编码和解码图像的方法、编码和解码设备与流程
技术领域
本发明一般属于图像处理的领域,更准确地属于数字图像以及数字图像序列的编码和解码。
本发明由此尤其可被用于在目前的视频编码器(MPEG、H.264等)或未来的视频编码器(ITU-T/VCEG(H.265)或ISO/MPEG(HVC))中实现的视频编码。
背景技术:
目前的视频编码器(MPEG、H264等)使用视频序列的按块(block-wise)表示。图像被切分为宏块,每个宏块自身被切分为块,并且每个块或宏块通过图像内或图像间预测来编码。于是,特定的图像通过空间预测(帧内预测)来编码,而其他图像在本领域技术人员已知的运动补偿的辅助下关于一个或多个编码-解码参考图像通过时间预测(帧间预测)来编码。此外,对于每个块,可以对残留块进行编码,该残留块与原始块减去预测相对应。在可选的变换之后,该块的系数可被量化,然后被熵编码器编码。
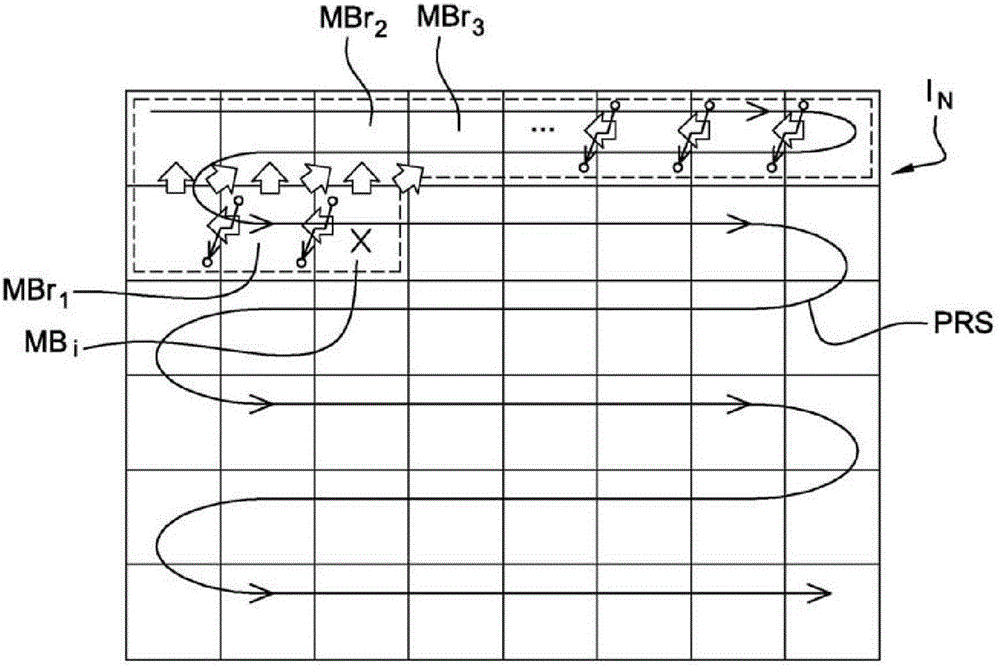
帧内预测和帧间预测需要之前已编码和解码的特定块可用,从而在解码器或编码器中被用于预测当前块。图1A表示这样的预测编码的示意性示例,其中,图像IN被分为块,该图像的当前块MBi经受与例如由阴影箭头表示的之前编码和解码的预定数量的三个块MBr1、MBr2、MBr3相关的预测编码。上述三个块特别包括紧邻地位于当前块MBi的左边的块MBr1、以及分别紧邻地位于当前块MBi的上方和右上方的两个块MBr2和MBr3。
这里更为特别关心的是熵编码器。熵编码器按照到达的顺序来对信息编码。典型地实现“光栅扫描”类型的块的逐行遍历,如图1A由参考(标号)PRS所示,从图像的左上角的块开始。对于每个块,表示该块所需的各个信息项(块类型、预测模式、残留系数等)被顺序分发给熵编码器。
已知一种足够复杂的有效算术编码器,被称为“CABAC”(“上下文适应二进制算术编码器”),其被引入到AVC压缩标准(也被称为ISO-MPEG4第10部分和ITU-T H.264)。
熵编码器实现各种构思:
-算术编码:例如最初在文档J.Rissanen and G.G.Langdon Jr,“Universalmodeling and coding,”IEEE Trans.Inform.Theory,vol.IT-27,pp.12–23,Jan.1981中描述的编码器使用该符号的出现概率来对符号进行编码;
-上下文适应:这包括适应要编码的符号的出现概率。一方面,实现快速获悉。另一方面,根据之前编码的信息的状态,特定的上下文被用于编码。每个上下文存在相对应的固有的符号出现概率。例如,上下文根据给定的配置对应于编码符号的类型(残留的系数、编码模式的信令等的表示),或者对应于邻居的状态(例如从邻居选择的“帧内”模式的数量等);
-二进制化:要编码的符号被转换为比特串的形式。随后,该各个比特被相继分发给二进制熵编码器。
于是,该熵编码器针对使用的每个上下文来实现一种系统,用于快速获悉与之前针对考虑的上下文来编码的符号相关的概率。该获悉基于这些符号的编码顺序。典型地,如上所述根据“光栅扫描”类型的顺序来遍历图像。
在对可等于0或1的给定符号b进行编码时,以下列方式针对当前块MBi来更新该符号的出现概率Pi的获悉:
其中,α是预定值,例如0.95,且Pi-1是在该符号最后出现时所计算的符号出现概率。
图1A表示这样的熵编码的示意性示例,其中,图像IN的当前块MBi被熵编码。在当前块MBi的熵编码开始时,所使用的符号出现概率是在之前编码和解码的块的编码之后获得的符号出现概率,根据上述“光栅扫描”类型的块的逐行遍历,该在之前编码和解码的块紧邻在当前块MBi的前面。仅为了图示清楚,图1A中通过细线箭头来表示针对特定的块的基于逐块依赖性的获悉。
该类型的熵编码的缺陷在于如下事实,在对位于行开始的符号进行编码时,使用的概率主要对应于位于前一行的末尾的符号所观察到的概率,与块的“光栅扫描”遍历相关。现在,由于符号概率的可能空间变化(例如,对于与运动信息项相关的符号,位于图像右侧部分的运动与在左侧部分观察到的可以不同,且从而对于由此产生的局部概率来说是类似的),可以观察到概率的局部适应性的缺失,这在编码时具有引起有效性损失的风险。
在互联网地址http://wftp3.itu.int/av-arch/jctvc-site/2010_04_A_Dresden/JCTVC-A114-AnnexA.doc(2011年2月8日)提供的文档“Annex A:CDCM Video Codec Decoder Specification”中描述了一种编码方法,其缓解了上述缺陷。如图1B所示,在以上文档中描述的编码方法包括:
-将图像IN切分为多个块的步骤,
-结合例如由阴影箭头表示的之前编码和解码的预定数量的三个块MBr1、MBr2、MBr3对该图像的当前块MBi进行预测编码的步骤。上述三个块特别包括紧邻地位于当前块MBi的左边的块MBr1、以及分别紧邻地位于当前块MBi的上方和右上方的两个块MBr2和MBr3,
-对图像IN的块进行熵编码的步骤,据此,在这些块可用时,每块使用分别针对紧邻地位于当前块上方的已编码和解码的块以及紧邻地位于当前块的左侧的已编码和解码的块来计算的符号出现概率。为了使后者更为清楚,在图1B中通过细线箭头来部分表示该符号出现概率的使用。
该熵编码的好处在于,它利用了由当前块的紧邻环境产生的概率,由此使得可能获得更高的编码性能。此外,使用的编码技术使得可能对预定数量的成对的相邻块的子集并行编码。在图1B展示的例子中,三个子集SE1、SE2和SE3被并行编码,在该例子中每个子集由虚线表示的一行块构成。当然,该编码需要分别位于当前块的上方和右上方的块可用。
该并行编码技术的缺陷在于,为了允许访问针对紧邻地位于当前块上方的块来计算的符号出现概率,需要存储与一行块关联的一些概率。如果例如在图1B中考虑第二行SE2的块,通过使用针对之前的第一行SE1的第一块来计算的符号出现概率,该行的第一块被熵编码。在完成第二行的第一块的编码时,出现概率的值V1的状态被存储在缓冲存储器MT中。随后,通过使用同时针对第一行SE1的第二块和第二行SE2的第一块来计算的符号出现概率,第二行SE2的第二块被熵编码。在完成第二行的第二块的编码时,出现概率的值V2的状态被存储在缓冲存储器MT中。该过程持续,直到第二行SE的最后一块。由于概率的数量非常大(存在与语法元素的数量和关联上下文的数量的组合一样多的概率),整一行的这些概率的存储在存储器资源方面非常昂贵。
技术实现要素:
本发明的一个目标是弥补上述现有技术的缺陷。
为此,本发明的主题涉及一种对至少一个图像进行编码的方法,包括下列步骤:
-将图像划分为多个块,
-将所述块分组为预定数量的块的子集,
-对所述块的子集中的每个并行编码,所考虑的子集中的块是根据遍历的预定顺序来编码的,针对所考虑的子集中的当前块,所述编码步骤包括下列子步骤:
·关于至少一个之前编码和解码的块对所述当前块进行预测编码,
·通过获悉至少一个之前的符号出现概率对当前块进行熵编码,
根据本发明的方法值得关注之处在于:
-在当前块是所考虑的子集中要编码的第一块的情形下,符号出现概率是针对至少一个其他子集中的编码和解码的预定块来计算的符号出现概率,
-在当前块是所考虑的子集中除第一块以外的块的情形下,符号出现概率是针对属于相同子集的至少一个已编码和解码的块来计算的符号出现概率。
该布置使得可能在编码器的缓冲存储器中存储较少数量的符号出现概率,因为除了块的子集的第一块之外的当前块的熵编码不再必定需要使用关于之前已编码和解码的块所计算的符号出现概率,该之前已编码和解码的块位于另一子集中并位于当前块上方。
该布置还使得可能保持现有的压缩性能,因为当前块的熵编码使用针对当前块所属的子集中的另一个之前编码和解码的块来计算的符号出现概率,并且最终已经通过更新概率来实现获悉,从而后者符合视频信号的统计。
在所考虑的块的子集中的第一当前块熵编码期间使用针对所述其他子集的第一块来计算的符号出现概率的主要好处在于,通过在编码器的缓冲存储器中仅存储所述符号出现概率的更新来节省该缓冲存储器,而不用考虑所述其他子集的其他连续块所获悉的符号出现概率。
在所考虑的块的子集的第一当前块的熵编码期间使用针对所述其他子集中除第一块以外的块(例如第二块)来计算的符号出现概率的主要好处在于,获得对符号出现概率的更精确且因此更好的获悉,由此带来更好的视频压缩性能。
在特定的实施例中,与所述子集中除第一块以外的要编码的当前块属于相同子集的所述编码和解码块是要编码的当前块的最近相邻块。
该布置由此使得可能在所考虑的子集中的第一块的熵编码期间仅存储所获悉的符号出现概率,因为在该特殊情形下,仅考虑针对位于第一当前块上方且属于另一子集的块来计算的符号出现概率。这带来了编码器的存储器资源的大小降低的优化。
在另一特殊实施例中,在所考虑的子集中的块的预测编码将关于所述考虑的子集以外的预定数量的之前编码和解码的块来执行的情形下,所述考虑的子集中的块的并行编码是以相对于在执行并行编码的顺序下紧邻在前面的块的子集而偏移预定数量的块来执行的。
