一种基于发布订阅机制的多源数据分发方法与流程
本发明涉及计算机分布计算中的数据分发,特别是一种基于发布订阅机制的多源数据分发方法。
背景技术:
发布订阅机制是一种为通讯参与者提供信息交互能力的通信范式。该机制的基本工作是:(1)对系统中各个用户所订阅的主题进行存储管理;(2)将用户发布的主题与之前存储在系统中的订阅主题进行匹配;(3)将发布主题下的消息内容分发给所有匹配的订阅者。由于发布订阅机制与生俱来的松耦合以及高可拓展特性,使发布订阅系统被视为实现大规模高可拓展性网络通讯应用的关键技术。
目前发布订阅系统的成熟产品主要集中在以股票交易系统为代表的消息分发系统领域,该类系统中单次数据分发任务的数据量往往较小。但是随着应用需求的拓展,发布订阅系统在大数据量分发场景下的潜力逐渐被重视,因此提高发布订阅系统在大数据量场景下的消息分发速度成为了亟待解决的问题。其中最主要的挑战在于,若要充分发挥发布订阅系统在大数据量场景下的能力,就必然会要求系统允许多个数据分发任务并行执行,即存在多个主题数据源同时进行数据分发。然而现有的数据分发机制往往只以单数据源应用场景作为研究对象,因此无法有效应对多源场景所引入的负载异构等特殊问题。
技术实现要素:
发明目的:针对现有技术存在的问题和不足,本发明的提供一种基于发布订阅机制的多源数据分发方法,能够支持大数据量以及多源场景的数据分发,并能够从全局考虑,保证分发过程中的负载均衡。
技术方案:为实现上述发明目的,本发明中基于发布订阅机制的多源数据分发方法,包括以下步骤:
构造子关系和子主题:针对任意一个主题,构造相应的数据发布和订阅关系,将该主题的数据发布和订阅关系分拆为若干个子关系,把该主题数据均匀分摊到该若干个子关系上,形成相同数目的子主题数据;
构造数据分发树:针对任意一个主题,建立一棵以该主题的数据发布方为根节点的主题数据分发树,根节点的下一层为各子主题的父节点;所有主题的数据分发树构成一片数据分发森林;
选择父节点,更新主题数据分发树的拓扑结构:针对任意一个节点,通过贪心策略和约束策略独立为各子主题选择父节点;
数据推送:对于任意一个主题,在所建立的分发树上推送相应主题数据报文。
其中,所述贪心策略为:
针对某个主题的某一子主题,建立所有订阅该子主题的节点集合;
针对集合中的某一个节点,从集合中任意选择一个候选父节点,该候选父节点为集合中除了该节点以及该节点当前父节点的任意节点;
获取该节点从该候选父节点接收该子主题数据所带来的系统总带宽增益值;
获取该节点停止从当前父节点接收该子主题数据所带来的系统总带宽损失值;
若系统总带宽增益值大于系统总带宽损失值,则将候选父节点更新为下一步数据推送的父节点。
其中,获取某一节点停止从其当前父节点接收某一子主题数据所带来的系统总带宽损失值包括以下步骤:
获取该当前父节点向该节点发送数据的子主题集合;
获取该当前父节点的当前出度,所述出度是指某一节点与其他节点之间的数据输出链路个数;
若该子主题集合剔除该停止接收的子主题后仍不为空,则系统总带宽损失值为0;否则,若该当前父节点的当前出度大于最大出度值,则系统总带宽损失值为0;否则,系统总带宽损失值为1。
其中,获取某一节点从其候选父节点接收某一子主题数据所带来的系统总带宽增益值包括以下步骤:
获取该候选父节点向该节点发送数据的子主题集合;
获取该候选父节点的当前出度,所述出度是指某一节点与其他节点之间的数据输出链路个数;
