基于卷积神经网络的视频编码后置滤波方法与流程
本发明涉及计算机视觉和视频编码领域,具体涉及一种基于卷积神经网络的视频编码后置滤波方法。
背景技术:
随着科技的发展和各种视频显示设备的丰富,视频已经日益成为人们生活中不可缺少的部分,在各个领域发挥着十分重要的作用。过去的几十年来见证了视频分辨率与显示设备屏幕的巨大发展,而超高分辨率的视频会产生庞大的数据量,这会对网络带宽产生极大的负担。因此,需要高效的视频编码和传输技术来保证用户观看视频的体验,同时尽可能地降低视频的数据量,为网络带宽减负。鉴于此,研究人员在几十年来不断研究高效的视频编码方法。视频编码技术,主要是通过移除视频中的冗余信息来减少视频的数据量以达到有效地储存和传输大量视频数据,其旨在尽量保持原视频质量的前提下,以更低的码率压缩视频。
然而,当前的视频编码标准主要都是基于块的混合视频编码技术,在这种编码框架下,基于块的帧内/帧间预测、转换以及粗量化都会导致视频质量的下降,尤其是在低码率的情况下。因此,减少视频编码中的失真成为当前视频编码领域的研究热点之一。虽然,在当前视频编码标准中也采取了一些算法来减少块效应和提高主观质量,但是其效果还不够理想,处理后的视频仍存在明显的块效应和边缘模糊,细节丢失仍比较严重。
技术实现要素:
本发明的主要目的在于利用卷积神经网络对非线性变换的强拟合能力,提出一种基于卷积神经网络的视频编码后置滤波方法,该方法建立起有损视频帧到无损视频帧的映射,从而近似得到视频编码中失真过程的逆变换,来达到减少失真的目的。
本发明为达上述目的所提供的技术方案如下:
一种基于卷积神经网络的视频编码后置滤波方法,包括卷积神经网络模型的训练步骤以及后置滤波处理步骤,其中:
所述训练步骤包括s1至s4:
s1、设置视频压缩的量化参数为20至51,对原始视频进行编码压缩,得到压缩视频;
s2、对所述压缩视频和所述原始视频进行帧的提取,得到多个帧对,每个所述帧对包含一压缩视频帧和一原始视频帧;
s3、将步骤s2提取的帧对按照帧类型和量化参数的不同划分为多个组;
s4、搭建卷积神经网络框架并初始化网络参数,使用步骤s3划分的组分别对神经网络进行训练,得到对应于不同量化参数和帧类型的多个神经网络模型;
所述后置滤波处理步骤包括s5和s6:
s5、将步骤s4得到的多个神经网络模型嵌入至视频编码器的后置滤波环节;
s6、对待处理的原始视频执行步骤s1和s2得到待处理帧对,并依据待处理帧对的量化参数和帧类型选择对应的神经网络模型进行滤波处理。
量化参数和帧类型的不同导致它们的失真性质也不同,本发明在训练和实际处理过程中都是提取原始视频和压缩视频组成的帧对,以此建立起有损视频帧和无损视频帧的映射;并通过训练出针对不同量化参数和帧类型的神经网络模型嵌入到编码器中后置滤波环节进行滤波处理,充分考虑量化参数和帧类型对失真程度的影响,采用本发明的方法先判别帧的量化参数和帧类型,再选择量化参数和帧类型都与之对应的神经网络模型来进行滤波,从而可以有效抑制失真。
附图说明
图1是本发明提供的基于卷积神经网络的视频编码后置滤波方法的流程图;
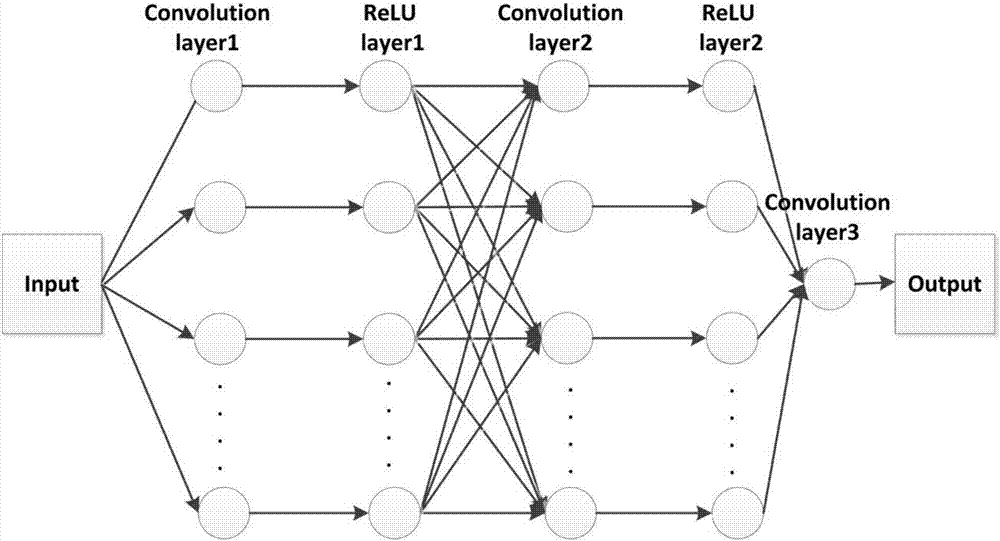
图2是卷积神经网络框架图;
图3是卷积神经网络的训练过程示意图。
具体实施方式