该布置允许针对要编码的当前的块的子集来实现在执行并行编码的顺序下在当前子集前面的块的子集中的块的处理过程的同步,由此使得可能保证被用于当前块的编码的前面子集中的一个或多个块的可用性。通过该方式,在验证前面的子集中的该块的可用性的步骤(例如为在现有技术的并行编码器中实现的步骤)可被有利地忽略,由此允许在根据本发明的编码器中对块进行处理所需的处理时间的加速。
相关地,本发明还涉及一种对至少一个图像进行编码的设备,包括:
-用于将图像划分为多个块的部件,
-用于将块分组为预定数量的块的子集的部件,
-对块的子集中的每个并行编码的部件,所考虑的子集中的块是根据遍历的预定顺序来编码的,针对所考虑的子集中的当前块,所述编码部件包括:
·关于至少一个之前编码和解码的块对当前块进行预测编码的子部件,
·基于至少一个符号出现概率对当前块进行熵编码的子部件,
所述编码设备值得关注之处在于:
-在当前块是所考虑的子集中要编码的第一块的情形下,针对第一当前块的熵编码,熵编码的子部件考虑针对至少一个其他子集中的编码和解码的预定块来计算的符号出现概率,
-在当前块是所考虑的子集中除第一块以外的块的情形下,针对当前块的熵编码,熵编码的子部件考虑针对属于相同子集的至少一个编码和解码块来计算的符号出现概率。
通过相应的方式,本发明还涉及一种对表示至少一个编码图像的流进行解码的方法,包括下列步骤:
-在图像中识别要解码的预定数量的块的子集,
-对与块的子集中的每个关联的流的部分并行解码,所考虑的子集中的块是根据遍历的预定顺序来解码的,针对所考虑的子集中的当前块,所述解码步骤包括下列子步骤:
·基于至少一个符号出现概率对当前块进行熵解码,
·关于至少一个之前解码的块对当前块进行预测解码,
该解码方法值得关注之处在于:
-在当前块是所考虑的子集中要解码的第一块的情形下,符号出现概率是针对至少一个其他子集的已解码预定块来计算的,
-在当前块是所考虑的子集中除该子集中第一块以外的块的情形下,符号出现概率是针对属于相同子集的至少一个解码的块来计算的。
在特定的实施例中,与所述子集中第一块以外的要被解码的当前块属于相同的子集的解码块是要解码的当前块的最近相邻块。
在另一特定实施例中,在所考虑的子集中的块的预测解码想要针对除了所考虑的子集以外的预定数量的之前编码和解码的块来执行的情形下,所考虑的子集中的块的并行解码是相对于在执行并行解码的顺序下紧邻在前面的块的子集而偏移预定数量的块来执行的。
相关地,本发明还涉及一种对表示至少一个编码图像的流进行解码的设备,包括:
-在图像中识别要解码的预定数量的块的子集的部件,
-对与块的子集中的每个关联的流的部分并行解码的部件,所考虑的子集中的块是根据遍历的预定顺序来解码的,针对所考虑的子集的当前块,所述解码部件包括:
·基于至少一个符号出现概率对当前块进行熵解码的子部件,
·关于至少一个之前解码的块对当前块进行预测解码的子部件,
所述解码设备值得关注之处在于:
-在当前块是所考虑的子集中要解码的第一块的情形下,针对第一当前块的熵解码,进行熵解码的子部件考虑针对至少一个其他子集的已解码预定块来计算的符号出现概率,
-在当前块是所述考虑的子集中除第一块以外的块的情形下,针对当前块的熵解码,进行熵解码的子部件考虑针对属于相同子集的至少一个解码块来计算的符号出现概率。
本发明的目标还在于一种包含指令的计算机程序,当该程序在计算机上执行时,所述指令用于执行以上的编码或解码方法的步骤。
该程序可以使用任意编程语言,且可以是源代码、目标代码或源代码和目标代码之间的中间代码的形式,例如部分编译的形式,或者任意其他想要的形式。
本发明的又一目标还在于一种可被计算机读取的记录介质,并且其包含例如上述计算机程序指令。
记录介质可以是能够存储程序的任意实体或设备。例如,该介质可以包括:存储装置,诸如ROM(如CD ROM)、或微电子电路ROM;或者磁记录装置,例如磁盘(软盘)或硬盘。
此外,该记录介质可以是传输介质例如电或光信号,其可以通过电或光缆以无线电或其他方式来传输。根据本发明的程序特别地可在互联网类型的网络上下载。
替换地,该记录介质可以是集成电路,程序被合并在该集成电路中,该电路适于执行所讨论的方法或可用于后者的执行。
上述编码设备、解码方法、解码设备和计算机程序至少具有与根据本发明的编码方法所表现的优势相同的优势。
附图说明
通过参考附图来描述的两个优选实施例,其他特征和优势将变得明显,在附图中:
-图1A表示根据第一例子的现有技术的图像编码图,
-图1B表示根据第二例子的现有技术的图像编码图,
-图2A表示根据本发明的编码方法的主要步骤,
-图2B详细地展示了在图2A中的编码方法中实现的并行编码,
-图3A表示根据本发明的编码设备的实施例,
-图3B表示图3A中的编码设备的编码单元,
-图4A表示根据第一优选实施例的图像编码/解码图,
-图4B表示根据第二优选实施例的图像编码/解码图,
-图5A表示根据本发明的解码方法的主要步骤,
-图5B详细地展示了图5A中的解码方法中实现的并行编码,
-图6A表示根据本发明的解码设备的实施例,
-图6B表示图6A中的解码设备的解码单元。
具体实施方式
现在将描述本发明的实施例,其中,根据本发明的编码方法被用于根据二进制流对一系列图像进行编码,该二进制流接近于用根据H.264/MPEG-4AVC标准的编码来获取的二进制流。在该实施例中,通过对初始符合H.264/MPEG-4AVC标准的编码器的调整例如以软件或硬件的方式来实现根据本发明的编码方法。以图2A所示的包含步骤C1到C5的算法的形式来展示根据本发明的编码方法。
根据本发明的实施例,在图3A所示的编码设备CO中实现根据本发明的编码方法。
参考图2A,第一编码步骤C1是将要编码的一系列图像中的图像IE切分为多个块或宏块MB,如图4A或4B所示。在所示例子中,所述块MB为正方形并且都有相同的大小。作为图像大小的函数,其不必是块大小的倍数,左侧的最后的块和底部的最后的块可以不是正方形。在替代的实施例中,块例如可以是矩形大小并且/或者互相不对齐。
每个块或宏块自身还可被分为子块,该子块自身还可细分。
该切分是通过图3A所示的划分模块PCO来实现的,其使用例如众所周知的划分算法。
参考图2A,第二编码步骤C2是将上述块分组为预定数量P的连续的块的子集SE1、SE2、…SEk、…、SEP,该子集将被并行编码。在图4A和4B所示的例子中,预定数量P等于4,并且用虚线表示的四个子集SE1、SE2、SE3、SE4分别由图像IE的前四行块构成。
该分组操作是通过图3A所示的计算模块GRCO利用众所周知的算法来实现的。
参考图2A,第三编码步骤C3包括对所述块的子集SE1、SE2、SE3和SE4中的每个并行编码,所考虑的子集中的块是根据遍历的预定顺序PS来编码的。在图4A和4B所示的例子中,当前子集SEk(1≤k≤4)中的块如箭头PS所示从左到右被依次编码。
该并行编码是通过图3A所示的数量为R(R=4)的编码单元UCk(1≤k≤R)来实现的,并允许编码方法的大幅加速。通过这样已知的方式,编码器CO包括缓冲存储器MT,其适于包含例如与当前块的编码协作的逐渐更新的符号出现概率。
如图3B更详细的展示,每个编码单元UCk包括:
·关于至少一个之前编码和解码的块对当前块进行预测编码的子单元,用SUCPk来表示;
·通过使用针对所述之前编码和解码的块来计算的至少一个符号出现概率对所述当前块进行熵编码的子单元,用SUCEk来表示。
预测编码子单元SUCPk能够根据传统的预测技术例如以帧内和/或帧间模式来执行当前块的预测编码。
熵编码子单元SUCEk本身是CABAC类型,但根据本发明来调整,在说明书中将进一步描述。
作为变体,熵编码子单元SUCEk可以是已知的霍夫曼编码器。
在图4A和4B所示的例子中,第一单元UC1对第一行SE1的块从左向右进行编码。在到达第一行SE1的最后一块时,会传递到第(N+1)行这里是第5行等的第一块。第二单元UC2对第二行SE2的块从左向右进行编码。在到达第二行SE2的最后一块时,会传递到第(N+2)行这里是第6行等的第一块。该遍历被重复直到单元UC4,其对第四行SE4的块从左向右进行编码。在到达第一行的最后一块时,会传递到第(N+4)行这里是第8行的第一块,以此类推直到图像IE的最后一块被编码。
与以上刚才描述的不同的其他类型的遍历当然也是可能的。于是,可以将图像IE切分为若干个子图像,并将该类型的切分独立地应用于每个子图像。每个编码单元也可以不处理如上解释的嵌套的行而是嵌套的列。还可以以任意方向来遍历行或列。
参考图2A,第四编码步骤C4是产生N个子比特流Fk(1≤k≤N)以及每个子集SEk中的已处理块的解码版本,该子比特流Fk表示被上述每个编码单元压缩的已处理的块。根据将在说明书中进一步详细描述的同步机制,用SED1、SED2、…SEDk、…、SEDP表示的所考虑的子集中的解码的已处理块可被图3A所示的某些编码单元UC1、UC2、……、UCk、……、UCP重新使用。
