一种风险分析设备、监控系统和监控方法与流程
本发明涉及信息管理技术领域,尤指一种风险分析设备、监控系统和监控方法。
背景技术:
随着信息技术的发展,互联网逐步成为中小企业的运营主体,作为it基础设施,服务器在企业运营等多方面发挥越来越大的作用。服务器作为网络的计算节点甚至核心,其稳定性一直是为广大企业及用户所关注的问题。一个网站如果长期处于不稳定状态,不仅会对公司的形象造成负面的影响,也会波及到公司的业务,进而对公司造成极大的经济损失。
但是,随着it设备规模的不断增加,it设备故障的告警种类与告警数量也随之急剧增加。由于造成网络问题的因素多种多样,当用户使用过程中遇到故障时,依靠个人经验逐一排查故障原因,分析定位问题效率低下。
如何提前发现风险,以及如何在遇到故障时快速排查故障原因,目前尚未提出有效的解决方案。
技术实现要素:
为了解决上述技术问题,本发明提供了一种风险分析设备、监控系统和监控方法,能够进行风险预判,并能够提高故障定位速度。
为了达到本发明目的,本发明实施例的技术方案是这样实现的:
本发明实施例提供了一种风险分析设备,包括比较模块和分析模块,其中,
所述比较模块,用于将被监控服务的性能监控数据和调用栈数据,与预先设置的若干个监控阈值进行比较,当所述性能监控数据或所述调用栈数据超过所述预先设置的监控阈值时,通知所述分析模块;
所述分析模块用于接收到所述比较模块的通知,将所述性能监控数据和所述调用栈数据与预先存储的告警或故障案例的数据进行匹配对比,判断所述被监控服务是否存在潜在风险或故障。
进一步地,所述性能监控数据包括所述被监控服务的内存使用量、cpu使用率、硬盘读写速度、线程数和并发访问量数据。
进一步地,所述调用栈数据包括两个或两个以上的所述被监控服务间的接口调用耗时,以及单个所述被监控服务内的不同函数间的内存使用量、cpu使用率、线程数、并发访问量和方法耗时。
进一步地,所述分析模块具体用于,将所述性能监控数据和所述调用栈数据在预设时间段内的区间走势,与所述预先存储的告警或故障案例的数据进行匹配度对比,选择匹配度分值高于预设的匹配度阈值的告警或故障案例作为所述潜在风险或故障。
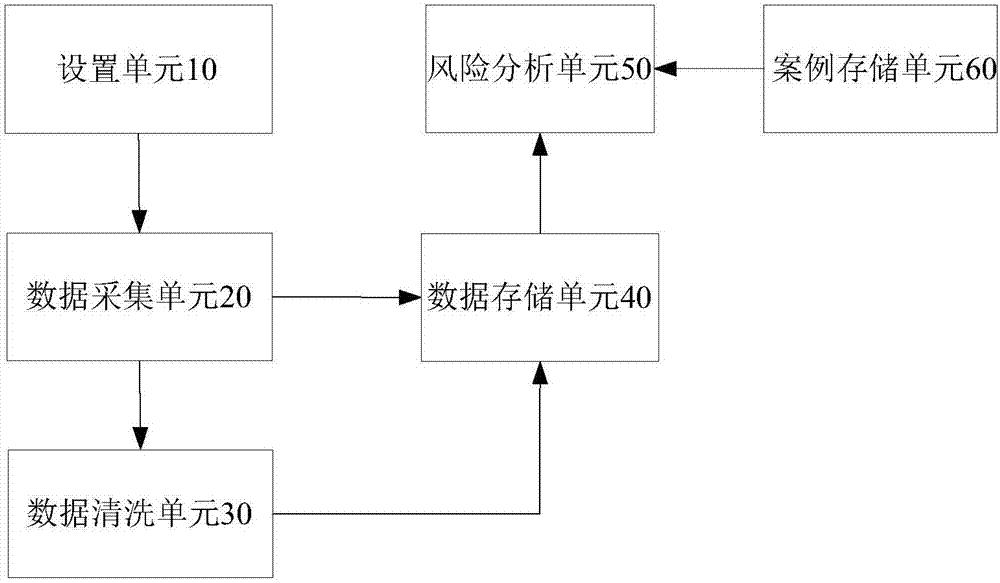
本发明实施例还提供了一种监控系统,包括设置单元、数据采集单元、数据清洗单元、数据存储单元、案例存储单元和风险分析单元,其中,
所述设置单元用于预先设置若干个被监控服务,并将其分配给所述数据采集单元;
所述数据采集单元用于采集所分配的被监控服务的性能监控数据和调用栈数据,并将所述性能监控数据存入所述数据存储单元,将所述调用栈数据传输至所述数据清洗单元;
所述数据清洗单元用于对来自所述数据采集单元的调用栈数据进行数据清洗和整合加工,将整合加工后的调用栈数据存入所述数据存储单元;
所述案例存储单元,用于存储告警或故障案例;
所述风险分析单元用于将所述数据存储单元中的性能监控数据和调用栈数据,与预先设置的若干个监控阈值进行比较,当所述性能监控数据或所述调用栈数据超过所述预先设置的监控阈值时,将所述性能监控数据和所述调用栈数据与所述案例存储单元中的告警或故障案例的数据进行匹配对比,判断所述被监控服务是否存在潜在风险或故障。
进一步地,所述数据清洗单元具体用于:识别并剔除所述调用栈数据中的孤立数据,将分散的调用栈数据整合加工到一起。
进一步地,所述风险分析单元具体用于,当所述数据存储单元中的所述性能监控数据或所述调用栈数据超过所述预先设置的监控阈值时,将采集的所述性能监控数据或所述调用栈数据在预设时间段内的区间走势,与所述案例存储单元中存储的所述告警或故障案例的数据进行匹配度对比,选择匹配度分值高于预设的匹配度阈值的告警或故障案例作为所述潜在风险或故障。
本发明实施例还提供了一种监控方法,包括:
预先设置若干个被监控服务;
采集所有被监控服务的性能监控数据和调用栈数据,将性能监控数据存入数据库;
对调用栈数据进行数据清洗和整合加工,将整合加工后的调用栈数据存入数据库;
