一种基于物联网大数据的设备信息采集系统及方法与流程
技术领域
本发明涉及计算机技术领域,具体地说是一种基于物联网大数据的设备信息采集系统及方法。
背景技术:
在实际项目开发中经常会遇到类似问题,例如:需要给手机用户推送一条服务信息,或者使用手机控制税控机或者其他硬件设备。但是在现有技术层面(TCP、HTTP、Socket等)没有符合相应技术要求的技术。因此MQTT协议就成为完成上述技术比较好的解决方案。因为MQTT协议相对于其他协议来说更轻量级,网络流量消耗极少(以字节为单位),对于客户机(手机、税控机等)耗电量得到很好控制。
MQTT协议是指消息队列遥测传输,协议支持所有平台,几乎可以把所有联网物品和外部连接起来,该协议特点,使用发布/订阅消息模式,提供一对多的消息发布,解除应用程序耦合;对负载内容屏蔽的消息传输;使用 TCP/IP 提供网络连接;小型传输,开销很小。
但是如果没有合适的框架系统,用户使用EMQTT与数据结合分析时会遇到种种繁琐的问题。第一客户需要关心安全问题,因为EMQTT的服务器是部署在外网,需要很高的安全性为了防止数据的丢失与泄漏;而且对于重新开发一套大数据Hadoop模型与EMQTT模型的结合费事费力,有很多无用功浪费在研究与封装上面。
基于此,现提供一种基于物联网大数据的设备信息采集系统及方法,使用该平台框架用户直接接入即可,安全性与数据结合分析都由框架完成用户不必操心,只需要专注于业务逻辑的实现即可。
同时随着物联网时代的到来,人工智能为当今社会生活提供的巨大的便利。本方案主要结合互联网时代,为发票开具终端、离境退税终端开具终端设计,同时可适用于具有该特点的所有系统。目前中国发票的多样性,电子发票,网络发票,电脑终端利用设备开具的增值税发票等。传统的设备终端开具系统都是利用传统的http协议服务,传输为单项传输,数据协议复杂,大量带宽被无意义的结构化数据信息占用。同时,http服务支撑的终端有限。该方案能够将互联网开票终端的数据实时采集,同时服务端控制终端上传数据不再是单项数据传递。
技术实现要素:
本发明的技术任务是针对以上不足之处,提供一种基于物联网大数据的设备信息采集系统及方法。
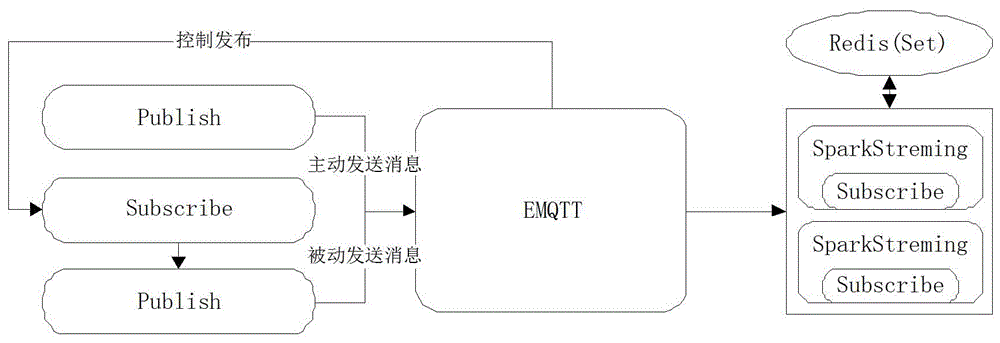
一种基于物联网大数据的设备信息采集系统,包括客户端和服务端,所述服务端采用开源的EMQTT服务集群,通过长连接的方式与客户端连接通信,客户端可以请求服务端也可以实时向服务端发送信息,相反服务端也可以请求客户端实时向客户端发送信息。
所述服务端的EMQTT服务集群中,部署有Redis缓存数据库;安装Kafka消息队列;集成安装hadoop组件,包括HDFS、hbase、zookeeper、Spark;且该EMQTT服务集群配置Nginx反向代理。
在服务端中,通过MQTT的长连接,实时获取终端设备的行为数据,并控制终端设备的行为;Hadoop 组件用于数据实时收集存储,通过MQTT的消息队列,将终端产生的高并发数据,匀化处理使后端接入的数据监听任务工作更具有稳定性;Redis缓存数据库作为数据暂存的临时位置,保证数据的重复传递,并通过Redis的haset存储类型去重。
所述客户端上配置有对应MQTT的发布和订阅消息模块,使得服务端实现订阅监听各客户端发布主题,并存入Redis中,这里的客户端包括移动终端、配置有传感器的终端设备。
一种基于物联网大数据的设备信息采集方法,基于上述系统,其采集过程为:
首先将客户端实时产生的数据信息,实时推送到EMQTT服务集群;
EMQTT服务集群接收到数据信息后,进行SparkStreaming流式计算;
然后将计算后的数据采集到分布式数据库Hbase进行存储,并通过Redis缓存数据库处理接收订阅重复数据的问题。
当客户端进行订阅或发布操作时,均通过Nginx反向代理有效隐藏后端服务的地址,然后通过地址映射连接到服务端后由EMQTT解析客户端发来的信息,将信息存入Redis缓存数据库处理接收订阅重复数据的问题。
在数据存入Redis缓存数据库后,将信息存入Hadoop大数据分析模型,进行下一步的分析操作:在Hadoop模型下通过SparkStreaming流式计算,将数据采集到分布式数据库Hbase进行存储,完成一次数据的逻辑交互于实时分析,当客户端订阅后收到服务端的指令信息,根据这些指令客户端会做出相应逻辑动作。