下面结合附图和具体的实施方式对本发明作进一步说明。
本发明利用卷积神经网络强大的非线性拟合能力,结合视频编码的特性,充分分析视频编码压缩过程中造成失真的原因,提出了基于卷积神经网络且相关于量化参数和帧类型的视频编码后置滤波方法,建立有损视频帧和无损视频帧之间的映射,训练得到不同量化参数(简称qp)以及不同帧类型下的卷积神经网络模型,用于在编码器的后置滤波环节针对不同量化参数和帧类型的帧进行滤波处理,可以有效抑制失真。
在混合视频编码框架中,帧类型主要有i帧、p帧和b帧,其中:
i帧采用的是帧内预测模式,又称之为帧内编码帧(intrapicture),i帧通常是每一个画面组(gop)的起始帧,它不依赖于前后帧的信息,因此在播放中可以作为随机播放的切入点。对于帧内预测模式,在解码端,是基于解码出的相邻的左边的块和上边的块,使用算法来进行当前块的预测,而后再加上残差数据来重建图像的原始信息,该残差数据由解码值和预测值相减而得;在编码端,需要使用相同的帧内预测,因为预测值与原始图像数据较相似,所以要传输的剩余数据的能量是非常低的,从而能够实现码流的压缩。
p帧和b帧采用帧间预测模式,p帧即前向预测帧(predictive-frame),参考前面的i帧或者b帧来去除时间上的冗余信息,实现高效压缩。b帧即双向预测内插编码帧,又称(bi-directionalinterpolatedpredictionframe),其需要参考前后的视频帧,利用两边的帧与b帧的相似性去除冗余信息。帧间预测主要是基于相邻帧之间较高的相似度,利用已知帧的信息来重建当前帧,通常使用的方法是通过运动估计和补偿的方式来进行帧间预测。寻找最匹配的宏块的方法即运动估计法,该方法是针对当前宏块,先在前一帧寻找最相似的宏块(即匹配块),对它们求差,产生很多零值,进行与帧内相似的编码流程就能节省可观的比特数。
在混合视频编码框架中,不同帧类型的视频帧,其编码方法是不一样的,正因如此,不同帧类型的视频帧其失真性质也不同。由于i帧是相对独立的,因此其失真的原因主要为量化过程和dct变换(离散余弦变换)过程,量化过程本质上是将多数值映射到少数值的过程,相对地,反量化过程即通过少数值来恢复多数值的过程,其恢复不可避免会存在数据误差,因此视频帧会出现一些由量化损失造成的高频噪声。产生p帧和b帧的主要方式是通过帧间预测的方式,这两种帧预测的源泉都是来自于i帧,因此i帧本身具有的失真性质也会传播给p帧和b帧;另外,运动估计和补偿的过程中,也存在导致失真的因素。比如,在帧间预测的运动补偿环节,当前帧的相邻两个块的预测块有可能并非来自于同一参考帧的相邻两个块的预测,有可能是自于不同帧中的两个块的预测。也就是说,相邻块参考的那两个块的边缘本身便不具备连续性,这也将导致一定的块效应现象,从而造成失真。
视频编码的基本原理就是利用视频序列所具有的相关性来压缩冗余信息,实现视频序列的高效传输。其中视频序列所具有的相关性主要分为空间和时间相关性,空间上的相关性主要体现在同一视频帧相邻像素点之间存在着相关性,时间上的相关性主要体现在时间上相邻的帧具有较高的相似度。因此,在混合视频编码框架中,每一视频帧的产生方式,不是帧内预测的结果,就是帧间预测的结果。不同类型的帧其产生机制也不相同,意味着在基于卷积神经网络的视频编码质量增强算法中需要将帧类型也考虑进来,以取得更好的效果。
