息。
Java字节码插装机制指的是在Java字节码生成之后,对其进行修改,增强其功能。这种做法相当于对应用程序的二进制修改。该方法能够在不修改源代码的前提下在类中加入新的成员、变量的声明、初始化;在代码的特定位置插入新的指令或者修改现有的指令,以及在目标类中插入新的方法。因此,通过使用Java字节码插装机制,就可以在不修改原Java虚拟机源代码的条件下增加所述解析模块。
至此,本发明实施例通过修改分布式计算框架和Java虚拟机对用于进行RPC的软件框架进行改造,改造后的软件框架不需要应用做出任何修改便可实现对同向流的采集,以供使用。
此外,现在的同向流实现都是在用户控件模仿阻塞行为的,这可以有效地促使线程让没调度的流进入睡眠。因此,一个CPU线程在任一时间最多只能发送一个流,不可伸缩。为了让每个线程能够服务多个I/O操作,通常的做法是利用操作系统提供的I/O多路复用主数据结构(multiplexing primitives)(例如,POSIX中的select和poll,Windows中的IOCP)。Hadoop和Spark对低等级非阻塞I/O使用java.nio。由于很多流行的框架(包括Hadoop和Spark)在Java虚拟机下编译,因此本发明实施例提供一种方法可以在支持java.nio的同时在Java虚拟机上支持很多第三方库。对此,本发明实施例采用Java字节码插装改变应用在运行时的行为,采集同向流信 息,基于调度结果拦截I/O操作。在Java虚拟机引导过程中,所述插装的代理被预加载。在首次I/O操作时,所述代理检测原始字节码的加载,并对其进行更改使其记录运行中Hadoop和Spark在Shuffle阶段中的job ID。用这样的方法同向流的信息就被采集到了。
Non-blocking I/O(非阻塞输入输出)是现代网络服务器的基础技术,可以提升网络服务器同时处理的请求数量级。但是由于步骤A1中对计算框架做出了改动,使得所述计算框架不能兼容非阻塞输入输出(non-blocking I/O),本发明的一个实施例通过Java字节码插装机制对Java虚拟机调用操作系统Non-blocking I/O接口的方法进行改动,使得改动过后的计算机框架能够兼容操作系统Non-blocking I/O。
以上实施例是对现有软件框架进行的改造,改造后的软件框架实现了在不修改应用的条件下获取同向流信息。接下来的实施例中将介绍如何对现有软件框架进行进一步地改造,以实现基于所述同向流信息对网络流的调度。
首先,所述改造进一步包括步骤:
步骤A3,生成一个代理,所述代理接收各Java虚拟机中的解析模块发送的同向流信息,并将所述同向流信息发送给调度器,所述代理还在所述调度器做出调度决定后执行所述调度决定;
步骤A4,生成所述调度器,所述调度器接收所述代理发送的同向流信息,并基于所述同向流信息做出调度决定。
由于执行调度决定实际上是对发送RPC消息的TCP连接进行流量控制或者是优先级控制的过程。因此,实施调度决定需要知道哪一个TCP链接负责发送哪个RPC消息。为了将所述RPC消息与发送所述RPC消息的TCP链接关联起来,本发明一实施例在前述步骤A2中进一步地令所述解析模块在获取所述同向流信息的同时还记录所述RPC消息对应的TCP链接,并将所述TCP链接的信息一并发送给所述代理。所述代理在获得TCP连接的信息之后,就可以依据所述调度器做出的调度决定对相应的TCP链接进行流量控制了。
更具体的,在一个实施例中,所述软件框架运行在Linux操作系统上, 所述代理使用Linux下的tc模块,并使用两层分层令牌桶(HTB,Hierarchical Token Bucket)对所述TCP链接进行流量控制。叶节点执行每流速率,根节点将外出包归类至对应的叶节点。
