公共背景噪声下激活式的声纹密码安全控制方法及系统与流程
本发明涉及智能家居的人机交互技术领域,尤其涉及一种公共背景噪声下激活式的声纹密码安全控制方法及系统。
背景技术:
随着社会的发展,语音作为一种媒介出现在人机交互界面中,是社会发展的趋势,相比其它任何一种人与人之间的交流方式来说,语音交流是一种快速的手段,语音识别已经慢慢渗透于我们日常生活当中,现在很多行业先驱相信借于语音进行人机之间的交互,会引向一个方便人们日常生活。
自动语音识别(automaticspeechrecognition,asr)技术自从二十世纪五十年代以来一直研究的主题。自动语音识别技术是一种将人的语音转换为文本的技术。语音识别是一个多学科交叉的领域,它与声学、语音学、语言学、数字信号处理理论、信息论、计算机科学等众多学科紧密相连。由于语音信号的多样性和复杂性,语音识别系统在人机交互领域的应用还不是很成熟,只有在特定的条件下获得满意的性能,或者说只能应用于特定的某些场合。
在智能家居给人们带来便捷生活的同时,人们的控制习惯渐渐发生了改变。语音技术的发展也为控制入口做出了一个很好的补充,再抛去传统遥控器和手机app之后,通过语音指令的发送让人们的生活更加便利。所谓智能语音主要是通过语音识别技术和语音合成技术为用户提供各种服务。在语音控制技术方面,人们与机器进行语音交流,让机器明白你说什么,这是人们长期以来梦寐以求的事情。试音识别技术就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的技术。
就目前语音识别的发展状况,语音识别技术分为很多种模式,比如说按系统的用户情况分为特定人和非特定人识别系统,按系统的词汇量分为小词汇量、中词汇量和大词汇量系统,按语音的输入方式分为孤立词、连接词和连续语音系统等,按输入语音的发音方式分朗读式、口语式,按输入语音的方言背景情况分为普通话、方言背景普通话、方言语音识别系统,按输入语言的情感状态分为中性语音、情感语音识别系统等等。但在高识别率的情况下只有通过特定的条件下才能实现。
现在设备的人机交互界面有键盘、图像、指纹等方式,但是键盘操作有很多不方便。在特定环境下,比如汽车驾驶人员在驾驶的时候操作键盘要手眼并用,就无法注意到路面状况,这就存在着交通隐患。对于某些身体残疾或老人来说,界面式的操作都不是很方便,甚至是不可能的。
通信以及网络的全球覆盖使得信息公开化成为历史必然,人们获取资料的手段前所未有的丰富,然而负面影响也随之而来。伴随着信息透明化,个人隐私的安全性也受到了极大的威胁,相应的,如何正确进行个人身份的识别进而保护私人数据,是人机交互中一个亟待深入的课题。在个人身份识别中,传统的文字密码等保密手段存在着易被窃取和冒认的危险,而利用人本身的生物特征是相对比较可靠的一门技术。许多生物特征往往具有唯一性,如dna、虹膜、指纹等等,这些特征不会改变;另一方面就是声音在一定的时间间隔内相对稳定的特征。上述两方面都可以作为识别的依据。声纹密码识别相对于指纹、虹膜识别来说,人声的采集成本低廉、操作简便,具有很好的通用性和独特性;同时声音带有较强的个人特征,可以广泛地普及到人们的日常生活领域中。
对于现状的智能家居的语音控制在很多场景下因语音交互体验不如人意而深受诟病,究其主要原因是受限于空间距离、背景噪声、其他人声的干扰、回声、混响等多重复杂因素,进而出现识别距离近、识别率低、安全性能低的明显缺点。现在大部分智能家居系统中的语音控制只是做到简单的控制,忽略了其功效和安全性。
所以说在人机交互中的自然语言交互的公共背景噪声下声音拾取和安全性是两个亟待深入研究的两个课题。
技术实现要素:
为了克服现有技术存在的缺点与不足,本发明提供一直公共背景噪声下激活式的声纹密码安全控制方法及系统,解决了背景噪声,其他人声、回声、混响低信噪比下对语音突发的增量进行定位拾取,通过三次安全语音识别及控制的操作解决上述现状的问题。
为解决上述技术问题,本发明提供如下技术方案:一种公共背景噪声下激活式的声纹密码安全控制方法,包括下述步骤:
s1、激活识别模块在普通环境下实时进行语音信号监测,若检测到语音信号,则对语音信号进行预加重、加窗和分帧处理,并求取语音信号的幅度值;根据实验得到语音信号与噪声之间的信噪比,并将信噪比转化为幅度差t;设t为判决门限值,若语音信号的前一帧与后一帧只差大于等于t,则认为进入静默期;若语音信号的前一帧与后一帧只差小于t,则判断是激活标志,并激活声源定位拾取模块;
s2、声源定位拾取模块通过麦克风阵列接收交互目标声源数据,并对交互目标声源进行到达时延差的估计;
s3、对估计后的到达时延差,结合麦克风阵列的位置构造多个双曲面,并计算每个双曲面的焦点,确定交互目标声源位置,从而在交互目标声源位置得到交互目标声源的语音信号;
s4、预处理模块对交互目标声源的语音信号进行预处理,预处理包括预滤波、采样、量化、模式转换、预加重、加窗、分帧处理、端点检测以及生产mfcc_d特征参数过程;
s5、对预处理后的语音信号,声纹密码识别模块提取特征参数,将特征参数与录音库的指令文本进行匹配。
进一步地,所述步骤s2中对目标声源进行到达时延差的估计,包括在二维空间和三维空间对目标声源进行到达时延差的估计;其中
所述二维空间对目标声源进行到达时延差的估计,具体为:设麦克风阵列包括三个麦克风,相邻麦克风之间的距离为δd,以阵列中心的麦克风为参考点,目标声源距参考点的距离为r,目标声源与距离r关系满足下式:
式中,τ1、τ2分别是麦克风阵列两侧的两个麦克风与参考点麦克风的时延差,v为声速;其中,上式中表示出目标声源相对于麦克风阵列的极坐标(r,θ)为:
由上式得,只要获知τ1、τ2的值,即可唯一确定目标声源的极坐标;
所述三维空间对目标声源进行到达时延差的估计,具体为:建立麦克风阵列模型,所述麦克风阵列模型包括两个平行的麦克风阵列,每个麦克风阵列包括三个麦克风;其中,麦克风阵列间距为d,且每个麦克风阵列均以中间的麦克风为参考点,把其中一个麦克风阵列的参考点作为原点,建立三维坐标系;设目标声源的球坐标为
首先,分别在麦克风阵列中通过上述二维空间对目标声源进行到达时延差的估计算法,得到目标声源相对两个麦克风阵列参考点的极坐标(r,θ)与(r',θ'),则由阵列的几何关系有:
其中,
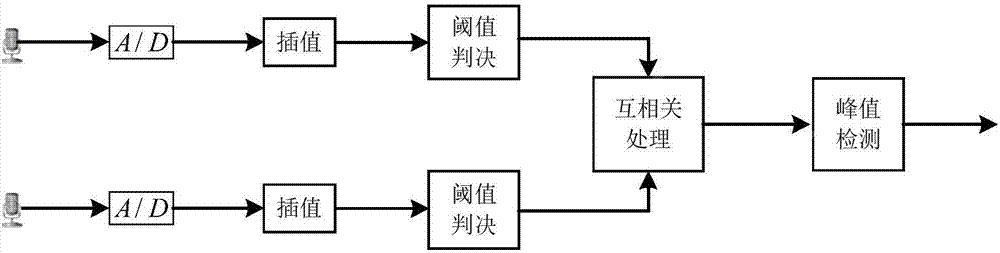
进一步地,所述步骤s2,在进行到达时延差的估计前,先对交互目标声源进行阈值判决,具体为:
a、对交互目标声源数据进行a/d转换,转换后第i个麦克风接收的信号xi(t)为:
式中,
b、为了确保时延差的估计精度,对麦克风接收到的信号进行插值处理,得到xi(n);设定一个较阈值a0,根据式
c、对不同麦克风经过阈值判决后的信号进行相关处理,通过峰值检测完成到达时延差的估计,所述进行相关处理方式为:
rij(τ)=e[xi(n)xj(n+τ)]。
进一步地,所述步骤c得到经过到达时延差的估计后的交互目标声源信号,此时,需对交互目标声源信号利用改进的加权波束形成法进行语音增强,具体为:
已知了各个麦克风与目标声源的距离,因此通过下式对各麦克风信号进行加权:
其中ωi为对第i个麦克风信号加权的权重,ri为第i个麦克风与目标声源之间的距离,r0为信号接收模型原点处麦克风与目标声源的距离;
此时,麦克风阵列的输出用下式描述:
其中,yi(n)为第i麦克风接收到的语音信号;δti为交互目标声源信号传播到第i个麦克风在采样域的时间延迟;m为接收信号的麦克风数;
