一种信息处理的方法、装置和移动终端与流程
本发明涉及语音识别技术领域,更具体地涉及一种信息处理的方法、装置和移动终端。
背景技术:
随着通讯技术的迅猛发展,移动终端成为日常生活必不可少的一项设备,同时,移动通信终端的发展也日渐成熟,可实现各种应用操作,用户遇到危险时可通过移动通信终端发送求救信息就是一种。
在现有技术中,用户使用移动通信终端求救需要接触到移动终端才能发出报警信息或者呼出电话,并且对现场的录制也要手动操作,不能在紧急情况或者特定场合下自动发出求救信息,用户意图接触移动终端进行自救的动作将会被危险分子识破并被阻止。比较常见的是,儿童离开家长视线、与陌生人约会、女性走夜路或者夜晚打车等各种原因都会造成人口失踪问题,又如,为避免夜晚打车的危险,女性打车时尽量打出租车,但是也无法避免遇上不良车主。此外,当当事人出行过程中发生危险时,往往不能及时向家人或者朋友发求救信号,甚至无法报警,即使有机会发出求救信号,也有可能因处于陌生地点,而无法及时告知其所在地,影响及时救援。
技术实现要素:
鉴于上述问题,本发明提出了一种克服上述问题或者至少部分地解决上述问题的一种信息处理的方法、装置和移动终端,提高用户在遇到突发事件的安全系数,且不容易被犯罪人员发现。
为解决上述技术问题,本发明实施例公开了如下技术方案:
第一方面,本发明实施例中提供了一种信息处理的方法,包括:
在语音监听模式开启下,接收语音数据;
获取所述语音数据内容信息中的语音特征;
将所述语音特征与预定义语音数据模型进行匹配,其中,所述预定义语音数据模型根据用户预先录入的语音数据生成;
若匹配向预定的联系人发送指定信息。
结合第一方面,本发明在第一方面的第一种实现方式中,所述语音特征包括语音的音高、音强、音长、音色。
结合第一方面,本发明在第一方面的第二种实现方式中,所述接收语音数据之后,还包括,
将所述语音数据拆分为单个元素和预定义语音数据模型的单个元素进行识别,如果识别误差不小于预设值,则丢弃所述语音数据;
所述识别误差值预设值为35%。
结合第一方面,本发明在第一方面的第三种实现方式中,所述预定义语音数据模型根据用户预先录入的语音数据生成,包括,
预先录入用户语音生成第一语音数据;
根据所述的第一语音数据内容信息提取语音特征;
将所述第一语音数据内容信息的语音特征转换为数字信息,并拆分成多个组成元素;
将所述多个组成元素重组为第二语音数据;
将第一语音数据和第二语音数据形成预定义语音数据模型。
结合第一方面的第二种实现方式,本发明在第一方面的第四种实现方式中,所述预定义语音数据模型根据用户预先录入的语音数据生成,包括,
预先录入用户语音生成第一语音数据;
根据所述的第一语音数据内容信息提取语音特征;
将所述第一语音数据内容信息的语音特征转换为数字信息,并拆分成多个组成元素;
将所述多个组成元素重组为第二语音数据;
将第一语音数据和第二语音数据形成预定义语音数据模型。
结合第一方面,本发明在第一方面的第五种实现方式中,所述将所述语音特征与预定义语音数据模型进行匹配,包括,
判断所述语音特征与预定义语音数据模型匹配的模糊度是否大于预设值,若大于则确认匹配;
所述模糊度设置值为65%。
结合第一方面,本发明在第一方面的第六种实现方式中,所述将所述语音与预定义语音数据模型进行匹配,包括,
根据所述接收到的语音数据的内容信息提取语音特征;
判断所述语音特征与根据预定义语音数据模型匹配的模糊度是否大于预设值,若不大于则确认不匹配;
若确认不匹配则丢弃所述语音数据。
结合第一方面,本发明在第一方面的第七种实现方式中,所述若匹配则向预定的联系人发送指定信息,包括,
若匹配则触发并唤醒预设应用程序向预定的联系人发送指定信息;
所述触发并唤醒为将触发指令通过intent方式传给预设应用程序,同时唤醒预设应用程序。
结合第一方面,本发明在第一方面的第八种实现方式中,所述若匹配向预定的联系人发送指定信息,还包括,
录入环境音;
调用GPS定位当前位置;
将GPS定位信息和环境录音添加到指定信息中;
触发并唤醒预设应用程序将所述指定信息发送至预定的联系人。
结合第一方面的第七种实现方式,本发明在第一方面的第九种实现方式中,所述若匹配向预定的联系人发送指定信息,还包括,