在进行了如上A1-A4步骤改造之后的软件框架的基础之上,本发明实施例提供了一种处理RPC通信中同向流信息的方法。所述方法包括:
步骤B1,所述应用通过所述分布式计算框架发送RPC消息,所述RPC消息包含所述RPC消息所属同向流的信息;
步骤B2,所述Java虚拟机在发送所述RPC消息前通过解析所述RPC消息获取所述同向流信息;
步骤B3,所述Java虚拟机将所述同向流信息发送给所述代理;
步骤B4,所述代理接收各Java虚拟机发送的同向流信息,并将所述同向流信息发送给所述调度器;
步骤B5,所述调度器基于所述同向流信息做出调度决定,并将所述调度决定发送给所述代理;
步骤B6,所述代理执行所述调度决定。
其中,所述分布式计算框架是Apache Hadoop或者Apache Spark,所述分布式计算框架包括经过修改的Netty框架,所述经过修改的Netty框架发送的RPC消息的消息格式中包含用于描述所述RPC消息所属同向流的项。
所述Java虚拟机中包含一个通过Java字节码插装机制增加的解析模块,所述解析模块在Java虚拟机启动时被加载,所述解析模块用于实现步骤B2中所述在发送所述RPC消息前通过解析所述RPC消息获取所述同向流信息。
在一个具体的实施例中,所述解析模块在获取所述同向流的同时还记录所述RPC消息对应的TCP链接,并将所述TCP链接的信息一并发送给所述代理;此时所述步骤B6具体包括:所述代理依据所述调度器做出的调度决定对相应的TCP链接进行流量控制。
进一步的,所述软件框架还Linux操作系统,所述代理使用Linux下的tc模块并使用分层令牌桶进行流量控制。
执行上述步骤B1和步骤B2,可以在不需要应用做出任何改动的条件 下获取同向流信息。进一步执行上述步骤B3至步骤B6可以在不需要应用做出任何改动的条件下,基于所述同向流信息对所述同向流所包含的网络流进行调度。
相应地,本发明实施例还提供一种服务器,所述服务器上建有软件框架,如图16所示。所述软件框架包括应用、分布式计算框架,Java虚拟机,所述应用发送的RPC消息中包含所述RPC消息所属同向流的信息,所述Java虚拟机在发送所述RPC消息前通过解析所述RPC消息获取所述同向流信息。
其中,所述分布式计算框架是Apache Hadoop或者Apache Spark,所述分布式计算框架包括RPC子模块,通过所述RPC子模块发送的RPC消息的消息格式中包含用于描述所述RPC消息所属同向流的项。所述RPC子模块可以是经过修改的Netty框架。
所述Java虚拟机中包含一个通过Java字节码插装机制增加的解析模块,所述解析模块在Java虚拟机启动时被加载,所述解析模块用于实现所述在发送所述RPC消息前通过解析所述RPC消息获取所述同向流信息。
进一步地,所述软件框架还包括代理和调度器。
所述Java虚拟机中的所述解析模块向所述代理发送其获取的同向流信息;所述代理接收各解析模块发送的同向流信息,并将所述同向流信息发送给调度器;所述调度器基于所述同向流信息做出调度决定,并交由所述代理执行所述调度决定。
进一步地,所述解析模块在获取所述同向流信息的同时还记录用于发送所述RPC消息的TCP链接的信息,并将所述TCP链接的信息一并发送给所述代理。所述代理依据所述调度决定对相应的TCP链接进行流量控制。
在一个具体的实施例中,所述软件框架进一步包括Linux操作系统,所述代理使用Linux下的tc模块并使用分层令牌桶进行流量控制。
使用上述实施例中服务器,可以实现在不修改应用的条件下对同向流信息的采集,并基于所述同向流信息进行调度。接下来通过仿真实验对本发明性能进行评估。评估主要针对以下两个问题。
首先关于所述代理。
