一种终端音频播放方法及系统与流程
本发明涉及终端领域,特别涉及一种终端音频播放方法及系统。
背景技术:
终端(Terminal)也称终端设备,是计算机网络中处于网络最外围的设备。终端包括计算机、电视机等电子设备,也包括移动终端,譬如手机、平板电脑等电子设备。在日常生活中,人们常用的是移动终端,即可以在移动中使用的计算机设备,其移动性主要体现在移动通信能力和便携化体积。广义上讲包括手机、笔记本、POS机甚至包括车载电脑。移动终端不仅可以通话、视频通话、拍照、听音乐、看视频、玩游戏,而且可以实现包括定位、信息处理、指纹扫描、身份证扫描、条码扫描、RFID扫描、IC卡扫描以及酒精含量检测等丰富的功能。
而现有终端在打电话和听录音、视频的时候,有时候由于环境背景音过大,导致无法听清说话者的声音,声音清晰度不高,给用户带来了大大的不便。
因而现有技术还有待改进和提高。
技术实现要素:
鉴于上述现有技术的不足之处,本发明的目的在于提供一种终端音频播放方法及系统,旨在解决现有终端的声音清晰度不高的问题。
为了达到上述目的,本发明采取了以下技术方案:
一种终端音频播放方法,其中,包括:
A、对终端待播放的音频数据进行声纹分析,得到对应的声纹特征;
B、将所述声纹特征与预先设置的声纹特征库进行匹配,若匹配成功,则保持所述音频数据的播放音量;若匹配不成功,则降低所述音频数据的播放音量。
所述的终端音频播放方法,其中,在所述步骤A之前,还包括:
A11、预先对多个声源进行标记,并对各个声源的音频数据进行声纹分析,得到对应的声纹特征;
A12、将各个声纹特征及其对应声源的声源标记关联存储,生成所述声纹特征库。
所述的终端音频播放方法,其中,所述步骤A具体包括:
A21、对所述声纹特征库中声源标记进行选择;
A22、对终端待播放的音频数据进行声纹分析,得到对应的声纹特征。
所述的终端音频播放方法,其中,所述步骤B具体包括:
B1、将所述声纹特征与选择的声纹特征库进行匹配,若匹配成功,则保持所述音频数据的播放音量;若匹配不成功,则降低所述音频数据的播放音量。
所述的终端音频播放方法,其中,所述步骤A具体包括:
A31、每隔预定时间对终端待播放的音频数据进行声纹分析,得到对应的声纹特征。
一种终端音频播放系统,其中,包括:
声纹识别模块,用于对终端待播放的音频数据进行声纹分析,得到对应的声纹特征;
声纹匹配模块,用于将所述声纹特征与预先设置的声纹特征库进行匹配,若匹配成功,则保持所述音频数据的播放音量;若匹配不成功,则降低所述音频数据的播放音量。
所述的终端音频播放系统,其中,还包括:
标记分析模块,用于预先对多个声源进行标记,并对各个声源的音频数据进行声纹分析,得到对应的声纹特征;
存储模块,用于将各个声纹特征及其对应声源的声源标记关联存储,生成所述声纹特征库。
所述的终端音频播放系统,其中,所述声纹识别模块包括:
声源选择单元,用于对所述声纹特征库中声源标记进行选择;
声纹分析单元,用于对终端待播放的音频数据进行声纹分析,得到对应的声纹特征。
所述的终端音频播放系统,其中,所述声纹匹配模块包括:
声纹匹配单元,用于将所述声纹特征与选择的声纹特征库进行匹配,若匹配成功,则保持所述音频数据的播放音量;若匹配不成功,则降低所述音频数据的播放音量。
所述的终端音频播放系统,其中,所述声纹识别模块,还用于每隔预定时间对终端待播放的音频数据进行声纹分析,得到对应的声纹特征。
相较于现有技术,本发明提供的终端音频播放方法及系统,通过对终端待播放的音频数据进行声纹分析,得到对应的声纹特征;将所述声纹特征与预先设置的声纹特征库进行匹配,若匹配成功,则保持所述音频数据的播放音量;若匹配不成功,则降低所述音频数据的播放音量;利用声纹识别技术,确认当前的音频数据与预存的声纹特征不匹配时,则降低环境背景音的音量,以达到当前音频数据的音量明显高于环境背景音的效果,提高了声音清晰度,带来了极大的方便。
附图说明
图1为本发明提供的终端音频播放方法的方法流程图。
图2为本发明提供的终端音频播放系统的结构框图。
