一种多摄像头直播方法及系统与流程
本发明涉及网络直播技术领域,尤其涉及一种多摄像头直播方法及系统。
背景技术:
随着高速有线及无线IP网络,大容量数据存储,数字视频压缩以及大规模计算等技术的迅猛发展,基于各类的视频传感器,我们的视觉触角已经被不断延伸到更大的广度和深度。同时,伴随着社交网络的不断发展,人们对可攫取的信息的丰富性的要求日益高涨。因此,富媒体应运而生。而人们对现场实时视频信息的需求愈发突出,视频直播迅速成为最直接最受欢迎的一种富媒体方式。直播通常是指在事件发生的现场同步采集、制作、发布视频(通常包括音频)信息的方式。从传播的本质而言,视频在人与人交互方面具有天然的优势,形态更丰富、信息更多元,能承载更为丰富的情感。直播的内容非常碎片化,打开电脑或手机的直播平台,随时有各种各样的直播场景供人们选择观看。视频直播真正做到去中心化,让任何人都能自由地表达自己。直播视频是人与人并连接最有效途径之一,在传达更丰富情感的同时,让沟通更有效率。由于延迟短,不确定因素会影响剧情发展,大大满足了人们的猎奇心理,这也是直播吸引观众的魅力之一。
2016年视频直播已全面移动化和泛娱乐化。,视频直播全面注入社交基因,运用社交关系或粉丝关系来进行直播已然将直播全面推向大众。其所营造的更新鲜化、生活化、多元化的直播场景,契合全民娱乐审美提升的发展趋势,受到了众多90后、00后用户追捧,爆发已经势不可挡。由腾讯视频制作的网络真人秀节目《我们15个》,15个职业迥异、年龄分布在20~60岁之间的普通人,在120台高清摄像机、360度全景镜头、80个麦克风的环绕下,共同生存一年——这一切,网民都可以通过手机24小时观看。没有剧本、没有预计、没有死角。节目从6月23日开播至7月31日的收视数据:总收视量3.8亿人次,日均收视996万人次,人均观看91分钟。网友们一共发了1000万条“弹幕”,平均下来每分钟都有232条。易观发布的《中国秀场娱乐市场专题研究报告2016》显示,移动互联网催生泛生活类直播,其中,秀场娱乐市场在2016年有望达100亿元。而根据华创证券预估,2020年直播行业市场规模将由2015年的120亿增长到1060亿。
人类史上最早的娱乐节目直播发生在1938年。当时,BBC仅仅让参赛者拼命拼写单词,完成了《拼写蜜蜂》的直播。近80年过去,如今任何人只要有一根网线,就可以完成一场直播,网络上有大批美女主播因此诞生。从技术上讲,直播并不存在任何难度。真正的难处是现场的调度、切播与时间控制。
当前主流直播软件的直播模式为一个主播进行直播,多个观众在该主播的直播间观看直播的方式。但是,目前这种秀场类的直播往往局限于单一直播场景,要么是直接置于电脑处的单一USB摄像头,要么即便是多个摄像头也是单一物理房间内聚焦于一点的多角度摄像头。[1]提出了一种将针对单一直播场景多方位的摄像头多路输出视频在远程进行同步播放的方式,主要通过在每一视频中叠加时间戳并在远程缓冲数据以求得时间戳同步的方式。[2]制作了一种硬件盒子,通过它可以基于红外监测控制直播摄像头的启停,从而保护主播的隐私(当离开直播范围时),并可以将摄像头的开关状态通过指示灯和声音直观展示给主播。[3]实现了一种把多个直播源整合到单一视频流的方法。为了减少硬件投入和安装麻烦,通过自动视频内容侦测技术,[4]提出了一种用分别面向教师和学生的双摄像头方式来取代传统的五摄像头安装方式的方法。[5]通过在所关注直播场景的多个角度架设摄像头的方式,基于视频拼接技术,实现了对直播场景的全景式直播。[6]则实现了一种双主播模式下在两个主播的直播间之间进行快速切换的方式。
