一种图像处理设备的制作方法
本发明涉及一种图像处理设备,特别涉及一种用于处理经过编码转换的压缩图像的图像处理设备。
背景技术:
近年来,随着社交媒体网站和照片共享网站的日渐普及,不断增加的用户每天都要上传大量的图像数据。因此,经营此类网站的运营商,期望能够高速而且大量地存储上传的图像。
然而,尽管所产生信息的堆积量在不断增加,但人们给予这些信息的时间或关注则是有限的资源(非专利文献1)。因此,实际上能够获得访问、并由用户浏览的图像仅仅为大量被保存的图像中的一部分。也就是说,在用户上传的图像量和用户下载(被访问阅览)的图像量之间存在不对称的关系。为此,网站运营商有必要采取使整体数据存储费用最小化的方法。
这里,非专利文献2公开了有关稀疏信号(sparsesignal)和稀疏模型(sparsitymodel)的技术,而非专利文献3和4公开了与逆量化有关的技术。
另外,例如非专利文献5~8中还公开了有关云计算存储的图像压缩相关技术。非专利文献5公开了通过sift描述符重建来自大型图像数据库的图像的技术。非专利文献6公开了改良的用于压缩相册的技术,其不是通过分析和搜索图像间相关性的像素值的搜索、而是通过局部特征的搜索来实现的。
非专利文献7公开了一项有关新型云计算数据库分配图像编码方案的技术。
另外,非专利文献8公开了有关jbig的技术。
在这里,专利文献1公开了一种用于提高压缩数据压缩度的jpeg图像代码转换相关技术。另外,专利文献2公开了一项图像处理设备相关技术:该设备用于将图像数据作为数据包进行处理,从而实时将图像数据作为存储器存储容量范围内的数据量进行压缩。
【现有技术文献】
【专利文献】
【专利文献1】特表2006-501736号公报
【专利文献2】特开2003-244446号公报
【非专利文献】
【非专利文献1】d.j.levitin,theorganizedmind:thinkingstraightintheageofinformationoverload,penguin,2014.
【非专利文献2】m.elad,m.a.t.figueiredo,andy.ma,“ontheroleofsparseandredundantrepresentationsinimageprocessing,”proc.ieee,vol.98,no.6,pp.972-982,june2010.
【非专利文献3】x.liu,g.cheung,x.wu,andd.zhao,“inter-blocksoftdecodingofjpegimageswithsparsityandgraphsignalsmoothnesspriors,”inieeeinternationalconferenceonimageprocessing,quebeccity,canada,september2015.
【非专利文献4】x.liu,x.wu,j.zhou,andd.zhao,“data-drivensparsity-basedrestorationofjpeg-compressedimagesindualtransform-pixeldomain,”inieeeconferenceoncomputervisionandpatternrecognition(cvpr),june2015.
【非专利文献5】h.yue,x.sun,j.yang,andf.wu,“cloud-basedimagecodingformobiledevices-towardthousandstoonecompression,”ieeetrans.multimedia,vol.15,no.4,pp.845-857,june2013.
【非专利文献6】z.shi,x.sun,andf.wu,“photoalbumcompressionforcloudstorageusinglocalfeatures,”ieeej.emerg.sel.topiccircuitssyst.,vol.4,no.1,pp.17-28,mar.2014.
【非专利文献7】x.song,x.peng,j.xu,g.shi,andf.wu,“cloudbaseddistributedimagecoding,”ieeetrans.circuitssyst.videotechnol.,vol.26,no.6,pp.1-1,june2016.
【非专利文献8】f.ono,w.rucklidge,r.arps,andc.constantinescu,“jbig2-theultimatebi-levelimagecodingstandard,”inieeeinternationalconferenceonimageprocessing,vancouver,canada,september2000.
【非专利文献9】xianmingliu,genecheung,xiaolinwu,debinzhao,"randomwalkgraphlaplacianbasedsmoothnesspriorforsoftdecodingofjpegimages,"acceptedtoieeetransactionsonimageprocessing,october2016.(arxiv)
【非专利文献10】m.eladandm.aharon,“imagedenoisingviasparseandredundantrepresentationoverlearneddictionaries,”inieeetransactionsonimageprocessing,vol.15,no.12,december2006.
【非专利文献11】j.pang,g.cheung,w.hu,ando.c.au,“redefiningself-similarityinnaturalimagesfordenoisingusinggraphsignalgradient,”inapsipaasc,siemreap,cambodia,december2014.
【非专利文献12】a.gershoandr.m.gray,vectorquantizationandsignalcompression.norwell,ma,usa:kluweracademicpublishers,1991.
【非专利文献13】l.y.weiandm.levoy,“fasttexturesynthesisusingtree-structuredvectorquantization,”insiggraph’00:proceedingsofthe27thannualconferenceoncomputergraphicsandinteractivetechniques.newyork,ny,usa:acmpress/addison-wesleypublishingco.,2000,pp.479-488.[online].available:http://dx.doi.org/10.1145/344779.345009
【非专利文献14】k.ramchandranandm.vetterli,“bestwaveletpacketbasesinarate-distortionsense,”ieeetransactionsonimageprocessing,vol.2,no.2,pp.160-175,apr1993.。
技术实现要素:
在此,在上述专利文献1所述的代码转换过程中,存在下述问题:解码时,难以实现从粗量化二进制索引(第2次量化产生的量化系数)到密量化二进制索引(第1次量化产生的量化系数)的逆映射(量化数据仓库匹配(qbm,quantizationbinmatching)。