若该子主题集合不为空,则系统总带宽增益值为0;否则,若该候选父节点的当前出度大于或等于最大出度值,则系统总带宽增益值为0;否则,系统总带宽增益值为1。
进一步地,对于任意节点,在选择父节点时所述约束策略包括:
1)该节点不能将负载比自身重的节点调整为自身的父节点;
2)只有该节点在没有比其负载更重的兄弟节点时,才可以请求从父节点脱离;
3)如果该节点在两次父节点选择间隔之内未收到任何数据报文,或者该节点的入度小于最大出度值,则该节点可不受约束条件1)和2)的限制,随机选择一个报文接收进度领先于自身的节点作为新父节点,所述入度是指某一节点与其他节点之间的数据输入链路个数;
4)如果该节点的当前父节点的负载比自身重,则不受约束条件1)和2)的限制执行一次节点上移操作,将该节点上移为其当前父节点的兄弟节点;
5)若该节点的出度已达到最大出度值,此时若有某一新节点请求成为该节点的孩子节点,且该新节点订阅的主题个数小于该节点的孩子节点中负载最重的节点所订阅的主题个数,则该节点作为该新节点的候选父节点时,系统总带宽增益值为1;
6)在不违背约束条件1)和2)的前提下,如果当前父节点的出度减候选父节点的出度之差大于1,且计算出的总带宽增益值等于系统总带宽损失值,则将总带宽增益值的值增加1。
其中,在所建立的分发树上推送相应主题数据报文具体为:
对于该分发数上的某一子主题,父节点获取其接收该子主题的最新报文序列号,以及其向该子主题分发树上所有孩子节点发送该子主题数据的报文序列号,所述报文序列号表示数据的接收进度;
只有当父节点的接收进度领先于孩子节点时,该父节点才向孩子节点进行数据推送。
有益效果:本发明中基于发布订阅机制的多源数据分发方法,通过利用多源和节点负载异构的数据分发森林的构造方式对数据分发系统的拓扑结构进行组织,能够在均衡节点负载的同时,提高系统的总带宽利用率,缩短多源数据分发任务的持续时间;本发明方法通过让数据订阅方参与数据分发过程,数据订阅方在接收数据的同时,转发数据,将原来数据发布方的顺序分发转变为数据在不同数据订阅方之间的并行分发,数据分发并行度较高;本发明方法在多源情况下,对多棵单主题的数据分发树进行全局考虑,针对节点异构特征,优化单主题的数据分发树拓扑结构,在均衡节点负载的同时,提高系统的总带宽利用率;在多源数据分发情况下,根据节点负载异构特征,采用贪心策略,尽可能增加节点连接数,提高数据转发效率,减少数据分发的延迟,通过仿真实验表明,本发明方法具有更短的数据分发时间。
附图说明
图1为本发明中基于发布订阅机制的多源数据分发方法的节点结构示意图;
图2为本发明中基于发布订阅机制的多源数据分发方法的生成的具有四树结构的分发森林示意图;
图3为本发明中基于发布订阅机制的多源数据分发方法的数据分发拓扑结构调整示意图;
图4为本发明中基于发布订阅机制的多源数据分发方法与传统数据分发方法的数据分发总时间性能比较图。
具体实施方式
下面结合实施例对本发明作更进一步的说明。
本发明中基于发布订阅机制的多源数据分发方法,采用基于多源和节点负载异构的数据分发森林的构造方式(PSDDF,Publish/Subscribe-based Data Distribution Forrest),多源指在某一时刻,系统内存在多个发布方同时发布不同主题的数据,在任一时刻,一个发布方发布一个主题的数据。
下面首先介绍PSDDF方法采用的系统模型。
PSDDF方法利用无向图对系统建模,图中的点代表系统中的节点,边代表系统中的网络连接。针对一个特定主题A的发布方和订阅方构成一个主题A的发布订阅集合。