假设每个麦克风接收的信号具有相同的统计特性,均值都为零,功率谱为φnn(ω);经过时间补偿后,各个通道的信号关于交互目标语音s(n)达到同步,则第i个麦克风经延迟补偿后的信号为:
其中,
由上式可知,根据目标声源位置的远近自适应调整通道加权的大小,不但能够达到固定波束形成器那样通过平均减弱噪声干扰的目的,同时还能最大化地利用信噪比较大通道的信号,更好地实现目标语音的增强。
进一步地,所述步骤s3中计算每个双曲面的焦点,其具体为:
根据麦克风接收信号模型,忽略信号幅度衰减,得两个麦克风接收的信号为:
y1(t)=s(t)+n1(t)
y2(t)=s(t-d)+n2(t)
其中,s(t)是交互目标声源信号,d是信号到达两个麦克风的相对时间延迟;n1(t)、n2(t)都为加性噪声干扰;
则y1(t),y2(t)的互相关函数r12(τ)为:
其中y1(ω)、y2(ω)分别是y1(t)、y2(t)的傅里叶变换,ψ12为广义互相关法频域的加权函数;根据不同的噪声情况来选择不同的所述加权函数,以使r12(τ)具有较尖锐的峰值。
进一步地,所述步骤s5中声纹密码识别模块提取特征参数,具体为:
s41、把一帧语音信号进行离散小波分解,分解为3层,每一层形成频带0khz-0.5khz、0.5khz-1khz、1khz-2khz、2khz-4khz,求出每一个频带的小波系数;
s42、求取每一层小波系数的频谱和每一层小波系数fft;
s43、频谱拼接:近似系数的频谱直接放置在第一层;由于高通信号抽取后下变频在低频处产生镜像,所有细节系数的频谱翻转后按照分辨率由小到大拼接;如此便拼接出了整个信号的频谱,即fft幅度谱的对称性,后半段则是拼接后频谱的镜像对称;
s44、对拼接的频谱求取能量:通过mel滤波器组,取对数能量,经过dct变换得到特征参数的dwt-mfc参数。
进一步地,所述步骤s5中录音库的指令文本,其预先通过录音模板生产模块进行处理,具体为:采用基于dwt-mfc的trendedhmm的模型对指令文本进行训练:
(1)假设系统用户a,该用户读3遍指定语音的文本指令,对每一遍的文本指令进行dwt-mfc特征参数的提取,得到3个特征向量序列;
(2)利用viterbi算法对每个特征向量序列进行分割,将分割后的多个特征向量序列合并为一个序列;
(3)利用sweep算法来估计模型参数;将上述的分割和优化进行迭代,直至viterbi得分进行收敛,得到每个用户相对应的特征参数的dwt-mfc参数。
本发明另一目的是提供一种公共背景噪声下激活式的声纹密码安全控制系统,包括激活识别模块、声源定位拾取模块、预处理模块、声纹密码识别模块、指令识别模块以及录音模板生成模块,其中
所述激活识别模块用于判断接收的语音信号是否为所需要的交互目标声源数据,从而激活声源定位语音增强模块;
所述声源定位拾取模块用于确定交互目标声源位置,并提取语音信号;
所述预处理模块用于对语音信号进行预处理,预处理包括预滤波、采样、量化、模式转换、预加重、加窗、分帧处理、端点检测以及生产mfcc_d特征参数过程;
所述声纹密码识别模块用于对相关文本的相关说话人识别,达到双重识别的过程;
所述指令识别模块用于于家庭设备的命令操作;
所述录音模板生成模块用于预先提取用户的声纹密码指令,并对声纹密码指令进行指令文本的训练。
进一步地,所述声源定位拾取模块包括麦克风阵列,所述麦克风阵列包括若干麦克风,所述麦克风用于接收交互目标声源数据。
采用上述技术方案后,本发明至少具有如下有益效果:
(1)本发明基于激活系统的实时检测,保证了识别系统的非实时性,延长了识别系统的生命周期,增大了效率;
(2)本发明声纹识别采用双重识别,增加了安全性。
附图说明
图1为本发明公共背景噪声下激活式的声纹密码安全控制方法的步骤流程图;
