一种多用户MIMO系统用户调度方法与流程
本发明涉及无线通信技术领域,尤其涉及多用户mimo系统中用户调度方法。
背景技术:
lte是ip化的网络系统,引入了正交频分复用和多输入多输出等关键技术。多用户mimo系统通过空分复用实现了多个用户占用相同时频资源进行并行数据流传送,进一步提高了频谱效率。3gpp定义了四种类型的服务,给定了各自的速率要求以及时延要求。在多用户mimo系统中进一步优化吞吐量和保证qos就是在这种背景下提出来的无线资源调度问题。调度即动态的将最适合的时/频资源分配给用户使之共享信道,是保证qos以及优化系统容量的关键。在lte网络中,为了保证qos,提出了很多调度算法,如fls(framelevelscheduler)、exp(exponential)、pf(proportionalfair)、mlwdf(modifiedlargestweighteddelayfirst)等等。
fls帧优先级调度方法根据数据帧中的以太网类型应用流量控制工具,使得高优先级数据的带宽得到保障。exp基于指数准则的分组调度算法在调度判决时综合考虑用户的相对信道条件、时延敏感度、队首分组等待时间等条件,具有吞吐量最优的特性。pf算法主要策略是使得用户的瞬时传输速率大的或者吞吐量小的用户将获得较高的优先级,在公平性和吞吐量之间寻求一种平衡。m-lwdf是在pf算法的基础上增加了对时延、综合信道质量、服务速率的考虑。
最重要的是,上述提到所有算法均没有考虑终端缓存。当考虑终端缓存时,基站发送的数据暂存在缓存中,用户也将从缓存中提取数据用于业务。一方面可以充分利用信道,当信道条件好时向用户传送数据并预存在缓存中,以增大系统吞吐量;另一方面,可以根据终端缓存的情况调整用户的优先级,当缓存中有数据时,用户允许较低的调度优先级控制时延。
技术实现要素:
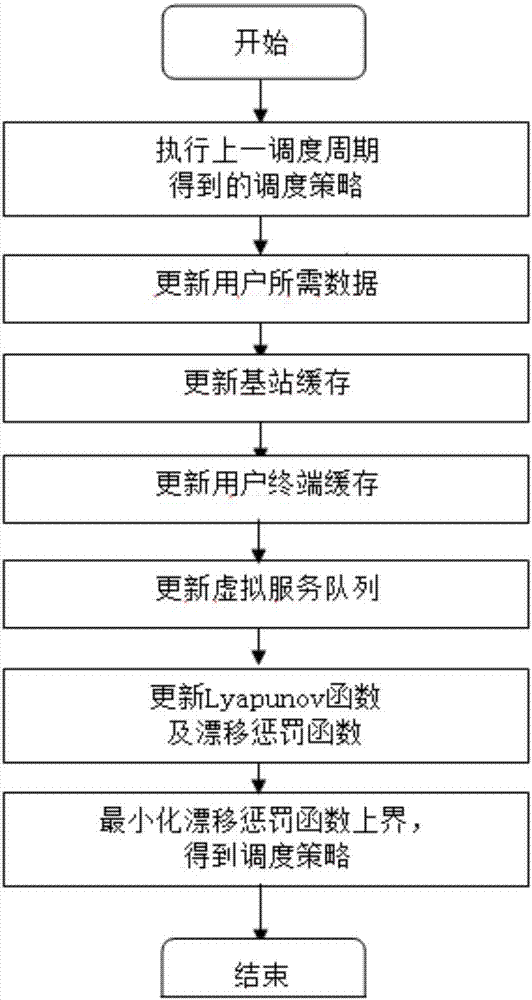
针对上述现有技术的缺点,本发明提出一种多用户mimo系统中考虑终端缓存的用户调度方法,从保证用户的qos的角度出发,利用lyapunov算法得到系统吞吐量最优的调度方案。
步骤1、在基站端,将不同用户所需的数据标记为不同的队列,构成等待基站调度的队列集合,并在每个调度周期开始时进行更新;
步骤2、用户app提取数据对应于数据出终端缓存器,基站发送数据对应于数据进终端缓存器,在每个调度周期开始时对用户终端缓存器进行更新;
步骤3、以系统处于稳定状态作为约束之一,调整调度方法,该稳定状态即基站产生用户所需数据的平均速率与用户app在终端提取数据的平均速率保持一致;
步骤4、以保证用户时延要求作为另一个约束,调整调度方法,在基站端为所有用户根据其业务类型设计虚拟服务,无论当前调度周期此用户是否被调度,所述虚拟服务总是在基站监测到其终端缓存小于门限值时启动;
步骤5、建立基站吞吐量最大的目标函数,该函数的约束条件由步骤3和步骤4得到,在每个调度周期开始时更新队列,构造lyapunov函数,将目标函数和lyapunov漂移通过惩罚因子结合起来得到漂移惩罚函数,利用lyapunov算法最小化其上界,据此得到基站的调度策略。
所述目标函数为
本发明的有益效果:
1.能够保证基站在满足时延要求的基础上传输用户数据,并且能够保证基站产生的用户所需数据的速率与用户app在终端提取数据的速率在平均意义上的一致性。