将数据库中的性能监控数据和调用栈数据,与预先设置的若干个监控阈值进行比较,当性能监控数据或调用栈数据超过预先设置的监控阈值时,将所述性能监控数据和所述调用栈数据与预先存储的告警或故障案例的数据进行匹配对比,判断被监控服务是否存在潜在风险或故障。
进一步地,所述对调用栈数据进行数据清洗和整合加工,具体包括:
识别并剔除所述调用栈数据中的孤立数据,将分散的调用栈数据整合加工到一起。
进一步地,所述将所述性能监控数据和所述调用栈数据与预先存储的告警或故障案例的数据进行匹配对比,具体包括:
将采集的所述性能监控数据或所述调用栈数据在预设时间段内的区间走势,与所述预先存储的告警或故障案例的数据进行匹配度对比,选择匹配度分值高于预设的匹配度阈值的告警或故障案例作为所述潜在风险或故障。
本发明的风险分析设备、监控系统和监控方法,通过采集被监控服务的性能监控数据和调用栈数据,将其与预先设置的监控阈值进行比较,并将所述性能监控数据和所述调用栈数据与预先存储的告警或故障案例的数据进行匹配对比,进而实现了风险预判与故障排查,提高了故障定位速度;同时,本发明结合案例存储单元,智能提供风险解决与故障处理方案,尽可能地缩短了故障的恢复周期,从而提升了故障解决效率和服务的可用性。
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本申请的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1为本发明第一实施例的一种风险分析设备的结构示意图;
图2为本发明第一实施例的一种监控系统的结构示意图;
图3为本发明第二实施例的一种监控系统的结构示意图;
图4为本发明第三实施例的一种监控系统的结构示意图;
图5为本发明第四实施例的一种监控系统的结构示意图;
图6为本发明第一实施例的一种监控方法的流程示意图。
具体实施方式
下面将结合附图及实施例对本发明的技术方案进行更详细的说明。
现在将参考附图描述实现本发明各个实施例的移动终端。在后续的描述中,使用用于表示元件的诸如“模块”、“部件”或“单元”的后缀仅为了有利于本发明的说明,其本身并没有特定的意义。因此,"模块"、"部件"或“单元”可以混合地使用。
参考图1,根据本发明的一种风险分析设备,包括比较模块1和分析模块2,其中:
比较模块1,用于将被监控服务的性能监控数据和调用栈数据,与预先设置的若干个监控阈值进行比较,当性能监控数据或调用栈数据超过预先设置的监控阈值时,通知分析模块;
分析模块2,用于接收到比较模块的通知,将所述性能监控数据和所述调用栈数据与预先存储的告警或故障案例的数据进行匹配对比,确定被监控服务是否存在潜在风险或故障。
值得说明的是,本发明所述的性能监控数据包括但不限于被监控服务的内存使用量、cpu使用率、硬盘读写速度、线程数、并发访问量等数据;本发明所述的调用栈数据包括两个或两个以上的被监控服务间的调用链数据(如接口调用耗时等),以及单个被监控服务内的不同函数间的调用栈数据(包括但不限于内存使用量、cpu使用率、线程数、并发访问量、方法耗时等);本发明所述的监控阈值包括但不限于被监控服务的内存使用量阈值、cpu使用率阈值、硬盘读写速度阈值、线程数阈值、并发访问量阈值、接口调用耗时阈值、方法耗时阈值等。
另外,需要说明的是,本发明的风险分析设备,强调的是同时通过被监控服务的性能监控数据和调用栈(和/或调用链)数据,进行风险预判和故障排查,通过结合这两类数据进行分析,可以提高故障定位速度。
进一步地,所述分析模块2具体用于:将性能监控数据或调用栈数据在预设时间段内的区间走势,与预先存储的告警或故障案例的数据进行匹配度对比,选择匹配度分值高于预设的匹配度阈值的告警或故障案例作为潜在风险或故障。
参考图2,根据本发明的一种监控系统,包括设置单元10、数据采集单元20、数据清洗单元30、数据存储单元40、风险分析单元50和案例存储单元60,其中,
设置单元10,用于预先设置若干个被监控服务,并将其分配给数据采集单元20;
数据采集单元20,用于采集所分配的被监控服务的性能监控数据和调用栈数据,并将性能监控数据存入数据存储单元40,将调用栈数据传输至数据清洗单元30;
