一种用后缀索引查找IP路由的系统的制作方法
本发明涉及ip地址字符串序列查找技术领域,更具体地,涉及一种用后缀索引查找ip路由的系统。
背景技术:
互联网上的每台主机都有一个唯一的ip地址,其中ipv4地址是32位。对于每一个进入路由器的数据报,都必须根据其目的ip地址查路由表从而找到相关的路由信息。目前的路由表查找算法一般集中于二分查找、平衡二叉树、哈希索引等,它们的查找时间随路由表中ip地址数量增长。
以下相关专利对当前ip地址查找的问题给出多个具体技术方案,这些方案的适用范围、原理及具体设计等都区别于本发明。
现有技术中有提出ip地址最长匹配快速查找的方法。其中涉及一种基于内存的ip地址最长匹配快速查找的方法,该方法首先对ip地址分成a类,b类,对ip按照8位一段的方式建立索引树,a类地址只有1层,b类地址有2层。对最底层,建立一个mask桶索引,每个mask下面挂接一个ip顺序表,在此顺序表中存放最终的ip项,查找的时候,根据传入的ip地址判定是a类还是b类地址,如果是a类地址,根据得到的mask桶索引,从32位mask的ip列表开始,采用二分法进行匹配,直到找到或者查找失败。如果是b类地址,则引导到第二段表中,用ip地址的次8位在第二段表中进行定位,并最终跟a类地址一样引导到mask桶索引,进行查找。还有提出了一种ip段地址集中查找ip地址的方法。本发明涉及一种在ip段地址集中查找ip地址的方法,步骤为:1)选取一个ip段地址,根据ip段的变化范围将ip段分为相邻域,并建立多个哈希链表存储所述ip段;2)在所述多个哈希链表中按照顺序查找出待查找的ip地址;3)在每个哈希链表中查找所述ip地址的方式为,先确定哈希位置,再遍历哈希链表。这种方法的hash表结构进行ip查找,最坏情况是访问了全部3张hash表,然而绝大多数ip地址段的变化范围集中在最后两个域,通常情况的查找在24位hash表中就能完成,而24位hash表每个索引位置允许变化的ip地址也就255个,它查找时间基本与ip段地址集的大小无关。
技术实现要素:
本发明提供一种加快查找速率的用后缀索引查找ip路由的系统。
为了达到上述技术效果,本发明的技术方案如下:
一种用后缀索引查找ip路由的系统,包括:
构造模块,根据路由表中的ip地址信息,完成加速表以及后缀数组的构造,并记录相关的数组信息,以待查询模块的调用;
查找模块,利用哈希表查找和后缀数组的快速查询,实现从构造好的ip字符串中查找出目的ip;
定位模块,处理匹配数据在原文字符串v中的定位,实现在路由表中快速准确查找目标ip地址。
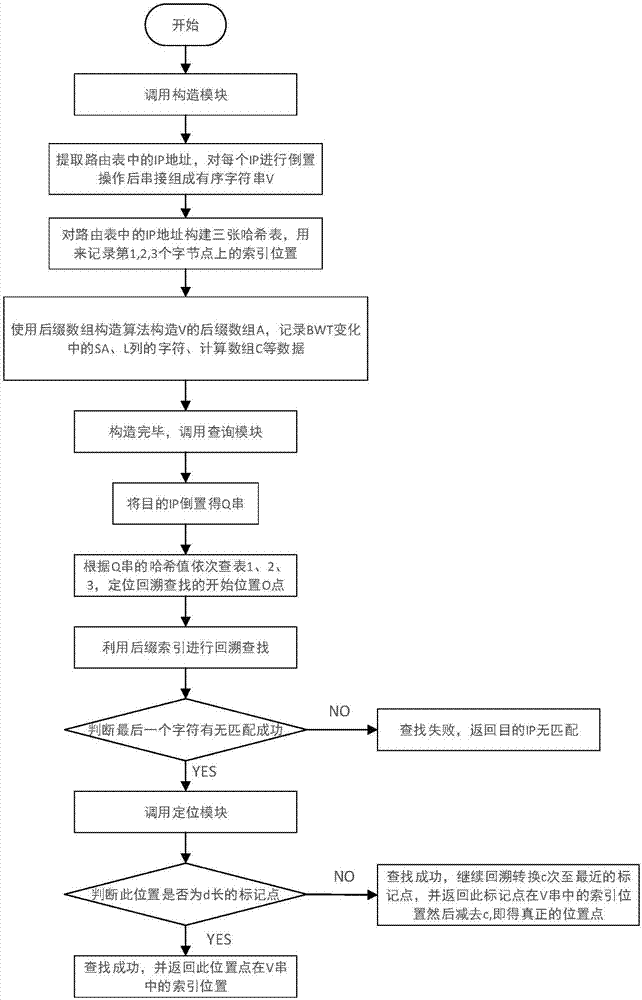
进一步地,所述构造模块利用路由表中的ip地址信息,完成加速表以及后缀数组的构造,并记录相关的数组信息的具体过程如下:
s21:将路由表里面的每个ip地址进行前后倒置运算,并且在每个ip地址后面加上一个结束符$,从而得到一个新的ip地址的字符串u。在字符串中,$是最小的字符,比0,1都要小;
s22:把步骤一中的n个新的ip地址u串接起来,得到一个总的字符串v;
s23:将u串的后3个字节,后2个字节,后1个字节依次构造哈希表1、哈希表2、哈希表3,每个哈希表有n个数据链表头,每个数据链表头指定其第一个数据节点的储存位置;再根据ip地址的字节数据逐个算出hash值,并将其链接至该hash值相应的数据链表头指定的第一个数据节点的存储位置,若第一个数据节点已存储有数据时,则存储至其指向的下一个储存位置,依次类推;哈希表中key表示为u串中后3个字节,后2个字节,后1个字节的具体组合形式,表1的索引范围为0-(2^24-1);表2的索引范围为0-(2^16-1),表3的索引范围为0-(2^8-1),value值存放位置,顺序存放每个u串中u[8]、u[16]、u[24]在v串中对应的索引位置,通过查询这三张哈希表实现字节定位,减少回溯的次数,进一步加速查找;
s24:把v串按后缀数组构造算法构造,得到v的后缀数组a;
s25:从a和v计算得到v的bwt,记为b,b[i]=v[a[i]-1],如果a[i]-1=0则b[i]=$;