参考图2A,第五编码步骤C5包括基于上述子流Fk来构造全局的流F。根据一个实施例,子流Fk被简单地并列,其额外的信息项用于向解码器表示每个子流Fk在全局流F中的位置。所述全局流F通过通信网络(未示出)传输到远程终端。后者包括图6A所示的解码器DO。
于是,如说明书中将更详细地描述,根据本发明的解码器能够隔离全局流F中的子流Fk,并将它们分配给解码器的每个组成解码单元。需要注意,将子流分解为全局流独立于选择使用若干个并行地操作的解码单元,并且通过该方法可以仅使用包含并行操作单元的编码器或解码器。
全局流F的该构造是在如图3A所示的流构造模块CF中实现的。
现在将参考图2B来描述例如在上述并行编码步骤C3期间在编码单元UCk中实现的本发明的各个特定子步骤。
在步骤C31的过程中,编码单元UCk选择图4A或4B所示的当前行SEk中要编码的第一块作为当前块。
在步骤C32的过程中,单元UCk测试当前块是否是图像IE中的第一块(位于顶部和左侧),在上述步骤C1中该图像已被切分为块。
如果是这种情形,在步骤C33的过程中,编码概率被初始化为之前在图3A的编码器CO中定义的值Pinit。
如果不是这种情形,在后续说明中将详细描述的步骤C40中,确定必要的之前编码和解码的块的可用性。
在步骤C34的过程中,对图4A或4B所述的第一行SE1中的第一当前块MB1进行编码。该步骤C34包括将在下面描述的多个子步骤C341到C348。
在第一子步骤C341的过程,通过帧内和/或帧间预测的已知技术来对当前块MB1进行预测编码,在其过程中,关于至少一个之前编码和解码的块来预测块MB1。
毋庸赘述,例如在H.264标准中提出的其他模式的帧内预测也是可以的。
当前块MB1还可以经过帧间模式的预测编码,在其过程中,关于从之前编码和解码的图像产生的块来预测当前块。当然可以设想其他类型的预测。在用于当前块的可能的预测中,根据对于本领域技术人员来说众所周知的速率失真准则来选择最优的预测。
上述预测编码步骤使得可能构造预测块MBp1,这是对当前块MB1的近似。与该预测编码相关的信息随后将被写入到流F,该流F被发送到解码器DO。该信息特别包含预测的类型(帧间或帧内),且如果合适,包含帧内预测的模式、块或宏块的划分类型(如果宏块已被细分)、参考图像索引、以及在帧间预测模式中使用的偏移矢量。该信息被编码器CO压缩。
在后面的子步骤C342的过程中,从当前块MB1中减去预测块MBp1,产生残留块MBr1。
在后面的子步骤C343的过程中,根据传统的直接变换操作(例如DCT类型的离散余弦变换)来变换残留块MBr1,产生变换的块MBt1。
在后面的子步骤C344的过程中,根据传统的量化操作(例如标量量化)来对变换的块MBt1进行量化。然后获得系数被量化的块MBq1。
在后面的子步骤C345的过程中,对系数被量化的块MBq1进行熵编码。在优选的实施例中,这需要CABAC熵编码。
在后面的子步骤C346的过程中,根据传统的反量化操作来对块MBq1进行反量化,这是在步骤C344中执行的量化的逆操作。然后获得系数被反量化的块MBDq1。
在后面的子步骤C347的过程中,对系数被反量化的块MBDq1进行逆变换,这是以上步骤C343中执行的直接变换的逆操作。然后获得解码的残留块MBDr1。
在后面的子步骤C348的过程中,通过将解码的残留块MBDr1加到预测块MBp1来构造解码的块MBD1。需要注意,后者与在说明书中进一步描述的对图像IE进行解码的方法完成时获取的解码块相同。解码块MBD1于是可被编码单元UC1或构成预定数量R的编码单元的任意其他编码单元使用。
在完成上述编码步骤C34时,例如如图3B所示的熵编码子单元SUCEk包含例如与第一块的编码协作而逐渐更新的所有概率。这些概率对应于各种可能的语法元素且对应于各种相关的编码上下文。
在上述编码步骤C34之后,在步骤C35的过程中进行测试,以确定当前块是否是该相同行的第j块,其中,j是编码器CO的已知预定值、且至少等于1。
如果是这样的情形,在步骤C36的过程中,针对第j块来计算的一组概率被存储在例如如图3A以及图4A和4B所示的编码器CO的缓冲存储器MT中,所述存储器的大小适于存储所计算的数量的概率。
在步骤C37的过程中,单元UCk测试刚才被编码的行SEk中的当前块是否是图像IE的最后一块。
如果是这种情形,则在步骤C38的过程中,编码方法结束。
如果不是这种情形,在步骤C39的过程中根据图4A或4B中的箭头PS所表示的遍历顺序来选择下一要编码的块MBi。
