一种结合节点信息和网络结构的社区发现方法与流程
本发明涉及一种结合节点信息和网络结构的社区发现方法,属于网络分析与挖掘领域。
背景技术:
针对网络的分析已成为最重要的交叉型研究领域之一,当前网络研究中的一个热点围绕社区结构展开。社区这一概念的原始定义是有相同特点或者兴趣爱好的一类人组成的团体。当开始将网络结构作为反映真实世界复杂系统的模型,社区的概念已经不仅仅局限于人类关系,逐步扩展到了各种各样的网络中。社区发现的任务就是识别检测出网络中由节点组成的一系列群体,这些群体内部节点之间联系紧密,而群体之间的节点连接则相对稀疏,而这些群体我们称之为社区。
网络分为无权网络和有权网络两种。无权网络中节点和节点之间的关系有“无关系”和“有关系”两种状态,而有权网络的权值则代表了节点之间相互作用的强度,网络蕴含的信息也更加丰富。现实社会中存在许多无权网络和有权网络的实例,相应地也诞生了许多处理无权网络和有权网络的社区发现算法。
对网络结构进行社区发现具有重要的意义,它不仅能直观地表现出不同种类的网络中模块化的分组结构,还可以帮助人们认识网络所代表的社会现象和系统、理解网络的功能和作用、发现网络中隐藏的信息和规律、预测网络的行为和变化以及指导人们解决网络所代表的现实问题等。
目前,社区发现主要分为两大类。一类方法是基于节点信息,通过计算节点之间的相似度,利用聚类算法完成社区划分。另一类方法是基于网络结构,通过网络节点之间的连接关系,利用社区发现算法完成社区划分。虽然针对这两种情况已经诞生了许多社区发现算法,但是这两种方法均具有局限性,它们往往只注重一方面的节点信息而忽略另一方面的重要性。第一类方法得到的社区成员之间一般会具有相似的特征信息然而相互之间连接不紧密,而第二类方法得到的社区成员之间关系连接紧密,却不具有较多的共同特征。这正是因为这两种方法不能合理地、完全地结合并利用网络节点的有效信息,所以根据这两种方法得到的社区发现结果并不理想。
技术实现要素:
针对现有技术的不足,本发明提供了一种结合节点信息和网络结构的社区发现方法;
术语解释
无向网络、有向网络:所谓网络,是由一些基本的单元和它们之间的连接所组成。根据这些连接边是否有确定的方向,我们可以将网络分为有向网络和无向网络两类。
网络结构,由节点与节点之间的连接边组成。在网络结构中,节点一般代表用户,而边则代表用户之间的相互关系。除此之外,一般情况下每个用户都会有用来描述用户属性的信息,这些信息由许多特征组成。我们一般用这些特征组成的向量来描述用户的属性,称为特征向量。每个用户都对应一个特征向量,根据不同用户的不同特征设置特征向量的值。假设学生小明是一个节点,小明具有籍贯、年龄、性别、成绩等特征。我们用0、1来表示这些特征。例如根据籍贯是否为山东、年龄是否在18-23之间、性别是否为男、考试成绩是否及格这些特征,用0表示否,1表示是。那么,小明的特征向量可以表示为(1,1,0,1)。
本发明的技术方案为:
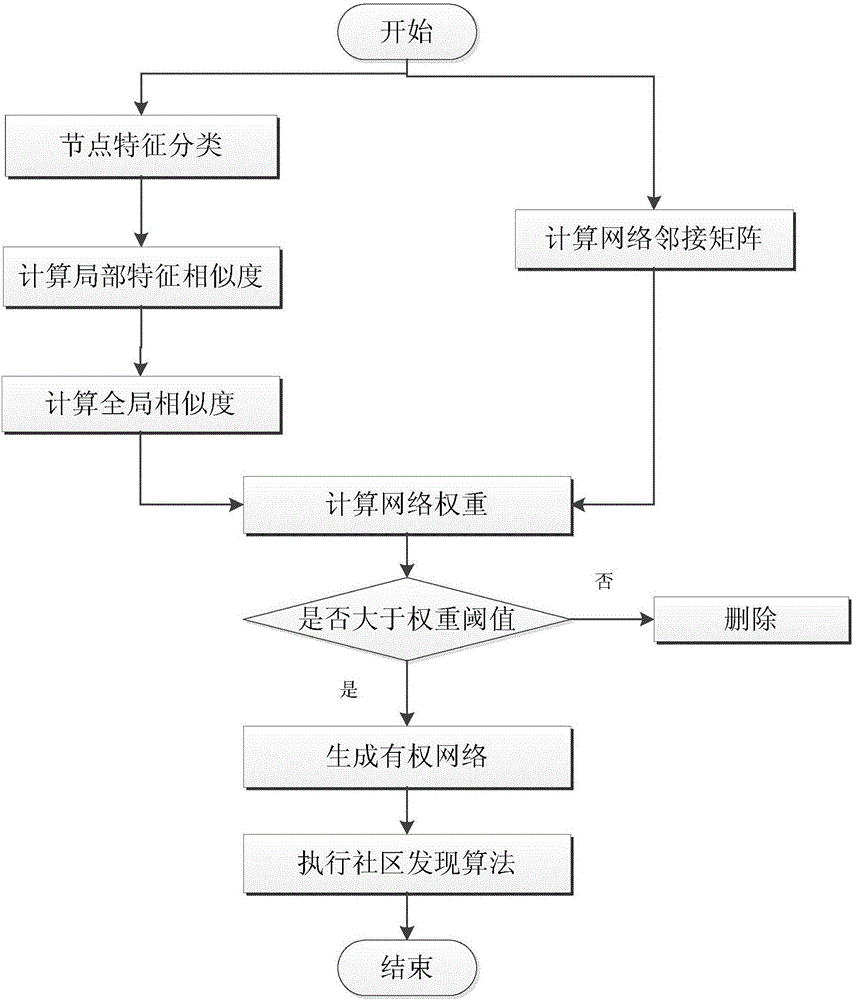
一种结合节点信息和网络结构的社区发现方法,具体步骤包括:
(1)根据节点特征对社区划分的影响程度,对节点特征进行分类;
(2)根据节点特征对节点进行内容相似度计算;