2.在上述qos保证的基础上实现了基站吞吐量的最大化。
附图说明
图1为本发明实施例的流程图;
图2为图1实施例中多用户mimo下行信道模型;
图3为四种类型业务的时延和速率要求。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
步骤1、建立系统模型。
将不同用户所需的数据标记为不同的队列,构成等待基站调度的队列集合,并在每个调度周期开始时进行更新。
如图2所示,在多用户mimo系统中,基站共有n根天线,最多能同时服务于m个用户。系统中共有k个用户,第k个用户的接收天线数为nk,基站产生的该用户所需数据包的速率为λk。在一个调度周期开始时,基站执行上一调度周期产生的调度策略α(t),并据此为每一个用户k分配传输速率γk(t),最终将从所有待调度用户k中选择不超过m个用户,并将其数据从基站端缓存器传输到相应的用户终端缓存器。用户k以速率μk从缓冲器中提取数据用于特定业务,当用户k的业务需要数据而缓冲器为空,并且没有数据到达时就会产生时延,影响用户app的qos。
系统最大支持的用户数m由下式给出:
其中nj代表用户j的接收天线数,n代表基站的天线总数。
以一个时隙为调度周期,时隙t产生的调度策略记为α(t)={α1(t),…,αk(t),…αk(t)},其中,αk(t)表示基站在时隙t对用户k的调度方案,并由下式给出:
因为基站同时支持用户数有上限,所以上式必须满足:
此外,用户k的带宽归一化速率rk(t)由下式给出:
其中,nk代表用户k的接收天线数,pk,j代表用户k的第j个接收天线信道中的传输功率,βk,j代表用户等效矩阵的奇异值。
由此得到在时隙t决定的每一个用户k所需数据的传输速率为:
γk(t)=αk(t)rk(t)(4)
每个调度周期结束时都会产生一个调度策略,它指示了基站在下一个调度周期将哪些用户所需的数据从基站端缓存送入相应的用户终端缓存中。在一个新的调度周期开始时,基站端根据用户所需数据以及上一调度周期的调度策略更新缓存状态。
步骤2、用户终端缓存状态描述。
每个调度周期结束时产生的调度策略,它决定了在下一个调度周期哪些用户的终端缓存器中将有数据进入。此外,当前调度周期内,用户业务根据需求会从其终端缓存器中提取数据,这也会影响下一个调度周期用户终端缓存的初始状态。在一个新的调度周期开始时,根据上一调度周期中的数据提取情况以及上一调度周期的调度策略,更新用户终端缓存。
构造一个队列模型来描述这一过程:
qk(t+1)=max{qk(t)-μk(t),0}+γk(t)(5)
其中,μk(t)为用户k的app从终端缓存中提取数据的速率,γk(t)为基站向用户k的终端缓存中发送数据包的速率。max{qk(t)-μk(t),0}表示用户可取的数据量不超过终端缓存器中的缓存。
需要说明的是,设计这一队列的目的是监视用户终端缓存的状态,以助于基站调整用户的优先级。比如,在一个调度周期中,当缓存器非空时,用户app可以提取缓存中已有的数据用于用户业务,而不依赖于当前调度周期基站是否向用户发送数据,此时基站可以对该用户赋予较低的调度优先级。
步骤3、数据包传送描述。
稳定状态下,基站产生用户所需数据的平均速率与用户app在终端提取数据的平均速率应保持一致。直观上,若将整个调度及传输过程视作黑盒操作,只考虑系统输入和输出,显然基站产生的用户所需数据包将作为输入,而用户app从终端缓存中提取的数据包将作为输出,平均意义上输入速率应等于输出速率,以达到供求平衡,即
