播发服务状态的抽样监控方法与流程
本发明涉及播发服务技术领域,特别涉及一种播发服务状态的抽样监控方法。
背景技术:
大规模高精度定位播发服务,通常使用网格(提供差分解算结果的最小单元)技术,将服务覆盖区域网格化。例如,服务要覆盖全中国(总960万平方公里),按照每个网格25平方公里,则大约需要40万个网格。
任何一个网格异常,都直接导致这个区域服务异常,因此需要监控每个网格的服务状态。
现有技术的技术方案通常如下:
使用软件模拟方案,让每个网格中均有一个虚拟用户,同时周期性触发定位请求,探测网格的服务状态,进而实现全国服务状态监控。
由于播发服务使用ntrip协议(在互联网上进行差分数据传输的协议,基于tcp/ip,属于应用层协议,差分数据即定位纠偏数据),而ntrip基于tcp长连接实现,也就是说每个网格,都与服务器建立长连接,因此服务端需要支持约40万的并发连接数。这个资源消耗非常大。每台服务器在保证系统稳定的前提下,通常最多只能提供3万个长连接。这还只是理论的情况,因为这些连接还需要共享服务器的cpu及内存资源。在播发服务这个特定场景下,按每个连接占用2.5m的内存计算,一台16g的服务器,实际情况下最多只能提供4千个长连接,也就是说只能监控约4千个网格。
由此可见,监控全国服务状态,大约需要使用100台监控服务器。这个成本非常大。
技术实现要素:
基于上述问题,本发明提出一种播发服务状态的抽样监控方法,能够使用少量服务器资源,快速监控海量网格的状态,大大降低了成本。
本发明采用的技术方案是:
一种播发服务状态的抽样监控方法,采用uml实体模型,所述uml实体模型包括三角组网表、服务器表和网格表;三角组网表存储了组网的信息;服务器表存储了服务器的信息;网格表存储了所有网格的信息。
进一步地,所述网格表使用ischeck字段,用于保存所述网格表是否是抽样选中的网格表。
进一步地,所述组网的信息包括物理基站、三角组网状态;所述服务器的信息包括ip地址、服务器状态;所述网格的信息包括网格名、网格与组网的关联关系、以及与服务器的关联关系。
进一步地,所述抽样监控方法包括randomassign过程;fetchgridbyip过程、checkgridstatus过程和updategridstatus过程,监控对象包括服务器表和数据库。
进一步地,所述randomassign过程包括:
服务器表在每个三角组网表内随机分配一个网格表,作为所述三角组网表的状态监控网格;数据库操作则是维护网格表的ischeck字段;
将所有标有ischeck的网格表,平均分配到所有服务器表上;数据库操作则是维护网格表的serverid字段。
进一步地,所述fetchgridbyip过程用于获取服务器表需要监控的网格表。
进一步地,所述获取服务器表需要监控的网格表步骤如下:
首先获取ip在服务器表查询服务器id,然后根据serverid在网格表中查询网格的信息,最后返回网格表。
进一步地,所述checkgridstatus过程用于逐一检查获取到的网格表中网格的信息。
进一步地,所述checkgridstatus过程使用多线程技术。
进一步地,所述updategridstatus过程负责将返回的网格的信息批量写入到数据库中。
本发明播发服务器在差分解算(即差分数据的计算过程)过程中,使用三角组网(由三个邻近的物理基站组成的三角形区域)技术,在同一个三角组网内的所有网格具有以下特点:
1、相同的解算结果;
2、相同的服务状态。