另外,非专利文献5~8中记载的技术,不能保证用户上传的原始图像的正确恢复。
本发明的目的是提供一种图像处理系统以解决上述问题,该图像处理系统在进行解码时,实现高压缩率的同时,保证用户可以接受的图像质量。
根据本发明第1方面提供的图像处理设备,其特征在于,
具备一逆映射单元,用于关于从第1量化系数进行的基于第2量化宽度的量化的第2量化系数,向第1量化系数进行逆映射,所述第1量化系数为将输入图像进行基于第1量化宽度的量化,所述第2量化宽度比第1量化宽度更宽;
所述逆映射单元,
从所述第2量化宽度范围内的所述第1量化系数的备选项中,基于先验概率(priorprobability)选择能够使量化单元量最大化的量化系数,将其作为所述第1量化系数来进行所述逆映射。
根据本发明的第2个方面提供的图像处理设备,其特征在于,具备
一过度完备字典(overcompletedictionary),用于根据多个图像的特征量的分布分类到多个群集;
一稀疏(sparse)图表模板,用于图表化所述特征量的分布,分类到所述多个群集;
一学习单元,用于从所述多个图像学习所述过度完备字典和所述稀疏图表模板;
一再编码单元,用于对于包括第1量化系数的编码图像,基于比所述第1量化宽度更大的第2量化宽度,从所述第1量化系数再编码至第2量化系数,所述第1量化系数为将输入图像基于第1量化宽度进行量化;
和一逆映射单元,用于对于所述第2量化系数,使用所述过度完备字典和所述稀疏图表模板,向所述第1量化系数进行逆映像;
所述学习单元,对于从所述多个图像抽取的多个块图像,通过tsvq(tree-structuredvectorquantization)分类至多个群集,构建二叉树,为了减少对于所述分类的各群集的群集索引的偏移,替换所述二叉树的节点,对于所述替换后的所述二叉树进行修剪,以使比率失真最优化,对于所述修剪后的所述二叉树,学习所述过度完备字典和所述稀疏图表模板;
所述再编码单元,进行再编码时,将群集索引保存在对应于所述第2量化系数的存储设备中,所述群集索引,进行再编码时,用于判断所述输入图像与所述学习后的所述过度完备字典及所述稀疏图表模板的哪个群集相符合;
所述逆映射单元,基于与所述第2量化系数关联的所述群集索引确定所述过度完备字典及所述稀疏图表模板内的群集,使用该确定的群集进行所述逆映射。
本发明能够提供一种图像处理系统,这种图像处理系统不仅可以实现高压缩率,还能在解码时保证用户可以接受的图像质量。
附图说明
图1是根据本发明实施例1表示云存储系统的全部构成的框图。
图2是根据本发明实施例1表示说明图像上传时流程的顺序图。
图3是根据本发明实施例1表示说明图像下载时流程的顺序图。
图4是根据本发明实施例1表示说明qbm解决方案的概念的图。
图5是根据本发明实施例1表示说明粗密转换处理(量化数据仓库匹配)之流程的流程图。
图6是根据本发明实施例1表示压缩增益之实例的示意图。
图7是根据本发明实施例1表示比率失真性能压缩之实例的示意图。
图8是根据本发明实施例1表示比率失真性能压缩之实例的示意图。
图9是根据本发明实施例1表示比率失真性能压缩之实例的示意图。
图10是根据本发明实施例2表示说明对于块内像素进行的密量化与粗量化之间关系的图。
图11是根据本发明实施例3表示图像处理系统之全部构成的框图。
图12是根据本发明实施例3表示说明粗密转换处理之流程的流程图。
图13是根据本发明实施例3表示利用bagofvisualwords(bovw)之情况下概念的示意图。
图14是根据本发明实施例3表示在某图像上特征量分布之实例的示意图。
图15是根据本发明实施例4表示云存储系统之全部构成的框图。
图16是根据本发明实施例4表示说明脱机学习之流程的图。
图17是根据本发明实施例4表示稀疏图表模板之实例的示意图。
图18是根据本发明实施例4表示说明通过脱机学习生成的树之概念的图。
图19是表示说明子空间检索的图。
图20是表示说明替换二叉树节点的图。
图21是表示说明比较二进制位分配前后索引偏移之概率分布的示意图。
图22是表示说明微分计数器之概念的图。
图23根据本发明实施例4表示码书设计算法之实例的示意图。
具体实施方式
以下,参照附图详细说明适用本发明的具本实施方式。在各附图中,相同的要素用相同的符号表示,为了说明的清楚明确,如有必要则省略重复说明。
<实施例1>
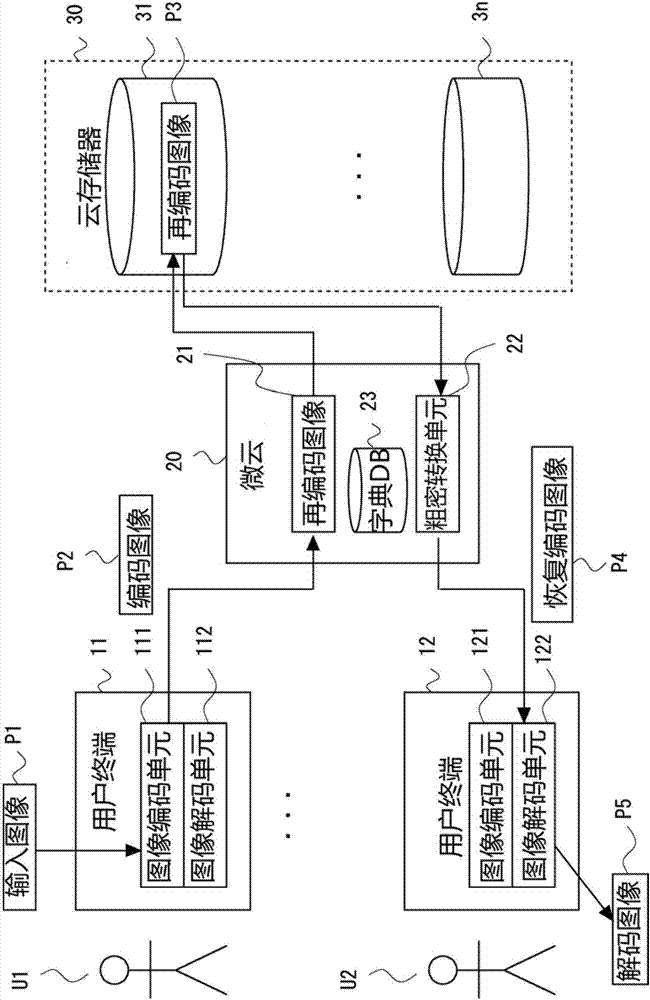
图1是根据本发明实施例1表示云存储系统的整体结构的框图。云存储系统具备用户终端11和12等、微云20和云存储器30。用户终端11通过网络(未图示)与微云20连接。
用户终端11是用户u1操作的信息处理终端,例如手机、智能手机、平板电脑终端、pc机等。用户终端11具备图像编码单元111和图像解码单元112。图像编码单元111对于用照相机等拍摄的输入图像,使用量化参数(quantizationparameters(qp))q进行jpeg的编码,从而生成编码图像p2。也就是说,编码图像p2是对于输入图像p1的压缩数据。本实施例中,用户终端11可以将编码图像p2上传到微云20。图像解码单元112可以对使用jpeg编码的图像解码后用于显示。
用户终端12是用户u2操作的信息处理终端。用户终端12具备与用户终端11相同构成的图像编码单元121及图像解码单元122。用户终端12在从微云20下载用jpeg编码的图像、即恢复编码图像p4的情况下,使用量化参数q进行jpeg的解码,输出(显示等)解码图像p5。
微云20是用1台以上计算机设备实现的云服务器。微云20通过网络与用户终端11等和云存储器30连接。微云20具备再编码单元21、粗密转换单元22和字典db23。字典db23是解码过程中存储参考信息的数据库。
对于编码图像p2,再编码单元21使用比qpq更粗的(幅宽的)q进行再编码,从而生成再编码图像p3。接下来,微云20将再编码图像p3发送并保存至云存储器30。
粗密转换单元22是逆映射单元的一个实例,按照从用户终端12发出的图像请求,从云存储器30获得再编码图像p3,基于字典db23对再编码图像p3进行粗密转换(量化数据仓库匹配),从而将p3恢复成恢复编码图像p4,再将p4返回到用户终端12。
云存储器30是具备多个永久性存储器31~3n的云计算型存储器,也称作中央云。云存储器30通过网络与微云20连接。例如,存储器31中保存了上述再编码图像p3。
图2是根据本发明实施例1表示说明图像上传时流程的顺序图。首先,用户终端11对于输入图像p1使用qpq进行jpeg编码,从而生成编码图像p2(s101)。具体地,图像编码单元111对于输入图像p1使用dct(discretecosinetransform离散余弦变换)转换为dct系数。接下来,图像编码单元111使用量化参数(qp)q进行量化,从dct系数转换为量化系数。也就是说,图像编码单元111对于每个n像素的代码块m,使用qpq=[q1,...,qn]来计算量化索引集合a(m)=[a1(m),...,an(m)]。另外,以后也有将a(m)表达为“密(fine)量化二进制索引a”的情况。然后,图像编码单元111对于量化系数通过熵编码转换为代码数据。也就是,编码图像p2中包含了密量化二进制索引a。另外,“量化参数”也可称为“量化表”或“量化宽度”。
