用于增强虚拟音频高度感知的系统和方法与流程
本发明涉及一种音频处理系统,并且具体地,涉及一种用于增强用户的虚拟音频高度感知(virtual audio height perception)的系统。
背景技术:
环绕音响系统通常具有围绕听众布置的多个扬声器单元。在诸如那些用于家庭娱乐的的简单的环绕音响系统中,扬声器可以安装为5.1扬声器配置,其包括前左扬声器单元、前右扬声器单元、后左扬声器单元、后右扬声器单元、中央扬声器单元和重低音扬声器。每个扬声器单元可以包括一个或多个驱动器。驱动器是指用于响应来自音频源的电子音频输入信号而产生声音的单个的电声换能器(electroacoustic transducer)。音频源(例如,CD、DVD、蓝光或数字媒体内容播放器)可以为不同的音频声道提供不同的音频信号,其中每个声道的音频信号被发送到不同的扬声器单元,用于产生由该信号表示的声音。
在更复杂的环绕音响系统中(例如那些在电影院使用的),通常会有更大数量的扬声器单元围绕着听众。音频源可以为更大数量的音频声道提供音频信号,其中每个声道的音频信号可以被发送到位于相对于听众的特定区域中的一组一个或多个邻近的扬声器,以产生由该信号表示的声音。通过具有更多的扬声器基于不同的音频声道的音频信号来产生声音,听众能够更好地感知来自听众周围的不同地点的声音,从而为听众提供更逼真和身临其境的娱乐体验。
为了进一步增强听众的娱乐体验,一些环绕音响系统包括一个或多个位于听众上方的扬声器单元,用于基于高度信道的音频信号来再现声音。例如,高度信道的音频信号可以表示来自位于听众当前视野上方的物体的声音,在特定的场景,诸如在听众上方飞行的直升机的声音。然而,这种方法存在问题。需要位于屋顶上的一个或多个扬声器的环绕音响系统设置起来很复杂。例如,在房间或结构的屋顶上安装一个或多个扬声器单元和布线可能是复杂或不切实际的,尤其是在家庭娱乐环境中,有可能天花板高度较低。安装扬声器单元后,可能很难将扬声器移动到不同的位置(例如,到不同的房间,或在同一个房间的新位置以适应不同的设置进行配置)。
已经提出了解决方案以帮助避免在家庭娱乐环境中使用的屋顶安装的扬声器。在一个示例中,如图1所示,向上发射扬声器(upward firing speaker)100和向前发射扬声器(forward firing speaker)102被放置在电视显示器104的附近。扬声器100和102可以是单独的扬声器单元(例如,向上发射扬声器100可以形成声吧系统(sound bar)的一部分,并且向前发射扬声器102可以形成落地扬声器单元的一部分),或可替换地,扬声器100和102可以作为一个扬声器单元集成在一起。向上发射扬声器102基于来自高度信道的音频信号产生声音,并引导声音沿着路径106(即朝向位于收听者110之上的预定位置108(例如屋顶的一部分),然后向收听者110反射)传播。向前发射扬声器100基于来自其它音频声道的音频信号产生声音112,并引导声音112沿路径112直接向收听者110传播。这种方法的问题是,高度信道通常覆盖宽的发声频率频谱,并且这些频率中的一些(特别是较低的频率)缺乏方向性。这意味着只有(具有特定频率)一些声音在从位置108反射后将被引导向收听者110,而其它频率的声音可能不会被适当地引导至收听者110,并且因此收听者100会感觉到这种声音比被适当地直接引导至收听者110的声音弱。因此,收听者110将难于听到一些源于向上发射扬声器100的声音,这些声音可能被源于向前发射扬声器102的直接的声音淹没。因此,将减弱收听者的娱乐体验。
本发明的目的是提供帮助解决上述确定的问题中的一个或多个的系统和方法。
技术实现要素:
根据本发明的第一个典型实施例,提供了一种用于增强用户的虚拟音频高度感知的音频处理系统,包括:
调整模块(rebalancing module),用于从源接收音频信号,该音频信号包括表示用于直接向用户发送的声音的低层信号(low layer signal)和表示通过从该用户上方的预定位置反射而向该用户发送的声音的高度信号(height signal);
该调整模块用于将该高度信号与该低层信号进行比较并且基于该比较来调整该高度信号的振幅(amplitude,幅度);
该低层信号被发送到用于将由该低层信号表示的声音直接向该用户发送的第一扬声器装置的一个或多个扬声器;并且
经调整的高度信号被发送到用于将由该高度信号表示的声音通过从该用户上方的预定位置反射而向该用户发送的第二扬声器装置的一个或多个扬声器。
优选地,通过该调整模块该高度信号的振幅包括基于该比较调整通过增益电平(gain level)来增加该高度信号的振幅。
优选地,该增益电平是下列项中的一个:(i)预定值;或(ii)基于该低层信号的振幅动态确定的值。
优选地,该系统进一步包括:
高通滤波器,用于产生由仅具有预定频率阈值的频率或高于该预定频率阈值的频率的经调整的高度信号所表示的声音的第一声部(first sound portion),其中,该第一声部被发送到用于通过从该用户上方的该预定位置反射而向该用户发送该第一声部的该第二扬声器装置的一个或多个扬声器;和
低通滤波器,用于产生由仅具有低于该预定频率阈值的频率的经调整的高度信号所表示的声音的第二声部(second sound portion),其中,该第二声部被发送到用于直接向该用户发送该第二声部的该第一扬声器装置和/或该第二扬声器装置的一个或多个扬声器。
优选地,该预定频率阈值为下列项中的一个:(i)1kHz的值;(ii)在1kHz与1.5kHz之间的预定值。
优选地,该系统进一步包括:路径补偿模块(path compensation module),用于在预定的第一时间间隔之后,控制该第一扬声器装置和/或该第二扬声器装置以基于该第二声部和/或该低层信号产生声音,该第一时间间隔开始于该第一扬声器装置和/或该第二扬声器装置基于该第一声部的对应部分产生声音的时间。
优选地,基于该第一扬声器装置和/或该第二扬声器装置与该用户之间的距离以及该第一扬声器装置和/或该第二扬声器装置与该用户上方的预定的第一区域之间的高度确定该第一时间间隔。
优选地,基于在与该用户邻近的区域中获得的声音测量值(sound measurement,声音测量)确定该第一时间间隔。
优选地,该系统进一步包括:优先效应延迟模块(precedence effect delay module),用于在预定的第二时间间隔之后,控制该第一扬声器装置和/或该第二扬声器装置以基于该第二声部和/或该低层信号产生声音,该第二时间间隔开始于该第一扬声器装置和/或该第二扬声器装置基于该第一声部的对应部分产生声音的时间。
优选地,该系统进一步包括:优先效应延迟模块,用于在预定的第二时间间隔之后,控制该第一扬声器装置和/或该第二扬声器装置以基于该第二声部和/或该低层信号产生声音,该第二时间间隔开始于该第一时间间隔的结束。
根据本发明的第二典型实施例,提供了一种用于增强用户的虚拟音频高度感知的音频处理方法,包括以下步骤:
从源接收音频信号,该音频信号包括表示用于直接向用户发送的声音的低层信号和表示通过从该用户上方的预定位置反射而向该用户发送的声音的高度信号;
将该高度信号与该低层信号进行比较并且基于该比较来调整该高度信号的振幅;
将该低层信号发送到用于将由该低层信号表示的声音直接向该用户发送的第一扬声器装置的一个或多个扬声器;并且
将经调整的高度信号发送到用于将由该高度信号表示的声音通过从该用户上方的预定位置反射而向该用户发送的第二扬声器装置的一个或多个扬声器。
优选地,该调整步骤包括:基于该比较通过增益电平来增加该高度信号的振幅。