图2为本发明公共背景噪声下激活式的声纹密码安全控制方法中对阈值判决的流程图;
图3为本发明公共背景噪声下激活式的声纹密码安全控制方法中改进的加权波束形成法结构图
图4为本发明公共背景噪声下激活式的声纹密码安全控制方法中对特征参数提取步骤流程图;
图5为本发明公共背景噪声下激活式的声纹密码安全控制系统的结构框图;
图6为本发明公共背景噪声下激活式的声纹密码安全控制系统的麦克风阵列接收三维信号的模型图。
具体实施方式
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互结合,下面结合附图和具体实施例对本申请作进一步详细说明。
如图1所示,本发明提供一种公共背景噪声下激活式的声纹密码安全控制方法,主要步骤包括:
s1、激活识别模块在普通环境下实时进行语音信号监测,若检测到语音信号,则对语音信号进行预加重、加窗和分帧处理,并求取语音信号的幅度值;根据实验得到语音信号与噪声之间的信噪比,并将信噪比转化为幅度差t;设t为判决门限值,若语音信号的前一帧与后一帧只差大于等于t,则认为进入静默期;若语音信号的前一帧与后一帧只差小于t,则判断是激活标志,并激活声源定位拾取模块;
s2、声源定位拾取模块通过麦克风阵列接收交互目标声源数据,并对交互目标声源进行到达时延差的估计;
s3、对估计后的到达时延差,结合麦克风阵列的位置构造多个双曲面,并计算每个双曲面的焦点,确定交互目标声源位置,从而在交互目标声源位置得到交互目标声源的语音信号;
s4、预处理模块对交互目标声源的语音信号进行预处理,预处理包括预滤波、采样、量化、模式转换、预加重、加窗、分帧处理、端点检测以及生产mfcc_d特征参数过程;
s5、对预处理后的语音信号,声纹密码识别模块提取特征参数,将特征参数与录音库的指令文本进行匹配。
下面为每一步骤的详细描述。
s1、激活系统:通过实时检测声源定位系统得到的语音信号,从而达到激活声纹密码识别系统。具体步骤:第一步将语音信号进行预处理包括预加重,加窗和分帧处理。第二步进行每帧信号幅度值得求取。第三步根据实验得到语音信号与噪声信噪比转化为幅度差的t设定为判决门限值,如果第二帧与第一帧之差大于t,则认为进入静默期,第三帧与第二帧之差小于t则判断是激活标志,通过缓存的处理从前一帧开始进行语音信号的确定,通过判断是否是语音信号去进行声纹密码系统。语音信号的确定是通过实验所设定的语音信号的能量值去确定是否是语音信号。这样一来,就会不轻易的启动声纹识别系统,降低了系统的功耗。尽可能让系统处于休眠状态。也防止虚检和漏检。
s2、声源定位语音增强模块:第一步:基于时延估计的声源定位系统估计出声源位置,具体实现步骤,第一阶段,到达时延差估计,通过麦克风阵列接收的数据,估计来自交互目标声源的信号到达阵列各个阵元的时间差;第二阶段,交互目标声源定位,利用第一阶段得到的到达时延差,结合麦克风的位置构造多个双曲面,在一定的最优准则和条件下,计算各个双曲面焦点,确定交互目标声源位置。具体实现过程,根据麦克风接收信号模型,忽略信号幅度衰减,得两个麦克风接收的信号为:
y1(t)=s(t)+n1(t)(3-23)
y2(t)=s(t-d)+n2(t)(3-24)
其中,s(t)是交互目标声源信号,d是信号到达两个麦克风的相对时间延迟;n1(t)、n2(t)都为加性噪声干扰。
则y1(t),y2(t)的互相关函数r12(τ)为:
其中y1(ω)、y2(ω)分别是y1(t)、y2(t)的傅里叶变换,ψ12为广义互相关法频域的加权函数。加权函数比较灵活,可以根据不同的噪声情况,选择不同的加权函数,以使r12(τ)具有较尖锐的峰值。