数据清洗单元30,用于对来自数据采集单元20的调用栈数据进行数据清洗和整合加工,将整合加工后的调用栈数据存入数据存储单元40;
数据存储单元40,用于存储来自数据采集单元20的性能监控数据和来自数据清洗单元30的调用栈数据;
案例存储单元60,用于存储告警或故障案例;
风险分析单元50,用于将数据存储单元40中的性能监控数据和调用栈数据,与预先设置的若干个监控阈值进行比较,当性能监控数据或调用栈数据超过预先设置的监控阈值时,将所述性能监控数据和所述调用栈数据与案例存储单元60中的告警或故障案例的数据进行匹配对比,判断被监控服务是否存在潜在风险或故障。
值得说明的是,本发明所述的性能监控数据包括但不限于被监控服务的内存使用量、cpu使用率、硬盘读写速度、线程数、并发访问量等数据;本发明所述的调用栈数据包括两个或两个以上的被监控服务间的调用链数据(如接口调用耗时等),以及单个被监控服务内的不同函数间的调用栈数据(包括但不限于内存使用量、cpu使用率、线程数、并发访问量、方法耗时等);本发明所述的监控阈值包括但不限于被监控服务的内存使用量阈值、cpu使用率阈值、硬盘读写速度阈值、线程数阈值、并发访问量阈值、接口调用耗时阈值、方法耗时阈值等。
进一步地,所述设置单元10包括配置管理数据库100和资源协调服务模块101,其中,
配置管理数据库100,用于存储若干个被监控服务,每个被监控服务包括若干个配置信息;
资源协调服务模块101,用于通过分布式资源协调服务,将若干个被监控服务分配给若干个数据采集单元20。
具体地,所述的配置信息包括被监控服务的ip地址、端口号等信息。
具体地,所述分布式资源协调服务,可以通过zookeeper分布式协调服务实现。zookeeper是一个分布式开源协调服务框架,是apachehadoop的一个子项目,为分布式应用提供高效、高可用的分布式协调服务,提供了诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知和分布式锁等分布式基础服务。
进一步地,所述数据采集单元20包括性能监控数据收集模块201、调用栈数据收集模块202,其中,
性能监控数据收集模块201,用于采集被监控服务的性能监控数据,并将其存入数据存储单元40;
调用栈数据收集模块202,用于采集被监控服务的调用栈数据,并将调用栈数据传输至数据清洗单元30。
在本发明一实施例中,性能监控数据收集模块201可以通过主动拉取或被动推送两种方式采集被监控服务的性能监控数据。当采用主动拉取方式时,性能监控数据收集模块201对被监控服务的性能监控数据进行周期性的采集,然后存入数据存储单元40;当采用被动推送方式时,在被监控服务的物理服务器上安装第一代理(agent)程序,第一代理程序周期性地收集其所在物理服务器的性能监控数据,然后由性能监控数据收集模块201将已收集的数据存入数据存储单元40。
在本发明一实施例中,调用栈数据收集模块202,在被监控服务的物理服务器上安装第二代理(agent)程序,由第二代理程序收集其所在物理服务器的调用栈数据,并将调用栈数据暂存于所在物理服务器的本地文件系统中;通过日志收集程序,将暂存的调用栈数据传输至数据清洗单元30。
具体地,所述的日志收集程序为flume日志系统。flume是一个高可用的、高可靠的、分布式的海量日志采集、聚合和传输的系统,flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,flume提供对数据进行简单处理,并写到各种数据接收方的能力。
进一步地,所述数据清洗单元30具体用于:识别并剔除调用栈数据中的孤立数据,将零散的调用栈数据整合加工到一起。
具体地,数据清洗单元30通过映射化简(mapreduce)技术对来自数据采集单元20的调用栈数据进行数据清洗和整合加工。mapreduce最早是由google公司研究提出的一种面向大规模数据处理的并行计算模型和方法,用于大规模数据集(大于1万亿字节)的并行运算。
具体地,所述数据存储单元40为hbase数据库。hbase是一个分布式的、面向列的开源数据库。