接下来,用户终端11将编码图像p2(密量化二进制索引a)上传到微云20(s102)。微云20的再编码单元21,对于接收到的编码图像p2,使用qpq进行jpeg再编码,将其转换为再编码图像p3(s103)。具体地、再编码单元21,按照每个代码块m,使用qpq=[q1,...,qn],将各a(m)映射到对应的量化索引集合b(m)=[b1(m),...,bn(m)]中,按顺序进行再编码。这里,qpq比上述q要粗些(coarser),也就是量化宽度较大。换言之,qpq比q更精细(fine),也就是说量化宽度较小。另外,以后,也有将b(m)表达为“粗(coarse)量化二进制索引b”的情况。另外,关于jpeg的再编码,例如,可以采用专利文献1的方法。
在这里,从a(m)到b(m)的映射,可能不是唯一的方式。例如,再编码单元21在对各像素的量化系数进行再编码时,一旦使用qpq进行量化后,在能够确认可以进行解码,进行可逆转换的情况下,实际上,在对该像素进行再编码,而不进行可逆转换时,是使用qpq的状态。此时,为了估计原始信号,例如,可以使用非专利文献3的逆量化处理,即,粗量化二进制索引b,一部分使用粗qpq进行量化(再编码),而剩余部分仍保持了使用精细的qpq进行的量化的状态。
接下来,微云20将再编码图像p3(粗量化二进制索引b)保存到云存储器30(s104)。
图3是根据本发明实施例1表示说明图像下载时流程的顺序图。在这里,已经通过图2所示的处理,将再编码图像p3在云存储器30中保存完毕。
首先,用户终端12通过用户u2的操作,将相当于输入图像p1之图像的请求发送至微云20(s201)。接下来,微云20对于云存储器30进行再编码图像p3的搜索(s202)。然后,微云20从云存储器30获得再编码图像p3(粗量化二进制索引b),作为图像的搜索结果(s203)。
这里,微云20的粗密转换单元22参考字典db23来实施将各个b(m)转换回a(m)的逆映射,即通过粗密转换恢复为恢复编码图像p4(密量化二进制索引a*)(s204)。也就是说,由粗的qpq恢复成更为精细的qpq。然后,粗密转换单元22将恢复编码图像p4发送至用户终端12。即,用户终端12下载恢复编码图像p4(s205)。然后,用户终端12的图像解码单元122,对于恢复编码图像p4使用量化参数q进行jpeg的解码(s206)。通过此项操作,用户终端12可以进行解码图像p5的显示等。
如上所述的本发明实施例1,通过权衡为保存全部图像而发生的存储成本与为了对全部图像的一小部分进行解码(逆映射)而发生的计算成本,可以称为有效的云存储系统。也就是说,首先,永久的存储,将上传的jpeg图像使用粗量化参数(qp)进行再编码,通过保存再编码图像,削减了存储成本。然后,对于请求图像,通过将再编码图像从粗量化二进制索引逆映射到密量化二进制索引,在用户终端侧进行通常的解码。此时,为了进行再编码图像的逆映射处理,虽然需要花费比通常更高的计算成本,但正如上面所述,尽管要求保存的图像数量很大,实际上被请求阅览的图像仅仅是一小部分。因此,即使加上解码过程中发生的计算成本,也可以说削减存储成本的意义更大。
然后,从用户侧的观点来看,最终解码显示的图像,与当初上传的图像相比,可以称为相同水平的密量化二进制索引的图像。也就是说,通过保持人眼无法区别的视觉品质,可以提供与典型云存储器同等的服务水平。另一方面,从运营商的观点来看,通过保存前进行再编码,能够保存比最初更粗的粗量化二进制索引的图像,因而能获得比通常更高的压缩增益及更低的存储成本的结果。
但是,如上所述,由于qpq比qpq更粗(也就是说、qi比qi更大),bi(m)与ai(m)相比,为零的可能性更高。也就是说、使用ai(m)时0以外的量化系数,在使用bi(m)时有可能为0。因此,请求图像的情况下,在微云上进行从粗量化二进制索引到密量化二进制索引的逆映射时,有必要在更高精度进行。这个问题称为量化数据仓库匹配问题(quantizationbinmatching(qbm)problem)。
本实施例中,通过下述最大后验概率(maximumaposteriori(map))公式,进行了从粗量化二进制索引到密量化二进制索引的逆映射,为此,有效利用了信号稀疏性模型(signalsparsityprior)。
在这里,若假定信号稀疏性模型(非专利文献2),通过字典的稀疏线性组合(sparselinearcombination)取得更近似的信息的可能性更高;对于固定大小的n像素的各个代码块,要使n个粗量化二进制索引在给定频率范围内找出最有可能的n个密量化二进制索引,需要将最大后验概率(maximumaposteriori(map))问题公式化。
该公式中,要求在特定n次元量化单元上进行先验分布的集成,与过去的逆量化研究相比,提出一种快速算法来近似先验分布集成,以搜索量化单元内单独求出可能性最高的信号。
因此,本实施例中,为了保证能够完全恢复输入图像,进行设计时需要考虑以下因素。
1)对于各块m,能够正确恢复原来的密量化索引a(m);
2)由于恢复图像与峰值信噪比(peaksignal-to-noiseratio(psnr)内的输入压缩图像非常相近,用户在视觉上不能区分。
因此,关于比原始qpq更粗的qpq,设计逆映射f(b)的目的是充分恢复输入图像。在这里,关于使用qpq再编码图像内足够大的块的一部分,只要求可以进行逆映射,剩余的块使用qpq不能改变。使用jbig进行无损编码的二进制小图像被追加编码,以使得块使用q通知再量化的解码。接下来,研究从粗qpq到密qpq的量化数据仓库匹配问题。
(量化单元相关map公式)
作为前提条件,xi代表目标代码块x的地面实况(ground-truth)的第i号dct系数。然后,ai,如下式(1)所示,是使用qpqi将xi量化的量化系数(密量化二进制索引)。
【数1】
因此,在具备ai和qi的解码器中,xi必须在间隔i(ai,qi)=[(ai-0.5)qi,(ai+0.5)qi)的范围内存在。另外,bi是对于再编码化图像内的xi,使用qpqi(qi在qi以上)进行量化的量化系数(粗量化二进制索引)。因此,再编码化后的xi,必须在更大的间隔i(bi,qi)=[(bi-0.5)qi,(bi+0.5)qi)的范围内存在。究其原因,由于原始编码化内的间隔i(ai,qi)及再编码化内的间隔i(ai,qi)均包括相同的xi,这些数据重复了。
因此,执行逆映射f:bi→ai时,需要研究式(2)所示的可能实现的bin集合fbi。
【数2】
接下来,将p(xi)定义为xi的先验概率(priorprobability)。最大后验概率(maximumaposteriori(map))公式,基于以下公式(3)及公式(4),搜索离散集合fbi内的最有可能的二进制^ai。
【数3】
其中
【数4】
一维qbm问题的map公式如图4所示。图4是根据本发明实施例1表示说明qbm解决方案之概念的图。从宽度q的粗量化bin与重复宽度q的3个密量化二进制(a、b、c)中选择最大总计概率(largestaggregateprobability)(p(xi|bi)的积分值)的其中一个。这与像非专利文献3中的典型逆量化研究不同,与量化二进制内可能性最高的信号相关的map公式,可以简洁地导向二进制范围内的p(xi|bi)的峰值位置。
这里,如将n维的先验概率p(x)连同块x内的n个dct系数x的全部均予以考虑,在下述公式(5)中表示,能够将更普遍的map最优化问题以公式化表示。
【数5】
其中,
【数6】
以下的公式(7),是将表示多维积分的公式(5),以更简洁的形式改写。
【数7】
