一种基于线性网络编码的数据传输优化方法与流程
本发明属于通信技术领域,具体涉及一种基于线性网络编码的数据传输优化方法。
背景技术:
车联网(vehicularadhocnetwork,vanet)作为物联网(internetofthings,iot)和智能交通系统(intelligenttransportsystems,its)的融合体,是以车内网、车际网和车载移动互联网为基础,连接车载设备,手持设备、路侧设备等通信终端以及移动互联网基础设施,进行无线通讯和信息交换的大规模网络。随着宽带移动通信技术的迅速发展和广泛应用,以及数字化、网络化、信息化与智能化技术的快速进步,以车、路和人为主题的通信网络正在逐步建立。车载终端(包括司机和乘车人的智能手机等)作为接入移动互联网的移动终端,大范围、高参与度地加入到移动互联网的数据传输业务,以及成为未来移动互联网络发展的必然趋势。各种典型和新兴服务类型在内的vanet信息服务将以文字、图片、音频和视频等多种信息类型全面搭载在数量庞大的、附属在车、路和人上的智能终端构成的vanet之上。随着各类信息服务的完善与普及,vanet中的数据传输流量将呈现出爆炸式增长。在vanet这个复杂耦合的通信系统当中,不断提高的数据传输需求将给承载网络带来巨大的传输压力。vanet的数据传输负载能力将面临挑战。
vanet中网络环境的动态多变、物理环境的复杂多样、信息(空间)环境的数据海量性与稀疏性并存,这使得一些传统的网络和数据传输技术难以对vanet下的数据传输提供很好的支持,而这要求vanet下的数据传输更加地高效并且要求数据的传输足够地稳定和可靠。
在传输过程中采用网络编码技术能够提高传输的稳定性和可靠性。卢冀等学者中提出的适用于无线网络的广播重传方法即满足了对数据传输的高效性要求,同时也减少了数据包的重传,该方法在基站选择编码数据包的依据是最小重传次数。对于需要重传的数据包,利用kimy提出的机会式网络编码方法进行编码,这样做可以使得重传的次数有效减少,最终在目的端从所有重传的数据包中恢复出丢失的数据包,从而提高目的端恢复丢失数据包的概率。为了提高无线网络中传输的可靠性和网络资源的利用率,代仕芳等学者利用网络编码技术来达到该目标。车辆在道路上的运动轨迹具有随机性,但是如果提前知道车辆的运动轨迹,那么就可以提前获取到热点,并将从中继处接收到的有用信息通过网络编码技术编码后传输到未来要到达这些热点传输范围内的车辆,zhangd,yeock等采用了这种思想,即提前预测车辆的运动轨迹。路边基础设施作为多跳通信中可用的中继,当其与车辆节点之间的信道质量降低时,网络连通性就会相应的降低,为了提高网络连通性,学者khlass采用了协作中继的方法,同时,当车辆节点与路边基础设施之间进行双向通信时,将引入模拟网络编码技术,从而提高车辆节点与路边基础设施之间的通信效率。上面这些文献都利用网络编码技术提高了网络性能,这说明网络编码技术在提供网络性能方面的可行性。wuy等将网络编码运用到两个用户通过多跳进行数据交互的通信环境中,在此基础上提出了一种分布式方案。为了减少数据传输的次数,谢勇等学者提出了一种基于网络编码技术的数据分发算法。为了提高车辆密集场景下数据传输的性能并保证数据传输的可靠性,马宁提出了一种基于代间渐进网络编码的数据传输策略,代间渐进网络编码是对传统代内网络编码的改进,即后代编码数据包包含了其之前所有代的数据包,目的车辆节点在丢包的情况下可通过后代编码数据包恢复出丢失的编码数据包,并能及时解码出源数据包。
从以上关于线性网络编码技术的描述可以看出,目前的研究重心是如何减少数据包在传输过程中的丢包率和数据包被篡改的可能性,减少数据包的重传,保证了数据传输过程中的可靠性。但对于传统数据传输方法中数据传输效率低的问题还没有有效的解决办法。
