基于VPN的分布式网络爬虫系统及调度方法与流程
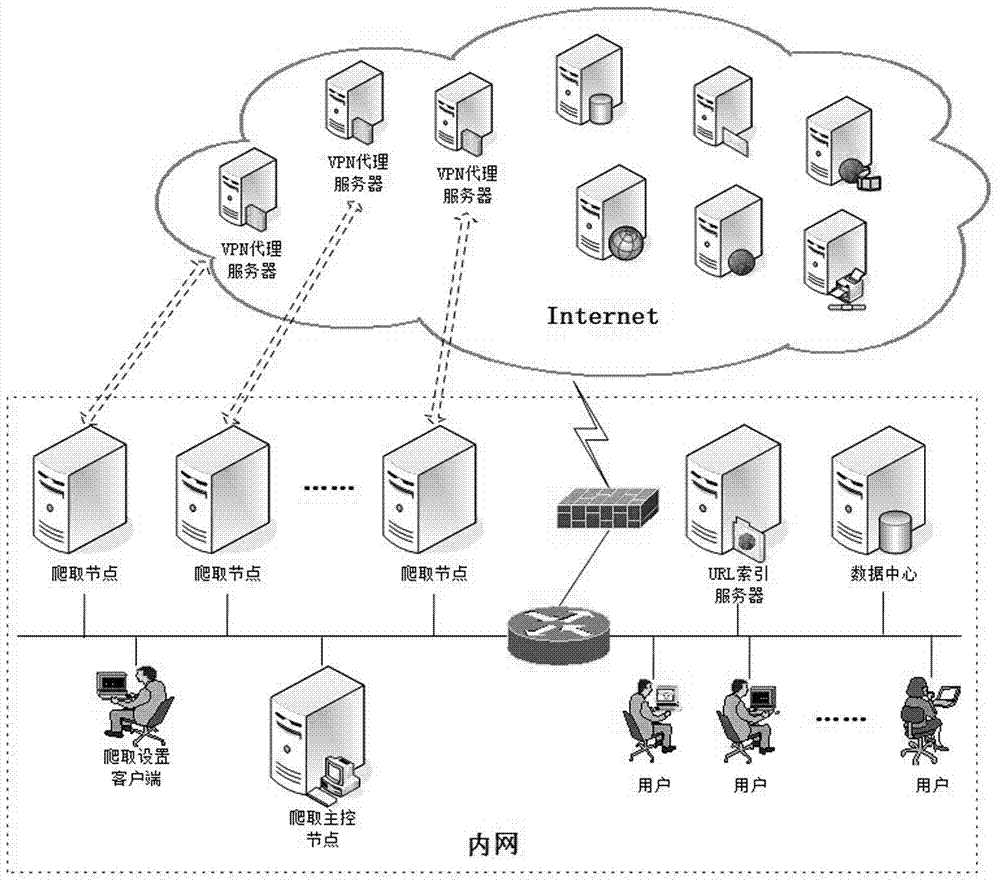
本发明涉及一种分布式网络爬虫系统及调度方法,更具体的说,尤其涉及一种基于vpn的分布式网络爬虫系统及调度方法。
背景技术:
:大数据时代的来临,网络上所承载的信息愈加丰富,其中既有指导行业发展走向的政策类网站,也有介绍相关领域最新科技动态及竞争对手产品信息的新闻类网站,还有反映用户对产品评价的博客、论坛、微博等社交网站。外网数据的有效接入和应用对各级各类企业辅助决策、制定计划、管理成本、销售运营、服务售后等提供信息支持,为企业更好知己知彼掌控市场打开了一扇窗口。网络爬虫起始于种子链接穿行于internet,将访问到的页面下载至本地,为网络数据采集提供技术支撑,为企业深度挖掘和分析网络数据奠定良好开端。根据网络爬虫所部署的地理位置和网络拓扑结构不同,可以将网络爬虫分为部署于同一局域网的单一域网络爬虫(single-domaindistributedcrawler,又称局域网爬虫)和分散部署于广域网的多域网络爬虫((multi-domaindistributecrawler,又称广域网爬虫)。无论是单一域网爬虫还是广域网爬虫最基本的功能均是网页数据抓取,而其灵魂则是调度策略,调度策略不同则抓取方法不同。调度策略主要包括种子链接分配策略、负载均衡策略、网页查重策略等。当前种子链接分配策略主要分为独立方式、静态方式和动态方式三类。独立方式中各网络爬虫互不通信独立采集各自页面;静态方式预先划分所有网络链接,将划分好的链接分配给网络爬虫;动态方式动态地为各网络爬虫分配网络链接,网络爬虫完成当前抓取任务时为其分配新的抓取任务。无论何种分配方式一般均是以域名(主机)为单位划分种子链接以降低通信开销。目前负载均衡策略主要分为静态负载均衡和动态负载均衡,其中静态负载均衡主要有轮询方式、比率方式、优先权方式等;而动态负载均衡在抓取过程中收集各爬虫服务器负载信息,根据负载情况迁移节点任务。无论何种均衡策略其任务迁移的对象均是网络链接,将高负荷爬虫的网络链接分配给低负荷爬虫,以均衡整个系统的负载。常用的网页查重策略有基于数据库的查重方式、基于b-树的去重方式、基于hash的去重方式、基于md5编码的去重方式、基于bloom的去重方式、基于广义表结构的去重方式等等。国内外的一些公司对大型网络爬虫已有成熟的解决方案,但是这些大型搜索引擎只能给大众用户提供一种普通不可定制的搜索服务,不可能考虑到不同用户的个性化需求。然而各类组织无论是政府机关、事业单位还是不同规模的企业在描述信息需求时,更倾向于使用一组关键词来描绘所关注的业务领域,且随着时间的推移这些关键词也会不断演进和变化。因此网络爬虫公司所提供的通用服务难以满足组织的深层信息需求,需要为组织个性化定制可部署于组织内的分布式网络爬虫。除大型跨国公司及集团类公司,大多数组织办公地点通常集中于同一区域,因此一般先是通过组建局域网(localareanetwork,lan)实现组织内的办公自动化(officeautomation,oa),而后通过路由器接入运营商的方式访问internet。就此而言,单一域网爬虫更适合于大多数组织的网络数据抓取。组织对web信息的需求并不仅局限于政策导向类的网站或新闻发布类的网站,为了更进一步地了解目标用户的需求,组织还需抓取论坛、微博等社交媒体平台数据。为应对领域的瞬息万变,组织需实时了解人们话题讨论的热点、风向、倾向等,这对社交媒体平台数据抓取提出了较高的实时性要求。然而在访问internet过程中,单一域网爬虫将共享运营商分配的同一个ip地址,大多数的组织很难拥有独属于自己的多个公网ip地址。受目标数据源服务器的限制,同一ip地址的爬虫在一定时间内只能采集同一目标服务器限定的数据。即使组织在局域网内设置了多个爬虫,这些爬虫在访问目标服务器的过程中也将被运营商分配相同的ip地址,因此当其中一个爬虫达到访问上限时,其余爬虫也将被拒绝访问。这对组织爬取数据的覆盖性和完整性提出了极大的挑战。因此如何在局域网内为组织部署分布式网络爬虫,以及如何为部署于局域网中的分布式爬虫设置合适调度策略,利用有限的ip地址应对不同类型网络媒体为组织尽可能多的采集数据是本发明基于vpn的分布式网络爬虫系统构建的主旨。技术实现要素:本发明为了克服上述技术问题的缺点,提供了一种基于vpn的分布式网络爬虫系统及调度方法。本发明的基于vpn的分布式网络爬虫系统,其特征在于:包括部署于同一组织局域网内的爬取设置客户端、爬取主控节点、多个爬取节点、url索引服务器、数据中心和用户,以及多个远程vpn代理服务器;组织局域网通过路由器接入运营商的方式访问internet,以便爬取节点使用vpn代理服务器访问internet中的目标数据源服务器;爬取设置客户端用于配置数据源、关键词、爬取策略,爬取主控节点根据爬取设置客户端的配置为爬取节点分配任务,实现爬取节点的调度以及均衡各爬取节点的负载;爬取节点中部署着网络爬虫系统,爬取节点根据爬取主控节点分配的任务选择一个vpn连接连入远程vpn代理服务器,使用vpn代理服务器访问internet中的目标数据源服务器;url索引服务器记录已爬取过的url及爬取时间,数据中心用于存储抓取的网页数据;用户是网络数据的使用者,通过与数据中心的交互获取相关数据。