其中,p-a(x|b)是以a(即,根据i(ai,qi);i=1,...,n)定义的量化单元ca内的概率p(x|b)的总计。求解公式(7)的课题是可以适当定义p(x)的方法,即能够高效并且正确计算p-a(x|b)的方法。
(先验概率p(x)的定义)
接下来,假定用于定义先验概率p(x)的稀疏模型(非专利文献2)。具体地,k稀疏信号模式是,像素区域内的n维信号x通过与来自过度完备字典(over-completedictionary)φ的k或者更少的原子(最小单位)进行线性结合,来充分近似。
【数8】
x=φα+ε,||α||0≤k···(8)
这里,模型误差ε很小。本实施例中,在机器学习驱动方法内,经过pca学习适应字典。
通过在公式(8)的两边适用dct运算符τ,获得公式(9)。
【数9】
x=ψα+ε′…(9)
其中,ψ=τφ。因此,x的稀疏性可以通过与φ相关的x的稀疏性来确定。
给出该模型,同时概率分布p(x)可以作为公式(10)表示。
【数10】
其中,σ是模型参数。从l0标准值进一步放宽到l1标准值。
最后,目标函数可以改写为公式(11)。
【数11】
如上所述,qbm问题一般不是通过图像逆量化(非专利文献3及4)执行的单个最佳稀疏解(sparsesolution)来解决,而是可以通过使用其范围内最大的和最稀疏的解来找到量化单元,进行再公式化。
(最优化)
很难直接优化上述公式(11)的目标函数。所以,不是寻找量化单元中的所有可能的稀疏解,而是找出单个最佳稀疏解作为代表,再乘以通过单元的积分获得的解(解的稀疏计数的指数函数)的先验概率值。这是公式(11)的多维积分的近似值,本质上讲,单元的积分越大,被发现的可能性越大,因此,可以找到具有更大总计概率的其它稀疏解。在索引的粗量化单元b内寻找初期稀疏解这一问题,如公式(12)中所示。
【数12】
与稀疏解α*相关的最优化问题,通过熟知的称为增广拉格朗日方法(augmentedlagrangianmethods(alm))的快速l1最小化算法,可有效而快速地加以解决。
如公式(13)所示,识别包含本稀疏解的密量化单元a*。
【数13】
识别的密量化单元a*(例如、图4所示的单元a及c)与粗量子化单元b仅部分重复的情况下,由于单元积分很小,其总计概率很小。为了对其它解的备选项进行测试,通过公式(12)对于密集的相邻量化单元,进行有关稀疏解的搜索。这些单元中,(单元内识别的稀疏解的)信号模型与单元积分的乘法运算结果中最大的,被选择作为最终解。
图5是根据与本发明实施例1表示说明粗密转换处理(图3的204)之流程的流程图。首先,事先让微云20学习与8x8块有关的字典。
接下来,粗密转换单元22采用公式(12)搜索粗量化二进制索引内最稀疏解的结果(s302)。也就是说,粗密转换单元22分别对于粗量二进制索引bi范围内的多个备选范围(a,b,c)搜索最稀疏解。图4所示的情况下,求出x3、x4、x6。
然后,粗密转换单元22估算p(x|a)(s303),即计算出a中最大的p(x3)值。然后,将a的宽度(x4-x2)乘以p(x3),求出量化单元a的量。同样,关于b,将b的宽度(x5-x4)乘以最大值p(x4),求出量化单元b的量。关于c,将c的宽度(x6-x5)乘以最大值p(x6),求出量化单元c的量。
然后,粗密转换单元22将邻近量化单元(a,b,c)之间的量化单元量进行比较,确定qpq的密量化二进制索引a*。如图4所示,确定了b。另外,如上所述,图4表示了一维的情况,更一般的情况下,8x8块中可以存在64维。
(试验结果)
为了证明本实施例的有效性,进行了下述试验。首先,使用了公知的柯达数据集。为了学习字典学习用的数据,随机选择了5张图像,剩余的图像作为测试图像使用。
关于jpeg编码时的品质因数(qualityfactor(qf)),通过从量化矩阵的集合中选择其中一个,表明压缩后图像的相对视觉品质在1至100的范围内。试验时,关于不同的图像,粗qf可以从50及55中选择,但将jpeg编码的精细qf固定在80。
这里,第1设计目的是保证能够正确恢复原始版本上传的密量二进制索引。这种情况下,正确恢复二进制索引意味着品质上没有损失。因此,报告了有关比特节省(bitsaving)的情况。另外,通过对具有可以保证正确恢复二进制索引的粗qf的图像块的一部分进行再编码,可以实现比特节省。
图6是根据本发明实施例1表示压缩增益之实例的示意图。图6显示了精细qf及粗qf、用于再编码而选择的块的比例、以及在8幅测试图像使用本方法而获得的纯压缩增益。关于测试图像、42.18%以下的块被选择用于使用粗qf进行补充压缩,结果显示,可以实现14.19%以下的比特节省。
第2替代方案的设计目的是,保证质量上非常接近上传图像的恢复,达到人眼无法识别品质差别的程度。为了实现这个目标,通过允许恢复和输入的密量化二进制索引之间的差异,减少“正确的二进制匹配”。差异的水平通过块水平二进制误差的合计来测算。本试验中,测试了6种情况,其中误差的合计为0,2,3,4,5和6。
图7lighthouse、图8ahoy、图9airplane,分别根据本发明实施例1表示3幅测试图像中使用jpeg的比率失真性能压缩。6种情况的psnr损失均在0.13db以内。这样小的psnr损失在典型情况下可以说不会产生视觉差异。也就是说,结果表明,本方法的jpeg效率很好。
进一步地,通过花费微不足道的psnr费用,视觉上无法区分的重新配置选项,与正确的二进制索引恢复的情况进行比较,实现足够高的比特节省效果。例如,使用6项误差合计,本方法分别用于lighthouse、ahoy及airplane,与图6所示的3.32%、2.01%及14.19%形成对比,分别实现16.71%、12.82%及20.7%的比特节省率。也就是说,可以实现充分的存储的节约。
如上所述,本实施例提出了一种与jpeg图像相关的云存储系统,该系统能够将用于保存大量上传图像的存储成本与用于对少数请求图像进行粗密转换的计算成本进行权衡。具体地,对于预先在用户终端使用量化参数(qp)q进行量化的编码图像,使用更粗的qpq重新编码,再保存在存储器中。这样,可以降低存储成本。而且,按照获取图像的请求,通过上述粗密转换(量化二进制配),进行从粗量化二进制索引到密量化二进制索引的恢复。这样,可以保持对于用户来说在视觉上没有差异感的图像质量。
在这里,本实施例可以有下述表现。也就是说,本实施例是具备,关于从基于第1量化幅度(qpq)将输入图像量化的第1量化系数(密量化二进制索引a)到基于比所述第1量化宽度更宽的第2量化宽度而量化的第2量化系数,用于向所述第1量化系数进行逆映射的逆映射单元的图象处理设备。特别地,所述逆映射单元,从所述第2量化宽度范围内的所述第1量化系数的备选项中(例如,对象像素的dct系数xi的)选择基于先验概率(priorprobability)将量化单元量最大化的量化系数,作为所述第1量化系数进行所述逆映射。也就是说,逆映射单元,从如图4所示的qpq的宽度(x6-x2)范围内的密量化二进制索引的备选项(a、b和c的各自所属的密量化二进制索引)中,求出来自p(x)与各备选宽度(a的情形,x4-x2;b的情形,x5-x4;c的情形,x6-x5)的量化单元量(相当于a、b和c的各自p(x)的积分值),作为在对各量化单元量中的最大值进行逆映射后的密量化二进制索引。
另外,所述逆映射单元,基于定义所述先验概率的稀疏模型,近似所述第1量化系数,进行所述逆映射。