广义互相关函数法原理和结构较为简单,基于某种最优原则在频域对麦克风接收的信号进行加权,具有较好的抑制噪声的能力,比较适合单声源的时延估计。但是,广义互相关频域加权函数的计算需要知道声源信号和加性噪声的相关先验知识,而在实际应用场景中,信号和噪声性质是事先是无法知道的。而且,在低信噪比和有限长的观察窗情况下,使用通过观察的数据对加权函数的估计值代替加权函数的理论值,往往导致广义互相关法的性能大大低于理论性能。
实际的人机语音交互场景主要以单目标声源交互为主,目标语音虽然在传播中易受环境噪声与其他说话者的干扰,但目标语音波形中幅度较大的信号在进行噪声叠加时,相对变化较小,保持原有的时域特征。则可以通过设定合适的阈值对接收的信号进行筛选,忽略小于阈值的信号,以大于阈值的信号为基准通过互相关函数估计两信号的相对时延。基于此本文提出一种先对接收信号进行阈值判决再做相关的声达时延差(tdoa)估计方法,算法框架如图2所示,具体为:
麦克风阵列均匀直线阵列的近场宽接收模型中,第i个麦克风接收到的信号xi(t)为:
式中,
首先,为了确保时延差的估计精度,对麦克风接收到的信号进行插值处理,得到xi(n)。
然后,设定一个较大的阈值a0,根据式(3-27)对插值后的xi(n)进行阈值判决处理。由于目标语音在接收的信号中以主导的成分存在,所以在选取合适的阈值进行判决后,a0在xi'(n)中的位置及数量大都由目标语音决定,而只受少量的干扰影响。即由xi'(n)之间的时延差可精确估计xi(t)之间的时延差。
阈值的选取极其关键,过小的阈值不但会增加计算量,而且在阈值判决后会残留大量的噪声干扰,进而影响声达时延差的估计,导致定位误差的增大;而过大的阈值会导致大量的目标语音信息在阈值判决中丢失,而且易受突发强噪声的干扰,从而导致错误地估计声达时延差。本文通过二次均值操作完成阈值a0的选取,第一次操作获取观察时间段内信号绝对值均值,第二次选取观察时间段内大于信号绝对值均值的信号,并求其均值作为阈值a0的值。
最后,由式(3-28)对来自不同麦克风经过阈值判决后的信号进行相关处理,通过峰值检测完成声达时延差的估计。
rij(τ)=e[xi(n)xj(n+τ)](3-28)
通过阈值筛选后,干扰噪声信号被减弱,而目标交互语音的时延信息被保留下来。在进行相关操作估计时延时,能够抑制噪声的影响,大大提高时延估计的精确性。第二步:利用改进的加权波束形成法进行语音增强。具体实现步骤:已知了各个麦克风与目标声源的距离,因此可以通过式(4-9)对各通道的信号进行加权。
其中ωi为对第i个麦克风信号加权的权重,ri为第i个麦克风与目标声源之间的距离,r0为信号接收模型原点处麦克风与目标声源的距离。
此时,如图3所示,系统的输出可用式(4-10)描述:
其中,yi(n)为第i麦克风接收到的语音信号。δti为交互目标声源信号传播到第i个麦克风在采样域的时间延迟,可以通过交互目标声源的位置信息、语音信号传播的速度、以及采用频率来确定,关于交互目标声源的定位,在第三章已经做了详细地讨论。m为接收信号的麦克风数。
假设每个麦克风接收的信号具有相同的统计特性,均值都为零,功率谱为φnn(ω)。经过时间补偿后,各个通道的信号关于交互目标语音s(n)达到同步,则第i个麦克风经延迟补偿后的信号为:
其中,
由式(4-12)可知,根据目标声源位置的远近自适应调整通道加权的大小,不但能够达到固定波束形成器那样通过平均减弱噪声干扰的目的,同时还能最大化地利用信噪比较大通道的信号,更好地实现目标语音的增强。
s3、声纹密码识别系统:此系统即相关文本的相关说话人二重识别系统。特征参数提取步骤如图4所示,具体步骤为:
(1)把一帧语音信号x(n)进行离散小波分解(层数为3层),形成频带0~0.5khz、0.5-1kh、1-2khz、2-4khz,求出每一个频带的小波系数。
(2)求取每一层小波系数的频谱,每一层小波系数fft。