本发明的基于vpn的分布式网络爬虫系统,所述爬取主控节点、爬取节点、url索引服务器和数据中心可采用逻辑划分,并非每个设备均需一个物理设备与其对应;url索引服务器可合并到数据中心,由数据中心承担已爬取url的记录;所述爬取设置客户端可以是任意具有爬取设置权限的用户。本发明的基于vpn的分布式网络爬虫系统的调度方法,通过以下步骤来实现:a).确定新闻类网站和社交媒体类网站的数据采集方法,对于信息更新频率和数量较低的新闻类网站,采用爬虫直接抓取目标源数据,再使用关键词进行数据过滤;对于信息更新频率和数量极高的社交媒体类网站,利用目标数据源的站内检索结合关键词获取有效信息,再使用爬虫抓取检索结果;b).爬取主控节点为各爬取节点分配任务,对于新闻类网站,将同一域名的新闻类网站分配给一个爬取节点采集目标源数据;对于社交媒体类网站,将同一域名的社交媒体类网站分配到全部爬取节点,并为每个爬取节点分配互不相同的关键词;c).各爬取节点生成初始采集目标数据源url列表,爬取主控节点为每个爬取节点分配vpn连接列表、新闻类网站采集入口url地址、社交媒体类采集入口url地址以及关键词后,爬取节点从vpn连接列表中选择最久未使用的vpn连接连入远程vpn代理服务器,使用vpn代理服务器访问新闻类网站和社交媒体类网站;设爬取节点获取的新闻类网站的网页url地址列表为url_init_listweb,获取的社交媒体类网站的检索入口url地址列表为url_init_listsoc,爬取节点的初始采集目标数据源列表url_init_list为url_init_listweb与url_init_listsoc的并集;d).各爬取节点确定最终采集目标数据源url列表,爬取节点通过将url_init_list与url索引服务器所维护的url_list进行比较、判断采集过url地址与初次访问时间差是否小于相应网页类型的重访问时间,形成中间采集目标数据源列表url_intermed_list;然后通过对url_intermed_list进行混排生成最终采集目标数据源列表url_final_list;e).各爬取节点采集目标数据源列表的网页数据,爬取节点采集url_final_list列表中各url地址所指向的网页数据,对于新闻类网页按照网站分组,将网页数据存放到新闻类网站结果列表data_final_listweb中;对于社交媒体类网页,将网页数据存放到社交媒体结果列表data_final_listsoc中;并将data_final_listweb和data_final_listsoc打包发送给数据中心;f).url索引服务器维护更新url列表,url索引服务器接收到爬取节点发送的url_list更新请求后,将所要更新的url地址添加到url_list列表中,并将访问时间设置为当前时间,实现url_list列表的更新;g).各爬取节点将爬取结果存储到数据中心,各爬取节点逐一采集各自最终采集目标数据源列表url_final_list中每条url数据源,将采集结果缓存至本地,在完成列表url_final_list中所有数据源的采集后,将采集到的数据一次性发送至数据中心;h).各爬取节点向爬取主控节点汇报状态,各爬取节点按照约定时间,定时向爬取主控节点发送心跳信号和各自的采集时间表;i).爬取主控节点根据所汇报的状态调节负载,爬取主控节点根据计算的新闻类网站的权重和社交媒体类网站的各关键词权重,对各爬取节点的负载做出均衡调整。本发明的基于vpn的分布式网络爬虫系统的调度方法,设爬取节点数为ncl,不同域名的新闻类网站数为nweb,不同域名的社交媒体类网站数为nsoc,社交媒体类网站的关键词数为nkw;则步骤b)中,为每个爬取节点平均分配个不同域名的新闻类网站,将域名不同的社交媒体类网站分配到所有爬取节点,并为每个爬取节点平均分配个不同的关键词;爬取主控节点维护着爬取节点任务分配表、爬取节点心跳表和vpn连接账户表,新闻类网站的任务分配表中记录各个爬取节点所分配到的网站及各个网站的权重,新闻类网站webi的权重的计算公式为:其中,为抓取新闻类网站webj所花费的时间,i∈[1,nweb],j∈[1,nweb];初始采集各新闻类网站花费时间未知时,认为所有新闻类网站采集时间相同,则各新闻类网站的初始权重为社交媒体类网站的任务分配表中记录各个爬取节点在每个社交媒体类网站中所分配到的关键词以及不同社交媒体类网站不同关键词的权重,社交媒体类网站soci中关键词kwj的权重的计算公式为:其中,为在社交媒体类网站soci中采集关键词kwk相关的信息所所花费的时间,i∈[1,nsoc],j、k∈[1,nkw];初始在各社交媒体类网站中采集不同关键词相关信息花费时间未知时,认为各关键词相关信息的采集时间相同,则各关键词的初始权重为本发明的基于vpn的分布式网络爬虫系统的调度方法,步骤c)中所述的各爬取节点生成初始采集目标数据源url列表具体通过以下步骤来实现:c-1).