进一步地,所述风险分析单元50还用于,当数据存储单元40中的性能监控数据或调用栈数据,超过预先设置的监控阈值时,将采集的性能监控数据或调用栈数据在预设时间段内的区间走势,与案例存储单元50中存储的告警或故障案例的数据进行匹配度对比,选择匹配度分值高于预设的匹配度阈值的告警或故障案例作为潜在风险或故障。
进一步地,参考图3,所述监控系统还包括故障处理单元70,其中,
所述风险分析单元50还用于,将潜在风险或故障发送至故障处理单元70;
故障处理单元70,用于对接收的潜在风险或故障进行处理,并将解决的风险或故障存入案例存储单元60。
进一步地,所述故障处理单元70,对解决的风险或故障进行评审,并将评审通过的风险或故障存入案例存储单元60。
值得说明的是,本申请中所述的评审通过的风险或故障,指的是包含正确的解决方案的风险或故障。
进一步地,参考图4,所述监控系统还包括报警单元80,其中,
所述风险分析单元50还用于,将潜在风险或故障发送至报警单元80;
报警单元80,用于将潜在风险或故障通过短信、邮件或语音电话等通道推送至系统负责人。
在本发明一具体实施例中,假设当采集的性能监控数据中的内存使用量超出预设的内存使用量阀值时,风险分析单元50从数据存储单元40中将同一时刻的调用栈数据取出,分析调用栈中是否存在哪个环节调用出现内存消耗加大的问题,并将分析结果通过报警单元推送至系统责任人;然后将性能监控数据和调用栈数据在预设时间段内的区间走势,与案例存储单元60中的告警或故障案例数据进行匹配度对比,若存在匹配度分值高于预设的匹配度阈值的告警或故障案例,则判断被监控服务存在潜在风险或故障,并将分析结果通过报警单元推送至系统责任人;
假设当采集的调用栈cpu使用率超出预设的cpu使用率阀值时,风险分析单元50从数据存储单元40中将同一时刻的性能监控数据中的cpu消耗数据取出,分析cpu消耗是否存在递增趋势,若cpu消耗存在递增趋势,则判断存在cpu耗尽风险,并将分析结果通过报警单元推送至系统责任人;然后将性能监控数据和调用栈数据在预设时间段内的区间走势,与案例存储单元60中的告警或故障案例数据进行匹配度对比,若存在匹配度分值高于预设的匹配度阈值的告警或故障案例,则判断被监控服务存在潜在风险或故障,并将分析结果通过报警单元推送至系统责任人;
假设被监控服务出现宕机,则从数据存储单元40中获取性能监控数据和调用栈数据,并将其在预设时间段内的区间走势,与案例存储单元60中的故障案例进行匹配度对比,若存在匹配度分值高于预设的匹配度阈值的故障案例,则将其通过报警单元推送至系统责任人。
参考图5,在本发明一具体实施例中,以zookeeper资源协调服务为基础搭建分布式任务监控集群,以flume日志收集服务为基础搭建调用栈数据追踪系统集群,以hbase分布式存储为性能监控数据或调用栈数据的数据仓库,以mysql为基础搭建故障处理备忘平台,使用scala(一种多范式编程语言)、spark(专为大规模数据处理而设计的快速通用的计算引擎)等大数据工具为基础搭建风险分析中心。
管理中心平台,主要负责被监控服务的相关关键信息配置管理,如被监控服务的ip地址、端口号、性能监控数据和调用栈数据的监控阀值等;以及负责已采集的被监控服务的性能监控数据和调用栈数据的查看;
性能监控数据收集中心,主要负责读取配置管理数据库中的配置信息,持久化到zookeeper资源协调服务上;然后再根据zookeeper资源协调服务实现分布式任务监控集群的分布式任务调度;性能监控数据收集中心的数据收集方法分为两类:主动拉取与被动推送。主动拉取指的是分布式任务监控集群对被监控服务进行周期性的性能监控数据采集,然后存入分布式性能监控数据存储仓库;被动推送指的是在被监控服务的物理服务器上安装相应的代理(agent)探针,代理探针周期性地收集宿主物理服务器上的性能监控数据,并主动调用分布式任务监控集群的服务,通过分布式任务监控集群的服务将已收集的数据持久化到分布式性能监控数据存储仓库;