hk(t+1)=hk(t)-μk(t)+λk(t)(6)
其中λk(t)为基站产生用户k所需数据包的速率,μk(t)为用户k的app从终端缓存中提取数据的速率。
步骤4、时延描述。
在基站端为所有用户根据其业务类型设计一个虚拟服务,无论当前调度周期此用户是否被调度,该服务总是在基站监测到其终端缓存小于某一门限值时启动,当终端缓存小于某门限值时,该终端上报给基站,该门限值也取决于业务类型。
具体的业务类型见图3。考虑到实时业务和非实时业务的区别,将非实时业务的门限值定为0,而实时业务的门限值定为该种业务以最高传输速率传输时最大时延内的数据量。
用户允许的时延越大意味着基站为这一服务所承诺的速率越小。用这种服务的速率来描述用户端的时延,通过构造一个虚拟队列来描述这一服务,即基站对用户终端缓存器中数据缓存量的大小所做出的反应。队列的更新公式如下:
其中,qk(t)代表在调度时隙t用户k的终端缓存中数据包的情况,
如前所述,当该服务启动,但多个调度周期中该用户仍旧未被基站调度,即无数据进k入终端缓存,用户就会产生时延,可以证明的是,在这种虚拟服务机制下的最大时延
其中,
步骤5、产生调度策略。
建立基站吞吐量最大的目标函数;此外,每个调度周期开始时,步骤2~步骤4中定义的各个队列都将进行更新。步骤2中所定义队列的更新意味着用户终端缓存状态的刷新,这有助于步骤4根据终端缓存选择合适的虚拟队列形式以调整用户优先级。步骤3中所定义队列的更新反映系统的输入输出状态。
根据这些更新后的队列构造lyapunov函数。将目标函数和lyapunov漂移通过惩罚因子结合起来得到漂移惩罚函数,而后利用lyapunov算法最小化其上界。直观上,通过最小化该上界可以帮助稳定lyapunov队列,并且控制吞吐量。特别的,当某用户终端缓存小于门限值时,由步骤4看出,其虚拟队列将从无到有,此时调度策略必须做出调整。按照步骤4中对虚拟队列的定义,基站将努力在后续调度周期为其分配传输速率以保证lyapunov队列的稳定,相当于在调度策略产生时赋予该用户较高的优先级。据此得到的调度策略将决定下一调度周期基站所服务的用户。
目标函数如下
其中,
本实施例所构造的lyapunov函数为:
lyapunov漂移的定义式为:
δ(θ(t))=e{l(θ(t+1))-l(θ(t))|θ(t)}(15)
将目标函数和lyapunov漂移结合起来得到漂移惩罚函数:
其中,v≥0代表权值,体现出队列积压最小化和吞吐量最大化之间的权衡。
将lyapunov函数的队列积压推到一个域中,使l(θ(t))≤m(m是一个常数),会帮助稳定各个队列,以保证约束条件得到满足。但是要在满足约束的条件下使得目标函数值最大,所以不再单单最小化式(15)来保证队列稳定,而是最小化式(16)来同时控制队列的稳定性以及系统的吞吐量。通过推导式(16)的上界,转而最小化该上界,来达到相同的效果。下面推导漂移惩罚函数的上界:
其中的b是一个常数,它满足:
需要设计一个调度算法去最小化式(17)得到的漂移惩罚函数的上界。根据机会主义最小化期望的思想,最小化如下不等式右边的项同样可以达到目的。
为了强调出基站向用户k的终端缓存中发送其所需数据包的速率取决于调度策略和信道状态,记
这个算法满足
定义
其中,
- 还没有人留言评论。精彩留言会获得点赞!