(3)频谱拼接:近似系数(低频部分)的频谱(图中的一半)直接放置在第一层;由于高通信号抽取后下变频在低频处产生镜像,所有细节系数(高频部分)的频谱(图中的一半)翻转后按照分辨率由小到大拼接;如此便拼接出了整个信号的频谱(fft幅度谱的对称性),后半段则是拼接后频谱的镜像对称。特殊地,人耳可以听到20hz到20khz的音频信号,但人说话的声音频率范围在300hz到3400hz。因此第一层细节系数(描述信号2-4khz)的频谱会有一段接近零的数值,为减小计算量,把第一层细节系数频谱的零值去掉后取前一半翻转拼接。
(4)拼接好的频谱求取能量,通过mel滤波器组,取对数能量,经过dct变换得到特征参数dwt-mfc参数。
通过trendedhmm进行用户的指令文本进行训练得到每个用户对应的trendedhmm,即trendedhmm就是每个用户的指令模型。指令文本经特征参数提取之后得到特征向量序列,然后经过viterbi算法对每个序列进行分割。这时对模型的状态q,得到相应的特征向量序列。然后将此特征向量序列与录音库所有用户的模型计算viterbi得分,取得分最高的那个为识别结果。
s4:录音库:采用基于dwt-mfc的trendedhmm的模型进行训练每个用户的多遍的指令文本进行训练。
(1)假设系统用户a,该用户读3遍“开机”的指令。对每一遍的文本进行dwt-mfc特征参数的提取。得到3个特征向量序列。
(2)利用viterbi算法对每个序列进行分割,将多个特征向量序列合并为一个序列。
(3)利用sweep算法来估计模型参数。将上述的分割和优化进行迭代,直至viterbi得分进行收敛。得到每个用户相对应的模型参数。
总结:在s1的存在下推到s2再到s3,然后将s3与s4进行模板匹配。得到结果。
采样:模拟信号首先被等间隔地取样,这时信号在时间上就不再连续了,但在幅度上还是连续的。经过采样处理之后,模拟信号变成了离散时间信号。一般情况下取采样频率为8khz。
量化:每个信号采样的幅度以某个最小数量单位△的整数倍来度量。这时信号不仅在时间上不再连续,在幅度上也不连续了。经过量化处理之后,离散时间信号变成了数字信号。
预加重:通过传递函数为h(z)=1-αz-1的高通数字滤波器来实现预加重,其中a为预加重系数,一般为0.9<a<1,设n时刻的语音采样值为x(n),经过预加重处理后结果为y(n)=x(n)-ax(n-1),这里取a=0.98。
加窗,分帧:进行预加重数字滤波处理后,下面就是进行加窗分帧处理,语音信号具有短时平稳性(10--30ms内可以认为语音信号近似不变),这样就可以把语音信号分为一些短段来来进行处理,这就是分帧,语音信号的分帧是采用可移动的有限长度的窗口进行加权的方法来实现的。一般每秒的帧数约为33-100帧,视情况而定。一般的分帧方法为交叠分段的方法,前一帧和后一帧的交叠部分称为帧移,帧移与帧长的比值一般为0-0.5。
汉明窗函数如下:
汉明窗的时域和频域波形,窗长n=61。
根据一种公共背景噪声下激活式的声纹密码安全控制方法,本发明提供了一种公共背景噪声下激活式的声纹密码安全控制系统,此系统分为两个版块,一个是录音版块,另一个是语音信号识别版块,语音信号识别版块通过函数的调用使用录音版块。录音程序在vc++环境下采用widows系统中的多媒体应用程序接口实现语音信号录制。信号识别的过程主要是通过matlab语音仿真。做到控制及安全的统一性,高效性,安全性。本发明主要应用于要求安全系数较高的智能家居系统当中,本文主要针对门禁和保险箱两个对安全要求较高的背景下,采用此方法。本系统主要基于安全,快速反应的语音信号识别。