爬取节点从vpn连接列表中选择最久未使用的vpn连接连入远程vpn代理服务器,使用vpn代理服务器访问新闻类网站和社交媒体类网站,获取初始采集目标数据源列表,同时记录使用该vpn连接的开始使用时间;并通过y/n记录vpn连接最近是否使用过,若最近使用过该vpn连接标识为y,反之标识为n;c-2).爬取节点首先解析采集任务的新闻类网站和社交媒体类网站的主机地址,然后将自身的任务主机地址与暂时停用目标主机列表host_disable_list进行比对,去除出现在host_disable_list中且停用时间小于2小时的任务主机,并删除host_disable_list中停用时间大于2小时的主机地址;c-3).假设比对host_disable_list之后保留的新闻类网站为webj,webj+1,…,webk,其对应的采集入口url地址分别是爬取节点spideri分别以为接入口获取相应网站中网页url地址列表比对host_disable_list之后保留的社交媒体类网站对应的检索入口url地址分别是各社交媒体分配到spideri的关键词为则爬取节点spideri分别以各社交媒体的检索地址为接入口结合社交媒体所对应的关键词获取各社交媒体网页url地址列表初始采集目标数据源列表url_init_list由url_init_listweb和url_init_listsoc组成,即url_init_list=url_init_listweb∪url_init_listsoc。本发明的基于vpn的分布式网络爬虫系统的调度方法,步骤d)中各爬取节点确定最终采集目标数据源url列表具体通过以下步骤来实现:d-1).爬取节点首先将url_init_list与url索引服务器所维护的url_list列表进行比对,查看url_init_list中的每条url地址是否采集过,若未采集则将此条url放入中间采集目标数据源列表url_intermed_list,并在url_intermed_list中记录此url为新增地址,否则执行步骤d-2);d-2).若url_init_list中某条url地址已存在于url列表,说明已经采集过此url地址中的数据,然而新闻类网站和社交媒体类网站的数据不断更新,在网页活跃期内仍需持续采集更新数据;因此,当url_init_list中某条url地址已存在于url_list中,则首先判断该url地址的网页类型,将当前时间与该url地址的初次访问时间对比,若两者的时间差小于相应网页的重访时间标准,则将此url地址放入url_intermed_list,否则不再采集该url地址数据。d-3).首先将url_intermed_list中的url地址按照主机分组划分成若干子列表,然后采用随机方法随机挑选一个子列表,并在该子列表中随机选择一个未被选中过的url地址放入url_final_list,迭代子列表和url地址的选择过程直至选完所有子列表的所有url地址。本发明的基于vpn的分布式网络爬虫系统的调度方法,步骤e)中所述的各爬取节点采集目标数据源列表的网页数据通过以下步骤来实现:e-1).爬取节点从自身的url_final_list中取出一条url地址,通过当前vpn连路采集url地址所指向的网页数据,若返回结果为网页数据,则执行步骤e-2);若返回结果为服务器拒绝访问或其他vpn相关错误,则执行步骤e-3);e-2).缓存采集结果,存放到混排的结果列表data_init_list中,并记录网页的类型、网页的来源、社交媒体类网页所对应的检索关键词、网页采集花费的时间;所采集的url地址被标识为新增地址时,则向url索引服务器发送url_list更新请求;e-3).若爬取节点中有标识为最近未使用过的vpn连接,则在标识为最近未使用过的vpn连接中,通过当前时间与最近未使用过的vpn连接的开始使用时间对比,选择一个最久未使用vpn连接,在连接成功后,执行步骤e-4);若爬取节点的vpn连接全部标识为最近使用过,执行步骤e-5);e-4).使用新的vpn连接采集网页数据,若返回结果为网页数据,则执行步骤e-2);若仍出现服务器拒绝访问或其他vpn相关错误,则执行步骤e-3);e-5).爬取节点向爬取主控节点申请新的vpn连接,若成功申请到新的vpn连接则将此vpn加入vpn连接列表,并将申请到的vpn连接标识为最近未使用,执行步骤e-3);若未申请到vpn连接执行步骤e-6);e-6).删除url_final_list中与此url主机地址相同的未采集url,执行步骤e-1)。本发明的基于vpn的分布式网络爬虫系统的调度方法,对社交媒体类网站的大规模采集对外网ip地址的要求远高于新闻类网站的采集,因此本发明所需的vpn个数主要受限于社交媒体类网站的关键词,通过如下公式估算:其中vpns表示所需vpn连接数,nsearchpage表示检索结果页链接个数,nvpn_ip表示社交媒体类网站允许一个ip地址采集的页数;所需爬取节点的个数通过如下公式估算:其中clients表示需要爬取节点的个数,expecttime表示完成一轮采集所花费的期望时间,accesstime表示连接远程服务器及采集数据时间,vpnlinktime表示vpn单次连接时间。