(3)根据网络结构,得到网络的邻接矩阵A;
(4)设定阈值,更新网络权重,生成有权网络;
(5)根据实际需要设置参数,选择社区发现算法,对步骤(4)得到的有权网络进行处理,得到最终社区划分。
根据本发明优选的,所述步骤(1),具体包括:
a、根据节点特征对社区划分的影响程度,人为地为节点特征分类;设定将某一节点特征分为n类特征;
b、对社区划分的影响程度比较大的节点的某类特征,为该类特征赋予较大的权值,对社区划分影响程度比较小的节点的某类特征,则为该类特征赋予较小权值;
n类特征的权值依次设为n1,n2,...,nn,n1+n2+...+nn=1。
步骤(1)举例说明如下:某在校大学生为节点,每个学生有性别、参加的社团、课程等节点特征,若想要社区划分结果倾向于将爱好相同的学生分在一起,则将参加的社团这一节点特征赋予60%的权重,课程这一节点特征赋予30%的权重,性别这一节点特征赋予10%的权重;若划分结果倾向于将同一班级的学生划分在一起,则可以将课程这一节点特征赋予70%的权重,参加的社团这一节点特征赋予25%的权重,性别这一节点特征赋予5%的权重。
根据本发明优选的,所述步骤(2),具体包括:
c、采用余弦相似度计算方法,分别计算节点的每一类特征的局部相似度,计算公式如式(Ⅰ)所示:
式(Ⅰ)中,Sij指网络中节点i和节点j的相似度,分别是指节点i、节点j的节点特征组成的特征向量;
d、对节点的每一类特征的局部相似度加权求和,求出全局相似度,节点i、j的全局相似度计算公式如式(Ⅱ)所示:
Simij=n1Sim1+n2Sim2+...+nnSimn (Ⅱ)
式(Ⅱ)中,Sim1,Sim2,...,Simn分别代表n类节点特征的局部相似度;Simij是指节点i和节点j的总相似度,即全局相似度。
根据本发明优选的,所述步骤(3),具体步骤包括:
对于无向网络,若网络中的任意两个节点i,j之间有连接,则设置Aij=Aji=1,若无连接,则设置Aij=0,通过这种方式,得到网络连接的邻接矩阵A,Aij、Aji分别是指矩阵A中第i行j列的元素和第j行i列的元素。
根据本发明优选的,所述步骤(4),具体步骤包括:
e、对于无向网络,网络中的任意两个节点i,j之间连接边的权重Qij设置公式如式(Ⅲ)所示:
Qij=kAij+(1-k)Simij (Ⅲ)
根据式(Ⅲ),得到网络中所有节点两两之间的权重;
k为常数,取值为(0,1)。通过设置不同的k值,调节节点特征和网络结构对社区划分影响的贡献度,k值越大则网络结构在社区划分中起主导作用越明显,k值越小则节点特征在社区划分中起主导作用越明显,在实际使用时,根据实际情况的具体需要,设定k值的大小。
f、根据权重Qij的取值范围,设置阈值q,设置公式如式(Ⅳ)所示:
q=Qijmin+p*(Qijmax-Qijmin) (Ⅳ)
式(Ⅳ)中,p为百分数,p的取值为(0,1),Qijmax、Qijmin分别指Qij取值的最大值和最小值;
举例说明如下:q=Qijmin+15%*(Qijmax-Qijmin)代表将权重大于Qijmin+15%*(Qijmax-Qijmin)的边保留,将权重低于总体水平的后15%部分边删除,从而达到简化网络结构的效果。