所述指令信息是根据服务端SparkStreaming流失计算得到指令结果,将这些指令结果推回到服务端,再次根据EMQTT框架代理服务器将指令消息推送给NIGNX反向代理服务器,然后NIGNX反向代理服务器根据对应地址找到相应客户端,当客户端收到对应的指令信息后即可做出对应逻辑动作。
本发明的一种基于物联网大数据的设备信息采集系统及方法和现有技术相比,具有以下有益效果:
本发明的一种基于物联网大数据的设备信息采集系统及方法,解决传感器、移动终端的数据在有限的带宽同时节省电量的情况下完成实时采集,适用于大并发,支持百万级传输终端,保证采集数据的实时,唯一和存储,实用性强,适用范围广泛,具有很好的推广应用价值。
附图说明
附图1是本发明实现示意图。
附图2为本发明的逻辑实现图。
具体实施方式
下面结合附图及具体实施例对本发明作进一步说明。
本发明基于物联网、大数据技术,集成搭建一套设备数据实时(控制)采集。利用EMQTT开源服务体系和hbase、spark等hadoop生态圈组件,将设备实时产生的数据信息,实时推送到EMQTT服务,并通过SparkStreaming流式计算,准实时的将数据采集到分布式数据库Hbase进行存储,并通过Redis缓存数据库处理接收订阅重复数据的问题。(如果不进行重复处理,该架构为了保证数据的传递过程中不丢失,客户端publish数据是采用至少发送一次的机制,而流式计算集群模式下很容易将数据采集重复造成冗余,故加入Redis缓存以采集的数据Rowkey,防止重复)。
如附图1、图2所示,一种基于物联网大数据的设备信息采集系统,包括客户端和服务端,所述服务端采用开源的EMQTT服务集群,通过长连接的方式与客户端连接通信,客户端可以请求服务端也可以实时向服务端发送信息,相反服务端也可以请求客户端实时向客户端发送信息。
所述服务端的EMQTT服务集群中,部署有Redis缓存数据库;安装Kafka消息队列;集成安装hadoop组件,包括HDFS、hbase、zookeeper、Spark;且该EMQTT服务集群配置Nginx反向代理。
在服务端中,通过MQTT的长连接,实时获取终端设备的行为数据,并控制终端设备的行为;Hadoop 组件用于数据实时收集存储,通过MQTT的消息队列,将终端产生的高并发数据,匀化处理使后端接入的数据监听任务工作更具有稳定性;Redis缓存数据库作为数据暂存的临时位置,保证数据的重复传递,并通过Redis的haset存储类型去重。
所述客户端上配置有对应MQTT的发布和订阅消息模块,使得服务端实现订阅监听各客户端发布主题,并存入Redis中,这里的客户端包括移动终端、配置有传感器的终端设备。
本系统利用了MQTT的长连接,可实时获取终端网关设备的各项行为数据,并可以控制终端的各项行为。因为终端设备和服务端是长连接,实现服务端对设备终端的控制。
Hadoop hbase组件作为数据实时收集存储的,能够支撑pb级数据存储和检索,利用MQTT的消息队列机制,将终端产生高并发数据,匀化处理使后端接入的数据监听任务工作更具有稳定性。
Redis作为数据暂存的临时位置,保证数据的重复传递,利用Redis的haset存储类型去重,既保证了数据的唯一,有保证的数据的及时传递。
在本发明中,除平台之外最重要的是对NINGX反向代理服务器、EMQTT与Hadoop大数据系统的整合封装,对应的有2个模块,一个为EMQTT与Redis分装;一个为Hadoop大数据模块封装。
首先在客户端有主动发布指令与被动指令,无论哪一种都以赋予EMQTT服务器,指令消息通过MQTT协议传输的服务器后根据订阅指令信息的不同会写入到Redis中,为解决重复指令问题做数据存储。
存入Redis后Hadoop中的SparkStreming流式计算既可以在其中获取指令进行分析处理,因为在Redis中做了指令冗余处理所以在智力可以直接使用。
经过计算分析之后得到最终结果可以将其存入Hbase中或者将数据指令再次返回给客户端,这样整个业务逻辑框架可以无缝连接,并且大大提高安全性与易用性,为客户节省不必要的开发时间,将大部分精力都放在自己的业务逻辑开发上。