本发明的有益效果是:首先,单一域网络爬虫共享同一ip出口地址,访问的频率和总量将受到限制,本发明中的爬取节点通过vpn拨号的方式连入远程vpn代理服务器,进而使用代理服务器的公网ip地址访问数据源,通过切换vpn连接获取不同公网ip,解决局域网爬虫ip地址单一问题;其次,虽然通过连入远程vpn代理服务器的方式可获得多个公网ip地址,但就社交新闻类网站的更新频率而言,ip地址仍是珍贵的稀缺资源,为使用一个ip地址尽可能多的获取数据,本发明采用多目标数据源url穿插采集的方式,避免同一时间过于密集地采集单一目标服务器中的数据,从而造成服务器拒绝访问问题,解决社交媒体类网站平台数据采集覆盖性和完整性;最后,与当前负载均衡通过分配网络连接方式不同,本发明采用调整关键词的方式均衡各爬取节点的负载。附图说明图1为本发明基于vpn的分布式网络爬虫系统的部署结构;图2为本发明基于vpn的分布式网络爬虫系统的数据抓取步骤;图3为本发明基于vpn的分布式网络爬虫系爬取中控节点生成的采集目标数据源列表;图4为本发明基于vpn的分布式网络爬虫系统爬取中控节点生成url_final_list的流程图。具体实施方式下面结合附图与实施例对本发明作进一步说明。为解决大多数组织在访问internet时ip地址单一,从而导致社交网站数据爬取不完整和覆盖差问题,本发明提出了一种基于vpn的分布式网络爬虫系统。如图1所示,给出了为本发明基于vpn的分布式网络爬虫系统的部署结构,本发明基于vpn的分布式网络爬虫系统部署于组织局域网内,通过路由器接入运营商的方式访问internet。基于vpn的分布式网络爬虫系统由爬取设置客户端、爬取主控节点、爬取节点、url索引服务器、数据中心以及最终用户组成。爬取设置客户端用于配置数据源、关键词、爬取策略等;爬取主控节点根据爬取设置客户端的配置为多个爬取节点分配任务,负责爬取节点的调度并均衡各爬取节点的负载;爬取节点中部署着网络爬虫系统,在接到爬取主控节点分配的采集任务后选择一个vpn连接连入远程vpn代理服务器,使用代理服务器访问internet中的目标数据源服务器;url索引服务器记录已爬取过的url及爬取时间;数据中心用于存储抓取的网页数据;用户是网络数据的使用者,可通过多种方式与数据中心交互。基于vpn的分布式网络爬虫系统中的各设备均为逻辑划分,并非每个设备均需一个物理设备与其对应。其中爬取设置客户端可以是任意具有爬取设置权限的用户;在设备性能富有余地的情况下,url索引服务器也可合并到数据中心,由数据中心承担已爬取url的记录功能。如图2所示给出了本发明基于vpn的分布式网络爬虫系统的数据抓取步骤,将基于vpn的分布式网络爬虫系统部署到组织内往后,所采用的数据抓取方法步骤如图2所示。步骤一:确定新闻类网站和社交媒体类网站平台的数据采集方法;步骤二:爬取主控节点为各爬取节点分配任务;步骤三:各爬取节点生成初始采集目标数据源url列表;步骤四:各爬取节点确定采集目标数据源url列表;步骤五:各爬取节点采集目标数据源列表的网页数据步骤六:url索引服务器维护更新url列表;步骤七:各爬取节点将爬取结果存储到数据中心;步骤八:各爬取节点向爬取主控节点汇报状态;步骤九:爬取主控状态根据所汇报的状态调节负载。步骤一,新闻类网站和社交媒体类网站平台的数据采集方法确定如下:组织关注的数据源既有指导行业发展走向的政策类网站,也有介绍相关领域最新科技动态及竞争对手产品信息的新闻类网站,以及反应用户对产品评价的博客、论坛、微博等社交网站。其中政策类网站和新闻类网站的信息一般是由网站编辑工作人员撰写录入,单个网站信息更新频率和数量较低,其日更新量一般不超过千条。而论坛、微博等社交媒体平台的信息由活跃于互联网和移动网的网民自由撰写发表,单个媒体平台信息更新频率和数量极高,日更新量超过亿条,任何第三方爬虫系统都难以应对如此量级的数据采集。所幸组织所关注的重点是业务领域相关信息,这些信息只是各类数据源提供数据的子集。组织通常可采用构建本体知识库的方式,描述业务领域过滤无效信息。为保证业务领域描述的完整性,构建的本体知识库一般包含几百个概念和实例(关键词)。在明确目标数据源和关键词的基础上,组织获取有效信息的方法有两种。其一,使用爬虫直接抓取目标源数据,再使用关键词进行数据过滤;其二,利用目标数据源的站内检索结合关键词获取有效信息,再使用爬虫抓取检索结果。假设本体知识库中的关键词数为nkw,目标数据源中单位时间内信息的更新量为nd,受限于新闻类网站页面承载的信息量,nd将分布于新闻类网站的多个页面,一个页面承载的信息数为c。在新闻类网站信息总更新量nd中,与组织业务领域相关的有效信息量为ni。两种采集方法与服务器的交互次数可分成两部分,分别是为得到有效信息所在的位置访问页面的次数(访问目录页次数)和抓取信息的次数(访问内容页次数)。若ni均匀的分布于nd中,则采用第一种方法获取全部ni条有效信息需访问目标数据源次,采用第二种方法获取全部ni条有效信息需访问目标数据源次。面对日信息更新量过亿的社交媒体类网站平台,则nd>>c,nd>>ni且nd>>nkw,采用第一种方法访问目标数据源的次数远大于第二种方法,显然对于信息更新频率极高的社交媒体类网站平台更适合于采用第二种方法而非第一种方法。而面对日信息更新量少于千条的新闻类网站数据nd并不会比ni大一个数量级,且若新闻类网站是组织挑选的行业内新闻类网站则nd≈ni,此时影响两种方法访问服务器次数的关键在于nkw。