进一步,所述逆映射单元,在所述第2量化宽度范围内的所述第1量化系数的范围内,按照每个所述备选项搜索所述先验概率的最大值,基于该最大值与所述第1量化系数的范围,计算出所述量化单元量,通过比较所述备选项之间的所述量化单元量,选择使所述量化单元量最大化的量化系数。也就是说,逆映射单元计算出密量化二进制索引的备选项a、b和c的各自相关p(x)的最大值,计算出p(x)的最大值与a、b和c的宽度的积(面积),将这些数值进行比较,从而选择出最大的值。
<实施例2>
接下来,说明上述实施例1的变形例,即实施例2。如实施例1所述,在再编码单元21进行再编码时(代码转换)时,一旦使用qpq进行转换后,模拟是否能够恢复原来的代码,只在可以保证可逆变换的情况下,通过qpq进行再编码。另外,如实施例1中所述,由于按照每个像素单位进行再编码,在处理效率及压缩效率方面有改进的余地。
所以,本实施例2中,将再编码的对象像素设定为以1个像素为间隔。即,关于1块的像素,密量化与粗量化交替进行。图10是根据本发明实施例2表示说明对于块内像素进行的密量化与粗量化之间关系的图。如图10的上部分所示,进行再编码时,密量化二进制索引(fine)和粗量化二进制索引(coarse)的像素交替配置。特别地,根据本实施例2所述的再编码单元21,以用虚线包围的4个像素作为一个单位,如图10的下部分所示,对于右下部的像素(4)进行再编码的情况下,通过使用邻接3个像素(1、2和3)进行粗密转换,应可以判断是否能够保证可逆转换。另外,右下部的像素(4)上的像素(2)与左侧的像素(3),保持了密量化二进制索引(fine)的状态,从而保持了未被再编码的信息量。另外,如图所示,右下部的像素(4)和左上部的像素(1),可以通过粗量化二进制索引(coarse)获得。
因此,最理想的是,再编码单元21,通过至少使用像素(2)和左侧像素(3)2个像素来判断是否可以保证可逆转换,判定是否可以对右下部的像素(4)进行再编码;粗密转换单元22将上部像素(2)与左侧像素(3)2个像素加入,进行右下部像素(4)的逆映射。因此,与实施例1相比,可逆转换的精度提高,作为结果,可进行再编码的概率提高,压缩率也提高。
进一步,补充上述,再编码单元21及粗密转换单元22,最好加入左上部的像素(1),对于是否可以对右下部的像素(4)进行再编码加以判定,并进行逆映射。因此,与上述相比,可逆转换的精度及压缩率可进一步提高。
另外,本实施例2中,在判断是否可保证如上述的4个像素单位的可逆转换后,关于通过微云20进行事先的字典学习,进行有关16x16块的操作。
另外,在实施例2中,在进行粗密转换处理方面,进行图5所示的步骤s302时,需要使用下列公式(14)。
【数14】
即,作为约束条件,将密量化与粗量化交替进行的4个像素作为对象。这样,通过将4个像素作为对象进行粗密转换(量化数据仓库匹配)时,同时进行解码处理,可以提高粗密转换处理的效率。
这里,本实施例可以有下述的表现。也就是说,本实施例还具备,关于包括所述第1量化系数的编码图像p2,通过进行再编码,使所述第1量化系数与所述第2量化系数交替,用于向再编码图像进行转换的再编码部。然后,所述逆映射单元,对于所述再编码图像内的所述第2量化系数(像素(4)的粗量二进制索引),使用该第2量化系数与相邻像素的所述第1量化系数(像素(2,3)的密量化二进制索引),进行所述逆映射。
进一步地,所述逆映射单元,进一步使用所述邻接像素和邻接像素的所述第2量化系数(像素(1)的粗量化二进制索引),进行所述逆映射。
<实施例3>
接下来,说明上述实施例1或2的变形例,即实施例3。本实施例3中,采用了多个种类的字典。图11是根据本发明实施例3表示图像处理系统之全部构成的框图。本发明的实施例3中,与图1相比,微云20替换为微云20a,存储器31中保存了与再编码图像p3关联的群集索引311。微云20a具备再编码单元21a,粗密转换单元22a与字典db23a。
字典db23a是基于多个测试图像的特征量的、根据其倾向被分类的多个群集组成的数据库。再编码单元21a参照字典db23a,确定编码图像p2所属的群集。微云20将再编码图像p3及确定的群集的群集索引311发送并保存至云存储器30。存储器31还保存与再编码图像p3关联的群集索引311。
粗密转换单元22a按照从用户终端12发出的图像请求,从云存储器30获得再编码图像p3及群集索引311,参照字典db23a,使用群集索引311对应的字典,对于再编码图像p3通过粗密转换恢复成恢复编码图像p4,然后返回至用户终端12。
图12是根据本发明实施例3表示说明粗密转换处理之流程的流程图。具体地,追加了图5的最初步骤s301,以后的处理是相同的。也就是说,粗密转换单元22a除了从云存储器获得再编码图像p3以外,还取得与再编码图像p3关联的群集索引311。然后,粗密转换单元22a参照字典db23a,从群集索引311选择使用的字典(s301)。然后,粗密转换单元22a使用字典db23a内选择的字典进行粗密转换处理。
这里说明在本实施例中字典的学习方法。按照(步骤1)特征量的直方图,将各个图像分类为群集,按照(步骤2)的各个群集进行字典的学习。
在这里,以本实施例3中字典的学习作为一个实例,说明使用bagofvisualwords(bovw)的情形。图13根据本发明实施例3表示利用bagofvisualwords(bovw)之情况下概念的示意图。说明上述步骤1。首先,将图13上部分的3个测试图像分割成多个块(或像素)(图13的下部分)。然后,例如,分析各个块,统计3个种类的特征fa、fb及fc的各自出现频率(适合程度)。图13的中段,分别是特征fa、fb及fc相关的直方图的图例。然后,按照这些直方图,将各个测试图像分类为群集。例如,有这样的倾向,即,自行车车座的块具有很明显的特征fb,人物皮肤和眼睛的块具有很明显的特征fa,小提琴的部分块具有较明显特征fc,因此关于各个块,可以进行群集分类。
图14是根据本发明实施例3表示在某图像上特征量分布之实例(直方图)的示意图。也就是说,表示与某幅图像上各块有关的特定特征量的直方图。因此,之后,在上述步骤2,按照与学习对象的图像有关的所属的群集,进行对应于该群集的学习。据此,字典的精度得以提高。
然后,按照上述进行再编码时,进行有关编码图像p2的群集的分类,确定群集索引(图像的特征),并将群集索引保存到云存储器30中。另外,进行解码时,基于粗量化二进制索引连同对应的群集索引来使用字典。因此,提高了计算速度及计算质量。
这里,本实施例可以有以下的表述。也就是说,进一步具备,关于多个图像,从各图像特征量的分布,分类到多个群集的字典信息部(字典db23a),以及,再编码单元21a,所述再编码单元21a用以将群集索引311保存到与所述第2量化系数(粗量化二进制索引b)关联的存储装置(存储器31),其中,从所述第1量化系数到所述第2量化系数进行再编码时,该群集索引311用于辨别所述输入图像与所述多个群集的哪个相符合。然后,所述逆映射单元,基于与所述第2量化系数关联的所述群集索引确定所述字典信息部内的群集,使用该确定的群集进行所述逆映射。
<实施例4>
接下来,说明上述实施例1至3的变形例,即实施例4。图15是根据本发明实施例4表示云存储系统之全部构成的框图。云存储系统中,存在用户终端11(用户u1)和用户终端(用户u2)、微云20b和云存储器30。系统主要有3项操作动作:脱机学习、图像上传和图像下载。
图像上传动作中,用户终端11将精细(密集)量化(以后称为密量化)的jpeg画像(编码图像)上传至微云,然后,微云20b的再编码单元21b,使用粗糙量化(以后称为粗量化)参数(qp)对图像的代码块的子集合进行再编码,最后将再编码图像p3(及后述边信息312)保存到云存储器30。