如果在步骤C35的过程中,当前块不是所考虑的行SEk中的第j块,则不经过以上步骤C37。
在步骤C40的过程中,确定对于当前块MBi的编码来说必要的之前编码和解码的块的可用性。考虑到这需要通过不同的编码单元UCk来对图像IE的块并行编码的事实,用于对这些块进行编码的编码单元可能未对这些块进行编码和解码,且因此它们还不可用。所述确定步骤包括验证位于前一行SEk-1中的预定数量N'的块例如分别位于当前块的上方和右上方的两个块是否可用于当前块的编码,即它们是否已经被对其进行编码的编码单元UCk-1编码且然后被解码。所述确定步骤还包括验证位于要编码的当前块MBi的左侧的至少一块的可用性。但是,考虑到图4A或4B所示的实施例中选择的遍历顺序PS,对所考虑的行SEk中的块依次进行编码。因此,左侧的已编码和解码的块总是可用的(除了一行中的第一块)。在图4A或4B所示的例子,这需要块紧邻地位于要编码的当前块的左侧。为此,仅测试分别位于当前块的上方和右上方的两个块的可用性。
该测试步骤易于使编码方法变慢,通过根据本发明的替代方法,图3A所示的时钟CLK适于对块编码的过程进行同步,从而确保分别位于当前块的上方和右上方的两个块的可用性,而不需要验证这两个块的可用性。于是,如图4A或4B所示,编码单元UCk总是以用于当前块的编码的前一行SEk-1中的预定数量N'(这里N'=2)的编码和解码块作为偏移来开始对第一块的编码。从软件的角度来看,实现这样的时钟使得可能在编码器CO中显著加速用于处理图像IE中的块所需的处理时间。
在步骤C41的过程中,进行测试来确定当前块是否是所考虑的行SEk中的第一块。
如果是这样的情形,在步骤C42的过程中,在缓冲存储器MT中仅读取在前一行SEk-1的第j块的编码期间计算的符号出现概率。
根据图4A所示的第一变体,第j块是前一行SEk-1中的第一块(j=1)。该读取包括用缓冲存储器MT中存在的概率来替换CABAC编码器的概率。对第二行SE2、第三行SE32和第四行SE4中的各个第一块进行处理,在图4A中通过细线表示的箭头来描述该读取步骤。
根据图4B所示的上述步骤C42的第二变体,第j块是前一行SEk-1的第二块(j=2)。该读取包括用缓冲存储器MT中存在的概率来替换CABAC编码器的概率。对第二行SE2、第三行SE32和第四行SE4中的各个第一块进行处理,在图4B中通过虚线表示的箭头来描述该读取步骤。
在步骤C42之后,通过上述步骤C34到C38的迭代,当前块被编码且然后被解码。
如果在上述步骤C41之后,当前块不是所考虑的行SEk的第一块,有利地不会读取从位于同一行SEk的之前编码和解码的块(即所示例子中紧邻地位于当前块的左侧的编码和解码块)产生的概率。确实,考虑到位于同一行中的块的顺序遍历读PS,如图4A或4B所示,在当前块的编码开始时在CABAC编码器中存在的符号出现概率正好是在该相同行中前一块的编码/解码之后存在的符号出现概率。
因此,在步骤C43的过程中,获悉所述当前块的熵编码的符号出现概率,其仅对应于如图4A或4B中的双实线箭头表示的针对同一行中的所述前一块来计算的符号出现概率。
在步骤C43之后,通过上述步骤C34到C38的迭代,当前块被编码且然后被解码。
解码部分的实施例的详细描述
现在将描述根据本发明的解码方法的实施例,其中,以软件或硬件的方式通过对初始符合H.264/MPEG-4AVC标准的解码器的调整来实现该解码方法。
以图5A所示的包含步骤D1到D4的算法的形式来展示根据本发明的解码方法。
根据本发明的实施例,在如图6A所示的解码设备DO中实现根据本发明的解码方法。
参考图5A,第一解码步骤D1是在所述流F中识别N个子流F1、F2、…、Fk、…、FP,该子流分别包含如图4A或4B所示的之前编码的块或宏块MB的N个子集SE1、SE2、…、SEk、…、SEP。为此,流F中的每个子流Fk与指示符关联,以允许解码器DO确定每个子流在流F中的位置。在所示例子中,所述块MB具有正方形并且都有相同的大小。作为图像大小的函数,其不必是块大小的倍数,左侧的最后的块和底部的最后的块可以不是正方形。在替代的实施例中,块例如可以是矩形大小并且/或者互相不对齐。
每个块或宏块自身还可被分为子块,该子块自身还可细分。
这样的识别是通过如在图6A中表示的流提取模块EXDO来执行的。
在图4A或4B所示的例子中,预定数量等于4,并且四个子集SE1、SE2、SE3、SE4用虚线表示。