由于同一个三角组网内的所有网格都具有相同的服务状态,也就是说这些网格如果发生异常,则会同时异常,恢复正常时也将同时恢复。同一个三角组网,只需要抽样监控一个网格即可。因此本发明的有益效果在于,需要用到的监控服务器数量将成倍数下降,显著降低了成本。
附图说明
图1是本发明uml实体模型。
图2是本发明流程时序图。
具体实施方式
本发明播发服务在差分解算过程中,使用三角组网技术,即一定区域内的网格,使用同一个三角组网的解算结果。下文中,结合附图和实施例对本发明作进一步阐述。
本发明采用uml实体模型,如图1所示,总共有3张核心表,其中:
如下图所示,总共有3张核心表,其中:
1、三角组网表,存储了组网的信息,包括物理基站、三角组网状态等信息;
2、服务器表,存储了服务器的信息,包括ip地址、服务器状态等;
3、网格表,存储了所有网格的信息,包括网格名、网格与组网的关联关系、以及与服务器的关联关系。另外需要特别注意,因为是抽样监控,使用了ischeck字段,用于保存此网格表是否是抽样选中的网格。
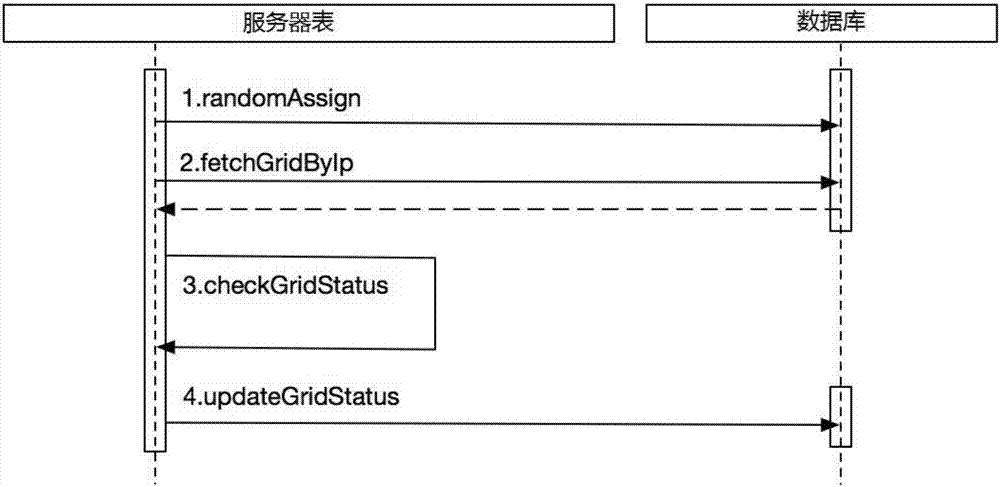
图2是本发明流程时序图,整个过程涉及到服务器表及数据库两个角色,详细的交互运行过程如下:
1、函数randomassign。这个过程主要有两个工作:
1.1、服务器表会在每个三角组网表内随机分配一个网格表,作为这个三角组网的状态监控网格。相应的数据库操作则是维护网格表的ischeck字段;
1.2、将所有标有ischeck的网格,平均分配到所有服务器表上。相应的数据库操作则是维护网格表的serverid字段。
2、函数fetchgridbyip。这个过程主要是获取本服务器表需要监控的网格表。首先获取ip在服务器表查询服务器id(serverid),然后根据serverid在网格表中查询网格的信息,然后返回网格表。
3、函数checkgridstatus。这个过程主要是逐一检查上一步中获取到的网格表中网格的信息。通常情况下会使用多线程技术,以更快的速度获取状态结果。
4、函数updategridstatus。这个过程则负责将上一步中返回的网格的信息,批量写入到数据库中
在本发明实施例中优先使用java语言来进行开发,java语言成熟的nio(非阻塞的io编译模型)网络通信及多线程开发类库,非常适合本发明所提到的tcp长连接等场景。
有一种替代方案,也可以实现本发明目的,使用较少的机器,监控大规模播发服务:降低探测频率。如将原本每20秒探测,修改为每40秒探测一次,系统占用资源将减少近一半。
本发明虽然已以较佳实施例公开如上,但其并不是用来限定本发明,任何本领域技术人员在不脱离本发明的精神和范围内,都可以利用上述揭示的方法和技术内容对本发明技术方案做出可能的变动和修改,因此,凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化及修饰,均属于本发明技术方案的保护范围。
技术特征:
技术总结
一种播发服务状态的抽样监控方法,采用UML实体模型,所述UML实体模型包括三角组网表、服务器表和网格表;三角组网表存储了组网的信息,包括物理基站、三角组网状态;服务器表存储了服务器的信息,包括IP地址、服务器状态;网格表存储了所有网格的信息,包括网格名、网格与组网的关联关系、以及与服务器的关联关系,网格表使用isCheck字段,用于保存网格表是否是抽样选中的网格表。本发明采用三角组网,只需要抽样监控一个网格即可,这样需要用到的监控服务器数量将成倍数下降。
技术研发人员:肖应军;宋飞
受保护的技术使用者:千寻位置网络有限公司
技术研发日:2017.04.18
技术公布日:2017.07.25
- 还没有人留言评论。精彩留言会获得点赞!