设置阈值q的意义是因为在Qij的值非常小的情况下在i,j之间建立连接边不仅对提高社区发现精度没有积极作用,而且还会增大网络的复杂度,增加社区发现过程的处理时间,所以此处设定阈值,将较小的权值排除,去除噪声的干扰。
g、生成有权网络,具体如下:
若Qij>q,则在节点i,j之间建立一条连接边,并给这条边赋予权重Qij,若Qij<q,则舍弃权重权重Qij,且节点i,j之间不建立连接边,根据此规则,对原始网络进行重建,生成有权网络。
至此,就将原来的无权网络变为有权网络,并且该有权网络包含了节点特征和网络结构两方面的信息。
根据本发明优选的,所述步骤(5),具体步骤包括:选择社区发现算法,对该有权网络进行处理,得到最终社区划分。
首先,衡量实际操作中是网络结构还是节点信息主导,通过选择参数k与q平衡其关系,然后,选择社区发现算法对该有权网络进行处理,得到最终社区划分。
根据本发明优选的,所述社区发现算法包括目前比较成熟的派系过滤算法、标签传播算法、GN算法等社区发现常用算法。
若实际操作中对时间要求比较严格,可以选择时间复杂度相对低的算法如标签传播算法,若对时间复杂度要求不高却对精度要求相对较高,那么可以选择GN算法等。有的需要发现重叠社区,有的需要发现非重叠社区。根据不同场景,灵活选择合适的社区发现算法,完成社区发现过程。
本发明的有益效果为:
1、本发明在社区发现过程中结合了节点特征和网络结构,通过对节点特征分类加权的方式,有效利用了节点信息,并通过设置参数k,调节节点信息和网络结构这两部分在社区发现中的贡献度。
2、本发明通过矩阵加和的形式,把节点特征与网络结构融合为权重的形式,将无权无向网络转变为有权无向网络,除此之外又通过设定阈值的方式,减小了不必要的计算开销,节省了社区发现过程的时间。
3、不针对特定场景,适合处理现实生活中存在的大部分网络,并且可以根据实际需要(时间需要或精度需要等)选择适合的社区发现算法,具有普适性和灵活性。
附图说明
图1为本发明所述方法的流程示意图。
具体实施方式
下面结合说明书附图和实施例对本发明作进一步限定,但不限于此。
实施例
网络结构是由节点与节点之间的连接边组成。在网络结构中,节点一般代表用户,而边则代表用户之间的相互关系。除此之外,一般情况下每个用户都会有用来描述用户属性的信息,这些信息由许多特征组成。我们一般用这些特征组成的向量来描述用户的属性,称为特征向量。每个用户都对应一个特征向量,根据不同用户的不同特征设置特征向量的值。
本实施例中,假设学生小明是一个节点,小明具有籍贯、年龄、性别、成绩等节点特征。我们用0、1来表示这些节点特征。根据籍贯是否为山东、年龄是否在18-23之间、性别是否为男、考试成绩是否及格这些节点特征,用0表示否,1表示是。那么,小明的特征向量可以表示为(1,1,0,1)。
一种结合节点信息和网络结构的社区发现方法,该方法的流程图如图1所示,具体步骤包括:
(1)根据节点特征对社区划分的影响程度,对节点特征进行分类;
a、根据节点特征对社区划分的影响程度,人为地为节点特征分类;设定将某一节点特征分为n类特征;
b、对社区划分的影响程度比较大的节点的某类特征,为该类特征赋予较大的权值,对社区划分影响程度比较小的节点的某类特征,则为该类特征赋予较小权值;