上述系统的实际搭建过程为:
1、EMQTT下载最新开源包编译安装,部署多个节点集群;配置EMQTT集群。
2、部署Redis缓存数据库;
3、安装Kafka消息队列;
4、集成安装hadoop组件,HDFS,hbase,zookeeper,Spark;
5、为EMQTT集群配置Nginx反向代理。
6、各客户端开发针对MQTT的发布和订阅消息(定义主题)。
7、服务平台实现订阅,监听各客户端发布主题,并存入Redis中;
8、实现SparkStreming任务,读取Redis任务写入Hbase中。
一种基于物联网大数据的设备信息采集方法,基于上述系统,其采集过程为:
首先将客户端实时产生的数据信息,实时推送到EMQTT服务集群;
EMQTT服务集群接收到数据信息后,进行SparkStreaming流式计算;
然后将计算后的数据采集到分布式数据库Hbase进行存储,并通过Redis缓存数据库处理接收订阅重复数据的问题。
当客户端进行订阅或发布操作时,均通过Nginx反向代理有效隐藏后端服务的地址,然后通过地址映射连接到服务端后由EMQTT解析客户端发来的信息,将信息存入Redis缓存数据库处理接收订阅重复数据的问题。
在数据存入Redis缓存数据库后,将信息存入Hadoop大数据分析模型,进行下一步的分析操作:在Hadoop模型下通过SparkStreaming流式计算,将数据采集到分布式数据库Hbase进行存储,完成一次数据的逻辑交互于实时分析,当客户端订阅后收到服务端的指令信息,根据这些指令客户端会做出相应逻辑动作。
所述指令信息是根据服务端SparkStreaming流失计算得到指令结果,将这些指令结果推回到服务端,再次根据EMQTT框架代理服务器将指令消息推送给NIGNX反向代理服务器,然后NIGNX反向代理服务器根据对应地址找到相应客户端,当客户端收到对应的指令信息后即可做出对应逻辑动作。
首先客户端上可以进行订阅/发布操作,无论是订阅还是发布都需要通过NIGNX,利用Nginx反向代理有效的隐藏了后端服务的地址,这样可以大大提高系统以及框架的安全性,避免了很多不必要的黑客与网络攻击。
然后通过地址映射连接到服务器后EMQTT解析客户端发来的信息,将信息存入Redis缓存数据库处理接收订阅重复数据的问题。处理完数据之后将信息存入Hadoop大数据分析模型,进行下一步的分析操作。
在Hadoop模型下通过SparkStreaming流式计算,准实时的将数据采集到分布式数据库Hbase进行存储,完成一次数据的逻辑交互于实时分析。
当客户端订阅后会收到服务端的指令信息,根据这些指令客户端会做出相应逻辑动作。而这些指令信息也是根据服务端SparkStreaming流失计算得到指令结果,将这些指令结果推回到服务端,再次根据EMQTT框架代理服务器将指令消息推送给NIGNX反向代理服务器,然后服务器根据对应地址找到相应客户端,当客户端收到对应的指令信息后即可做出对应逻辑动作。
该技术方案中采用了开源的EMQTT服务,该服务集群可以支撑百万级网络终端设备实时在线连接,该连接为长连接。这样相当于服务端和客户端建立了一个通道,客户端可以请求服务端也可以实时向服务端发送信息,相反服务端也可以请求客户端实时向客户端发送信息。传统的http服务只能实现客户端向服务端发送请求和传递数据。服务端只能被迫应答客户端。
利用Nginx反向代理有效的隐藏了后端服务的地址,同时将客户端的请求和监听进行了软负载(EMQTT集群同样具有负载能力),进一步加大了系统的稳定性,服务端的监听客户端上传的数据信息,接收到后进入Redis临时存储,HSet保证数据唯一。Spark将存入Redis数据进行抽取进入HBase列式数据库。
通过上面具体实施方式,所述技术领域的技术人员可容易的实现本发明。但是应当理解,本发明并不限于上述的具体实施方式。在公开的实施方式的基础上,所述技术领域的技术人员可任意组合不同的技术特征,从而实现不同的技术方案。
除说明书所述的技术特征外,均为本专业技术人员的已知技术。
- 还没有人留言评论。精彩留言会获得点赞!