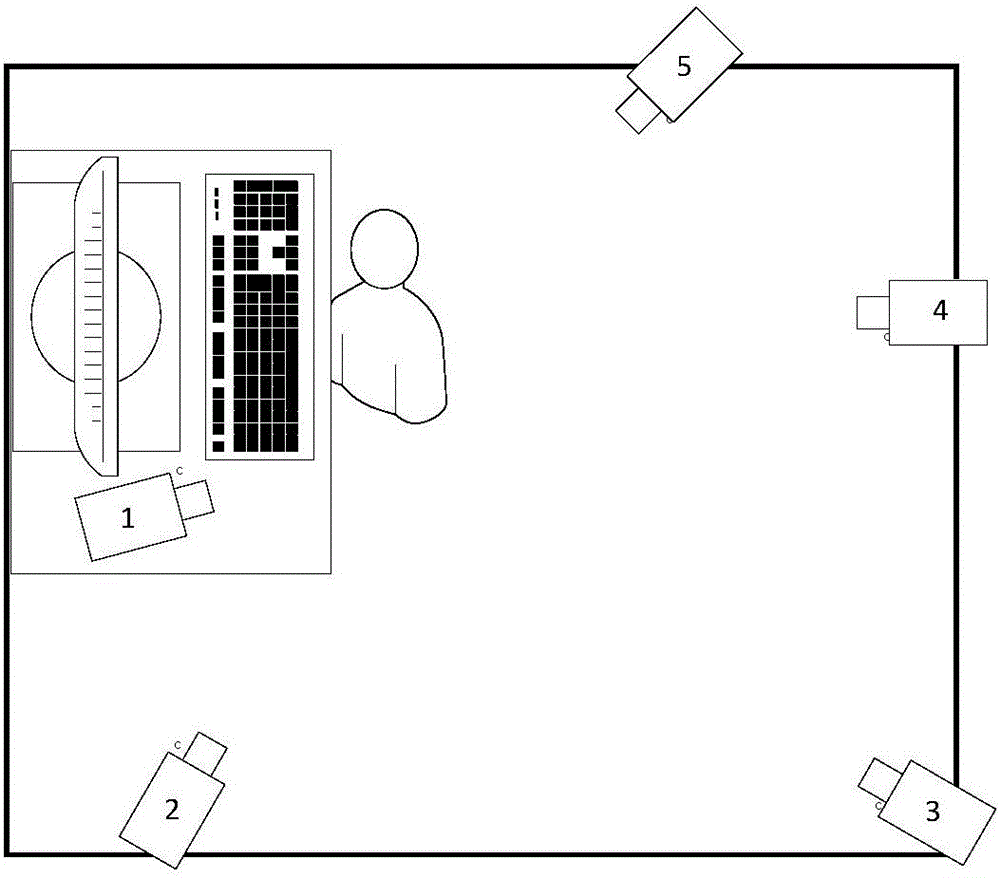
目前的这种单直播场景的直播方式已经大大限制了主播的表演空间和呈现内容(如图1所示)。而[4]提出的方式仅仅局限于教学这一单一形式,[6]则只考虑了两个单空间的切换问题。其实更好的方式是类似真人秀的基于多空间多方位摄像头的方式,也即本发明提出的多位摄像头的方式,这里的多位包含三个含义:1.多摄像头:整个系统包含至少两个或两个以上的摄像头;2.多位置:这些摄像头处于多个离散的位置,比如在两个不同的房间内;3.多方位:这些摄像头的朝向是可以完全不受任何因素影响的,比如不像[4]和[5]需要特别针对技术方案需要精心设计。如图2所示,主播应该可以在多处自由活动,摄像头的安装主要是为了获得尽量无死角的覆盖,而不应该是为了后续的技术解决方法(比如全景重建)考虑。
当然,实现这种类似电视真人秀的直播方式,有一个最大的问题就是必须需要一个导播来迁移视频观众的注意重心。否则如果需要观众时刻面对如图2所示的所有7个摄像头的话,一是会很快失去兴趣(因为一般只有一个有主播而其它的基本是静止画面),二是会浪费大量的带宽(仅仅用来传输无人的画面)。
引用:[1](CN105245977 A)一种多组摄像头同步直播的方法(公示中)。
[2](CN105141847 A)一种电脑摄像头直播用多功能转接设备(实质性审查中);
[3](CN100452033 C)一种实现流媒体直播的方法。
[4](CN105611237 A)一种教学录播用双摄像头模拟五摄像头的方法。(实质性审查中);
[5](CN105847851 A)全景视频直播方法、装置和系统以及视频源控制设备(实质性审查中)。
[6](CN106028166 A)直播过程中直播间切换方法及装置。(实质性审查中)。
技术实现要素:
本发明所要解决的技术问题是针对现有直播需要人为切换摄像头无法保证直播活动的流畅性的问题,而提供一种多摄像头直播方法。
本发明解决上述技术问题的技术方案如下:
一种多摄像头直播方法,包括如下步骤:
S1、在直播场景内,固定至少两个深度摄像头,通过深度摄像头获取各直播场景的背景深度值并存储;
S2、通过深度摄像头获取主播的当前位置深度图像,根据深度图像生成最佳深度摄像头序号,将直播画面切换至最佳深度摄像头画面;
S3、持续通过深度摄像头获取的深度图像、检测主播位置是否发生变化,当主播位置变化时返回步骤S2。
进一步地,所述S2中通过深度摄像头获取主播当前位置的方式为:通过深度摄像头获取主播当前位置深度,标记主播当前位置深度与直播场景背景深度不一致的区域为主播覆盖区域,选取主播覆盖区域面积最大的深度摄像头为最佳摄像头。
进一步地,所述S2中通过深度摄像头获取主播当前位置的方式为:
记录人为主观标定出的主播在不同位置深度时对应的最佳摄像头序号;直播时通过深度摄像头获取主播当前位置深度,再根据记录的人为标定结果生成最佳摄像头序号。
进一步地,所述步骤S2还包括自动插播:当所有深度摄像头检测到主播所在区域的深度值均为背景深度值时,自动插播备用直播信号;当重新检测到主播时,切换回最佳深度摄像头画面。
本发明还提供了一种多摄像头直播系统,包括存储模块、摄像头组、存储模块、处理器,
所述摄像头组包括至少两个用于获取直播画面及主播区域深度的深度摄像头;
所述存储模块用于存储各个直播场景的背景深度值;
所述处理器用于接收所述摄像头组得到的深度图像,通过所述深度图像随时监测主播是否在处于盲区,当主播不处于盲区时判断出当前最佳深度摄像头序号;
进一步地,所述处理器用于通过所述深度图像标记主播当前位置深度与直播场景背景深度不一致的区域为主播覆盖区域,选取主播覆盖区域面积最大的深度摄像头为最佳摄像头。
进一步地,所述存储模块还用于存储人为主观标定出的主播在不同位置深度时对应的最佳摄像头序号;所述处理器用于根据所述深度图像以及存储的人为标定结果生成最佳摄像头序号。
进一步地,所述存储模块还用于存储备用直播资源;所述处理器还用于根据所述深度图像中深度值均为背景深度值时,调用备用直播资源;当所述处理器重新检测到主播时,将直播画面切换至最佳深度摄像头画面。
本发明自动实现了最佳摄像头的切换,在网络主播多种与观众互动过程中自动保持直播过程的流畅性,有利于网络主播提高直播的效率,并在网络主播暂时离开摄像头前时,自动插播其他内容。
附图说明
图1为单房间直播场景示意图;
图2为多房间直播场景示意图;
图3为本发明基本流程示意图。
具体实施方式
以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
如附图3所示,一种多摄像头直播方法,包括如下步骤:
S1、在直播场景内,固定至少两个深度摄像头,通过深度摄像头获取各直播场景的背景深度值并存储;
深度摄像头采用彩色/深度摄像头(RGBD摄像头)获取直播场景中的深度图像,通过骨架检测技术(开源的OpenNI/NiTE技术)找到当期主播所在的准确位置。
由于主播所在直播场景光照以及主播衣着,发型造型变化大,且摄像头拍摄视角在不同主播平台中变化较大。如果利用普通的RGB摄像头,通过传统图像识别技术(如HOG+SVM技术或HOG+Adaboost技术),很难准确识别出主播人来。因此本发明选用同时能获取彩色与深度信息的RGBD摄像头,配合上骨架检测技术(选用开源的OpenNI/NiTE技术),利用深度数据及NiTE训练好的骨架识别器识别出各种角度与姿势下的主播位置。
RGBD摄像头同时还能提供不同分辨率的RGB信息,用户可以根据具体要求选用,如果需要高分辨率的,还可以选择微软公司的KinectV2作为RGBD摄像头。
为了降低成本,本发明专利选用了华硕的xtionproLive彩色/深度摄像头,也可采用其他厂商深度摄像头如KinectV1,KinectV2。由于骨架追踪技术是一种鲁棒性的技术,因此主播可以采用坐,站立等多种姿势,不受限制。