n类特征的权值依次设为n1,n2,...,nn,n1+n2+...+nn=1。
将小明所在的大学作为数据集,其学生为节点,那么,如果倾向于将来自山东本地的本科生分为一类,那么调高第一项和第二项节点特征的比重,将其设为40%籍贯、40%年龄,10%性别、10%成绩,则对应的权重取值分类有两类n1=80%,n2=20%。如果倾向于将能够顺利毕业的本科生分为一类,那么适当调高第二项和第四项特征的比重,将其设为10%籍贯、40%年龄,10%性别、40%成绩,则对应的权重取值分为两类n1=80%,n2=20%。
(2)根据节点特征对节点进行内容相似度计算;
c、采用余弦相似度计算方法,分别计算节点的每一类特征的局部相似度,计算公式如式(Ⅰ)所示:
式(Ⅰ)中,Sij指网络中节点i和节点j的相似度,分别是指节点i、节点j的节点特征组成的特征向量;
d、对节点的每一类特征的局部相似度加权求和,求出全局相似度,节点i、j的全局相似度计算公式如式(Ⅱ)所示:
Simij=n1Sim1+n2Sim2+...+nnSimn (Ⅱ)
式(Ⅱ)中,Sim1,Sim2,...,Simn分别代表n类节点特征的局部相似度;Simij是指节点i和节点j的总相似度,即全局相似度。
对应步骤(1)中n1=80%,n2=20%,得出Simij=80%*Sim1+20%*Sim2;
(3)根据网络结构,得到网络的邻接矩阵A和权重矩阵Q;
e、对于无向网络,若网络中的任意两个节点i,j之间有连接,则设置Aij=Aji=1,若无连接,则设置Aij=0,通过这种方式,得到网络连接的邻接矩阵A,其中Aij、Aji分别是指矩阵A中第i行j列的元素和第j行i列的元素。
对于无向网络,网络中的任意两个节点i,j之间连接边的权重Qij设置公式如式(Ⅲ)所示:
Qij=kAij+(1-k)Simij (Ⅲ)
根据式(Ⅲ),得到网络中所有节点两两之间的权重;
(4)设定阈值,更新网络权重,生成有权网络;
f、根据权重Qij的取值范围,设置阈值q,设置公式如式(Ⅳ)所示:
q=Qijmin+p*(Qijmax-Qijmin) (Ⅳ)
式(Ⅳ)中,p为百分数,p的取值为(0,1),Qijmax、Qijmin分别指Qij取值的最大值和最小值;
g、生成有权网络,具体如下:
若Qij>q,则在节点i,j之间建立一条连接边,并给这条边赋予权重Qij,若Qij<q,则舍弃权重权重Qij,且节点i,j之间不建立连接边,根据此规则,对原始网络进行重建,生成有权网络。
(5)根据实际需要设置参数,选择社区发现算法,对步骤(4)得到的有权网络进行处理,得到最终社区划分。
具体步骤包括:选择社区发现算法,对该有权网络进行处理,得到最终社区划分。所述社区发现算法包括目前较为成熟的派系过滤算法、标签传播算法、GN算法等社区发现常用算法。
若实际操作中对时间要求比较严格,可以选择时间复杂度相对低的算法如标签传播算法,若对时间复杂度要求不高却对精度要求相对较高,那么可以选择GN算法等。有的需要发现重叠社区,有的需要发现非重叠社区。根据不同场景,灵活选择合适的社区发现算法,完成社区发现过程。
- 还没有人留言评论。精彩留言会获得点赞!