优选地,该增益电平是下列项中的一个:(i)预定值;或(ii)基于该低层信号的振幅动态确定的值。
优选地,该方法进一步包括以下步骤:
产生由仅具有预定频率阈值的频率或高于预定频率阈值的频率的经调整的高度信号所表示的声音的第一声部,其中,该第一声部被发送到用于通过从该用户上方的该预定位置反射而向该用户发送该第一声部的该第二扬声器装置的一个或多个扬声器;并且
产生由仅具有低于该预定频率阈值的频率的经调整的高度信号所表示的声音的第二声部,其中,该第二声部被发送到用于直接向该用户发送该第二声部的该第一扬声器装置和/或该第二扬声器装置的一个或多个扬声器。
优选地,该预定频率阈值为下列项中的一个:(i)1kHz的值;(ii)在1kHz与1.5kHz之间的预定值。
优选地,该方法进一步包括以下步骤:在预定的第一时间间隔之后,控制该第一扬声器装置和/或该第二扬声器装置以基于该第二声部和/或该低层信号产生声音,该第一时间间隔开始于该第一扬声器装置和/或该第二扬声器装置基于该第一声部的对应部分产生声音的时间。
优选地,该方法进一步包括以下步骤:基于该第一扬声器装置和/或该第二扬声器装置与该用户之间的距离以及该第一扬声器装置和/或该第二扬声器装置与预定的第一区域之间的高度确定该第一时间间隔。
优选地,该方法进一步包括以下步骤:基于在与该用户邻近的区域中获得的声音测量值确定该第一时间间隔。
优选地,该方法进一步包括以下步骤:在预定的第二时间间隔之后,控制该第一扬声器装置和/或该第二扬声器装置以基于该第二声部和/或该低层信号产生声音,该第二时间间隔开始于该第一扬声器装置和/或该第二扬声器装置基于该第一声部的对应部分产生声音的时间。
优选地,该方法进一步包括以下步骤:在预定的第二时间间隔之后,控制该第一扬声器装置和/或该第二扬声器装置以基于该第二声部和/或该低层信号产生声音,该第二时间间隔开始于该第一时间间隔的结束。
附图说明
参照所附附图仅通过示例的方式描述本发明的典型实施例,其中:
图1是现有技术的声音系统的示图;
图2A是根据本发明第一典型实施例的音频处理系统中的模块的框图;
图2B是根据本发明第二典型实施例的音频处理系统中的模块的框图;
图2C是根据本发明第三典型实施例的音频处理系统中的模块的框图;
图2D是根据本发明第四典型实施例的音频处理系统中的模块的框图;
图2E是根据本发明第五典型实施例的音频处理系统中的模块的框图;以及
图3是根据本发明典型实施例的音频处理方法的流程图。
具体实施方式
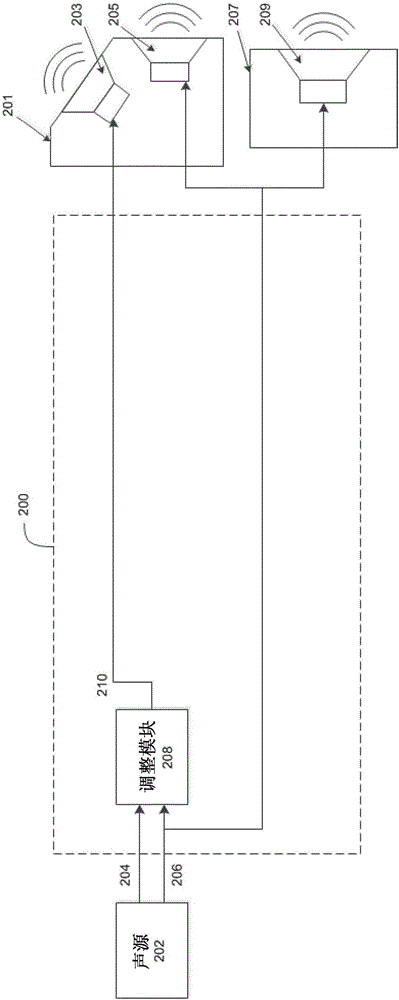
图2A是示出了根据本发明典型实施例的音频处理系统的主模块的框图。如在图2A中示出的,音频处理系统200从音频源202(或声源)接收电音频输入信号(即,高度信号204和低层信号206),由音频处理系统200处理该电音频输入信号以生成提供至一个或多个扬声器单元201和207的电音频输出信号。
扬声器单元201和207均可以包括一个或多个驱动器(例如,203、205、209)。驱动器是指响应于电音频输入信号产生声音的单个电声换能器,并且例如,驱动器可以是平板扬声器、传统扬声器、高度定向扬声器等。在典型实施例中,扬声器单元201可包括一个或多个向上发射扬声器203和/或一个或多个向前发射扬声器205。扬声器203和205可以沿着或者关于长轴布置以形成声吧系统。在典型实施例中,扬声器单元207可包括一个或多个向前发射扬声器209。