PSDDF方法的假设有:
(1)节点同构,图中所有节点具有相同的处理能力及上下载带宽,且节点的上下载带宽值相等。
(2)连接同构,图中每条连接的传输延时相同,具有相同的带宽上限。
(3)节点采用均匀分配的方式向其出边/入边分配上载/下载带宽。
(4)图中不存在平行边,也不存在自环。
(5)节点负载由节点订阅的主题个数量化表示,即每多订阅一个主题,节点的负载等级增加1。
(6)所有节点构成一张完全无向图。
PSDDF首先需要构造针对单源单主题A的数据分发树。通过将原有的发布订阅关系拆分为N个子关系,形成N个子主题。
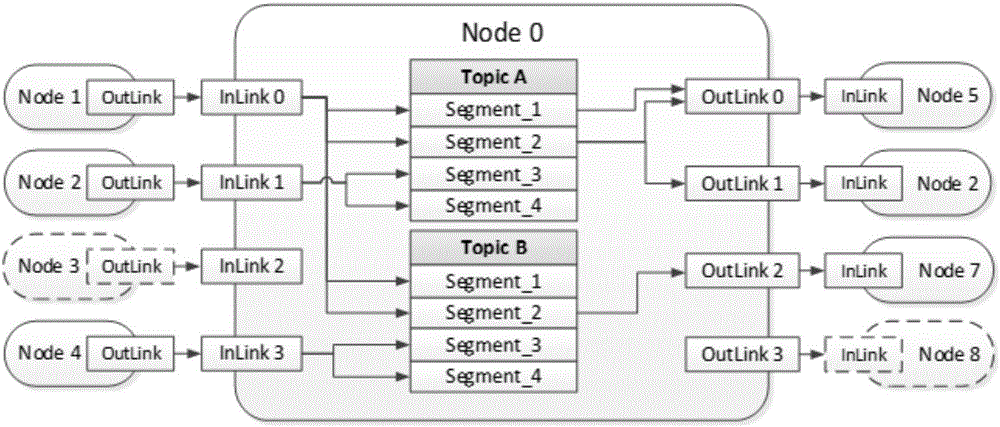
图1所示例子展示了PSDDF节点结构,一个节点具有多个OutLink,每个OutLink是对一条节点出边的抽象,OutLink中记录该出边的信息,包括所有经由该出边进行数据推送的主题名列表以及该边所指向的下游节点对列表中各个主题的数据接收进度。节点的每个InLink是对一条节点入边的抽象。每一对OutLink-InLink表示一条连接两个节点的链路。图中Node 0节点同时订阅A、B两个主题,每个主题都分为N=4个数据块,各个数据块从入边InLink接收数据,并通过出边OutLink向孩子节点推送数据。当前0号节点有3条出边分别指向5号、2号和7号节点,3条入边来自1号、2号和4号节点。
主题数据A(Topic A)被分成了segment_1、segment_2、segment_3和segment_4四个子主题。主题A的全部数据均摊到四个子主题上。可以选用已有的单源分发树构造方法,如雪球算法、SB算法、FT算法等,建立一棵以数据发布方A为根节点的主题数据分发树。
在多源情况下,为每一个数据发布方构造一棵数据分发树,形成一片数据分发森林,如图2所示,构造了一片2源的数据分发森林。图2中有两棵数据分发树,数据发布方分别为A和B。订阅主题A的节点集合是{1,2,3,4},订阅主题B的节点集合是{1,5,6,7},节点1同时订阅了主题A和主题B。每个主题的数据被分成了4个子主题,分别为segment1、segment2、segment3和segment4。为了更好地利用带宽资源,每个订阅节点都会成为某一个子主题的子树的根。在图2主题A中,节点1是segment1子主题的子树的根,节点2、3和4分别为其他子主题的子树的根。针对每一个子主题的子树,都要覆盖该主题的所有订阅节点。
然后根据父节点选择算法对分发树进行拓扑调整。每一个节点中的子主题各自独立调用该算法为本子主题选择父节点。该算法无需再对所有分发树以及一个主题下的四棵分发子树视为整体进行综合调整的原因是父节点选择算法在对单棵分发树/子树的结构调整规则中已经包含了对系统整体拓扑结构的考虑。因此,PSDDF的父节点选择算法能够通过独立优化各棵分发树的方式来优化主题整体乃至包含多个主题的系统整体的拓扑结构。其优化方法是通过增加系统中的连接数量来增大并发度,从而达到提高系统总带宽利用率的目的。PSDDF的父节点选择算法具体可分为贪心策略和约束策略两部分。
(1)贪心策略
假设节点i正在为子主题A_seg1进行数据分发且节点i在A_seg1分发树中的当前父节点为Pold,算法1是PSDDF的父节点选择算法。
算法1PSDDF父节点选择算法的贪心算法