在图像下载动作中,微云20b的粗密转换单元22b,将被请求的粗量化图像(再编码图像p3及边信息312)从云存储器30取出,将粗量化的代码块逆映射到密量化块。
脱机学习动作中,为了使从图像下载中的粗量化块到密量化块的逆映射操作易于实现,微云20b的学习单元,事先计算并记忆了适当字典23b及图表模板24。另外,学习单元25也可以设在微云20b的外部。接下来详细说明这些动作。
1)脱机学习:图像下载过程中,将从粗量化块到密量化的逆映射作为信号恢复问题。
近些年,为了实现非专利文献9中从jpeg压缩形式恢复到图像像素补丁,一般情况下将稀疏模型(sparsityprior)(非专利文献10)与图表信号平滑模型(graph-signalsmoothnessprior)(非专利文献11)组合使用。这2个模型能够很容易恢复各自像素补丁当中组织化和结构化的图像内容。
假定使用这2个模型,高速实施过程中,必须要使用图像恢复中的小字典和稀疏的(sparse)图表。面对这个目标,我们首先要构造树型结构向量式量化(tree-structuredvectorquantization:tsvq)(非专利文献12),以便将像素块ψ从大型学习集ψ0分类至树型结构最终节点对应的类似块的不同群集。对于各个群集i,基于该群集关联的学习数据ψi,让过度完备字典及稀疏图表模板进行学习。构建分类树后,重要的设想是,图像下载过程中,在能够正确识别将原始块加以分类的群集的情况下,能够很容易地将关联字典及与群集关联的图表从粗块逆映射到密块中。
2)图像上传:用户终端11将jpeg压缩图像(编码图像p2)上传到微云20b(微云)。在这里,n-像素代码块x,分别按照用精密qpq=[q1,…,qn]赋值的n量化二进制索引a(x)=[a1(x),…,an(x)]的集合列举。详细地,第i号的量化二进制计数ai(x)形成以下结果。
【数15】
其中,ti是dct变换矩阵t的第i行。
然后,微云20b的再编码单元21b,使用粗qpq=[q1,...,qn]对编码图像p2的块的子集合再编码,将精密二进制索引a(x)映射到与永久保存到云存储器30的代码块x相对应的粗二进制索引b(x)中。微云20b在图像上传过程中,对于再编码的块执行逆映射,目的是从使用信号模型的粗b(x)恢复到精细的a(x)。再编码单元21b只对可以“正常”逆映射的图像中的块x在上传过程中进行逆映射。对于小的二进制图像,使用作为边信息(sideinformation:si)312的jbig(非专利文献8),可以进行无损编码,其中,边信息能够给出关于解码器上哪个块使用q进行粗糙再编码的相关信息。
本系统可以保证,对于jpeg图像中再编码的块,可以在2种模式的任何一种正常进行逆映射。i)无损失恢复(可逆恢复,losslessrecovery)(无损失模式):意味着为了准确恢复,对于各个再编码块x的原始a(x),可以确定保证恢复。或者ii)接近无损恢复(near-losslessrecovery)(接近无损模式):意味着,为了能够以高概率精确恢复,对应于原始图像的a(x),在统计上可以保证。这样,使得解码的jpeg图像与原始图像很接近,用户从视觉上无法区分差异。无损模式下,为了保证使用适当的字典及图表模板从而对再编码块的各自对应a(x)完全恢复,对应于tsvq中x的群集索引,在上传过程中,也使用提议的分布式编码方法,作为si被编码。
3)图像下载:用户u2在召回事先上传的图像时,微云20b从云存储器30取出粗量化的图像(再编码图像),对于用户u2,将块x的粗量化b(x)分别逆映射至密量化的a(x)。为了使图像取出延迟最小化,应该使用,在图像上传过程中以作为si的编码群集索引表示的,适当的小型字典的和稀疏的图像模板,来高速地进行逆映射。
这里,在粗量化仓库内,首先(作为图4中的x3表示的)通过搜索可能性最高的信号可以重写量化数据仓库匹配问题。
【数16】
然后,确定包括可能性最高信号x0的密量化仓库向量a0。
【数17】
接下来,在粗仓库向量b内,将发现可能性最高信号x0这样的问题作为焦点。
这里,使用2个信号模型,将发现赋值粗仓库索引向量b可能性最高的x^这个问题作为焦点。另外,包括发现的最高可能性信号的密量化仓库为恢复的密仓库索引。另外,2种信号模型是指稀疏模型和图表信号平滑模型。进一步地,为了实现高速实施,我们学习了对应于各群集的小字典及稀疏的图表模板。
通过将2种模型ps(x)与pg(x)结合,将p(x)定义如下。
【数18】
发现附加了索引的粗量化单元b内最有可能信号的问题,可以进行下述公式化。
【数19】
s.t.,xi∈i(bi,qi),i=1,…,n.···(19)
目标函数可以通过交替优化解答。
图16是根据本发明实施例4表示脱机学习之流程的图。学习单元25从学习图像pg抽取(收集)学习块集合bs(块图像)(s401)。优选地,例如,学习图像pg为多数的高分辨率图像群。接下来,学习单元25,对于学习块集合bs,按照tsvq分类为多个群集,构造树型结构(二叉树)ts。然后,学习单元,为了减少对于所分类各群集的群集索引的偏移,替换树型结构(二叉树)的节点(s403)。另外,该节点的替换,与后面所述树节点的比特分配对应。另外,学习单元25,为了使对应于替换后二叉树的比率失真最优化,进行修剪(s404)。另外,该修剪步骤与后述比率失真最优化树修剪对应。然后,学习单元25对于修剪后的二叉树学习过度完备字典和稀疏图表模板(s405及s406),保存在作为字典db23b及图表模板24的存储装置(未图示)。另外,该存储装置可以设在微云20b内部或外部。另外,完整的tsvq在解码器上是必需的,完整树的索引对于各块进行计算。
(适应性的字典及图表模板学习)
考虑多数的脱机学习数据,对应于与类似像素块不同的群集,学习字典及图表模板。对于各群集,基于分类于该群集的学习数据的像素块,使其学习过度完备字典及1个稀疏图表模板。
1)小字典学习:对于特定的群集,存在分配的n学习块y=[y1,y2,···,yn]。这里,yi表示向量形式内的学习块i。按照k-svd(非专利文献10),通过使下列目标函数最小化,计算字典φ。
【数20】
2)稀疏图表模板学习:同样地,学习有关特定群集的稀疏图表。对于各个群集,首先计算重心(centroid)块。重心块是分配给该群集的学习块的中心或平均值。然后,对于该重心块,构造稀疏图表模板。图17是根据本发明实施例4表示稀疏图表模板之实例的示意图。如图17所示,只连接纵向的、横向的或倾斜的邻接节点。究其原因,图表为稀疏图表,如果l为稀疏矩阵,可以采用i+λ2l^逆阵的高速解决方法,能够用于降低公式(21)的计算复杂性。另外,各模板为连接的图表。
【数21】
(完全tsvq构建(fulltsvqconstruction))
假定学习数据集ψ0后,我们首先构建目标高度hmax的二进制完整树(abinaryfulltree,完整二叉树)t0(图18(a))。具体地,构建完整树需要采取以下步骤(非专利文献12):
1)初始化:树的高度h=0初始化。我们将学习集ψ0整体作为关联学习集的平均计算,将重心c0与高度0的路由节点r关联。
2)二进制分配:对于高度h的各节点i,我们生成2个子节点j及k。这里,i→0j、i→1k。我们为了使其重心cj及ck的相关总距离最小化,将与节点i关联的学习集ψi分配给2个不重复的子集ψj及ψk。
【数22】
使用lloyd算法(lloydalgorithm),可以解答局部最合适的公式(22)。由交替执行的2个步骤构成,直到实现局部收敛性(localconvergence)。