基于前述的原理,本发明具体实施方式提出了基于卷积神经网络的视频编码后置滤波方法,该方法包括卷积神经网络模型的训练步骤以及后置滤波处理步骤,如图1所示:
所述训练步骤包括s1至s4:
s1、设置视频压缩的量化参数为20至51,对原始视频进行编码压缩,得到压缩视频;
s2、对所述压缩视频和所述原始视频进行帧的提取,得到多个帧对,每个所述帧对包含一压缩视频帧和一原始视频帧;
s3、将步骤s2提取的帧对按照帧类型和量化参数的不同划分为多个组;
s4、搭建卷积神经网络框架并初始化网络参数,使用步骤s3划分的组分别对神经网络进行训练,得到对应于不同量化参数和帧类型的多个神经网络模型;
所述后置滤波处理步骤包括s5和s6:
s5、将步骤s4得到的多个神经网络模型嵌入至视频编码器的后置滤波环节;
s6、对待处理的原始视频执行步骤s1和s2得到待处理帧对,并依据待处理帧对的量化参数和帧类型选择对应的神经网络模型进行滤波处理。
本发明的方法首先需要训练神经网络,再用训练好的神经网络模型进行滤波处理。下面以一种具体的实施例来说明本发明提供的上述基于卷积神经网络的视频编码后置滤波方法。
选取用于训练的原始视频,进行编码压缩,压缩时的量化参数qp设置为20至51(即连续的整数20、21、22、23、24、……、50、51),得到不同qp下的压缩视频。优选地,可以采用常用的jm10和/或hm12视频编码标准软件对原始视频进行编码压缩。对原始视频和对应的压缩视频进行帧提取,得到很多个帧对,帧对可以表示为“原始视频帧-压缩视频帧”,即每个帧对包含一原始视频帧及一对应的压缩视频帧。将得到的所有帧对按照帧类型和量化参数qp的不同划分为多个组,具体的划分过程例如是:将所有帧对先按照qp的不同(32)进行划分,再对每个qp下的帧对按照帧类型分为i帧、p帧和b帧,从而得到所述的多个组(在本例中,得到),每个组内的帧对具有相同的帧类型和量化参数qp。
待训练的神经网络的架构包括卷积层和relu层,在一种具体的实施例中,搭建的神经网络的架构可参考图2,包括3个卷积层(图中的convolutionlayer1、convolutionlayer2、convolutionlayer3)和2个relu层(图中的relulayer1和relulayer2),卷积层和relu层依次交替连接,例如,输入层input之后连接卷积层1(convolutionlayer1),卷积层1的输出连接relu层1(relulayer1),relu层1的输出连接卷积层2(convolutionlayer2),卷积层2(convolutionlayer2)的输出连接relu层2(relulayer2),relu层2的输出连接卷积层3(convolutionlayer3),卷积层3的输出连接输出层output。需要说明,图2所示的卷积神经网络仅仅是示例性的,不构成对本发明的限制。对图2所示的神经网络中,设置卷积层1、2、3的滤波核大小(滤波核即卷积核)分别为9、1、5,神经元个数分别为64、32、1;relu层的神经元个数与和relu层连接的上一层卷积层的神经元个数保持一致。