录入环境音;
调用GPS定位当前位置;
将GPS定位信息和环境录音添加到指定信息中;
触发并唤醒预设应用程序。
第二方面,本发明提供了一种信息处理的装置,包括,
监听模块,用于监听语音获取语音数据;
接收模块,用于接收所述的语音数据;
获取模块,用于获取所述语音数据内容信息中的语音特征;
匹配模块,用于将所述语音特征与预定义语音数据模型进行匹配,其中,所述预定义语音数据模型根据用户预先录入的语音数据生成;
设置模块,用于预先设置至少一个以上的联系人接收指定信息;处理模块,用于确定匹配时,向预定的联系人发送指定信息。
结合第二方面,本发明在第二方面的第一种实现方式中,所述语音特征包括语音的音高、音强、音长、音色。
结合第二方面,本发明在第二方面的第二种实现方式中,所述接收语音数据之后,还包括,
将所述语音数据拆分为单个元素和预定义语音数据模型的单个元素进行识别,如果识别误差不小于预设值,则丢弃所述语音数据;
所述识别误差值预设值为35%。
结合第二方面,本发明在第二方面的第三种实现方式中,还包括存储模块,所述存储模块用于存储预定义语音数据模型,所述预定义语音数据模型根据用户预先录入的语音数据生成,包括,
预先录入用户语音生成第一语音数据;
根据所述的第一语音数据的内容信息提取语音特征;
将所述第一语音数据内容信息的语音特征转换为数字信息,并拆分成多个组成元素;
将所述多个组成元素重组为第二语音数据;
将第一语音数据和第二语音数据形成预定义语音数据模型。
结合第二方面第二种实现方式,本发明在第二方面的第四种实现方式中,还包括存储模块,所述存储模块用于存储预定义语音数据模型,所述预定义语音数据模型根据用户预先录入的语音数据生成,包括,
预先录入用户语音生成第一语音数据;
根据所述的第一语音数据的内容信息提取语音特征;
将所述第一语音数据内容信息的语音特征转换为数字信息,并拆分成多个组成元素;
将所述多个组成元素重组为第二语音数据;
将第一语音数据和第二语音数据形成预定义语音数据模型。
结合第二方面,本发明在第二方面的第五种实现方式中,
所述匹配模块将所述语音特征与预定义语音数据模型进行匹配,包括,
判断所述语音特征与预定义语音数据模型匹配的模糊度是否大于预设值,若大于则确认匹配;
所述模糊度预设值为65%。
结合第二方面,本发明在第二方面的第六种实现方式中,所述匹配模块将所述语音特征与预定义语音数据模型进行匹配,包括,
判断所述语音特征与根据预定义语音数据模型匹配的模糊度是否大于预设值,若不大于则确认不匹配;
若确认不匹配则丢弃所述语音数据。
结合第二方面,本发明在第二方面的第七种实现方式中,所述处理模块若匹配则向预定的联系人发送指定信息,包括,
若匹配则触发并唤醒预设应用程序向预定的联系人发送指定信息;
所述触发并唤醒为将触发指令通过intent方式传给预设应用程序,同时唤醒预设应用程序。
结合第二方面,本发明在第二方面的第八种实现方式中,还包括,
录音模块,用于实时录入环境音;
调用模块,用于调用GPS定位当前位置;
信息模块,将环境录音和GPS定位信息添加到指定信息中;
触发模块,触发并唤醒预设应用程序将所述指定信息发送至预定的联系人。
结合第二方面的第七种实现方式,本发明在第二方面的第九种实现方式中,还包括,
录音模块,用于实时录入环境音;
调用模块,用于调用GPS定位当前位置;
信息模块,将环境录音和GPS定位信息添加到指定信息中;
触发模块,触发并唤醒预设应用程序将所述指定信息发送至预定的联系人。
第三方面,本发明提供了一种移动终端,包括,
预设功能按键、处理器、存储器和传声器;
所述功能按键用于在锁屏状态下供用户触发生成操作指令;
所述传声器用于接收控制指令,开启或结束录音;
所述存储器用于存储支持锁屏状态下的录音装置执行第一方面中任意一项所述的信息处理方法的程序;
所述处理器被配置为用于执行所述存储器中存储的程序。
相对于现有技术,使用本发明提供的技术方案至少具有以下优点:
当遇到突发事件时,用户就可以在不接触到手机的情况下,进行紧急求救,向预先设定的联系人发出指定信息,其预先设定的联系人收到信息即可快速采取必要救援行动,从而简化求救操作步骤,缩短用户被救的时间,提高用户在遇到突发事件的安全系数,且不容易被犯罪人员发现。
本发明的这些方面或其他方面在以下实施例的描述中会更加简明易懂。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见的,下面描述中的附图仅仅是本发明的一些实施例,对于本领域技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1示出了本发明一种信息处理的方法的流程图。
图2示出了本发明一个实施例中信息处理的方法的语音模型HMM基本结构。
图3示出了本发明一个实施例中信息处理的方法的Sphinx连续语音识别系统流程图。
图4示出了本发明一种信息处理的装置的结构图。
图5示出了本发明一种移动终端的结构框图。
具体实施方式
为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
在本发明的说明书和权利要求书及上述附图中的描述的一些流程中,包含了按照特定顺序出现的多个操作,但是应该清楚了解,这些操作可以不按照其在本文中出现的顺序来执行或并行执行,操作的序号如101、102等,仅仅是用于区分开各个不同的操作,序号本身不代表任何的执行顺序。另外,这些流程可以包括更多或更少的操作,并且这些操作可以按顺序执行或并行执行。需要说明的是,本文中的“第一”、“第二”等描述,是用于区分不同的消息、设备、模块等,不代表先后顺序,也不限定“第一”和“第二”是不同的类型。
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例一
为了说明本发明一种信息处理的方法、装置和移动终端的方法实现过程,请参阅图1,该方法包括如下步骤:
S101:在语音监听模式开启下,接收语音数据;
当用户开启移动终端时,即开始实时监听周围的语音数据;
一旦监听到语音数据即接收所述语音数据;
优选的,将所述语音数据拆分为单个元素和预定义语音数据模型的单个元素进行识别,如果识别误差不小于预设值,则丢弃所述语音数据;
所述识别误差值预设值为35%。
S102:获取所述语音数据内容信息中的语音特征;
所述语音特征包括语音的音高、音强、音长、音色。
S103:将所述语音特征与预定义语音数据模型进行匹配,其中,所述预定义语音数据模型根据用户预先录入的语音数据生成。
优选的,构建至少一个预定义语音数据模型,例如,可以选择导入厂商预先设置的语音数据模型,例如“SOS”、“救命啊”、“help”等其他各国“救命”的语言和/或方言;
用户也可以根据自身的需求自行设置语音数据模型,具体包括:
预先录入用户语音生成第一语音数据,用户可在正常情况下录入语音,例如:录入不容易被歹徒识破的求救语言“几点了,我妈喊我回家吃饭”等等,如果提示录入不成功或需多录入几次,即可重复录入该求救语言;
根据所述的第一语音数据的内容信息提取语音特征;
将所述第一语音数据内容信息的语音特征转换为数字信息,并拆分成多个的组成元素;
将所述的多个组成元素重组成第二语音数据;
将第一语音数据和第二语音数据形成预定义语音数据模型。
具体以HTM(HMM Tools Kit)和CMUsphinx举例说明。
HTM(HMM Tools Kit)是由英国剑桥大学工程系的语音视觉和机器人技术工作组(Speech Vision and Robotics Group)开发,专门用于建立和处理HMM的实验工具包,主要应用于语音识别领域,也可用于语音模型的测试和分析。其具体训练步骤如下:
(1)数据准备
收集汉语标准普通话的语料库,并将语料库中的语音标记,创建语音识别模块或单元元素列表文件。
(2)特征提取
本系统采用MFCC进行语音的特征参数提取,训练中将每一个语音文件用工具HCopy转换成MFCC格式。
(3)HMM定义
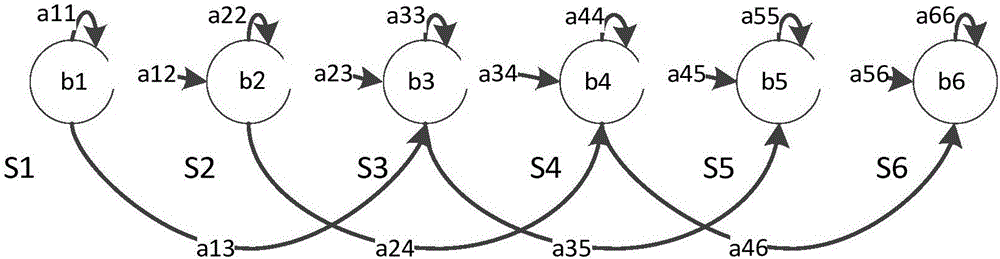
在训练HMM模型时要给出模型的初始框架,本系统中的HMM模型选择同一个结构,如图2所示。该模型包含4个活动状态{S2,S3,S4,S5),开始和结束(这里是S1,S6),是非发散状态。观察函数bi是带对角矩阵的高斯分布,状态的可能转换由aij表示。