·给定固定重心cj和ck的情况下,通过将各ψ∈ψi作为更近的重心来向分割(partition)分配ψ,可求出局部最适合的分割ψj和ψk。
·给定固定分割ψj及ψk的情况下,通过使各自的二乘误差最小化,更新重心cj及ck。对于cj,进行如下计算:
【数23】
这意味着,通过取ψj的平均值,计算作为群集的ψj之中心的cj。
开始交替发生劳埃德算法之前,按照非专利文献13,将对应于高度h的节点i的2个子重心cj及ck作为ci及摄动版本进行初始化。即,
【数24】
cj=ci,ck=ci+η···(24)
其中,η表示噪音方差σ=1的高斯噪声。
3)更大二进制完整树的生成:在构成的二进制完整数的高度h比目标值hmax小的情况下,以1为增量增加h,转到第2步。
(群集索引的稀疏编码)
在无损失模式下,图像下载过程中,为了指定适当的字典及图表模板,以便将再编码块x的粗索引b(x)逆映射到精密索引a(x),将“精确”群集索引i确定为图像上传过程中的si,进行编码。具体地,使用精密索引a(x)的输入,首先构建硬解码(harddecoded)的块x^,使用块x^从路由节点r至高度hmax的最终节点e0遍历(traverse)完整树t0。通过遍历,在节点i上,将x^与各自的子节点j及k的2个重心cj和ck进行比较,进入具有更近重心的节点。
到达最终节点e0后,将关联字符串se0确定为x。作为(后述)群集使用的实际最优化的vlt(variable-lengthtree)t(图18(b)),由于是典型完整树t0的子集,不使用x^,而是遍历t,t0中间节点t当中的最终节点用作终端,这种情况下,se是se0的子字符串(substring)。se0的子字符串se表示为qt(x)。2个最终节点t0及t的字符串的实例,如图18(c)所示。
为了降低编码成本,不采取直接编码qt(x),而采取通过粗索引b(x)硬解码的块x^来遍历t0,利用图像下载过程中获得的字符串x及其噪音观察y之间的相关性,提出高效率的稀疏编码方式。基本的设想是,对于更多的观察/目标字符串的配对(y、x),为实现qt(y+δ)=qt(x),在码本c设计差分代码字δj,以用于对作为si的适当差分δj进行编码。按照高概率p(δj)选择差分δj的情况下,使用算术编码(arithmeticcoding)(近似的)的码率‐logp(δj)较低。
为了实现qt(y+δj)=qt(x),在差分δj∈c不存在的情况下,直接对索引代码字di编码。其中,i为块x^的群集索引。直接索引代码字对于各群集是唯一的(固有的),所以其概率典型情况下较低,编码成本更高。
基于无损失模式的树型结构向量量化的最优化
这里,定义了tsvq最优化问题,讨论了tsvq最优化方法。考虑到存在2个最优化变量vltt和码本c,提出交替最优化方法。
(a)固定c,最优化t。这称为最优vlt设计问题。
(b)固定t,最优化c。这称为最优差分码本问题。
以下按照顺序说明用于解决这2项问题的详细算法。
(a)最优vlt设计
固定c后,最优化问题表述如下。
【数25】
上述的目标函数表示,vltt的rd成本,可以分别按概率p(i)加权的最终节点i的各项rd成本进行合计。说明了使公式(25)最小化的2项步骤。
首先,根据公式(25),对于不同的最终节点i,为了诱导更有利的误差分布p(y|i)(例如,对于最终节点i,获得更小的比率的结果,实现p(si|i)向中心分布的非对称分布,提出在vltt上的节点重新分配二进制位(0和1)的步骤(1)。
接下来,对于向vltt分配所确定的比特,提出步骤(2):从初期的树最优地删除最终节点,进行rd-最优化树修剪。
这2个步骤在实现收敛之前交替执行。接下来说明这2个步骤。
(1)树节点的比特分配:对于密量化块x,以如下方式定义其概率。
【数26】
p(x)=p(i)pi(x)···(26)
这里,p(i)为最终节点的概率,pi(x)为通过群集i所属块扩展(spanned)的子空间(subspace)si内的x的概率。粗量化块y能够估计x的噪音版本(noisyversion),按下述方式模型化。
【数27】
y=x+z···(27)
其中,z为噪音。
通过解决下述最优化问题,找到y的可能性最高的群集索引j*。
【数28】
如根据噪音模型,上述的最优化可以按下述方式改写。
【数29】
然而,由于x和z均是高维向量(high-dimensionalvectors),意味着解答公式(29)并不是不言自明的问题。反而,为了取得与si的重心ci最相近的重心,需要找到y的可能性最高的子空间。
【数30】
这里,m是y的子空间的备选数量。
求出y后,为了强行使索引j*节点接近节点i,需要再分配树节点的二进制位。实例如图19和图20中所示。图19是表示说明子空间检索的图。密量化块x部署在子空间s1中。如果选择噪音模型,可能性较高的噪音观测值y用粗体虚线表示。通过处理公式(29),检索y的可能性最高子空间的索引。图20是表示说明如何替换二叉树节点的图。假定x部署在s1中,检索到的可能性最高的y部署在s3中。索引偏移为2。为了使s1及s3相互接近,向树分支再分配正确的二进制位。索引偏移减少为1。因此,群集索引的偏移减少。图21是表示如何比较二进制位分配前后索引偏移之概率分布的示意图。如图21所示,索引偏移的概率在0的周围更集中,码本c的传送成本更小。因此,对于最终节点i,实现更小的比率。
(2)比率失真最优化树修剪(rate-distortionoptimized刚pruning):二进制位重新分配后,为了以最优方式从初期树t去除最终节点,执行rd-最优化树修剪步骤。通过清除更多的最终节点,虽然失真变大,树变得更短,但比率变得更小。我们通过改变树的深度,实现了失真与比率之间的最优权衡。存在若干利用比率失真结构(ratedistortionframework)实现的修剪树算法(prune-treealgorithms)。这里,我们的系统中,采用称为修剪子的方法(非专利文献14)。然而,本发明不限于该方法。
对于预定的树t’,存在有限数量的修剪子树(pruned){t}。我们为了找到与公式(25)的最小值相关的数据,进行了广泛的检索。具体地,修剪了2个兄弟最终节点(brotherendnodes),将它们的父节点作为新的最终节点,得到新的vltt。对于t,总计所有最终节点的失真与比率(rate),计算rd成本。
【数31】
对于从左到右最终节点的所有节点对,以递归方式进行该项处理。最终,以下述方式获得最优vlt树:
【数32】
(b)最佳代码本设计
1)稀疏编码方法:这里,焦点问题是如何设计赋值vltt的最适合码本。如已知的,假定统计p(y|x)是固定的,。可行的(feasible)码本c意味着,关于p(y|x)>0的观测/目标对(y,x),i)能够选择如qt(y+δj)=qt(x)的差分代码字δj∈c,ii)能够选择如si=qt(x)的直接索引代码字ci。最优的代码本c意味着,对于全部数据对(y,x),可以进行上述可行的选择,将设想的编码成本降至最低。
首先,与典型的差分编码不同,为了对各观测/目标对(y,x)的正确差分δ=x-y进行编码,不需要采用编码器;如qt(y+δj)=qt(x)的任何可行差分代码字δj同样可以接受。我们用r(y,x)表示可实行的差分范围。vltt中的量化数据仓库i=qt(x)的下限和上限,通过(li,ui)表示。很明显,量化仓库i的大小ui-li越大,获得的范围r(y,x)越大。