接着,采用前述得到的多组帧对分别单独地去训练上述搭建好的例如图2所示的神经网络。首先,将每个组内的帧对依据分辨率和场景来划分训练集、验证集和测试集,例如将qp为20且帧类型为i帧的所有帧对划分为训练集、验证集和测试集,将qp为20且帧类型为p帧的所有帧对划分为训练集、验证集和测试集,其中,测试集内的帧对具有分辨率和场景多样的特点。其次,将所有的帧对按照一定的像素间距截取图像块,得到“原始帧图像块-压缩帧图像块”的图像块对,作为训练过程中神经网络的输入。
以qp为20、类型为i帧的一组帧对为例来说明训练神经网络的过程,例如,对该组内的所有帧对中的帧按28个像素为间距来截取图像块,例如每个图像块的大小为33×33,在训练过程中,所有的卷积层都不使用padding操作来避免边界效应(因为使用padding相当于人工复制了边界的像素点,从而扩大了图像的大小,边界处的信息就不准确了),为了计算输出图像块和原始图像块之间的损失值,本发明将原始图像块也裁成跟输出图像块的大小一致。接着,将截取的所有图像块随机均分为多个批次,将一个批次的图像块依次输入神经网络,完成一个批次则为一次迭代,有多少个批次即进行多少次迭代,在迭代过程中利用随机梯度下降法进行后向传播,更新网络参数,来不断最小化损失函数。每迭代一定次数则采用验证集来校正训练出的网络参数,以防止过拟合。
具体的训练过程如图3所示,卷积层的神经元对输入的图像块的操作表示为
待参数收敛时,完成训练,得到qp为20、类型为i帧的该组帧对所对应的神经网络模型,嵌入到编码器后置滤波环节作为滤波用。同理地,qp为20、类型为p帧的一组帧对也采用上述方法来训练神经网络,得到对应于qp为20、类型为p帧的该组帧对的神经网络模型;其它qp值下的帧对也采用同样的方法来训练神经网络。
假设训练过程中所采用的压缩视频有jm10和hm12两种软件,则两种软件压缩得到的压缩视频应当分开进行处理,分开来训练。从而,经过上述的训练方法,则可以得到以下的多个神经网络模型:
jm10标准软件编码下对应qp为20至51的32个不同的i帧模型,jm10标准软件编码下对应qp为20至51的32个不同的p帧模型,jm10标准软件编码下对应qp为20至51的32个不同的b帧模型,hm12标准软件编码下对应qp为20至51的32个不同的i帧模型,hm12标准软件编码下对应qp为20至51的32个不同的p帧模型,hm12标准软件编码下对应qp为20至51的32个不同的b帧模型。
在实际使用过程中,对待处理的原始视频经编码器进行编码压缩和帧对提取之后,对得到的帧对进行量化参数和帧类型的判断,例如判断得知当前待处理的帧对的qp为23、类型为b帧,则选择属于qp为23、类型为b帧的图像块训练得到的神经网络模型来进行后置滤波处理。在优选的实施例中,可将采用的编码软件也考虑进来,即在训练时还根据编码软件的不同分别进行训练(正如上一段所描述的),从而在实际使用时还考虑先分辨是何种编码软件压缩编码得到的,再考虑量化参数和帧类型来选择对应的神经网络模型进行滤波处理。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的技术人员来说,在不脱离本发明构思的前提下,还可以做出若干等同替代或明显变型,而且性能或用途相同,都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!