为了测量由所述代理引起的CPU开销,发明人在具有8GB内存4核Intel E5-1410 2.8GHz CPU的Dell PowerEdge R320服务器的NIC(Network Interface Card,网络接口卡)上运行一百多条网络流,使其工作在饱和状态下。与不使用代理相比,使用代理仅造成1%的CPU负荷增长,而吞吐量保持不变。也就是说,本发明只需要牺牲很小的性能就可以扩展很多代理。
其次,关于所述调度。总的来讲,本发明在正常工作负载下且超过90%的识别准确度时,能够实现和Aalo相当的CCT(Aalo需要先验知识),同时比每流公平共享(per-flow fair sharing)算法CCT小82.9%。此外,本发明的容错设计使CCT提速1.16倍。减少40%由于识别错误而引起的减速。后期绑定和同向流内部优先级排序对本发明都是非常重要的。前者可减少10%的CCT,后者对小的同向流可减少40%的CCT。
本发明的平均CCT及95百分位CCT相比于每流公平共享(per-flow fair sharing)算法的CCT分别减少了58.3%和80.4%,而和需要同向流先验知识的Aalo相比,本发明几乎具有相同的表现。
下面将具体介绍所述实验和仿真是如何进行的。
首先建立试验床。所述试验床由40个连接至Pronto 3295 48-port Gigabit Ethernet switch(48端口、千兆比特、以太网服务器)的服务器。每个服务器都是一个Dell PowerEdge R320并搭载4核Intel E5-1410 2.8GHz CPU,8G内存,500G硬盘和Broadcom BCM5719NetXtreme Gigabit Ethernet NIC。每个服务器具有Linux 3.16.0.4内核运行Debian 8.2-64bit。实验利用同样的计算引擎计算Varys和Aalo。设定坐标间隔Δ=100ms,并设定∈=100,d=150为缺省值。
然后设定仿真器。对于大规模仿真,所述实验使用轨迹驱动网络流级别仿真器。并用此仿真器运行同向流轨迹详细的任务级别的重播。它保存任务的输入输出比,位置条件,以及两个工作之间的到达间隔时间,并以1s作为决定间隔。
接着设定工作负载。实验使用真实工作负载,采集来自3000机器,150机架脸谱网(Facebook)生产集群一小时的Hive/MapReduce轨迹。所述轨迹包含超过500条同向流(7*105个网络流)。所述同向流的大小(1MB-10TB) 以及一个所述同向流内部的网络流的数量(1-2*104)遵循重尾分布。图8示出同向流之间的到达时间分布以及并发同向流的数量的分布。实验中相应地按比例缩小作业以与设定的最大可能为40Gbps的二分带宽相匹配,同时还保留所述作业的通信特点。
然而,所述脸谱网的轨迹并不包含具体的网络流级别的信息,例如网络流的起始时间以及端口号等。为了能够在仿真中进行合理的重演,首先在实验床中的Spark和Hadoop上运行基准程序(例如,WordCount和PageRank)。基于试验床学习到的同向流内部网络流的到达时间模式,我们将网络流的起始时间信息加回脸谱网工作负载中以模仿Spark和Hadoop的网络流量。
Spark网络流量:每个同向流内部的各个网络流按照100ms内的均匀分布进行生成。
Hadoop网络流量:每个同向流内部的各个网络流按照1000ms内的均匀分布进行生成,实验还增加平均为100ms的额外指数延迟。
最后设定度量。为了易于将本发明的CCT与Aalo(当今最先进的需手动注解同向流的同向流调度方法)以及每网络流公平共享(per-flow fair sharing)的CCT进行比较,这里将本发明的CCT进行标准化。即:
值越小说明性能越好。如果标准化后的值大于(小于)1,则说明本发明更快(更慢)。
下面介绍试验床实验的结果。