设计码本时,直观地,优先小的码本c;概率只集中于少数的代码字δj或ci,因此编码成本-logp(δj)或-logp(ci)变小。如上所述,对于对应于数据对(y,x)的群集索引进行编码时,按照范围r(y,x)提供的自由度赋值,我们的设计方法如下所述。首先,只选择覆盖更大范围r(y,x)的少数差分δj。然后,对于剩余数据对(y,x),为了保持可行性,使用直接索引代码字ci。接下来,详细说明该处理过程。
2)码本设计算法:首先,为了保证实行的可能性,假定对应于vltt最终节点i,所有直接索引代码字ci包括在码本中。然后,按如下方式追加差分代码字δj。首先,p(y|x)有上升的趋势,所以是使用最普遍的代码字,追加初期(缺省)差分δ0=0。
对于每个观测/目标数据对(y,x),确认范围r(y,x)与现用码本c中的现有差分δj不重复。如果不重复,如图22所示,将用p(y|x)按比例缩小的r(y,x)添加至差分计数器h(δ)。将来自与现存差分代码字不重复的全部数据对(y,x)的范围累积后,将峰值δ*=maxδh(δ)添加到c,指定作为下一个备选项。
接下来,将差分代码字的备选项δ*添加至c的情况下,计算预测的编码成本。对于各数据对(y,x),在接近0的范围r(y,x),检索代码字δj∈c。在r(y,x)内没有δj∈c的情况下,对于该数据对,使用直接索引(directindex)ci。其中,i=q(x)。向全部数据对(y,x)的代码字给予映射后,可以用表格表示各代码字对应的概率,可以使用公式(33)计算比率。
【数33】
只有在得到的比率减少的情况下,最终追加该备选值δ*。要尝试追加其它差分代码字的各备选值,在比率降低的情况下,重复上述步骤。算法的伪码在算法1(图23)中表示。
伴随统计保证实现的近无损失模式(near-losslessmode)
接下来,说明近无损失模式的相关情况。近无损失模式与无损失模式不同,无损失模式可绝对保证对于各块x能够从粗索引b(x)恢复精密数据仓库索引a(x),而近无损失模式可以统计上保证能够以高概率从b(x)恢复a(x)。通过降低恢复必要条件,近无损失模式能够实现明显降低的计算量。
具体地,脱机学习过程中,完整tsvq构建后,将学习块分类至不同的群集。相同群集的块共用相似的结构。对于各群集,使用与该群集关联字典及图表模板,计算精密索引a(x)从粗索引b(x)精确逆映射的块的比例。为了保证对于完整图像的统计学保证,使用了各群集的恢复成功率。
图像上传过程中,对于各代码块xi,通过脱机统计,存在关联的恢复成功概率p(xi)。与无损失恢复不同,为了决定对哪个块进行再编码,不是对量化数据仓库匹配进行最优化,而是选择比事先设定的阈值pt更高的平均恢复成功概率。更具体地,沿着队列对全部代码块进行详细搜索(扫描),逐步确定再编码的代码块。到达代码块xi后,按下述方式计算调查的块{xj}ij=1的平均恢复成功概率api。
【数34】
api≧pt的情况下,将xi追加到再编码的子集。这个决定处理,由于不按块实行实际的逆映射,速度很快。
为了选择用于qmb的字典和图表模板,对完整树进行遍历,图像下载过程中,使用粗量化块。无损失恢复过程中,如那样执行,由于不需要支付由于对群集索引进行编辑所要追加的成本,可以节约更多的存储空间。
这里,本实施例可以如下表述。也就是说,一种图像处理设备微云20b,具备一过度完备字典(overcompletedictionary)(字典db23b),用于根据多个图像的特征量的分布分类到多个群集;一种稀疏(sparse)图表模板(图表模板24),用于图表化所述特征量的分布,分类到所述多个群集;一学习单元25,用于从所述多个图像学习所述过度完备字典和所述稀疏图表模板;一再编码单元21b,用于对于包括第1量化系数的编码图像,从所述第1量化系数,基于比所述第1量化宽度更大的第2量化宽度,再编码至第2量化系数,所述第1量化系数是将输入图像基于第1量化宽度进行量化的系数;和一逆映射单元(粗密转换单元22b),用于对于所述第2量化系数,使用所述过度完备字典和所述稀疏图表模板,向所述第1量化系数进行逆映像。然后,学习单元21,对于从所述多个图像抽取的多个块图像,通过tsvq(tree-structuredvectorquantization)分类至多个群集,构建二叉树,为了减少对于所述分类的各群集的群集索引偏移,替换所述二叉树的节点,对于所述替换后的所述二叉树进行修剪,以使比率失真最优化,对于所述修剪后的所述二叉树,学习所述过度完备字典和所述稀疏图表模板。再编码单元21,将群集索引保存在对应于所述第2量化系数的存储设备(云存储器30)中,所述群集索引,进行再编码时,用于辨别所述输入图像与所述学习后的所述过度完备字典及所述稀疏图表模板的哪个群集相符合。逆映射单元,基于与所述第2量化系数关联的所述群集索引确定所述过度完备字典及所述稀疏图表模板内的群集,使用该确定的群集进行所述逆映射。据此,字典和图表模板的精度提高,逆映射的精度也可以得到提高
<其它发明的实施例>
另外,上述说明中,由于jpeg作为图像压缩手法举例,dct系数作为转换系数。但是,本发明不仅限于dct,还适用离散正弦转换(discretesinetransform(dst))或者非对称离散正弦转换(asymmetricdiscretesinetransform(adst))等其它基于块的转换编码及解码装置。
进一步的,本发明不仅限于上述实施例,在不脱离本发明要点范围内的各种变更当然也可以适用。例如,上述实施例中说明了本发明的硬件构成,但本发明肯定不限于此。本发明可以通过向cpu(中央处理器centralprocessingunit)执行计算机程序来实现任何处理。这种情况下,计算机程序可使用各种类型非临时性计算机可读媒介(nontransitorycomputerreadablemedium)保存,供计算机使用。
非临时性计算机可读媒介包括各种类型的具有实体的记录媒介(tangiblestoragemedium)。非临时性计算机可读媒介的实例包括磁记录媒介(例如软磁盘、磁带和硬盘驱动器)、光磁记录媒体(例如磁光盘)、cd-rom(只读存储器readonlymemory)、cd-rcd-r/w、dvd(digitalversatiledisc)、bd(bluray(注册商标disc)、半导体存储器(例如掩膜只读存储器、prom(可编程只读存储器programmable)eprom(erasableprom可擦(可)编程只读存储器)、闪速存储器、ram(randomaccessmemory随机存储器)。另外,计算机程序也可通过各类临时性计算机可读媒介(transitorycomputerreadablemedium)提供给计算机。临时性计算机可读媒介的实例包括电信号、光信号及电磁波。临时性计算机可读媒介,通过电线及光纤等有线通信线路或无线通信线路,可以将程序提供给计算机。
【附图符号说明】
u1用户
11用户终端
111图像编码单元
112图像解码单元
u2用户
12用户终端
121图像编码单元
122图像解码单元
20微云
21再编码单元
22粗密转换单元
23字典db
20a微云
21a再编码单元
22a粗密转换单元
23a字典db
30云存储器
31存储器
3n存储器
311群集索引
p1输入图像
p2编码图像
p3再编码图像
p4恢复编码图像
p5解码图像
20b微云
21b再编码单元
22b粗密转换单元
23b字典db
24图表模板
25学习单元
312边信息
pg学习图像
bs学习块集合
ts树结构(二叉树)
- 还没有人留言评论。精彩留言会获得点赞!