技术实现要素:
本发明的目的在于解决传统数据传输方法中数据传输效率低的问题,为此提出一种基于线性网络编码的数据传输控制优化方法,该方法在发送端对原始数据进行分组加工,在对这些分组信息进行编码操作后,将其转发给下一中继车辆,当中继接收到上一车辆转发过来的数据后,会在进行重编码操作后再转发给下一中继车辆,依此类推,直到数据信息到达目的端,目的端车辆对接收到的数据信息进行解码操作,恢复出原始数据。
本发明为解决上述技术问题所采取的技术方案是一种基于线性网络编码的数据传输优化方法,具体包括如下步骤:
步骤1:在发送源将需要传输的数据信息进行分组,然后采用线性网络编码技术对这些分组数据进行编码;
步骤2:将编码后的分组数据转发到中继车辆,中继车辆对接收到的编码后的数据进行重编码操作,然后进行转发;
步骤3:如果下一跳车辆不是目的端车辆,则重复步骤2;如果下一跳车辆是目的端车辆,则进行以下步骤;
步骤4:目的端车辆接收到数据时,首先进行线性相关计算,如果接收到的数据不具有线性相关性,则接收该数据,否则,不接收;
步骤5:对接收到的数据进行解码操作,恢复出原始数据,如果无法解码出原始数据,则向上一跳中继车辆进行反馈,要求重传;
步骤6:如果目的端车辆仍然无法解码出原始数据,则继续向上一跳中继车辆进行反馈,依此类推,直到目的端车辆能够解码出原始数据。
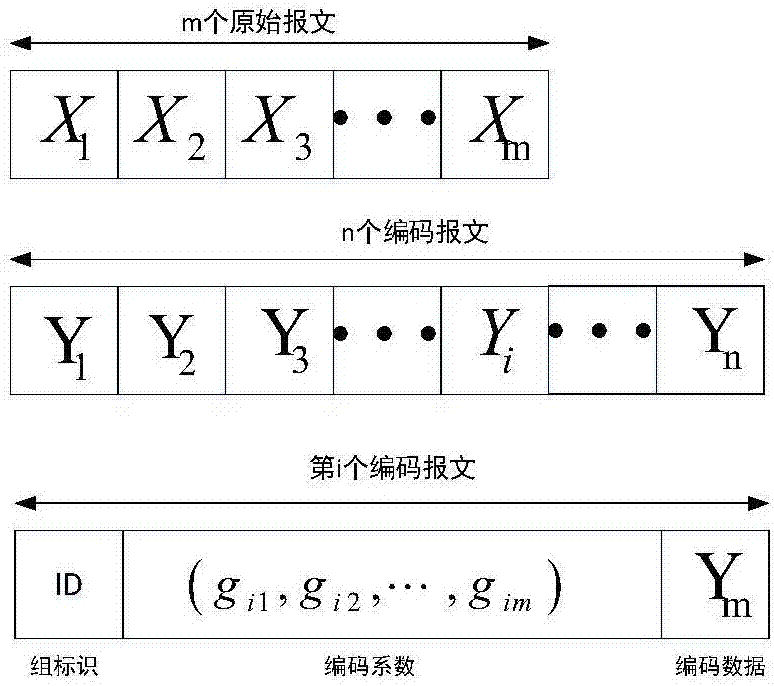
进一步,上述步骤1中所述的分组和编码具体为:在发送节点处,先将需要发送的数据包分成若干组,每组数据包包含m个数据报文,原始数据用xi(xi∈{1,2,…,m})来表示,然后从有限域fq中选取m个编码系数(gi1,gi2,…,gim),将其添加到对应报文的头部,同时在报文头部添加分组标志,以区分编码后的数据,按照下式所示的编码规则将上述分组数据包进行编码:
其中,gij是随机选取的参数,涉及的“乘”操作和“加”操作都是在galois域gf(2q)上进行的,在分组数据xi头部添加分组id和一个代码向量
为了统计剩余分组数据量,在发送节点设置一个初始值为m'的计数器,其中m'>m,每发送一个编码数据,计数器就相应地减1,发送节点直到计数器变为0时才会终止编码数据的发送。
上述步骤2中所述重编码操作和转发具体包括:假定中继节点接收到k个编码报文y1,y2,…,yk,而(gi1,gi2,…,gim)为该报文对应的编码系数,其中xi=1,2,…,k,根据编码规则和
根据上式可知,ylr是原始分组数据的随机线性组合,其中编码系数
在进行步骤5所述的解码操作时,当目的车辆接收到的分组数据数大于发送车辆发送的分组数据数时,且所有分组数据之间不具备相关性时,下面的方程组有解,即此时可以利用高斯消元法对方程组进行求解,从而恢复出原始数据,假定目的车辆共接收到y1,y2,…,ym共m份数据,这些数据对应的编码系数为(gi1,gi2,…,gim),(i=1,2,…,m),为了判断能否解码出原始数据,首先判断这些编码系数的相关性,如果编码系数组成的矩阵
与现有技术相比,本发明的有益效果:
1、本发明在传统的数据传输过程中引入了线性网络编码技术,数据通过线性网络编码技术合成一个数据包进行发送,加大了分组编码数据之间的耦合程度,能够有效减少数据在传输过程中的丢包率,从而减少数据的重传次数。
2、本发明在传输过程中采用了线性网络编码技术导致的重传次数的减少,从而减少的传输过程中所消耗的带宽。
3、本发明在传输过程中采用了线性网络编码技术能够在目的端更好的保证数据的完整性,提高了数据包的交付率。