(4)HMM训练
在训练过程开始之前,为了使得训练算法快速精准收敛,HMM模型参数必须根据训练数据正确初始化。HTK提供了2个不同的初始化工具:Hinit工具和HCompv工具,先使用HInit工具对HMM模型进行初始化,再用HCompv工具来对模型进行平坦初始化。HMM模型的每个状态给定相同的平均向量和变化向量,在整个训练集上全局计算而得。最后用HRest的多次估计迭代,估计出HMM模型参数的最佳值,经多次迭代,将训练得到的单个HMM模型整合到一个hmmsdef.mmf文件中。
Sphinx是由美国卡内基梅隆大学开发的大词汇量、非特定人、连续英语语音识别系统。一个连续语音识别系统大致可分为四个部分:特征提取,声学模型训练,语言模型训练和解码器。具体如图3所示:
(1)预处理模块:
对输入的原始语音信号进行处理,滤除掉其中的不重要的信息以及背景噪声,并进行语音信号的端点检测(找出语音信号的始末)、语音分帧(近似认为在10-30ms内是语音信号是短时平稳的,将语音信号分割为一段一段进行分析)以及预加重(提升高频部分)等处理。
(2)特征提取:
去除语音信号中对于语音识别无用的冗余信息,保留能够反映语音本质特征的信息,并用一定的形式表示出来。也就是提取出反映语音信号特征的关键特征参数形成特征矢量序列,以便用于后续处理。
(3)声学模型训练:
根据训练语音库的特征参数训练出声学模型参数。在识别时可以将待识别的语音的特征参数同声学模型进行匹配,得到识别结果。
(4)语言模型训练:
语言模型是用来计算一个句子出现概率的概率模型。它主要用于决定哪个词序列的可能性更大,或者在出现了几个词的情况下预测下一个即将出现的词语的内容。换一个说法说,语言模型是用来约束单词搜索的。它定义了哪些词能跟在上一个已经识别的词的后面(匹配是一个顺序的处理过程),这样就可以为匹配过程排除一些不可能的单词。
进一步的,将所述语音特征与预定义语音数据模型进行匹配,包括,
判断所述语音特征与预定义语音数据模型匹配的模糊度是否大于预设值,若大于则确认匹配,所述模糊度预设值为65%。
更进一步的,所述将所述语音特征与预定义语音数据模型进行匹配,包括:
判断所述语音特征与根据预定义语音数据模型匹配的模糊度是否大于预设值,若不大于则确认不匹配;
若确认不匹配则丢弃所述语音数据。
例如,用户发出“妈妈喊你回家吃饭”,即可将“妈妈喊你回家吃饭”与“几点了,我妈喊我回家吃饭”进行匹配;
当模糊度匹配不小于65%时,即确认匹配。
S103:若匹配则向预定的联系人发送指定信息;
优选的,若匹配则触发并唤醒预设应用程序向预定的联系人发送指定信息;
所述触发并唤醒为将触发指令通过intent方式传给预设应用程序,同时唤醒预设应用程序。
进一步的,若确认匹配时,录入环境音,调用GPS定位当前位置,将GPS定位信息和环境录音添加到指定信息,向预定的联系人发送所述指定信息;
所述GPS定位信息包含当前所在的纬度信息和经度信息。
更进一步的,若确认不匹配时,则丢弃所述语音数据。
实施例二
为了说明客户端详细模块的组成,请参阅图4,本实施例中至少包含了以下模块:
监听模块401、接收模块402、获取模块403、识别模块404、匹配模块405、处理模块406、录音模块407、调用模块408、信息模块409、触发模块410和存储模块411和设置模块412。
所述监听模块401,用于监听语音获取语音数据,当用户开启移动设备时,即开始实时监听周围的语音数据;
所述接收模块402,用于接收所述的语音数据;
所述获取模块403,用于获取所述语音数据内容信息中的语音特征;
进一步的,所述语音特征包括语音的音高、音强、音长、音色。
优选的,还包括所述的识别模块404,用于将所述语音数据拆分为单个元素和预定义语音数据模型的单个元素进行识别。
进一步的,如果所述识别模块识别单个语音数据的识别误差不小于预设值,则丢弃所述语音数据;
所述识别误差值预设值为35%。
所述匹配模块405,用于将所述语音特征与预定义语音数据模型进行匹配,其中,所述预定义语音数据模型根据用户预先录入的语音数据生成;