根据本发明的典型实施例,音频源202表示代表使用连接至音频处理系统200的扬声器单元201、207生成的声音的音频信号的来源。例如,音频源202可以是经由有线或无线数据连接(例如,经由RCA、USB、光输入、同轴输入、蓝牙或IEEE 802.11无线/WiFi连接)连接至音频处理系统200的媒体播放器设备(例如,移动电话、MP3播放器、CD播放器、DVD播放器、蓝光播放器或数字媒体内容播放器)。媒体播放器设备从与一段媒体内容的一个或多个不同的音频信道(例如,高度信道、左前信道、右前信道、左后信道、右后信道、中央信道以及音乐或者视频记录的超低音信道)相关联的存储介质(例如,存储数据的磁带、光盘或磁盘、RAM/ROM/闪存、硬盘、或网络存储设备)读取数据,并且生成表示每个音频信道要再现的声音的不同的音频输入信号。高度信道包括表示来自以上听众的当前视角的目标的声音的音频数据和/或音频信号。下层信道包括表示来自高度信道旁边的一个或多个其他音频信道的声音的音频数据和/或音频信号。在图2A中示出的实例中,音频源202生成至少:(i)表示基于来自高度信道的数据确定的声音的高度信号204,以及(ii)表示基于来自下层信道的数据确定的声音的低层信号206
根据本发明另一典型实施例(附图中未示出),音频源202可以是构成音频处理系统200的一部分的音频处理模块。在这种实施方式中,音频源202接收不包括高度信道的一个或多个音频信道的音频输入信号,并且然后基于所接收的音频输入信号,生成至少:(i)表示模拟高度信道的声音的高度信号204;以及(ii)表示一个或多个其他音频信道的声音的低层信号206。例如,音频源202可以基于以下因素中的一个或多个确定来自音频信道中任一个的某些声音分量为模拟高度信道(并且因此由高度信号204表示)的一部分:(i)具有预定频率值以上的音调(pitch)的声音分量;(ii)基于与音频信道相关联的任意元数据预测为声音的声音分量,该声音源自于上述的听众,和/或来自不同的音频信道的相应声音分量的一个或多个音频特性的比较(诸如,相对音量、音调、一致性和/或时间间隔内声音分量的持续时间);(iii)基于声音分量与声音样本库的比较预测为涉及某个目标(例如,直升机桨叶)的声音分量。
在图2A中示出的实施方式中,音频处理系统200由从音频源202接收高度信号204和低层信号206的调整模块208构成。低层信号206通常表示直接向收听者(或者用户)发送的声音。高度信号204通常表示旨在从用户上方的预定位置发送给用户或者通过从用户上方的预定位置反射而发送给用户的声音。调整模块208比较高度信号204和低层信号206的一个或多个音频特性,并且基于该比较来调整高度信号204的振幅级(amplitude level)。例如,调整模块208可以比较高度信号204和低层信号206的振幅,并且然后基于该比较调整高度信号204的振幅。
在典型实施例中,如果高度信号204的振幅在特定时间点降到相对于低层信号206的振幅设置的预定振幅阈值以下(例如,如果高度信号204的振幅小于低层信号206的振幅),那么调整模块208通过增益电平调整在该特定时间点高度信号204的振幅。增益电平可以是将高度信号204的当前振幅提高一预定量的预定值。可替换地,增益电平可以是动态值,例如,其通过超过相应时间点处低层信号206的振幅的一预定量或者通过相应时间点处的低层信号206的多个振幅而增大高度信号204的当前振幅。调整模块208生成随后可被传送至扬声器单元201的一个或多个向上发射扬声器203的经调整的高度信号210,用以通过从用户上方的预定位置(例如,108)反射而向用户发送声音。可以将低层信号206分别传送至扬声器单元201和207中的一个或多个向前发射扬声器205或209,以直接向用户发送声音。
图2B中所示出的典型实施例包含图2A中示出的实施方式的所有的特征,但进一步包括高通滤波器212、低通滤波器214以及信号组合器220。在图2A和图2B中,相同的数字用于指代两个实施方式所共同的部件。