s25:扫描v计算数组c[0]和c[1],对于a[i],c[0][i]=b[0,i]中0的个数,c[1][i]=b[0,i]中1的个数,得出v的bwt中0与1字符的rank值。
进一步地,所述查询模块利用哈希表查找和后缀数组的快速查询,实现从构造好的ip字符串中查找出目的ip,该过程具体步骤如下:
s31:把要查询的目的ip地址倒置,得到q串,将q串看成模式进行查找;
s31:根据q查询构造模块中的哈希表,加快回溯查找过程中开始位置的定位问题;首先查表1,对q后3个字节用hash算法计算hash值,按其hash值,找到相应的数据链表头,再根据数据链表头指向的存储位置进行逐一的查找比对key值;如果有匹配key,则返回表1中与之对应的value值,即原文中的索引值;如果在表1中没有找到位置和key值都相等的表项,则开始定位q的后2个字节有无匹配,同样的原理查表2,返回匹配的索引值,如果无则用表3定位q的后1个字节有无匹配,返回匹配的索引值,如无则返回最近的’$’所对应的索引值;
s33:遍历后缀数组a,找到第二步返回的索引值a[i],a[i]对应的字符即为开始点o,以此为基点开始回溯查找,得到q串的最长公共前缀lcp;从bwt变换过程中存在b[i]=v[a[i]-1]的关系,通过查找后缀数组a[i]位置上的字符,得到a[i]的前继字符,遍历c[0]和c[1],用来计算rank[0]与rank[1];回溯至最长公共前缀lcp与目标ip地址q串完全匹配,则查找成功,记录与q串匹配的最终字符在路由表中的位置,若无匹配结果,则在路由表中无此目的ip地址。
进一步地,所述步骤s33中回溯查找的过程如下:
对ip地址v串进行循环移位之后按字典序排序,排序后的矩阵产生的第一列,记为first列,简写为f列,最后一列记为last列,简写为l列,对f列以固定步长d进行标记,并且将这些标记字符,对应在v中的索引位置也标记下来。实现上述第二步中查哈希表定位字节之后,从定位点o点开始,利用sa对v串进行回溯查找,从右往左的逐个字符进行回溯转换;
在上述排序产生的矩阵具有如下性质:取l列,f列中任意两个相同的字符(0,1,$),若这两个相同的字符的rank值相同,则这两个相同的字符将映射到原文(即v串)的同一个位置;若回溯转换后得到的行数所映射的l列的字符,与目标ip地址q串中的前继字符一致,则表明该目标ip地址在路由表中存在,继续查找直至完全匹配;若不一致,则表明q不存在,ipv4地址只由几个字符组成,在进行查找的过程中,一般前继字符经常相同,所以回溯转换得到的位置将不止1个,而是一个区间。该范围内所有结果皆是与q部分匹配的解,直到q完全匹配成功,则最后一次回溯转换将得到一个在f列中行数。
进一步地,定位模块处理匹配数据在原文字符串v中的定位的过程如下:
1)判断这个从查询模块中传递过来的这个f列的行数,是不是在查询模块中以d的步长选取的标记字符点;
2)获取目标ip地址q在路由表字符串v中的准确位置;如果判断为标记点,直接获得q在v串中的位置;若不是标记点,则继续使用回溯转换,同时记录使用次数num,直至回溯到v串中最近的一个标记点;最后将标记点所对应的位置减去回溯转换次数num,得到q在v串中的准确位置,返回结果,从而实现在路由表中快速准确查找目标ip地址。
与现有技术相比,本发明技术方案的有益效果是:
本发明通过构造模块根据路由表中的ip地址信息,完成加速表以及后缀数组的构造,并记录相关的数组信息,以待查询模块的调用;查找模块利用哈希表查找和后缀数组的快速查询,实现从构造好的ip字符串中查找出目的ip;定位模块,处理匹配数据在原文字符串v中的定位,实现在路由表中快速准确查找目标ip地址。
附图说明
图1为本发明中具体实施案例的系统模块架构图;
图2为本发明中具体实施案例的整个系统模块的流程图;
图3为本发明中具体实施案例中在构造模块中哈希表1的数据结构图;
图4为本发明中具体实施案例中在查找模块中哈希表找匹配项的流程图;
图5为本发明中具体实施案例中在查找模块中查询哈希表加速ip地址字节定位的流程图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
下面结合附图和实施例对本发明的技术方案做进一步的说明。
实施例1