优选的,构建至少一个预定义语音数据模型,导入厂商预先设置的语音数据模型,例如“SOS”、“救命啊”、“help”等其他各国“救命”的语言和/或方言;
也可以根据用户自身的需求自行设置语音数据模型,具体包括:
所述存储模块411,用于存储构建的至少一个预定义语音数据模型4111;
所述构建的至少一个预定义语音数据模型4111:
录入用户语音数据,用户可在正常情况下录入语音,例如:录入不容易被歹徒识破的求救语言“几点了,我妈喊我回家吃饭”等等,如果系统提示录入不成功或需多录入几次,即可重复录入该求救语音;
根据所述的用户语音数据的内容信息提取语音特征;
将所述第一语音数据内容信息的语音特征转换为数字信息,并拆分成多个组成元素;
重组所述多个的组成元素成第二语音数据;
将第一语音数据和第二语音数据形成预定义语音数据模型。
进一步的,根据预定义语音数据模型设置模糊度,将所述的模糊度设置为65%。
更进一步的,将所述语音特征与预定义语音数据模型进行匹配,包括:
判断所述语音特征与根据预定义语音数据模型匹配的模糊度是否大于预设值,若不大于则确认不匹配;
若确认不匹配则丢弃所述语音数据。
例如,用户发出“妈妈喊你回家吃饭”,即可将“妈妈喊你回家吃饭”与“几点了,我妈喊我回家吃饭”进行匹配;
当模糊度匹配不小于65%时,则确认匹配;否则确定为不匹配。
所述处理模块406,用于确认匹配时向预定的联系人发送指定信息。
所述录音模块407,用于实时录入环境音;
所述调用模块408,用于调用GPS定位当前位置;所述定位信息包含当前所在的纬度信息和经度信息;
所述信息模块409,用于将环境录音和GPS定位信息添加到指定信息中;
优选的,所述触发模块410,用于在确认匹配时,触发并唤醒预设应用程序将所述指定信息发送至预定的联系人;
进一步的,当确认匹配时,录入环境音,调用GPS定位当前位置,将GPS定位信息和环境录音添加到指定信息中,触发并唤醒预设应用程序将所述指定信息发送至预定的联系人。
所述设置模块412,用于预先设置至少一个以上的联系人4121接收指定信息。
更进一步的,所述处理模块406确定不匹配时,继续监听。
实施例三
为了说明本发明一种信息处理的方法和装置均在如下所述的移动终端中实现,
所述移动终端,包括预设功能按键、处理器、存储器和传声器;
所述功能按键用于在锁屏状态下供用户触发生成操作指令;
所述传声器用于接收控制指令,开启或结束录音;
所述存储器用于存储支持锁屏状态下的录音装置执行前文所述信息处理的方法的程序;
所述处理器被配置为用于执行所述存储器中存储的程序。
详细叙述如下:
本实施例的系统中包括至少一个装置,以及用于接收所述装置发出求救信息的预定联系人。
该移动终端可以包括在手机、平板电脑、PDA(Personal Digital Assistant,个人数字助理)等任意移动终端中,以移动终端手机为例进行以下说明:
如图5所示,移动终端手机包括:射频(Radio Frequency,RF)电路610、存储器620、输入模块或单元630、显示模块或单元640、传感器650、音频电路660、无线保真(wireless fidelity,WiFi)模块670、处理器680、以及电源690等部件。本领域技术人员可以理解,图5中示出的手机结构并不构成对手机的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
下面结合图5对手机的各个构成部件进行具体的介绍:
RF电路510可用于收发信息或通话过程中,信号的接收和发送,特别地,将基站的下行信息接收后,给处理器580处理;另外,将设计上行的数据发送给基站。通常,RF电路510包括但不限于天线、至少一个放大器、收发信机、耦合器、低噪声放大器(Low Noise Amplifier,LNA)、双工器等。此外,RF电路510还可以通过无线通信与网络和其他设备通信。上述无线通信可以使用任一通信标准或协议,包括但不限于全球移动通讯系统(Global System of Mobile communication,GSM)、通用分组无线服务(General Packet Radio Service,GPRS)、码分多址(Code Division Multiple Access,CDMA)、宽带码分多址(Wideband Code Division Multiple Access,WCDMA)、长期演进(Long Term Evolution,LTE)、电子邮件、短消息服务(Short Messaging Service,SMS)等。