具体实施方式
本发明提供一种终端音频播放方法及系统。为使本发明的目的、技术方案及效果更加清楚、明确,以下参照附图并举实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
本发明提供一种终端音频播放方法,请参阅图1,所述终端音频播放方法,包括以下步骤:
S100、对终端待播放的音频数据进行声纹分析,得到对应的声纹特征;
S200、将所述声纹特征与预先设置的声纹特征库进行匹配,若匹配成功,则保持所述音频数据的播放音量;若匹配不成功,则降低所述音频数据的播放音量。
下面结合具体的实施例对上述步骤进行详细的描述。
在所述步骤S100中,对终端待播放的音频数据进行声纹分析,得到对应的声纹特征。本发明的终端可为手机、平板电脑、计算机等,对终端待播放的音频数据进行声纹分析,关于声纹分析此乃现有技术,这样便可得到待播放的音频数据的声纹特征。所谓声纹(Voiceprint),是用电声学仪器显示的携带言语信息的声波频谱。人类语言的产生是人体语言中枢与发音器官之间一个复杂的生理物理过程,人在讲话时使用的发声器官--舌、牙齿、喉头、肺、鼻腔在尺寸和形态方面每个人的差异很大,所以任何两个人的声纹图谱都有差异。这样,不仅指纹,声纹也可应用于生物识别领域之中,特别是人物识别。
然后在步骤S200中,将其与预先设置的声纹特征库进行匹配,若匹配成功,则保持所述音频数据的播放音量;若匹配不成功,则降低所述音频数据的播放音量。也就是说,如果待播放的音频数据的声纹特征没有在预先存储的声纹特征库中,那么就降低该音频数据的音量,如果在的话,就保持原有音量不变。这样,便可将不匹配的音频数据的播放声音降低,匹配的音频数据的播放声音不变,便可突出了匹配的音频数据声音,从而提高了声音清晰度。
举例来说,若声纹特征库中存有音频中各个声源(也就是各个人物)的声纹特征,在音频播放时,若待播放的音频数据得到的声纹特征与声纹特征库不匹配,则表明该待播放的音频数据没有包含上述各个声源(也就是各个人物)的声音,则该音频数据为环境背景音,将该音频数据的音频音量降低,则对应降低了环境背景音,相对地达到了突出人物声音的效果。关于降低音量具体降低多少,可根据实际需要进行时设置,也可直接静音,还可采用降低固定音量值。
请继续参阅图1,优选地,在所述步骤S100之前,还包括:
S111、预先对多个声源进行标记,并对各个声源的音频数据进行声纹分析,得到对应的声纹特征;
S112、将各个声纹特征及其对应声源的声源标记关联存储,生成所述声纹特征库。
具体来说,关于声纹特征库,可采用上述步骤得到,预先采集多个声源对应的声纹特征,并且对各个声源对应进行标记,将标记与声纹特征关联存储,从而得到声纹特征库。所述标记可采用文字、图案、符号和/或数字等。在实际应用时,可采用各个声源的名字作为标记,将其名字与对应的声纹特征关联存储。譬如通讯录中各个人物名字及其对应的声纹特征都存储在声纹特征库中。
进一步地,所述步骤S100具体包括:
S121、对所述声纹特征库中声源标记进行选择;
S122、对终端待播放的音频数据进行声纹分析,得到对应的声纹特征。
具体来说,就是对声纹特征库中的声源标记进行选择,实际应用时,可为接受用户对各个名字的选择,便可从声纹特征库中找到对应的声纹特征。
进一步地,所述步骤S200具体包括:
S201、将所述声纹特征与选择的声纹特征库进行匹配,若匹配成功,则保持所述音频数据的播放音量;若匹配不成功,则降低所述音频数据的播放音量。也就是说,识别待播放的音频数据的声纹特征,将其与用户选择的声纹特征进行匹配,判断是否是用户所期待的或者说用户所选择的声音,若为是,则正常播放,若为否,则调低该音频数据音量。这样,可以使得用户的目标声源的音量明显高于环境背景音,提高了声音清晰度。
优选地,所述步骤S100具体包括:
S131、每隔预定时间对终端待播放的音频数据进行声纹分析,得到对应的声纹特征。具体来说,就是每隔一定时间就对终端待播放的音频数据进行声纹分析,然后进行匹配,如果不匹配,表明可能为声源的环境背景音,进行降音处理;若匹配,则正常播放;这样,便达到了突显声源(也就是正确说话人)声音的效果。关于预定时间,可根据实际需要进行设置。优选地,由于音频一帧一帧的数据,可对每一帧的待播放音频数据进行声纹分析。
以下以一应用实施例对本发明详细阐述如下。用户在终端设备上预存多个说话者(即上述的声源)的声纹特征和说话者姓名(即上述的声源标记)。如果是音视频播放过程,用户选择需要确认的多个说话者的声纹特征。如果是电话过程,则可根据通讯录中的姓名匹配终端设备预存的说话者姓名,从而获取需要确认的说话者声纹特征。启动声纹识别模块,获取声音,该声音可来自音频文件,也可来自外界现场声音。启动声纹特征分析。再将获取的声纹特征与用户选择的说话者声纹特征相匹配。匹配不成功,则不是说话者说的话,则降低此帧音频音量。匹配成功,则启动标记该说话内容的说话者姓名。在音视频播放或电话的每一帧播放时,判断该帧是说话人说的话,还是环境背景音。如果确认是说话者说的话,则保持此帧音频音量为音频播放音量。如果不是说话者说的话,则降低此帧音频音量,从而达到了突出说话人声音的效果。
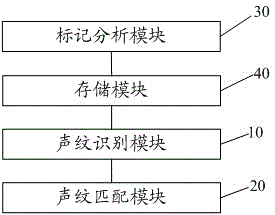
基于上述实施例提供的终端音频播放方法,本发明还提供一种终端音频播放系统。请参阅图2,所述终端音频播放系统包括:
声纹识别模块10,用于对终端待播放的音频数据进行声纹分析,得到对应的声纹特征;
声纹匹配模块20,用于将所述声纹特征与预先设置的声纹特征库进行匹配,若匹配成功,则保持所述音频数据的播放音量;若匹配不成功,则降低所述音频数据的播放音量。
请继续参阅图2,进一步地,所述的终端音频播放系统,还包括:
标记分析模块30,用于预先对多个声源进行标记,并对各个声源的音频数据进行声纹分析,得到对应的声纹特征;
存储模块40,用于将各个声纹特征及其对应声源的声源标记关联存储,生成所述声纹特征库。
进一步地,所述声纹识别模块10包括:
声源选择单元,用于对所述声纹特征库中声源标记进行选择;
声纹分析单元,用于对终端待播放的音频数据进行声纹分析,得到对应的声纹特征。
进一步地,所述声纹匹配模块20包括:
声纹匹配单元,用于将所述声纹特征与选择的声纹特征库进行匹配,若匹配成功,则保持所述音频数据的播放音量;若匹配不成功,则降低所述音频数据的播放音量。
进一步地,所述声纹识别模块10,还用于每隔预定时间对终端待播放的音频数据进行声纹分析,得到对应的声纹特征。
由于所述终端音频播放系统的具体原理和详细技术特征在上述终端音频播放方法实施例中已详细阐述,在此不再赘述。
上述功能模块的划分仅用以举例说明,在实际应用中,可以根据需要将上述功能分配由不同的功能模块来完成,即划分成不同的功能模块,来完成上述描述的全部或部分功能。
本领域普通技术人员可以理解上述实施例方法中的全部或部分流程,是可以通过计算机(或移动终端)程序来指令相关的硬件完成,所述的计算机(或移动终端)程序可存储于一计算机(或移动终端)可读取存储介质中,程序在执行时,可包括上述各方法的实施例的流程。其中的存储介质可以为磁碟、光盘、只读存储记忆体(ROM)或随机存储记忆体(RAM)等。譬如,声纹特征库也可存储在与终端数据交互的服务器中。
综上所述,本发明提供的一种终端音频播放方法及系统,通过对终端待播放的音频数据进行声纹分析,得到对应的声纹特征;将所述声纹特征与预先设置的声纹特征库进行匹配,若匹配成功,则保持所述音频数据的播放音量;若匹配不成功,则降低所述音频数据的播放音量;利用声纹识别技术,确认当前的音频数据与预存的声纹特征不匹配时,则降低环境背景音的音量,以达到当前音频数据的音量明显高于环境背景音的效果,提高了声音清晰度,带来了极大的方便。
可以理解的是,对本领域普通技术人员来说,可以根据本发明的技术方案及其发明构思加以等同替换或改变,而所有这些改变或替换都应属于本发明所附的权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!