如图1-2所示,一种用后缀索引查找ip路由的系统,本实例以存储在路由表项中的路由ip地址x,y,z,m为例,对本实施例提供的路由表项快速查找方法进行举例说明。其中路由ip地址x至m具体如下:
路由ip地址x:11010100011000101010001011000111
路由ip地址y:00010010001000100111010111100110
路由ip地址z:00100010001011001001010101100001
路由ip地址m:01010100100010001010111000010010
第一步:将路由表里面的每个ip地址d1d2d3d4(其中d代表一个8位由0,1字符组成的字符串)进行前后倒置运算,并且在每个ip地址后面加上一个结束符$,从而得到一个新的ip地址的字符串u(d4d3d2d1$)。
倒置后的字符串u(x):11100011010001010100011000101011$
倒置后的字符串u(y):01100111101011100100010001001000$
倒置后的字符串u(z):10000110101010010011010001000100$
倒置后的字符串u(m):01001000011101010001000100101010$
第二步:把n个ip地址u串接起来,得到一个总的字符串v串(11100011010001010100011000101011$01100111101011100….)
第三步:将u串的后3个字节,后2个字节,后1个字节依次构造哈希表1、哈希表2、哈希表3。每个哈希表有n个数据链表头,每个数据链表头指定其第一个数据节点的储存位置;再根据ip地址的字节数据逐个算出hash值,并将其链接至该hash值相应的数据链表头指定的第一个数据节点的存储位置,若第一个数据节点已存储有数据时,则存储至其指向的下一个储存位置,依次类推;这三张表的key值分别为(d3<<16)+(d2<<8)+d1、(d2<<8)+d1以及d1,value值存放位置,顺序存放每个u串中u[8]、u[16]、u[24]在v串中对应的索引位置。这样key最多有2^24,2^16,2^8种情况。哈希表具体的结构如下图3所示。构造这样的hash表用来定位最开始的查找点o。
按上述步骤构造好hash表后,其中每个数据节点中的表项具体如下:
hash表1
hash表2
hash表3
第四步:把v串按后缀数组构造算法构造得到v的后缀数组a。
s=s[0...n)=是后缀数组sa的输入,在本发明中,这个输入就是指路由表中的ip地址序列,后缀数组的创建其实就是将输入字符串的所有后缀从小到大进行排序之后,然后将排好序的后缀的开头位置,顺次存入一个一维数组,这个一维数组就是sa。即sa={a[0],a[1],a[2]……}={第1行后缀开头在原文的索引位置,第2行后缀开头在原文的索引位置,第3行后缀开头在原文的索引位置……}。
第五步:从a和v计算得到v的bwt,记为b,b[i]=v[a[i]-1],如果a[i]-1=0则b[i]=$。查找后缀数组a[i]位置上的字符,可以得到a[i]的前继字符b[i]。
第六步:记录v计算数组c[0]和c[1],对于a[i],c[0][i]等于b[0,i]中0的个数,c[1][i]等于b[0,i]中1的个数,得出v的bwt中0与1字符的rank值。
在构造好路由表之后,调用查询模块,具体查询步骤如下:
第一步:把要查询的目的ip地址e1e2e3e4(其中e代表一个8位由0,1字符组成的字符串)倒置,得到q(e4e3e2e1)。
第二步:根据q查询在构造模块中构造好的哈希表,来加快回溯查找中开始点的定位问题。首先查表1,用hash算法计算q的前3个字节(从后往前数,下同)的哈希值,找到相应的数据链表头,再根据数据链表头指向的存储位置进行逐一的查找比对key值。如果有匹配key,则取出匹配ip地址u[8]的索引值,具体步骤如图4所示。如果在表1中没有找到位置和key值都相等的表项,则开始定位q的前2个字节有无匹配,同样的原理查表2,(如有则返回value中的索引值u[16],以便回溯查找第3个字节),如果无则查表3,定位q的第一个字节有无匹配(如有则返回value中的索引值u[24],以便回溯查找第2个字节),如无则回溯查找第1个字节,具体步骤如图5所示。例如,目的ip地址倒置串q为01010101111000100100011000101011,查找构造模块举例的三张hash表,查找表1无与之匹配的表项;则返回查找表2,计算目的ip后两个字节hash值,找到相等的hash(x),在这一数据链表头下有匹配的表项0100011000101011,则取出key对应的value为16。