存储器520可用于存储软件程序以及模块,处理器580通过运行存储在存储器520的软件程序以及模块,从而执行手机的各种功能应用以及数据处理。存储器520可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序(比如声音播放功能、图像播放功能等)等;存储数据区可存储根据手机的使用所创建的数据(比如音频数据、电话本等)等。此外,存储器520可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他易失性固态存储器件。
输入模块或单元530可用于接收输入的数字或字符信息,以及产生与手机的用户设置以及功能控制有关的键信号输入。具体地,输入模块或单元530可包括触控面板531以及其他输入设备532。触控面板531,也称为触摸屏,可收集用户在其上或附近的触摸操作(比如用户使用手指、触笔等任何适合的物体或附件在触控面板531上或在触控面板531附近的操作),并根据预先设定的程式驱动相应的连接装置。可选的,触控面板531可包括触摸检测装置和触摸控制器两个部分。其中,触摸检测装置检测用户的触摸方位,并检测触摸操作带来的信号,将信号传送给触摸控制器;触摸控制器从触摸检测装置上接收触摸信息,并将它转换成触点坐标,再送给处理器580,并能接收处理器580发来的命令并加以执行。此外,可以采用电阻式、电容式、红外线以及表面声波等多种类型实现触控面板531。除了触控面板531,输入模块或单元530还可以包括其他输入设备532。具体地,其他输入设备532可以包括但不限于物理键盘、功能键(比如音量控制按键、开关按键等)、轨迹球、鼠标、操作杆等中的一种或多种。
显示模块或单元540可用于显示由用户输入的信息或提供给用户的信息以及手机的各种菜单。显示模块或单元540可包括显示面板541,可选的,可以采用液晶显示器(Liquid Crystal Display,LCD)、有机发光二极管(Organic Light-Emitting Diode,OLED)等形式来配置显示面板541。进一步的,触控面板531可覆盖显示面板541,当触控面板531检测到在其上或附近的触摸操作后,传送给处理器580以确定触摸事件的类型,随后处理器580根据触摸事件的类型在显示面板541上提供相应的视觉输出。虽然在图5中,触控面板531与显示面板541是作为两个独立的部件来实现手机的输入和输入功能,但是在某些实施例中,可以将触控面板531与显示面板541集成而实现手机的输入和输出功能。
手机还可包括至少一种传感器550,比如光传感器、运动传感器以及其他传感器。具体地,光传感器可包括环境光传感器及接近传感器,其中,环境光传感器可根据环境光线的明暗来调节显示面板541的亮度,接近传感器可在手机移动到耳边时,关闭显示面板541和/或背光。作为运动传感器的一种,加速计传感器可检测各个方向上(一般为三轴)加速度的大小,静止时可检测出重力的大小及方向,可用于识别手机姿态的应用(比如横竖屏切换、相关游戏、磁力计姿态校准)、振动识别相关功能(比如计步器、敲击)等;至于手机还可配置的陀螺仪、气压计、湿度计、温度计、红外线传感器等其他传感器,在此不再赘述。
音频电路560、扬声器561,传声器562可提供用户与手机之间的音频接口。音频电路560可将接收到的音频数据转换后的电信号,传输到扬声器561,由扬声器561转换为声音信号输出;另一方面,传声器562将收集的声音信号转换为电信号,由音频电路560接收后转换为音频数据,再将音频数据输出处理器580处理后,经RF电路510以发送给比如另一手机,或者将音频数据输出至存储器520以便进一步处理。