在图2B中所示出的典型实施例中,经调整的高度信号210被传送至高通滤波器212和低通滤波器214。高通滤波器212生成由仅具有预定频率阈值或以上的频率的经调整的高度信号210表示的声音的第一声部。高通滤波器212的输出然后可以被传送至扬声器单元201的一个或多个向上发射扬声器203,以通过从用户上方的预定位置(例如,108)反射向用户发送声音。在典型实施例中,预定频率阈值是1kHz,或可替换地,可以是1kHz与1.5kHz之间的值。低通滤波器214产生由仅具有低于预定频率阈值的频率的经调整的高度信号210表示的声音的第二声部。低通滤波器214的输出(直接或者在信号组合器220将高通滤波器212的输出与低层信号206组合之后)可分别被传送至扬声器单元201和/或207中的一个或多个向前发射扬声器205和/或209,以直接向用户发送声音。
使用高通滤波器212和低通滤波器214的优点在于:来自经调整的高度信号210中往往更有方向性的高频率声音分量将会由向上发射扬声器203通过从用户上方的一点的反射而引导向用户。由于声音更有方向性,即使声音被反射用户也能更清楚地听见声音。经调整的高度信号210中往往方向性较弱的低频率声音分量将经由向前发射扬声器205和/或209直接引导向用户。
图2C中示出的典型实施例包含图2B中示出的实施方式的所有的特征,但进一步包括路径补偿模块216和216'。路径补偿模块216和216'可以实现为独立的模块,或可替换地,可通过单个模块的方式提供。在图2B和图2C中,相同的数字用于指代两个实施方式所共用的部件。
在图2C中示出的典型实施例中,通过低通滤波器214生成的第二信号部分被传送至路径补偿模块216,并且从音频源202接收的低层信号206被传送至路径补偿模块216'。路径补偿模块216和216'两者均将第一时间延迟(由第一时间间隔表示的)引入至由扬声器单元201和/或207生成第二声部(并且优选地还有低层信号)的时间。换言之,路径补偿模块216和216'控制扬声器单元201和/或207中的一个或多个向前发射扬声器205和/或209,用以在预定第一时间间隔之后基于第二声部和/或低层信号产生发送给用户的声音。第一时间间隔可以开始于扬声器单元201和/或207中的一个或多个向前发射扬声器205和/或209基于第一声部的对应部分产生声音的时间。在该上下文中,第一声部的对应部分是指在路径补偿模块216和216'处理第二声部(和/或低层信号)的相关部分的同时由从音频源202接收的第一声部表示的音频信号的部分。在组合的信号被传送至扬声器单元201和/或207中的一个或多个向前发射扬声器205和/或209用于产生声音之前,信号组合器220可以将路径补偿模块216和216'的输出组合。
参照图1,能够看出反射声音106的路径比直接声音112的路径稍微长一些,从而导致反射声音106比直接声音112花费稍微较长的时间到达收听者110。引入第一时间延迟的优点是延迟直接声音(例如,由低通滤波器214生成的第二声部和/或低层信号206表示的声音)的产生,使得这些直接声音将会与反射声音(例如,由高通滤波器212生成的第一声部表示的声音)基本上同时到达收听者。
在典型实施例中,基于扬声器单元201和/或207与用户之间的距离,以及扬声器单元201和/或207与用于从用户上方反射声音的预定的第一区域(例如,108)之间的高度来确定第一时间延迟。
可替换地,在另一典型实施例中,基于使用被放入与用户或听众相邻的区域中的一个或多个麦克风获得的声音的测量来确定第一时间延迟。声音测量的目的是确定直接声音(例如,由低通滤波器214生成的第二声部,优选地,还有低层信号206表示的声音)与反射声音(例如,由高通滤波器212生成的第一声部表示的声音)到用户的位置之间的任何延迟的程度。例如,可以通过发送第一测试信号作为反射声音,并且然后测量使用用户附近的麦克风检测到第一测试信号的第一时间间隔来实现这种测量。然后可以发送第二测试信号作为直接声音,并且然后测量用户附近的麦克风检测到第二测试信号的第二时间间隔。可以基于第一时间间隔与第二时间间隔之间的差来确定第一时间延迟。