在整个数据分发过程中,节点i上的各个子主题将周期性地执行算法以不断进行父节点调整。算法以所有订阅子主题A_seg1的节点的集合S作为输入参数,该集合可以从发布订阅系统获取。步骤3中的带宽增益是指当节点i选择从Pcandidate接收子主题A_seg1数据时,有可能会新建一条由Pcandidate到节点i的连接,从而使系统总带宽增加一条连接的带宽值。而步骤4中的带宽损失是指如果节点i不再从Pold接收子主题A_seg1的数据,则有可能会断开由Pold到节点i的连接,使系统总带宽减少该连接的带宽值。用带宽增益值BWGain减去带宽损失值BWLoss就能计算出一次父节点调整所造成的系统总带宽变化值。只有当一次调整预计能使系统总带宽增大时,节点才会进行此次调整。
如果算法的执行结果是令节点i将Pcandidate调整为其在子主题A_seg1分发树中的新父节点,则Pold需要将A_seg1这一主题名从其指向节点i的OutLink的主题名列表中删除。如果Pold指向节点i的OutLink中仅有A_seg1一个主题名,则说明经过此次调整已经没有任何子主题通过此条OutLink推送数据了,因此Pold删除此OutLink,Pold的出度值减1。同样地,Pcandidate需要将A_seg1这一主题名添加到从Pcandidate指向节点i的OutLink的主题名列表中。如果Pcandidate原本并无指向节点i的连接,则Pcandidate将添加一个指向节点i的OutLink并将A_seg1记录到此OutLink,Pcandidate的出度值增1。
为了获取BWGain和BWLoss的值,节点i需要向Pcandidate和Pold发送请求报文并等待其回复。Pcandidate和Pold在收到请求后,根据自身当前情况计算出BWGain和BWLoss的值并回复给节点i。子过程1为步骤3的子过程,Pcandidate收到节点i的请求后执行该子过程,并将BWGain返回给节点i。子过程2为步骤4的子过程,Pold收到节点i的请求后执行该子过程,并将BWLoss返回给节点i,子过程1和子过程2中的MAX为最大出度值,可根据系统情况具体设置。图1中,5、2、7号节点将节点0选为任何子主题的Pcandidate都无法提高系统总带宽。如果节点8将节点0选为Pcandidate,有可能使节点0添加出边OutLink3,从而使BWGain=1。
(2)约束策略
约束策略的作用是针对多主题场景下存在节点负载异构的情况,实现两个目标:一是避免轻负载节点出现在重负载节点的子树中,并使重负载节点在分发树的结构调整过程中保持下沉趋势从而逐渐远离根节点。二是均衡节点负载。假设以节点i为对象,则约束策略包括如下6个约束条件:
1)节点i不能将负载比自身重的节点调整为自身的父节点。
2)只有在节点i没有比其负载更重的兄弟节点时,节点i才可以请求从父节点脱离。
3)如果节点i在两次父节点选择算法执行间隔之内未收到任何数据报文,或者节点i的入度小于最大出度值MAX,则节点i可不受约束条件1和2的限制,立即选择一个报文接收进度领先于自身的节点作为新父节点。
4)如果节点i的当前父节点j的负载比自身重,则不受约束条件1和2的限制立即执行一次节点上移操作,将节点i上移为节点j的兄弟节点。
5)假设节点i的出度已达到最大出度值MAX,且节点i的孩子节点中负载最重的节点所订阅的主题个数为k。此时若有节点j请求成为节点i的孩子节点且节点j订阅的主题数小于k,则允许节点i在计算BWGain时忽略子过程1中的步骤3。
6)在不违背约束条件1和2的前提下,如果算法中Pold的出度减Pcandidate的出度之差大于1,且计算出的BWGain等于BWLoss,则将BWGain的值增加1。