参考图5A,第二解码步骤D2是对所述块的子集SE1、SE2、SE3和SE4中的每个并行解码,所考虑的子集中的块根据遍历的顺序PS来编码。在图4A或4B所示的例子中,当前子集SEk(1≤k≤4)中的块如箭头PS所示从左到右被依次解码。在步骤D2完成时,获得解码的块的子集SED1、SED2、SED3、…、SEDk、…、SEDP。
该并行解码是由如图6A所示的数量为R(R=4)的解码单元UDk(1≤k≤R)来实现的,并且允许解码方法的大幅加速。按照这样已知的方式,解码器DO包括缓冲存储器MT,其适于包含例如与当前块的解码协作地逐渐更新的符号出现概率。
如图6B更详细地展示,每个解码单元UDk包括:
·通过获悉针对至少一个之前解码的块来计算的至少一个符号出现概率、对所述当前块进行熵解码的子单元,用SUDEk来表示,
·关于所述之前解码的块来对当前块进行预测解码的子单元,用SUDPk来表示。
预测解码子单元SUDPk能够根据传统的预测技术例如在帧内和/或帧间模式下执行当前块的预测解码。
熵解码子单元SUDEk本身是CABAC类型,但根据本发明来调整,在说明书中将进一步描述。
作为变体,熵解码子单元SUDEk可以是已知的霍夫曼解码器。
在图4A或4B所示的例子中,第一单元UD1对第一行SE1中的块从左向右进行解码。在到达第一行SE1的最后一块时,会传递到第(N+1)行(这里是第5行)等的第一块。第二单元UC2对第二行SE2中的块从左到右进行解码。在到达第二行SE2的最后一块时,会传递给第(N+2)行(这里是第6行)等的第一块。该遍历重复直到单元UD4,其对第四行SE4中的块从左向右进行解码。在到达第一行的最后一块时,会传递给第(N+4)行(这里是第8行)的第一块,以此类推直到最后识别的子流中的最后一块被解码。
与以上刚才描述的不同的其他类型的遍历当然也是可能的。例如,每个解码单元也可以不处理如上解释的嵌套的行而是嵌套的列。还可以以任意方向来遍历行或列。
参考图5A,第三解码步骤D3是基于在解码步骤D2中获得的每个解码的子集SED1、SED2、…、SEDk、…、SEDP来重构解码的图像。更准确地说,每个解码的子集SED1、SED2、…、SEDk、…、SEDP中的解码块被发送到例如如图6A所示的图像重构单元URI。在步骤D3的过程中,当这些块变得可用时,单元URI在解码的图像中写入解码块。
在图5A所示的第四解码步骤D4的过程中,图6A所示的单元URI给出完全解码的图像ID。
现在将参考图5B来描述例如在上述并行解码步骤D2期间在解码单元UDk中实现的本发明的各个特定子步骤。
在步骤D21的过程中,解码单元UDk选择在图4A或4B所示的当前块SEk中要解码的第一块作为当前块。
在步骤D22的过程中,单元UDk测试当前块是否是被解码的图像中的第一块,在该实例中为子流F1的第一块。
如果是这种情形,在步骤D23的过程中,解码概率被初始化为之前在图6A的解码器DO中定义的值Pinit。
如果不是这种情形,将在后续说明中描述的步骤D30的过程中确定必要的之前解码的块的可用性。
在步骤D24的过程中,对图4A或4B所示的第一行SE1中的第一当前块MB1进行解码。该步骤D24包括以下将描述的多个子步骤D241到D246。
在第一子步骤D241的过程中,对与当前块相关的语法元素进行熵解码。更准确地说,通过例如图6B所示的CABAC熵解码子单元SUDE1对与当前块相关的语法元素进行解码。CABAC熵解码子单元SUDE1对压缩文件的子比特流F1进行解码以产生语法元素,且同时以该方式来更新其概率,从而在该子单元对符号进行解码的时刻,该符号的出现概率等于在上述熵编码步骤C345中对该相同符号进行编码时得到的符号出现概率。
在后面的子步骤D242的过程中,通过帧内和/或帧间预测的已知技术来对当前块MB1进行预测解码,在其过程中,关于至少一个之前解码的块来预测所述块MB1。
毋庸赘述,例如在H.264标准中提出的其他模式的帧内预测也是可以的。
在该步骤的过程中,借助于在之前的步骤中解码的语法元素进行预测解码,该语法元素特别包含预测的类型(帧间或帧内),且如果合适,包含帧内预测的模式、块或宏块的划分类型(如果后者已被细分)、参考图像索引、以及在帧间预测模式中使用的偏移矢量。
上述预测解码步骤使得可能构造预测块MBp1。
在后面的子步骤D243的过程中,借助于之前解码的语法元素来构造量化残留块MBq1。
在后面的子步骤D244的过程中,根据传统的反量化操作来对量化的残留块MBq1进行反量化,这是在上述步骤C344中执行的量化的逆操作,以产生解码的反量化块MBDt1。
