一种基于Storm的实时海量云应用访问统计实现方法与流程
本发明涉及计算机软件应用技术领域,具体涉及一种基于Storm的实时海量云应用访问统计实现方法。
背景技术:
在当下云计算时代,大量的应用部署在云端。一个优秀的云计算平台能够确保部署其上的应用稳定、高效的运行。那么,应用的弹性扩展是对此保证的一个有力保证。而通过应用短时间内的访问量的统计分析是进行弹性扩展很有效的一个手段。
Storm是由专业数据分析公司 BackType 开发的一个分布式实时数据处理软件,是一个分布式的、容错的实时计算系统。它具有编程模型简单、高容错性,扩展简易方便,快速实时等特点。考虑到云应用访问量的庞大以及弹性扩展实时性的要求,选用Storm来进行云应用访问量的统计。
技术实现要素:
本发明要解决的技术问题是:本发明针对以上问题,提供一种基于Storm的实时海量云应用访问统计实现方法。
本发明所采用的技术方案为:
一种基于Storm的实时海量云应用访问统计实现方法,所述方法通过配置storm数据源;利用storm对半分钟内云应用访问量进行累加,并将半分钟内的访问数据写入数据库,作为云应用弹性扩展依据或统计使用。
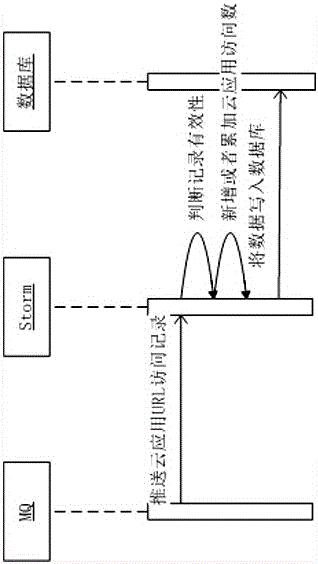
所述方法实现涉及的系统包括MQ消息队列,Storm统计计算,数据库存储三部分,其中:
MQ负责获取云应用URL访问记录,推送到Storm;
Storm接受MQ推送云应用URL访问数据,开始进行处理;
Storm根据数据库配置将数据写进数据库存储中。
消息队列(MQ)是一种应用程序对应用程序的通信方法。应用程序通过写和检索出入列队的针对应用程序的数据(消息)来通信,而无需专用连接来链接它们。消息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用通常是用于诸如远程过程调用的技术。排队指的是应用程序通过队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求。
所述方法实现步骤如下:
1)MQ获取云应用URL访问记录,推送到Storm;
2)Storm接受MQ推送云应用URL访问数据,开始进行处理;
3)Storm判断该URL是否是脏数据,如果是,跳转5),如果不是,进行如下处理;
4)Storm从统计列表里面获取当前URL对应云应用的访问数,如果存在,将其自增,写回统计列表;如果不存在,则在统计列表新增该云应用访问信息;
5)Storm判断当前时间与上次数据写入时间是否超过半分钟,如果不是,则跳转2;如果是,则进行如下操作;
6)Storm根据数据库配置将数据写进数据库表中。
本发明的有益效果为:
本发明实现环境易搭建,依托Storm实时计算平台对海量数据的实时处理能力能够及时将大量的云应用访问量进行统计、处理与保存,对应用弹性扩展以及应用的统计提供了强有力的保障,具有很好的推广使用价值。解决了云应用访问的实时统计的问题;解决了海量云应用访问统计的问题;为应用弹性扩展提供依据;为应用统计提供数据。
附图说明
图1为基于Storm的实时海量云应用访问统计的方法的时序图。
具体实施方式
下面根据说明书附图,结合具体实施方式对本发明进一步说明:
实施例1:
一种基于Storm的实时海量云应用访问统计实现方法,所述方法通过配置storm数据源;利用storm对半分钟内云应用访问量进行累加,并将半分钟内的访问数据写入数据库,作为云应用弹性扩展依据或统计使用。
实施例2
如图1所示,在实施例1的基础上,本实施例所述方法实现涉及的系统包括MQ消息队列,Storm统计计算,数据库存储三部分,其中:
MQ负责获取云应用URL访问记录,推送到Storm;
Storm接受MQ推送云应用URL访问数据,开始进行处理、过滤、统计,;
Storm根据数据库配置将半分钟内统计结果的数据写进数据库存储中。
实施例3
在实施例2的基础上,本实施例所述方法实现步骤如下:
1)MQ获取云应用URL访问记录,推送到Storm;
2)Storm接受MQ推送云应用URL访问数据,开始进行处理;
3)Storm判断该URL是否是脏数据,如果是,跳转5),如果不是,进行如下处理;
4)Storm从统计列表里面获取当前URL对应云应用的访问数,如果存在,将其自增,写回统计列表;如果不存在,则在统计列表新增该云应用访问信息;
5)Storm判断当前时间与上次数据写入时间是否超过半分钟,如果不是,则跳转2;如果是,则进行如下操作;
6)Storm根据数据库配置将数据写进数据库表中。
实施方式仅用于说明本发明,而并非对本发明的限制,有关技术领域的普通技术人员,在不脱离本发明的精神和范围的情况下,还可以做出各种变化和变型,因此所有等同的技术方案也属于本发明的范畴,本发明的专利保护范围应由权利要求限定。
- 还没有人留言评论。精彩留言会获得点赞!