在图2D中示出的典型实施例包含图2C中示出的实施方式的所有的特征,但进一步包括优先效应延迟模块218和218'。优先效应延迟模块218和218'可以实现为独立的模块,或可替换地,可通过单个模块的方式提供。在图2C和图2D中,相同的数字用于指代两个实施方式所共用的部件。
在图2D中示出的典型实施例中,路径补偿模块216和216'的输出被分别传送至优先效应延迟模块218和218'。优先效应延迟模块218和218'两者均将第二时间延迟(由第二时间间隔表示的)引入至由扬声器单元201和/或207生成第二声部和/或低层信号的时间。换言之,在预定第二时间间隔之后,优先效应延迟模块218和218'控制扬声器单元201和/或207中的一个或多个向前发射扬声器205和/或209以基于第二声部和/或低层信号产生用于发送至用户的声音。对于音频处理系统200具有路径补偿模块216和216'以及优先效应延迟模块218和218'的实施方式,第二时间间隔可以从第一时间间隔结束时开始。对于音频处理系统200具有优先效应延迟模块218和218'但不具有路径补偿模块216和216'的实施方式,第二时间间隔可以开始于扬声器单元201和/或207中的一个或多个向前发射扬声器205和/或209基于第一声部的对应部分产生声音的时间。第二时间间隔的值可以是基于哈斯效应(Haas effect)确定的预置值(例如,优选地,20毫秒)。
引入第二时间延迟的优点是延迟直接声音(例如,由低通滤波器214生成的第二声部,以及优选地还有低层信号206表示的声音)的产生,甚至进一步使得用户在直接声音之前听到反射声音(例如,由高通滤波器212产生的第一声部表示的声音),从而进一步提高反射声音的音响效应(audible effect)。
在典型实施例中,第二时间延迟是预定时间间隔。可替换地,在另一典型实施例中,第二时间延迟可以是由优先效应延迟模块218基于从用户接收的选择输入所采用的多个预定时间间隔中的一个。
本发明的典型实施例是基于向上发射声音设备(例如,扬声器单元201的一个或多个向上发射扬声器203)将声音发送至天花板(声音从天花板反射至收听者或用户)的原理。以这种方式,收听者感知来自向上发射声音设备的声音作为升高的声音(即,来自相对于收听者升高的位置的声音)。在典型实施例中,向上发射声音设备可具有一定的方向性(D(f))。这是指声能的一部分被发送至天花板(声能从该天花板到达收听者)作为升高的声音,并且用户感知的在其他方向上发送的声能的一部分相反作为直接声音。直接声音使反射的声能“模糊”,并且因此,感知升高的声音。另外,在典型实施例中,方向性与频率有关(即,频率越高方向性越高)。利用周密考虑的机械结构,可以获得较低频率(例如,小于1kHz)的特定方向性,其可为用户提供对如这样较低频率的声音的升高的一定感知,但这可能不会与较高频率的升高的感知一样清楚。
随着频率增大或升高,更多的能量被引导至天花板并从天花板反射(Er(f)),并且随着频率减小或降低,更多的能量引导向收听者(Ed(f))。这可由两个交叉的曲线表示。以具有高于直接能量的反射能量的频率(即,Er>Ed),将存在用户对高度的感知。这可重新用公式表示,使得当方向性(D)高于临界方向性(Dcrit)时-即,D>Dcrit-然后用户将会清楚地感知到声音升高(即,来自相对于用户升高的位置)。以具有高于反射的能量的直接的能量的频率,直接声音可掩蔽反射声音并且降低或破坏高度感知。这可重新用公式表示使得当方向性低于临界方向性时-即,D≤Dcrit-那么用户将会几乎感知不到或完全感知不到声音在升高(即,相对于用户没有源于升高的位置)。