第三步:遍历后缀数组a,则a[i]=16对应的字符即为最开始的查找点o,然后以o点依次回溯查找,得到q串的最长公共前缀lcp(从右至左)。从bwt变换过程中存在b[i]=v[a[i]-1]的关系,因此通过查找后缀数组a[i]位置上的字符,可以得到a[i]的前继字符。比如查找到a[1],可得到a[1]的前继字符b[1],所以利用这个性质,逐个比较目的ip与字符串v的字符。遍历c[0]和c[1],用来计算rank[0]与rank[1],在后缀数组中rank值相同的同一字符一一映射对应,当最长公共前缀lcp与目标ip地址q串完全匹配,则查找成功,定位查找最后一个匹配字符在路由表中的索引位置,若与无匹配结果,则在路由表中无此目的ip地址。
根据图5所示流程找到o点的索引位置后,实现字节匹配,只需要从这个索引位置开始匹配q串剩余的字符,因为每一个ipv4地址有32位,由n个ip地址组成的字符串v数据庞大,介于篇幅有限,下面我们以字符串”110101001110$”为例代表字符串v,实现从v中查找目标子串=”100”,来展示这一个回溯查找余下字符的具体过程。
索引:0123456789101112
v:110101001110$
q:001
此例回溯查询的具体步骤如下:
第一步,通过构造模块,我们将原文v=”110101001110$”构造后缀数组我们得到sa={{12}{11,6,4,2,7}{5,3,1,9,0,8}},根据桶排序我们可知f数组中第0位为{$},第1-5位为{1},第6-12位为{1},从而得到f列中0与1的rank数值,v的bwt可以表示为b[i]=v[a[i]-1],即为l数组,在本例中为{01111010011$0}。
第二步,调用搜索模块,在本发明的系统中可以通过查哈希表确定开始查找点o的位置,此例需根据要搜索的目标字符串q=”001”,根据b[i]数组,定位到b[i]=’1’的b[1]-b[4],b[6],b[9]-b[10]这几个开始查找点的位置,通过计数数组c[0]与c[1]的数值,得出相应b[i]对应的rank值,rank值表示的就是当前数组中某个字符出现的次数。由后缀数组rank值的一个性质,rank值相等即表示此字符在两列都是在出现的第几次的位置上,向前回溯至在f中rank值相等并且f[i]=’1’的对映位置,此过程为一个映射的过程。
根据对映位置的b[i]=v[a[i]-1]可以计算得到下一个待匹配的字符,通过轮询只有b[7],b[8],b[12]与待匹配的目的地址ip第二个字符’0’相符,由此同样的原理按照rank值相等继续回溯至f[3]-f[5]。根据对映位置b[i]=v[a[i]-1]得b[3]=v[6-1]=v[5]=’1’,b[4]=v[2-1]=’1’,b[5]=v[6]=’0’由此得到,与目标ip地址完全匹配的最后一行只有b[5]=’0’,然后根据’0’的rank值回溯查找至f[2]。
第三步,定位模块:将目标ip在v串中的具体位置返回给存储器。
具体位置返回主要分为两种情况:如果f[2]是路由表中以定长为d标记得标记点,在查询模块中已经将对f数组中标记点所对应的v串的位置信息一起记录下来了,则返回位置为标记点f[2]所对应的在v串中位置信息v[2]=6,可得目标ip字符串q在v串索引为6的位置;若是不为标记点,则继续回溯至最近的标记点,最后将标记点所对应的原文位置信息减去回溯转换次数c,从而得到目标ip地址的准确位置。
相同或相似的标号对应相同或相似的部件;
附图中描述位置关系的用于仅用于示例性说明,不能理解为对本专利的限制;
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!