S2、通过深度摄像头获取主播的当前位置深度图像,根据深度图像生成最佳深度摄像头序号,将直播画面切换至最佳深度摄像头画面;
S3、持续通过深度摄像头获取的深度图像、检测主播位置是否发生变化,当主播位置变化时返回步骤S2。
所述S2中通过深度摄像头获取主播当前位置的方式为:通过深度摄像头获取主播当前位置深度,标记主播当前位置深度与直播场景背景深度不一致的区域为主播覆盖区域,选取主播覆盖区域面积最大的深度摄像头为最佳摄像头。
实际操作中,由于事先安装摄像头的时候有一种成本考虑,因此各个摄像头间的重叠区域面积较少。因此可以根据主播所占的面积多少来决定哪一个摄像头是最佳摄像头。比如图2中右下角所示房间中有2个摄像头,虽然两个摄像头的区域有一定重叠,但重叠面积较少,但主播接近摄像头7的时候,在摄像头7的画面中存在的图像面积较大,同时通过深度信息也能进一步确认距离,这个时候就选取摄像头7为最佳摄像头。
所述S2中通过深度摄像头获取主播当前位置的方式为:
记录人为主观标定出的主播在不同位置深度时对应的最佳摄像头序号;直播时通过深度摄像头获取主播当前位置深度,再根据记录的人为标定结果生成最佳摄像头序号。
多摄像头直播方法还包括自动插播:当所有深度摄像头检测到主播所在区域的深度值均为背景深度值时,即判断出主播处于所有深度摄像头的拍摄盲区,并自动插播备用直播信号:
即利用深度摄像头,通过对检测到的主播骨骼所在位置的深度信息进行不断评测,当主播所在区域的深度值为背景深度值时,可判断主播离开了所在位置。选用深度做上述前景运动检测的原因是深度信息不易受环境光照,阴影的影响。因为在主播室内主播动作会不断改变及光照也会不断变化(跳舞时的光照变化很严重),因此传统基于RGB摄像头做前景运动检测是不能用的。这也是本发明专利的一个特色。当上述通过前景检测技术检测到主播位置发生变化时(即主播离开了该出现的位置范围),则判断其他摄像头对应的区域是否出现有效骨架。如果发现了有效的人体骨架,说明有主播存在,再找到最适合的摄像头,然后迅速切换到该摄像头。在主播处于盲区位置(即不在任何摄像头所覆盖范围内时候)自动插播图像类广告(单幅宣传用的图像)。
本发明还提供了一种多摄像头直播系统,包括存储模块、摄像头组、存储模块、处理器,
所述摄像头组包括至少两个用于获取直播画面及主播区域深度的深度摄像头;
所述存储模块用于存储各个直播场景的背景深度值;
所述处理器用于接收所述摄像头组得到的深度图像,通过所述深度图像随时监测主播是否在处于盲区,当主播不处于盲区时判断出当前最佳深度摄像头序号。
所述处理器用于通过所述深度图像标记主播当前位置深度与直播场景背景深度不一致的区域为主播覆盖区域,选取主播覆盖区域面积最大的深度摄像头为最佳摄像头。
所述存储模块还用于存储人为主观标定出的主播在不同位置深度时对应的最佳摄像头序号;所述处理器用于根据所述深度图像以及存储的人为标定结果生成最佳摄像头序号。
所述存储模块还用于存储备用直播资源;所述处理器还用于根据所述深度图像中深度值均为背景深度值时,调用备用直播资源。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!