显然对于信息更新频率较低的新闻类网站,采用第一种方法采集数据,而后在本地使用关键词过滤信息的方式,可有效减少与服务器的交互次数,增强ip地址利用率。因此本发明采用第一种方法采集新闻类网站数据,而采用第二种方法采集社交媒体类网站数据。步骤二,在明确新闻类网站和社交媒体类网站平台的采集方法后,爬取主控节点为各爬取节点分配任务的方案如下:当前种子连接分配策略一般是以域名(主机)为单位,将同一域名的数据交由一个爬取节点采集。本发明也采用此种策略采集新闻类网站数据,将同一域名的新闻类网站分配给一个爬取节点采集。如前所述采集社交媒体类网站平台,访问目标服务器的次中,nkw次访问并未采集信息,而是关键词检索引起的开销。受同一ip地址访问总量限制以及关键词的演进和变化,若仍将同一域名的社交媒体类网站也交由一个爬取节点采集,关键词的检索会造成极大的浪费有限的访问总量。针对社交媒体类网站数据采集,本发明将同一域名的社交媒体类网站分配到全部爬取节点,并为每个爬取节点分配互不相同的关键词。假设爬取节点数为ncl,不同域名新闻类网站数为nweb,不同域名社交媒体类网站数为nsoc,社交媒体类网站的关键词为nkw。在初始各爬取节点状态未知时,爬取主控节点的种子连接分配策略为:将域名不同的新闻类网站平均分配到各爬取节点,也即随机为每个爬取节点分配个不同域名新闻类网站;而将域名不同的社交媒体类网站分配到所有爬取节点,将不同关键词平均分配到各爬取节点,也即为每个爬取节点分配nsoc个不同域名社交媒体类网站,并随机分配个不同的关键词。爬取主控节点维护着爬取节点任务分配表、爬取节点心跳表和vpn连接账户表。如表1所示,给出了新闻类网站爬取任务分配表:表1表1记录各个爬取节点所分配到的新闻类网站以及各个新闻类网站的权重,新闻类网站webi的权重计算公式为:其中为抓取新闻类网站webj所花费的时间j∈[1,nweb],初始采集各新闻类网站花费时间未知时,认为所有新闻类网站采集时间相同,则各新闻类网站的初始权重为表2给出了社交媒体类网站爬取任务分配表:表2表2的右续表:表2记录各个爬取节点在每个社交媒体类网站中所分配到的关键词,以及不同社交媒体类网站不同关键词的权重,社交媒体类网站soci中关键词kwj的权重计算公式为:其中为在社交媒体类网站soci中采集关键词kwk相关的信息所花费的时间k∈[1,nsoc],初始在各社交媒体类网站中采集不同关键词相关信息花费时间未知时,认为各关键词相关信息的采集时间相同,则各关键词的初始权重为表3crawlerstatespider1***spider2***spider3***…………spiderncl***如表3所示,给出了爬取节点心跳表,爬取主控节点定时接收各个爬取节点的心跳状态,并记录在爬取节点心跳表中,从而了解爬取节点是否宕机以及是否有新的爬取节点加入,心跳表中的state记录着各个爬取节点向爬取主控节点最后返回心跳时间。当有节点宕机或新节点加入时,根据各个新闻类网站爬取时间、各个社交媒体类网站不同关键词相关信息爬取所花费的时间,以及所拥有的爬取节点数依据负载均衡原则重新分配任务。爬取主控节点在给爬取节点分配任务的同时为其分配一个vpn连接列表,初始时爬取主控节点所分配的vpn连接列表包含两个ip地址不同vpn连接。在信息采集过程中,当所分配的ip地址达到采集上限时,爬取节点将向主控节点申请新的vpn连接,若存在未分配vpn连接则主控节点将为爬取节点再分配一个连接。如表4所示,给出了爬取中控节点的vpn连接账户表:表4vpnconnectionipaddressuserpasswordassignmentvpn1*********spider3vpn2*********nonevpn3*********spider1vpn4*********spiderncl…………………………vpnw*********spider2爬取主控节点在vpn连接账户表中记录着系统所拥有的vpn账号及各账号的分配情况,如表4所示,其中assignment记录着vpn连接账户的分配情况。步骤三,各爬取节点在分配到vpn连接列表、新闻类网站采集入口url地址、社交媒体类网站搜索入口url地址以及关键词后,生成初始采集目标数据源列表方案如下:爬取节点中部署着网络爬虫系统,在接到爬取主控节点分配的采集任务以及vpn连接列表后,从vpn连接列表中选择一个最近未使用且最久未使用的vpn连接连入远程vpn代理服务器,使用代理服务器访问internet中新闻类网站和社交媒体类网站,获取初始采集目标数据源列表,同时记录使用该vpn连接的起始时间。如表5所示,给出了爬取节点的vpn列表:表5爬取节点所维护的vpn列表如表5所示,starttime记录vpn连接的开始使用时间,recentlyused通过y/n记录vpn连接最近是否使用过,若最近使用过该vpn连接则标识为y,反之标识为n。暂时停用目标主机列表host_disable_list记录着暂时不采集的主机地址及起始停用时间。在采集任务开始之前,爬取节点spideri将首先解析采集任务的新闻类网站及社交媒体类网站的主机地址。