WiFi属于短距离无线传输技术,手机通过WiFi模块570可以帮助用户收发电子邮件、浏览网页和访问流式媒体等,它为用户提供了无线的宽带互联网访问。虽然图5示出了WiFi模块570,但是可以理解的是,其并不属于手机的必须构成,完全可以根据需要在不改变发明的本质的范围内而省略。
处理器580是手机的控制中心,利用各种接口和线路连接整个手机的各个部分,通过运行或执行存储在存储器520内的软件程序和/或模块,以及调用存储在存储器520内的数据,执行手机的各种功能和处理数据,从而对手机进行整体监控。可选的,处理器580可包括一个或多个处理模块或单元;优选的,处理器580可集成应用处理器和调制解调处理器,其中,应用处理器主要处理操作系统、用户界面和应用程序等,调制解调处理器主要处理无线通信。可以理解的是,上述调制解调处理器也可以不集成到处理器580中。
手机还包括给各个部件供电的电源590(比如电池),优选的,电源可以通过电源管理系统与处理器580逻辑相连,从而通过电源管理系统实现管理充电、放电、以及功耗管理等功能。
尽管未示出,手机还可以包括摄像头、蓝牙模块等,在此不再赘述。
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的方法、装置和移动终端的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
在本申请所提供的几个实施例中,应该理解到,所揭露的方法、装置和移动终端,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述模块或单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个模块或单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或模块或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
所述作为分离部件说明的模块或单元可以是或者也可以不是物理上分开的,作为模块或单元显示的部件可以是或者也可以不是物理模块或单元,即可以位于一个地方,或者也可以分布到多个网络模块或单元上。可以根据实际的需要选择其中的部分或者全部模块或单元来实现本实施例方案的目的。
另外,在本发明各个实施例中的各功能模块或单元可以集成在一个处理模块或单元中,也可以是各个模块或单元单独物理存在,也可以两个或两个以上模块或单元集成在一个模块或单元中。上述集成的模块或单元既可以采用硬件的形式实现,也可以采用软件功能模块或单元的形式实现。
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:只读存储器(ROM,Read Only Memory)、随机存取存储器(RAM,Random Access Memory)、磁盘或光盘等。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分步骤是可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。
以上对本发明所提供的一种信息处理的方法、装置和移动终端进行了详细介绍,对于本领域的一般技术人员,依据本发明实施例的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
概括的说,本发明提供的技术方案概述如下:
A1、一种信息处理的方法,包括:
在语音监听模式开启下,接收语音数据;
获取所述语音数据内容信息中的语音特征;
将所述语音特征与预定义语音数据模型进行匹配,其中,所述预定义语音数据模型根据用户预先录入的语音数据生成;
若匹配则向预定的联系人发送指定信息。
A2、如A1所述的方法,所述语音特征包括语音的音高、音强、音长、音色。
A3、如A1所述的方法,所述接收语音数据之后,还包括,
将所述语音数据拆分为单个元素和预定义语音数据模型的单个元素进行识别,如果识别误差不小于预设值,则丢弃所述语音数据;
所述识别误差值预设值为35%。