本系统整体模块如图5所示,包括声源定位拾取模块、预处理模块、激活识别模块、声纹密码识别模块、指令识别模块以及录音模板生成模块,声源定位拾取模块包括麦克风阵列,麦克风阵列包括若干麦克风(优选为3个)。
其中,预处理模块:预处理包括预波,采样,量化,模式转换,预加重,加窗,分帧处理,端点检测,mfcc_d特征参数。频率为16khz,分帧处理的帧长设置为32ms,,帧移和帧长的比值为1/2,加窗为汉明窗。端点检测采用基于能量和过零率双重界限确定语音的起始点和结束点。
声源定位拾取模块:语音是人机交互中最自然的方式,既不需要接触或佩戴数据设备,也不存在视觉盲点。在基于语音的人机交互系统中,由于噪声的影响,特别是交互环境中其他无关说话人语音的干扰,严重降低了交互系统的性能。本系统在人机交互系统语音信号信噪比的提高,可以距离式的语音操作,突破了手持式和佩戴设备对语音进行识别。本系统采用基于时延估计的声源定位方法。
为更好地得到声源的空间位置,基于麦克风线性均匀线阵,采用双阵列空间三维定位的方法,提出了一种由六个数字麦克风构成的平行均匀线阵拾音模块。结合基于阈值判决的声达时延差估计方法实现目标声源的三维定位。在智能家居中基于麦克风阵列声源定位解决了噪声抑制、混响消除、声源测向、回声抵消等等各个方面都得到了良好的解决。
采用matlab语言处理到的信号,使用图6所示的平行均匀线阵三维信号接收模型,每个子阵列由3个全向数字麦克风构成,因为数字麦克风具有更好的信噪比以及更好的抗rf和emi能力。本系统将麦克风间距为15cm,阵列间距为30cm,声音在空气中的传播速度定位340m/s,信号采样频率为16khz。通过延时叠加波束形成算法,然后通过声源三维定位算法准确获取目标声源的位置信息后,通过延时补偿使各通道中目标,语音信号同步后,再对各通道信号进行加权。
通过延时叠加波束形成算法得到的是目标信号的增强信号,可以通过延时叠加波束形成算法达到5db以上的增强效果。达到去噪的效果,同时也达到空间距离式的语音识别。
录音生成模板模块:录音程序在vc++环境下采用widows系统中的多媒体应用程序接口实现语音信号录制。使用多媒体应用程序接口编程简单、控制方便。
录音模块有2个板块的录音训练,存储三个录音库,通过函数的调用来匹配相对应的语音库。声纹密码语音库:采用统计模型的隐马尔可夫模型来描述语音模型,进行语音行库的训练。经过三次语音模板的录制,提高了识别的稳定性,排除了偶然性。
激活识别系统:通过声源定位麦克风拾取系统对声音实时的收入语音信号,通过实时检测的语音信号的平均幅度差(实时收入声音的幅度与背景噪声下的幅度的差值),当其差值达到一定的时候通过放大电路激活声纹密码识别模块,背景噪声下的幅度通过实验来设定。
声纹密码模块:此模块是基于特定人的自有密码设定之后的声纹密码识别,匹配用户自主设定的密码,当进入声纹密码识别模块时,提示用户说出密码。此模块基于模板匹配的viterb算法进行声纹密码识别。
指令识别模块:此模块主要操作门禁和保险箱的命令操作,指令内容设为“打开“,在指令识别中,本系统采用调整后的动态时间规整算法,而且dtw的时间相关性只能识别分辨指令,时间非常短,符合我们建立此系统的初衷。由于时间规整受到短时的限制,在指令识别中虽然语句是比较短的,但是动态时间规整算法还是有很多约束。为了避免因为训练效果不好影响识别率,在使用改进后的动态时间规整的上还采用了多种路径搜索。结果证明识别指令的识别率比较高。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解的是,在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种等效的变化、修改、替换和变型,本发明的范围由所附权利要求及其等同范围限定。
- 还没有人留言评论。精彩留言会获得点赞!