附图说明
图1为本发明的方法流程图。
图2为网络编码的报文格式。
具体实施方式
下面结合说明书附图对本发明创造作进一步的详细说明。
vanet中以车辆作为节点,其数据传输过程如图1所示主要分为三个过程,发送节点编码、中继节点重传和转发、目的节点解码,具体分析如下:
首先是发送节点编码。在发送节点处,先将需要发送的数据包(即原始数据)分成若干组,每组数据包包含m个数据报文,原始数据用xi(xi∈{1,2,…,m})来表示。然后从有限域fq中选取m个编码系数(gi1,gi2,…,gim),将其添加到对应报文的头部,同时在报文头部添加分组标志,以区分编码后的数据。按照公式1所示的编码规则将分组数据包进行编码。
其中,gij是随机选取的参数,涉及的“乘”操作和“加”操作都是在galois域gf(2q)上进行的。在分组数据xi头部添加分组id和一个代码向量
接下来是中继节点的重传和转发。在接收端需要将分组数据进行还原,同组编码报文对于数据的还原必不可少。为了减少编码报文之间的相互干扰,需要对同组编码报文进行集中发送。在中继车辆簇中,车辆节点间配合着接收分组数据,同时为了区分同组编码报文,对编码的分组数据也需要进行标识。在对同组编码报文进行缓存的过程中,该中继簇与下一簇之间会进行信息交互,该信息中包含同组编码报文的完整程度。在整个发送过程中,中继簇拥有发送和接收双重身份。假定中继节点接收到k个编码报文y1,y2,…,yk,而(gi1,gi2,…,gim)为该报文对应的编码系数,其中xi=1,2,…,k。根据编码规则(公式1)和公式2,中继节点产生的新编码报文数是k,然后将新报文继续向下一跳中继车辆传输。
将公式2进行变形:
根据公式3可知,ylr是原始分组数据的随机线性组合,其中编码系数
同样地,当中继车辆转发分组数据时,同样会在ylr的分组数据头部添加一个新的编码向量hj=(gi1,gi2,…,gim)。
最后是目的节点解码。目的车辆节点接收到的数据众多,而这所有接收到的数据并不全部是目的车辆所需要的,因此,为了提高效率,需要辨别出所需要的数据,仅对该部分数据进行解码操作。当所有分组数据被目的车辆接收后,首先要进行相关性的计算,如果分组数据没有重复被收到,则其没有线性相关性,则将该数据进行保存,否则进行舍弃。所有编码分组的编码系数对目的车辆是已知的,表示为公式5,通过对该方程组的求解,就可以恢复出原始数据。然而,根据数学知识可知,公式5并不总是有解的。当目的车辆接收到的分组数据数大于发送车辆发送的分组数据数时,且所有分组数据之间不具备相关性时,方程组有解,即此时可以利用高斯消元法对方程组进行求解,从而恢复出原始数据。假定目的车辆共接收到y1,y2,…,ym共m份数据,这些数据对应的编码系数为(gi1,gi2,…,gim),(i=1,2,…,m),为了判断能否解码出原始数据,首先判断这些编码系数的相关性,如果编码系数组成的矩阵
根据公式5可知,如果目的车辆接收到的同组报文数量不足,则所需要的编码系数组成的矩阵不满足满秩的条件,通过目的车辆就无法解码出全部的原始数据。当目的车辆无法解码获得全部原始数据时,为了寻找同组编码数据报文,就需要向上一跳中继车辆进行反馈,如果仍没有找到,则继续向上一跳反馈,直到找到足够解码出全部原始数据的同组编码报文。
以上所述的仅是本发明的优选实施方式。应当指出,对于本领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干变形和改进,这些也应视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!