然后将任务主机地址与host_disable_list进行对比,去除出现在host_disable_list中且停用时间小于2小时的任务主机,并删除host_disable_list中停用时间大于2小时的主机地址。假设比对host_disable_list之后保留的新闻类网站为webj,webj+1,…,webk,其对应的采集入口url地址分别是爬取节点spideri分别以为接入口获取相应新闻类网站中网页url地址列表比对host_disable_list之后保留的社交媒体类网站对应的检索入口url地址分别是各社交媒体类网站分配到spideri的关键词为则爬取节点spideri分别以各社交媒体类网站的检索地址为接入口结合社交媒体类网站所对应的关键词获取各社交媒体类网站网页url地址列表初始采集目标数据源列表url_init_list由url_init_listweb和url_init_listsoc组成,也即url_init_list=url_init_listweb∪url_init_listsoc。步骤四,各爬取节点在得到初始采集目标数据源列表后,确定采集目标数据源列表包含如下三个阶段:阶段一:比对url采集列表url索引服务器所维护的url列表(url_list)记录着所有已爬取过的网页url及爬取时间,如表6所示,给出了爬取中控节点的url列表:表6urlaccesstimeweborsochttp://…***web_comhttp://…***sochttps://…***web_edu………………https://…***soc其中,accesstime记录网页的初次访问时间,weborsoc用于区分网页是来自于社交媒体类网站还是新闻类网站,同时根据新闻类网站后缀不同又将新闻类网站网页分为com、net、edu、gov四种类型。爬取节点首先将url_init_list与url_list进行比对,查看url_init_list中的每条url地址是否采集过,若未采集则将此条url放入中间采集目标数据源列表url_intermed_list,并在url_intermed_list中记录此url为新增地址,否则转入阶段二;阶段二:比对url采集时间若url_init_list中某条url地址已存在于url列表,说明已经采集过此url地址中的数据,然而新闻类网站和社交媒体类网站的数据不断更新,在网页活跃期内仍需持续采集更新数据。斯坦福大学的cho和garcia-monlina指出网页更新时间间隔符合指数分布,不同类型网页更新频率不同。本发明分别统计社交媒体类网站网页、com网站网页、net网站网页、edu网站网页和gov网站网页的平均更新时间作为重访时间标准。因此,当url_init_list中某条url地址已存在于url_list中,则首先判断该url地址的网页类型,将当前时间与该url地址的初次访问时间对比,若两者的时间差小于相应网页的重访时间标准,则将此url地址放入url_intermed_list,否则不再采集该url地址数据。阶段三:混排中间采集目标数据源列表有限的外网ip地址在大规模信息采集中是极其珍贵的资源,在一定时间内无节制频繁地访问同一新闻类网站或社交媒体类网站,会受到目标数据服务器的拒绝,这将成为影响信息采集的制约因素。为充分使用有限的外网ip地址,与其他爬虫系统不同,本发明避免集中采集同一新闻类网站或社交媒体类网站url地址,将url_intermed_list中的url地址进行混排生成最终采集目标数据源列表url_final_list。如图3所示,给出了中控节点生成的采集目标数据源列表,图4给出了本发明中爬取中控节点生成url_final_list的流程图,首先将url_intermed_list中的url地址按照主机分组划分成若干子列表,然后采用随机方法随机挑选一个子列表,并在该子列表中随机选择一个未被选中过的url地址放入url_final_list,迭代子列表和url地址的选择过程直至选完所有子列表的所有url地址。此外,为避免同一新闻类网站或社交媒体类网站的多次域名寻址节省带宽,爬取节点可在一次访问后记录新闻类网站和社交媒体类网站的ip地址。在url_intermed_list中被标识为新增地址的url在混排到url_final_list时,同样被标识为新增地址。本发明采用url+标识在url_intermed_list与url_list对比中未出现在url_list中的url地址,也即之前未采集过的网页url地址。步骤五,爬取节点在得到采集目标数据源列表后,采集网页数据包含如下两个阶段:阶段一:采集url_final_list中各url所指向网页数据1、从url_final_list中取出一条url地址。2、通过当前vpn链路采集url地址所指向的网页数据。3、监测返回结果,3-1若返回结果为网页数据,3-1-1统计当前网页采集花费时间,并缓存采集结果,存放到混排的结果列表data_init_list中,表7给出了混排的结果列表,其中weborsoc记录网页的类型,用于区分该网页是新闻类网站类网页还是社交媒体类网站类网页;host记录网页的来源新闻类网站或来源社交媒体类网站;keyword记录社交媒体类网站类网页所对应的检索关键词,新闻类网站类网页则为空值none;cost记录网页采集花费的时间;page存储网页的具体内容。