在图2E中示出的典型实施例旨在通过引入经受降低的高度感知的频率范围内的优先效应解决这个问题。实施方式考虑到两个关键参数:(i)用户通过从天花板反射的声音明显或清楚地感知升高的声音所需的最小方向性(Dcrit);以及(ii)对应于Dcrit的频率,该频率可称为临界频率(fcrit)。图2E中示出的典型实施例包含图2D中所示出的实施例的全部特征,其中,相同的数字用于指代为两个实施方式所共用的部件。为了以小于fcrit的频率增加对Dcrit的感知进行以下操作。从调整模块208输出的总频带被传送至高通滤波器212和低通滤波器213。高通滤波器212产生由仅具有fcrit或fcrit以上的频率的经调整的高度信号210所表示的声音的第一声部。低通滤波器214产生由仅具有低于fcrit的频率的经调整的高度信号210表示的声音的第二声部。由优先效应延迟模块218(执行与图2D中的模块218相同的功能)处理低通滤波器214的输出。在图2E中,使用信号组合器220将优先效应延迟模块218的输出和高通滤波器212的输出组合在一起,在此之后,组合的信号被传送至扬声器单元201的一个或多个向上发射扬声器203。优先效应延迟模块218'的输出可分别传送至扬声器单元201和/或207中的一个或多个向前发射扬声器205和/或209,用于直接向用户发送声音。在图2E中示出的典型实施例中,优先效应延迟模块218可帮助提高收听者对具有低于fcrit的频率的声音(如来自天花板或者至少增加的高度)的心理声学感知。
图3是由如在图2A、图2B、图2C或图2D中的任一个中描述的音频处理系统200的模块执行的音频处理方法300中的处理步骤的流程图。本领域技术人员将会理解的是,由参照图2A、图2B、图2C或图2D描述的模块中的任何一个或多个提供的任何特征(整体或部分地),以及如参照图3描述的步骤中的任何一个或多个(整体或部分地)可以通过使用硬件(例如,通过一个或多个分立电路、专用集成电路(ASIC)、和/或现场可编程门阵列(FPGA)),或使用软件(例如,由在代码、信号和/或从存储器访问的指令的控制下操作的数字信息处理器模块执行的相关特征)、或使用如上所述的硬件和软件的组合来实现。
音频处理方法300开始于步骤302,其中,音频处理系统200从音频源202接收高度信号204和低层信号206。在步骤304中,调整模块208比较高度信号204和低层信号206的一个或多个音频特性(例如,振幅)。在步骤306中,调整模块208基于在步骤304中执行的比较调整高度信号204的振幅。
步骤308确定是否需要使用高通滤波器212和低通滤波器214进一步处理调整模块208的输出。如果步骤308确定没有这种需要(例如,基于表示用户或系统偏好,或者音频处理系统200中不存在高通滤波器212和低通滤波器214的数据),那么在步骤310中,调整模块208的输出210被传送至扬声器单元201的一个或多个向上发射扬声器203,用于产生通过从用户上方的预定位置反射而向用户引导的声音,并且低层信号206被传送至扬声器单元201和/或207中的一个或多个向前发射扬声器205和/或209,用于产生引导向用户的声音。
如果步骤308确定存在这种需要(例如,基于表示用户或系统偏好,或者在音频处理系统200中存在高通滤波器212和低通滤波器214的数据),则调整模块208的输出被传送至高通滤波器212和低通滤波器214两者。在步骤312中,高通滤波器212基于调整模块208的输出的经调整的高度信号210生成第一信号部分。如上所述,第一信号部分包含具有预定频率阈值的频率或预定频率阈值以上的频率的声音。在步骤314中,低通滤波器214基于调整模块208的输出的经调整的高度信号210生成第二信号部分。如上所述,第二信号部分包含具有预定频率阈值以下的频率的声音。