A4、如A1或A3所述的方法,所述预定义语音数据模型根据用户预先录入的语音数据生成,包括,
预先录入用户语音生成第一语音数据;
根据所述的第一语音数据的内容信息提取语音特征;
将所述第一语音数据内容信息的语音特征转换为数字信息,并拆分成多个组成元素;
将所述的多个组成元素重组为第二语音数据;
将第一语音数据和第二语音数据形成预定义语音数据模型。
A5、如A1所述的方法,所述将所述语音特征与预定义语音数据模型进行匹配,包括,
判断所述语音特征与预定义语音数据模型匹配的模糊度是否大于预设值,若大于则确认匹配;
所述模糊度预设值为65%。
A6、如A1所述的方法,所述将所述语音特征与预定义语音数据模型进行匹配,包括,
判断所述语音特征与根据预定义语音数据模型匹配的模糊度是否大于预设值,若不大于则确认不匹配;
若确认不匹配则丢弃所述语音数据。
A7、如A1所述的方法,
所述若匹配则向预定的联系人发送指定信息,包括,
若匹配则触发并唤醒预设应用程序向预定的联系人发送指定信息;
所述触发并唤醒为将触发指令通过intent方式传给预设应用程序,同时唤醒预设应用程序。
A8、如A1或A7所述的方法,所述若匹配则向预定的联系人发送指定信息,还包括:
录入环境音;
调用GPS定位当前位置;
将GPS定位信息和环境录音添加到指定信息中;
触发并唤醒预设应用程序将所述指定信息发送至预定的联系人。
B9、一种信息处理的装置,包括:
监听模块,用于监听语音获取语音数据;
接收模块,用于接收所述的语音数据;
获取模块,用于获取所述语音数据内容信息中的语音特征;
匹配模块,用于将所述语音特征与预定义语音数据模型进行匹配,其中,所述预定义语音数据模型根据用户预先录入的语音数据生成;
处理模块,用于确定匹配时向预定的联系人发送指定信息。
B10、如B9所述的装置,所述语音特征包括语音的音高、音强、音长、音色。
B11、如B 9所述的装置,所述接收语音数据之后,还包括,
将所述语音数据拆分为单个元素和预定义语音数据模型的单个元素进行识别,如果识别误差不小于预设值,则丢弃所述语音数据;
所述识别误差值预设值为35%。
B12、如B9或B11所述的装置,还包括存储模块,
所述存储模块用于存储预定义语音数据模型,所述预定义语音数据模型根据用户预先录入的语音数据生成,包括,
预先录入用户语音生成第一语音数据;
根据所述的第一语音数据的内容信息提取语音特征;
将所述第一语音数据内容信息的语音特征转换为数字信息,并拆分成多个组成元素;
将所述多个组成元素重组为第二语音数据;
将第一语音数据和第二语音数据形成预定义语音数据模型。
B13、如B9所述的装置,所述匹配模块将所述语音特征与预定义语音数据模型进行匹配,包括,
判断所述语音特征与预定义语音数据模型匹配的模糊度是否大于预设值,若大于则确认匹配,
所述模糊度预设值为65%。
B14、如B9所述的装置,所述匹配模块将所述语音特征与预定义语音数据模型进行匹配,包括,
判断所述语音特征与根据预定义语音数据模型匹配的模糊度是否大于预设值,若不大于则确认不匹配;
若确认不匹配则丢弃所述语音数据。
B15、如B9所述的装置,所述处理模块若匹配则向预定的联系人发送指定信息,包括,
若匹配则触发并唤醒预设应用程序向预定的联系人发送指定信息;
所述触发并唤醒为将触发指令通过intent方式传给预设应用程序,同时唤醒预设应用程序。
B16、如B9所述的装置,还包括,
录音模块,用于实时录入环境音;
调用模块,用于调用GPS定位当前位置;
信息模块,将环境录音和GPS定位信息添加到指定信息中;
设置模块,用于预先设置至少一个以上的联系人接收指定信息;
触发模块,触发并唤醒预设应用程序将所述指定信息发送至预定的联系人。
C17、一种移动终端,包括:
预设功能按键、处理器、存储器和传声器;
所述功能按键用于在锁屏状态下供用户触发生成操作指令;
所述传声器用于接收控制指令,开启或结束录音;
所述存储器用于存储支持锁屏状态下的录音装置执行前A1至A8中任意一项所述的信息处理方法的程序;
所述处理器被配置为用于执行所述存储器中存储的程序。
- 还没有人留言评论。精彩留言会获得点赞!