调用栈数据追踪系统集群,通过以代理(agent)方式植入到被监控服务的物理服务器上,对被监控服务进行无侵入式的调用栈(和调用链)数据采集,暂存于本地文件系统中;使用flume日志收集服务,将暂存的数据信息传送到数据清洗服务集群中,使用mapreduce等相关技术对采集的调用栈(和调用链)数据进行数据清洗和整合加工,并将整合加工后的数据存储到分布式调用栈数据存储仓库;
风险分析中心,主要负责将性能监控数据与调用栈数据这两类数据与预设的监控阀值进行对比,进行风险预判与故障分析;并当性能监控数据或调用栈数据,超过预先设置的监控阈值时,将性能监控数据或调用栈数据在预设时间段内的区间走势,与案例存储数据库中存储的告警或故障案例的数据进行匹配度对比,根据匹配度分值计算排序,将排名前n名(n为自然数,例如n=5)的告警或故障案例作为故障解决备选方案,通过相关渠道推送至系统责任人,促进被监控服务的隐患排除以及性能瓶颈的突破,保障被监控服务的高可用性;
故障处理备忘平台,主要负责在被监控服务的故障排除之后,详细记录此次故障及其解决方案,并由相关人员进行评审,一旦评审通过,则持久化到案例存储数据库中,以备后续其它服务预警或故障时使用;
报警平台,主要负责将潜在风险或故障、故障解决备选方案等相关信息通过邮件、短信、语音电话等通道告知系统责任人。
参考图6,根据本发明的一种监控方法,包括:
步骤601:预先设置若干个被监控服务;
步骤602:采集所有被监控服务的性能监控数据和调用栈数据,将性能监控数据存入数据库;
步骤603:对调用栈数据进行数据清洗和整合加工,将整合加工后的调用栈数据存入数据库;
步骤604:将数据库中的性能监控数据和调用栈数据,与预先设置的若干个监控阈值进行比较,当性能监控数据或调用栈数据超过预先设置的监控阈值时,将所述性能监控数据和所述调用栈数据与预先存储的告警或故障案例的数据进行匹配对比,判断被监控服务是否存在潜在风险或故障。
值得说明的是,本发明所述的性能监控数据包括但不限于被监控服务的内存使用量、cpu使用率、硬盘读写速度、线程数、并发访问量等数据;本发明所述的调用栈数据包括两个或两个以上的被监控服务间的调用链数据(如接口调用耗时等),以及单个被监控服务内的不同函数间的调用栈数据(包括但不限于内存使用量、cpu使用率、线程数、并发访问量、方法耗时等);本发明所述的监控阈值包括但不限于被监控服务的内存使用量阈值、cpu使用率阈值、硬盘读写速度阈值、线程数阈值、并发访问量阈值、接口调用耗时阈值、方法耗时阈值等。
另外,需要说明的是,本发明强调的是同时通过被监控服务的性能监控数据和调用栈(和/或调用链)数据,进行风险预判和故障排查,通过结合这两类数据进行分析,可以提高故障定位速度。
进一步地,在步骤601中,通过分布式资源协调服务,预先设置若干个被监控服务。
具体地,所述分布式资源协调服务,可以通过zookeeper分布式协调服务实现。zookeeper是一个分布式开源协调服务框架,是apachehadoop的一个子项目,为分布式应用提供高效、高可用的分布式协调服务,提供了诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知和分布式锁等分布式基础服务。
在本发明一实施例中,在步骤602中,可以通过主动拉取或被动推送两种方式采集被监控服务的性能监控数据。当采用主动拉取方式时,对被监控服务的性能监控数据进行周期性的采集,并将其存入数据库中;当采用被动推送方式时,在被监控服务的物理服务器上安装第一代理(agent)程序,第一代理程序周期性地收集其所在物理服务器的性能监控数据,然后将已收集的数据存入数据库中。
在本发明一实施例中,在步骤602中,可以通过在被监控服务的物理服务器上安装第二代理(agent)程序,由第二代理程序收集其所在物理服务器的调用栈数据,并将调用栈数据暂存于所在物理服务器的本地文件系统中;通过日志收集程序,将暂存的调用栈数据存入数据库中。
具体地,所述的日志收集程序为flume日志系统。flume是一个高可用的、高可靠的、分布式的海量日志采集、聚合和传输的系统,flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,flume提供对数据进行简单处理,并写到各种数据接收方的能力。