对于约束策略的第一个目标,除了用约束条件1来设置明确的禁止行为之外,还使节点能够依据自身负载轻重程度在分发树中“上浮”或“下沉”。本发明以MAX=4为例进行详细说明,如图3所示,假设除2号节点是重负载节点外,其余节点都是轻负载节点。图3(a)是分发树的初始状态,此时10号节点想要将1号节点调整为自身的新父节点,由于10号节点的负载比2号节点轻,因此触发约束条件5,1号节点作为Pcandidate会忽略自身出度已经为4这一情况,而将此次调整的BWGain计算为1。因为4号节点的出度为5,10号节点从4号节点脱离所造成的BWLoss为0,有BWGain>BWLoss,分发树调整为图3(b)所示结构。节点10的上浮使节点1的出度变为5,这使得1号节点的孩子节点从1号节点脱离所造成的带宽损失值BWLoss降低为0,因此图3(b)中2、3、4、5、10号节点一旦在找到能使BWGain值等于1的位置就会从1号节点下脱离。根据约束条件2,下一个脱离的节点是2号节点,因为它的负载最大。在图3(b)中,节点2选择将3号节点作为新父节点,因此分发树的结构调整为图3(c)。节点2下沉之后,节点1的出度重新变为4,此时节点1的孩子节点从节点1脱离造成的损失值BWLoss恢复为1,不再会有孩子节点从节点1脱离。
对于均衡负载这一目标,前五条约束条件用于将重负载节点的发送负载转移给轻负载节点,最后一条约束条件则用于避免发送负载过于集中在某一轻负载节点上,即避免热点问题。
确定了分发森林的拓扑结构后,主题数据采用数据推送算法将数据推送到所有主题订阅方。
算法2PSDDF数据推送算法
以图1的Node0为例,算法的输入参数S为OutLink所指向的2、5、7号节点。节点i仅需要向订阅主题A_seg1,而不是所有出边发送主题A_seg1的数据,节点的OutLink记录经由该出边传输的子主题,此时Node0的OutLink0记录经由此出边进行数据推送的子主题有:A_seg1与A_seg2。
为实现推送式数据分发,令节点i在指向节点k的OutLink中保存有节点k关于主题A_seg1的数据接收进度Seqk,每向节点k发送一包A_seg1的数据报文,节点i都会将此Seqk加1。
步骤1需要获取节点i自身的数据接收进度。只有当父节点的接收进度领先于孩子节点时父节点才有内容向孩子节点进行数据推送。对于订阅节点,其数据接收进度通过步骤7从0开始逐步累积。
至此,在多源情况下,各主题数据通过分发森林有效快速地完成数据推送。
图4给出了本方法的数据分发总时间的实验分析。实验包含2个主题发布节点,分别发布主题A和主题B。主题订阅节点共有7个,其中3个仅订阅主题A,另外3个节点仅订阅主题B,最后1个节点同时订阅主题A和B。实验的分发数据量都为1000包,每包大小为1M字节。对比算法为CS算法和FT算法。CS算法是一种基于网格结构的算法,其父节点选择算法按照Coolstreaming实现。FT算法采用静态四树结构进行数据分发。从图4中可以看到,CS算法的数据分发总时间为1000秒,FT算法需要570秒,本方法需要500秒,明显缩短了数据分发总时间。
以上详细描述了本发明的优选实施方式,但是,本发明并不限于上述实施方式中的具体细节,在本发明的技术构思范围内,可以对本发明的技术方案进行多种等同变换,这些等同变换均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!