在后面的子步骤D245的过程中,对反量化块MBDt1进行逆变换,这是以上步骤C343中执行的直接变换的逆操作。然后获得解码的残留块MBDr1。
在后面的子步骤D246的过程中,通过将预测块MBp1加到解码的残留块MBDr1来构造解码块MBD1。所述解码块MBD1于是可被解码单元UD1或构成预定数量N的解码单元的一部分的任意其他解码单元使用。
在完成上述解码步骤D246时,例如如图6B所示的熵解码子单元SUDE1包含例如与第一块的解码协作而逐渐更新的所有概率。这些概率对应于各种可能的语法元素以及各种关联的解码上下文。
在上述解码步骤D24之后,在步骤D25的过程中进行测试,以确定当前块是否是该相同行的第j块,其中j是解码器DO的已知预定值且至少等于1。
如果是这种情形,在步骤D26的过程中,针对第j块来计算的一组概率被存储在例如如图6A以及图4A或4B所示的解码器DO的缓冲存储器MT中,所示存储器的大小适于存储所计算的概率的数量。
在步骤D27的过程中,单元UDk测试刚才被解码的当前块是否是最后的子流中的最后一块。
如果是这种情形,在步骤D28的过程中,解码方法结束。
如果不是这种情形,执行步骤D29,在步骤D29的过程中根据图4A或4B中的箭头PS所示的遍历顺序来选择要解码的下一块MBi。
如果在上述步骤D25的过程中,当前块不是所考虑的行SEDk中的第j块,进行以上的步骤D27。
在上述步骤D29之后的步骤D30的过程中,确定对于当前块MBi的解码来说必要的之前解码的块的可用性。考虑到这需要通过不同的解码单元UDk来对块并行编码的事实,用于对这些块进行解码的解码单元可能未对这些块进行解码,且因此它们还不可用。所述确定步骤包括验证位于前一行SEk-1中的预定数量N'的块(例如分别位于当前块的上方和右上方的两个块)是否可用于当前块的解码,即它们是否已经被对其进行解码的解码单元UDk-1解码。所述确定步骤还包括验证位于要解码的当前块MBi的左侧的至少一块的可用性。但是,考虑到图4A或4B所示的实施例中选择的遍历顺序PS,对所考虑的行SEk中的块依次进行解码。因此,左侧的解码的块总是可用的(除了一行中的第一块)。在图4A或4B所示的例子中,这需要块紧邻地位于要解码的当前块的左侧。为此,仅测试分别位于当前块的上方和右上方的两个块的可用性。
该测试步骤易于使解码方法变慢,通过根据本发明的替代方法,图6A所示的时钟CLK适于对块解码的过程进行同步,从而确保分别位于当前块的上方和右上方的两个块的可用性,而不需要验证这两个块的可用性。于是,如图4A或4B所示,解码单元UDk总是以用于解码当前块的前一行SEk-1中的预定数量N'(这里N'=2)的解码块作为偏移来开始对第一块进行解码。从软件的角度来看,实现这样的时钟使得可能在解码器DO中显著加速处理每个子集SEk中的块所需的处理时间。
在步骤D31的过程中,进行测试以确定当前块是否是所考虑的行SEk中的第一块。
如果是这样的情形,在步骤D32的过程中,在缓冲存储器MT中仅读取在前一行SEk-1的第j块的解码期间计算的符号出现概率。
根据图4A所示的第一变体,第j块是前一行SEk-1中的第一块(j=1)。该读取包括用缓冲存储器MT中存在的概率来替换CABAC解码器的概率。对第二行SE2、第三行SE3和第四行SE4中的各个第一块进行同样处理,在图4A中通过细线表示的箭头来描述该读取步骤。
根据图4B所示的上述步骤D32的第二变体,第j块是前一行SEk-1的第二块(j=2)。该读取包括用缓冲存储器MT中存在的概率来替换CABAC解码器的概率。对第二行SE2、第三行SE3和第四行SE4中的各个第一块进行处理,在图4B中通过虚线表示的箭头来描述该读取步骤。
在步骤D32之后,通过上述步骤D24到D28的迭代,当前块被解码。
如果在上述步骤D31之后,当前块不是所考虑的行SEk的第一块,有利地不会读取从位于同一行SEk的之前解码的块(即所示例子中紧邻地位于当前块的左侧的解码块)产生的概率。确实,考虑到位于同一行中的块的顺序遍历读PS,如图4A或4B所示,在当前块的解码开始时在CABAC解码器中存在的符号出现概率正好是在该相同行中前一块的解码之后存在的符号出现概率。
因此,在步骤D33的过程中,获悉用于所述当前块的熵解码的符号出现概率,其仅对应于如图4A或4B中的双实线箭头表示的针对同一行中的所述前一块来计算的符号出现概率。
在步骤D33之后,通过上述步骤D24到D28的迭代,当前块被解码。
- 还没有人留言评论。精彩留言会获得点赞!