表7urlweborsochostkeywordcostpageurl1web***none******url2soc************url3web***none******………………………………urlnsoc************3-1-2若所采集的url地址被标识为新增地址时,则向url索引服务器发送url_list更新请求。3-2若返回结果为服务器拒绝访问或其他vpn相关错误,3-2-1若vpn列表的recentlyused有标识为n的vpn连接,则在标识为n的vpn连接中,通过当前时间与vpn列表中的starttime对比,选择一个最久未使用vpn连接,在连接成功后将starttime记录为当前时间,标识该vpn连接的recentlyused为y,转入3-2-2;若vpn列表的recentlyused全部标识为y,则转入3-2-3。3-2-2使用新的vpn连接采集网页数据,若返回结果为网页数据,则将vpn列表中除此vpn连接的其他recentlyused标识为n,转入3-1;若仍出现相同错误,转入3-2-1。3-2-3爬取节点向爬取主控节点申请新的vpn连接,若成功申请到新的vpn连接则将此vpn加入vpn连接列表,并将recentlyused标识为n,转入3-2-1;若未申请到vpn连接,则转入3-2-4。3-2-4将该url主机地址及当前时间记录到host_disable_list,删除url_final_list中与此url主机地址相同的未采集url,并将vpn列表中除此vpn连接的其他recentlyused标识为n,转入1。4、迭代本阶段中的步骤1至步骤3直至url_final_list为空。阶段二:计算新闻类网站及社交媒体类网站权重,将采集结果发送到数据中心1、在完成本轮url_final_list的采集后,重新分组data_init_list,1-1对于新闻类网页按照网站分组,存放到新闻类网站结果列表data_final_listweb。1-2对于社交媒体类类网页按照社交媒体类网站分组后,再按照网页所对应关键词进行分组,存放到社交媒体类网站结果列表data_final_listsoc。2、计算新闻类网站采集时间和社交媒体类网站各关键词相关信息采集时间,记录到爬取节点采集时间表,其逻辑结构如表8和表9所示:表8webcostroundwebj******webj+1******………………webk******表9表8给出了爬取节点记录的新闻类网站的采集时间表,表9给出了所记录的社交媒体类网站的采集时间表,其中cost记录各新闻类网站和社交媒体类网站的各关键词采集所花费的时间,round记录本轮url_final_list采集完成时间。2-1汇总data_final_listweb中同一新闻类网站所有网页的采集时间,记录到新闻类网站采集时间表,如表8所示。2-2汇总中同一社交媒体类网站同一关键词所有网站的采集时间,记录到社交媒体类网站采集时间表,如表9所示。3、将data_final_listweb和data_final_listsoc打包,发送给数据中心,转入步骤三。步骤六,url索引服务器维护更新url列表url索引服务器在接收到爬取节点发送的url_list更新请求后,将url地址添加到url_list中,并将访问时间设置为当前时间。为提高检索速度,url_list可采用倒排索引机制。步骤七,各爬取节点向数据中心发送爬取结果各爬取节点逐一采集各自目标数据源列表中每条url数据源,将采集结果缓存至本地,在完成任务列表中所有数据源的采集后,按照批处理的方式将采集到的数据一次性发送到数据中心。数据中心将统一负责接收并按照规定的存储格式,对采集结果进行解析存储。步骤八,各爬取节点向爬取主控节点汇报以下两种状态:1、心跳状态各爬取节点按照约定时间,定时向爬取主控节点发送心跳信号,以表明爬取节点仍处于活动状态。爬取主控节点若在约定时间内未收到爬取节点的心跳信号,则认为爬取节点宕机,反之则认为爬取节点工作正常。当爬取主控节点收到新的心跳信号时则认为有新的爬取节点加入。2、信息采集情况各爬取节点按照约定时间,定时将各自的采集时间表发送到爬取主控节点,发送成功后清空本地表。步骤九,爬取主控节点调节各爬取节点负载的方案如下:该步骤中所述的爬取主控节点根据所汇报的状态调节负载具体通过以下步骤来实现:i-1).获取采集时间表,各爬取节点定时将所记录的新闻类网站的采集时间表和社交媒体类网站的采集时间表发送至爬取主控节点,爬取主控节点将其存储至本地的信息采集汇总时间表中;新闻类网站的采集时间表由各新闻类网站及采集网站所花费的时间cost、采集网站的完成时间round组成;执行步骤i-2);i-2).计算平均访问时间和权重,爬取主控节点以天为单位,在一天结束时分析当天的信息采集汇总时间表,按新闻类网站汇总当天多轮采集时间,计算当天每个新闻类网站的一轮抓取所需平均访问时间,按社交媒体类网站关键词汇总当天多轮采集时间,计算当天每个社交媒体类网站的每个关键词抓取所需平均访问时间;按照公式(1)计算各新闻类网站的权重;按照公式(2)计算各社交媒体类网站的各关键词的权重;各爬取节点的社交媒体类网站的关键词负载均衡调节通过步骤i-3)至步骤i-10)来实现;i-3).