步骤316确定是否需要通过路径补偿模块216和216'进一步处理高通滤波器212和低通滤波器214的输出。如果步骤316确定没有这种需要(例如,基于表示用户或系统偏好的数据),或者音频处理系统200中不存在路径补偿模块216和216'),那么在步骤318中,由高通滤波器212产生的输出被传送至扬声器单元201的一个或多个向上发射扬声器203,用于产生通过从用户上方的预定位置反射而引导向用户的声音,并且由低通滤波器214产生的输出被传送至扬声器单元201和/或207中的一个或多个向前发射扬声器205和/或209,用于产生引导向用户的声音。
如果步骤316确定存在这种需要(例如,基于表示用户或系统偏好的数据),或者音频处理系统200中存在路径补偿模块216和216',则由低通滤波器214产生的输出被传送至路径补偿模块216,并且从音频源206接收的低层信号206可以被传送至路径补偿216'。在步骤320中,在第一时间间隔之后,路径补偿模块216和216'基于第二信号部分和/或低层信号来控制声音的产生。已参照图2C描述了该步骤所涉及的细节。
步骤322确定是否需要使用优先效应延迟模块218和218'进一步处理调整模块208的输出。如果步骤308确定没有这种需要(例如,基于表示用户或系统偏好,或者音频处理系统200中不存在优先效应延迟模块218和218'的数据),那么在步骤324中,由高通滤波器212产生的输出被传送至扬声器单元201的一个或多个向上发射扬声器203,用于产生通过从用户上方的预定位置反射而引导向用户的声音,并且由路径补偿模块216和216'产生的输出被组合(例如,使用组合器模块220或类似的装置)并被传送至扬声器单元201和/或207中的一个或多个向前发射扬声器205和/或209,用于产生引导向用户的声音。
如果步骤322确定存在这种需要(例如,基于表示用户或系统偏好,或者在音频处理系统200中存在优先效应延迟模块218和218'的数据),则路径补偿模块216和216'的输出被分别传送至优先效应延迟模块218和218'。在步骤326中,在第二时间间隔之后,优先效应延迟模块218和218'基于第二信号部分和/或低层信号控制声音的产生。已参照图2D描述该步骤涉及的细节。例如,在一些实施方式中,第二时间间隔可以在第一时间间隔之后开始。在一些实施方式中,第二时间间隔可以开始于扬声器单元201和/或207中的一个或多个向前发射扬声器205和/或209基于第一声部的相应部分产生声音的时间。
在步骤328中,由高通滤波器212产生的输出被传送至扬声器单元201的一个或多个向上发射扬声器203,用于产生通过从用户上方的预定位置反射而向用户引导的声音,并且将由优先效应延迟模块218和218'产生的输出进行组合(例如,使用组合器模块220或者类似的装置),并传送至扬声器单元201和/或207中的一个或多个向前发射扬声器205和/或209,用于产生向用户引导的声音。
在步骤310、318、324和328之后,音频处理方法300结束。
在本申请中,除非指定并非如此,否则术语“包括(comprising)”、“包含(comprise)”及其语法上的变形旨在表示“开放性的”或“包括在内的”语言,使得它们包括所记载的元件,但也允许包括另外的非明确记载的元件。
虽然已经参考示例性实施方式描述了本发明,但本领域技术人员将理解的是,在不偏离本发明精神和范围的情况下,可以进行各种改变并且可用等同物替代其元件。此外,在不偏离本发明的基本范围的情况下,可以进行修改以使本发明的的教导适用于特殊情况或材料。因此,本发明不限于在本说明书中所公开的特定实例,而是涵盖落入所附权利要求的范围内的所有的实施方式。
- 还没有人留言评论。精彩留言会获得点赞!