图9显示与基于TCP的每流公平共享相比,本发明可以将平均CCT减小58.3%,而将95百分位CCT减小80.4%。相应地,平均作业完成时间和95百分位作业完成时间(JCT,Job Completion Time)也分别减少28.5%和60%。还可以看到Aalo标准化后的作业以及同向流完成时间都接近1,说明本发明几乎具有和Aalo一样的表现。
为了评估本发明的可伸缩性,试验床实验模仿运行了高达40,000个代理。图10a和图10b展示了由500个协调轮回(coordination round)得出的不同数量的模仿代理(例如40,000模仿代理指每个机器模仿1000代理)平均完成一个协调轮回的时间。在每次实验中,协调器将平均100个并发同向流的调度信息转移至每个模仿代理。
与预期的一致,本发明的伸缩性并不像Aalo的那么好,这是因为本发明有识别过程,而Aalo并没有此过程。然而,需要说明的是本发明的识别加速已经具有很大的进步—DBSCAN支持400个代理都需要好几分钟。
尽管本发明可以在6954ms协调40,000个代理,然而协调周期△(coordination period△)肯定是增长的。为了理解△对性能的影响,我们用越来越高的△再次运行之前的实验(参见图10b)。可以观察到,类似于Aalo,本发明在△增长时表现的更糟,并在△>100s时性能骤然下降。
下面将重点介绍一下关于调度的部分。
首先介绍本发明在正常工作负载下调度的仿真结果。图11a示出几种不同的调度算法在标准化的CCT方面的表现。显然本发明可以有效地容许一些识别错误,并且明显地优于每网络流公平共享。举例来说,对于Spark网络流量来说,在95%识别准确度时,本发明几乎与Aalo的表现一样好,同时本发明明显优于每网络流公平共享(CCT减少62.9%)。对于Hadoop网络流量来说,在90%的识别准确度时,本发明稍稍比Aalo差一点点(CCT长10%),但还是优于每网络流公平共享(CCT减少56.5%)。为了更直观地表现,图11b显示了本发明在Spark网络流量下的CCT的CDF(Cumulative Distribution Function,累积分布函数),可以看到这也几乎与Aalo一致。
然后介绍本发明在两个具有挑战性的场景中的仿真结果。所述挑战性场景一个是指成批到达(batch arrival),一个是指展开到达(stretched arrival)。在这两个场景下,本发明的识别精度不如在正常工作负载下的表现。
图12a对比了几种不同的调度算法在使用Hadoop网络流量并处于成批到达的场景下的表现。可以预料,在这种场景下有更多的错误识别发生。 相应地,本发明调度方法的性能逐渐下降。举例来说,本发明在成批到达的场景下与具有正确信息的Aalo相比,性能低(CCT长30%-80%)。
图12b显示了几种不同的调度算法在展开到达场景下的表现。最后再来验证如图13中本发明的容错设计的有效性。可以注意到,不具有后期绑定和同向流内部优先级排序时,本发明调度方法与直接使用Aalo相比对含有不准确识别信息的输入数据进行调度的结果是一样的。图13a显示在成批到达的场景下,本发明容错设计总体上可以带来3-5%的CCT改善。特别的是,本发明容错设计可以为小同向流来带10-20%的CCT改善(图15a中的后者)。进一步的,由图13b可知,本发明在展开到达场景下可以带来更多的性能提升。此时,本发明容错设计给Hadoop和Spark网络流量可以提供总体为1.16倍、1.14倍的提速。考虑到本发明大约比Aalo慢1.3倍(图12b),1.16倍提速可以减少由于错误识别而造成的影响约40%。
接下来介绍所述后期绑定和所述同向流内部优先级排序各自独立的好处。首先后期绑定在展开到达的场景下仍可以带来不可忽视的改善。无论是对Hadoop还是Spark,改善都超过10%。相对而言,同向流内部优先级排序带来的改善会稍微少一些,在展开到达的场景下改善Hadoop 7%,在其他场景下改善1-5%。然而,同向流内部优先级排序能为小同向流CCT带来高达40%的改善。