判断耗时时间差,爬取主控节点计算出各爬取节点完成某社交媒体类网站的关键词一轮抓取所需平均访问时间,找出耗时最长和最短的爬取节点,计算两者耗时时间差,若两者时间差不大于用户预设调节时间差阈值,则维持当前社交媒体类网站关键词的分配状态,均衡负载结束;若两者时间差大于用户预设调节时间差阈值,则执行步骤i-4);i-4).关键词排序,爬取主控节点按照权重降序排列该社交媒体类网站的关键词,执行步骤i-5);i-5).重新分配关键词,爬取主控节点从排好序的关键词中,依次取出第1至第ncl个关键词顺序分配给spider1、spider2、…、spiderncl,然后依次取出第ncl+1至第2ncl个关键词逆序分配给spider1、spider2、…、spiderncl,迭代该过程,直至分完该社交新闻类网站的所有关键词,将此关键词的分配记录为初始状态kw_init_assignment,spideri代表第i个爬取节点,i≤ncl;执行步骤i-6);i-6).迭代次数清零,抽取kw_init_assignment状态中所有爬取节点中所有关键词的权重,并计算爬取节点所分配关键词权重的方差variance_init,并将迭代次数iteration清零,令iteration=0;i-7).迭代次数加1,令iteration=iteration+1,然后判断迭代次数iteration是否小于指定迭代次数iteration_threshold,若是,则令本次迭代的方差variance_miniteration等于初始状态方差,variance_miniteration=variance_init,执行步骤i-8);否则,执行步骤i-10);i-8).交换关键词,随机选择两个爬取节点,并在所选择的爬取节点中随机选择两个关键词进行交换,然后重新抽取所有爬取节点中所有关键词的权重,计算权重方差variance_random;执行步骤i-9);i-9).比较权重方差的大小,比较variance_random与variance_miniteration的大小;如果variance_random<variance_miniteration,则保持两个关键词的交换,将variance_random赋值给variance_miniteration,令variance_miniteration=variance_random,并将交换失败计数counter清零,令counter=0;variance_miniteration为所记录关键词权重方差的最小值,执行步骤i-8);如果variance_random≥variance_miniteration,则撤销两个关键词的交换,并使交换失败计数counter加1,即令counter=counter+1;若交换失败计数counter的值小于累计次数阈值counter_threshold,转入步骤i-8);若counter≥counter_threshold,将此关键词的分配记录为第iteration次迭代状态kw_intermediteration_assignment,转入步骤i-7);i-10).选取最优状态进行分配,比较多个kw_intermediteration_assignment中的关键词权重方差variance_miniteration的值,将variance_miniteration值最小的kw_intermediteration_assignment记录为关键词分配最终状态kw_final_assignment,按照此最终状态更新爬取节点任务分配表,并按此表重新为各个爬取节点分配任务;各爬取节点的新闻类网站的负载均衡调节采用与步骤i-3)至步骤i-10)相同的方法,只需将步骤i-3)至步骤i-10)中社交媒体类网站的关键词替换为新闻类网站即可。当爬取节点只应用于信息采集时,服务器负载即为两类数据源的采集工作。此时,当采集任务均衡时,可认为各节点的负载也较为均衡。步骤i-2)所计算的新闻类网站和社交媒体类网站关键词权重描述了采集任务的繁重程度,因此通过均匀地分配新闻类网站和社交媒体类网站关键词,从而使得各爬取节点的权重和相似,即可达到均衡爬取节点负载的目的。此外,为满足用户需求,系统所需的vpn个数和爬取节点个数计算方法如下所示:1、vpn个数对社交媒体类网站的大规模采集对外网ip地址的要求远高于新闻类网站的采集,因此本发明所需的vpn个数主要受限于社交媒体类网站的关键词,可通过如下公式大致估算:其中vpns表示所需vpn连接数,nsearchpage表示检索结果页链接个数,nvpn_ip表示社交媒体类网站允许一个ip地址采集的页数。2、爬取节点个数本发明所需爬取节点的个数可通过如下公式大致估算:其中clients表示需要爬取节点的个数,expecttime表示完成一轮采集所花费的期望时间,accesstime表示连接远程服务器及采集数据时间,vpnlinktime表示vpn单次连接时间。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1