进一步地,在步骤603中,对调用栈数据进行数据清洗和整合加工,具体包括:识别并剔除调用栈数据中的孤立数据,并将零散的调用栈数据整合加工到一起。
具体地,通过映射化简(mapreduce)技术对调用栈数据进行数据清洗和整合加工。mapreduce最早是由google公司研究提出的一种面向大规模数据处理的并行计算模型和方法,用于大规模数据集(大于1万亿字节)的并行运算。
具体地,所述数据库为hbase数据库。hbase是一个分布式的、面向列的开源数据库。
进一步地,所述步骤604中将所述性能监控数据和所述调用栈数据与预先存储的告警或故障案例的数据进行匹配对比,具体包括:将采集的性能监控数据或调用栈数据在预设时间段内的区间走势,与预先存储的告警或故障案例的数据进行匹配度对比,选择匹配度分值高于预设的匹配度阈值的告警或故障案例作为潜在风险或故障。
进一步地,在所述步骤604之后,所述监控方法还包括:
对潜在风险或故障进行处理,并将解决的风险或故障存入案例存储数据库。
进一步地,在所述步骤604之后,所述监控方法还包括:对潜在风险或故障进行处理,并对解决的风险或故障进行评审,将评审通过的风险或故障存入案例存储数据库。
值得说明的是,本申请中所述的评审通过的风险或故障,指的是包含正确的解决方案的风险或故障。
进一步地,在所述步骤604之后,所述监控方法还包括:
将潜在风险或故障通过短信、邮件或语音电话等通道推送至系统负责人。
在本发明一具体实施例中,假设当采集的性能监控数据中的内存使用量超出预设的内存使用量阀值时,获取同一时刻的调用栈数据,分析调用栈中是否存在哪个环节调用出现内存消耗加大的问题,然后对性能监控数据和调用栈数据在预设时间段内的区间走势,与现有的告警或故障案例的数据进行匹配度对比,若存在匹配度分值高于预设的匹配度阈值的告警或故障案例,则判断被监控服务存在潜在风险或故障,将分析结果推送至系统责任人;
假设当采集的调用栈cpu使用率超出预设的cpu使用率阀值时,获取同一时刻的性能监控数据中的cpu消耗数据,分析cpu消耗是否存在递增趋势,若cpu消耗存在递增趋势,则判断存在cpu耗尽风险,然后对性能监控数据和调用栈数据在预设时间段内的区间走势,与现有的告警或故障案例的数据进行匹配度对比,若存在匹配度分值高于预设的匹配度阈值的告警或故障案例,则判断被监控服务存在潜在风险或故障,将分析结果推送至系统责任人;
假设被监控服务出现宕机,则获取性能监控数据和调用栈数据,并将其在预设时间段内的区间走势,与现有的故障案例进行匹配度对比,若存在匹配度分值高于预设的匹配度阈值的故障案例,则将其通过报警单元推送至系统责任人。
本发明的风险分析设备、监控系统和监控方法,通过采集被监控服务的性能监控数据和调用栈数据,并将其与预先设置的监控阈值进行比较,进而实现风险预判与故障排查,能够提高故障定位速度;进一步地,本发明结合案例存储单元,智能提供风险解决与故障处理方案,尽可能地缩短故障的恢复周期,从而提升故障解决效率和服务的可用性。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者装置不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者装置所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者装置中还存在另外的相同要素。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质(如rom/ram、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机,计算机,服务器,空调器,或者网络设备等)执行本发明各个实施例所述的方法。
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!