为了理解为什么后期绑定可以有效的改善CCT,图14a展示了以直径d对所述识别了的同向流进行扩展之前和扩展之后(即前述的扩展同向流C*)的识别准确度。可以观察到,查全率提升4%,代价是查准率下降4%。高查全率意味着一个同向流中的网络流有更多的网络流被成功的划分在一个组中,也就是说同向流扩展有效地识别了一些掉队者。这些被识别的掉队者在他们被绑定至具有最高优先权的同向流后就不再是掉队者了。因此,后期绑定可以有效地减少掉队者的数量,从而改善CCT。
在展开到达场景下,所述后期绑定可以带来明显地改善。而在展开到达的场景下直径d是如何对所述后期绑定的效果造成影响呢?从图14b中可以看到,在开始的时候,标准化的CCT随着d的增加而改善。这说明更多的掉队者被成功地识别了,因此减小了相应同向流的CCT。然而,当d 继续增加,后期绑定会引入过多的先驱者,导致更长的CCT。
同向流内部的优先级排序又是如何有益的呢?为说明这一点,首先依据同向流的长度和宽度对所述同向流进行分类。具体的,最长的网络流小于5MB的同向流被认为是短的同向流。宽度不超过50个网络流的同向流被认为是窄的同向流,则认为。我们发现超过50%的同向流都是又短又窄的(SN)同向流。然而,由于它们占总网络流量负载还不到0.1%,因此它们的表现并不能清楚地通过总CCT来表现。图15a显示了SN同向流在成批到达时标准化的CCT。可以看到同向流内部的优先级排序可以带来16%的改善。一个可能的原因是当许多同向流成批到达时,本发明有可能将一些同向流错误分类为“超级”同向流。同向流内部的优先级排序可以有效地加速这些被错误分类的同向流中的SN同向流。
图15b所示为展开到达场景下SN同向流的标准化CCT。展开到达模式容易产生许多掉队者。而同向流内部优先级排序可以有效地提升SN同向流中掉队者的速度高达40%。
近来,同向流抽象越来越多地被人们关注。然而,现有的同向流知晓方案都要求开发者对应用做出很大的改动,并需要手动对同向流进行注解。本发明首先提出将对应用透明的同向流识别和具有容错能力的同向流调度相结合。
尽管已经有很多关于ITC(Internet Traffic Classification,网络流量分类)的文献,一些本质的差别还是让它们无法被应用到同向流识别中。首先,一旦父亲工作结束,由一个特定同向流捕捉的网络流相互之间的关系便不再重现。因此,同向流无法被标注成预定的类别。与此相反,在传统的网络流量分类中,网络流量通常对应于稳定的类别。其次,时效性对同向流识别是非常重要的,这是因为它的结果要作为调度的输入。与此相反,在很多传统的ITC任务中,迟来的识别也仍是有作用的(例如,入侵检测)。
还有一个相似的主题,鲁邦调度,已经在运筹学中被大量研究。然而,鲁邦调度首要的是处理在预计算调度过程中的突发事件。而本发明具有容错能力的调度方法是为了调度可能具有错误输入的任务。
本发明可以不需要对应用做任何修改就能够自动地识别并调度同向 流。本发明利用增量式聚类算法以快速运行对应用透明的同向流识别,并通过提出具有容错能力的同向流调度算法来减小识别错误的可能。试验床实验以及轨迹追踪仿真显示本发明在超过90%的识别准确度时,本发明调度方法有效地处理剩余的识别错误。本发明的总体表现与Aalo相当,同时明显优于每网络流公平共享。
总而言之,本发明不需要手动地在应用中进行注解,因此更加实用。同时本发明还提供了一些可以研究方向,包括在数据密集型工作负载前的识别机制的推广,为实现更佳的可伸缩性而进行的去中心化,在线参数调整,处理同向流相关性,以及将具有容错能力的调度算法和分配算法应用至其他领域。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!