一种应用于聚集用户场景下的大规模MIMO系统预编码方法与流程
本发明属于移动通信技术及多天线技术领域,涉及一种小区内同频干扰的抗干扰方法,尤其涉及一种应用于聚集用户场景下的大规模mimo系统预编码方法。
背景技术:
目前,随着无线通信技术和移动互联网的飞速发展,人们不断地对移动通信速率提出更高的要求。然而,无线通信系统中可用频谱和发射功率等系统资源都是有限的,无法满足日益增长的速率要求。大规模mimo(multiple-inputmultiple-output)系统通过在基站配置众多天线数(几十甚至上百根),并且基站天线数量远远大于基站同时服务的用户数量,使得基站到各个用户间的信道相互正交,从而能够获得更高的频谱效率、更好的功率效能,以及较低的检测复杂度等,并已成为第五代移动通信的关键技术之一。但是,上诉优点的获得是假设放置在基站的大规模天线阵列的各个天线相互间独立,即用户到各根天线的信道相互独立。然而,在实际场景中,这一理想条件将难以实现。首先,受限于基站的空间限制,当放置如此数量的天线时,天线间的间距必然无法太大;其次,基站往往布置在建筑物顶端或者天花板上端,周围散射体是较为稀疏的,导致需要较远的天线间距才能使天线间的相关性去除。因此,在大规模天线系统中,实际上天线间的相关性是难以避免的。由此将导致大规模天线系统信道矩阵的秩(rank)实际上是小于终端数目的,这将使得线性预编码的效果大打折扣。
此外,对于用户终端的行为研究表明,用户终端在地理位置上往往具有聚集效应,即用户终端往往会聚集在一个较小的范围内。例如,校园内的终端往往不会在整个校园内均匀分布,而是会聚集在各个教室和实验室内;大型的商业中心中,终端更趋向于聚集在各个专柜或娱乐设施前。此时,考虑到聚集在一起的终端周边环境相类似,与天线阵列的相对位置接近,基站到这些终端的下行信道矢量(假设终端配置单天线)存在较大的相关性,若采用基于迫零准则的预编码,则由基站到这些终端所组成的下行信道矩阵是准病态的,即在信道矩阵的自相关矩阵的非零特征值中,最小特征值会远小于最大特征值,导致迫零预编码会极大地放大发射信号功率,使性能下降。并且,在大规模mimo系统中,由于用户数较大,基于迫零的预编码算法的复杂度也是需要考虑的问题。
故,针对目前现有技术中存在的上述缺陷,实有必要进行研究,以提供一种方案,解决现有技术中存在的缺陷。
技术实现要素:
有鉴于此,确有必要提供一种应用于聚集用户场景下的大规模mimo系统预编码方法,采用两级预编码方法,从而能够有效的降低了计算复杂度,并取得较好的性能。
为了解决现有技术存在的技术问题,本发明的技术方案如下:
一种应用于聚集用户场景下的大规模mimo系统预编码方法,包括以下步骤:
步骤s1:基站根据用户终端的信道状态信息(csi)获取各个终端信号的到达角;
步骤s2:基站根据到达角,对用户终端进行分簇;其中,对第l簇的按到达角顺序排列
步骤s3:利用每簇的信道状态信息(csi)设计各簇用户终端的外层预编码矩阵w=[w1,…,wl],具体设计步骤如下:
令
基于迫零预编码(zf)设计外层预编码矩阵
得到外层预编码矩阵w=[w1,…,wl];
步骤s4:根据每簇的信道状态信息(csi)并结合外层的预编码w获取等效的信道状态信息(csi)矩阵
步骤s5:基站根据等效的csi矩阵
步骤s6:由外层预编码矩阵w和内层预编码矩阵q得到预编码矩阵f=wq,基站利用预编码矩阵f向用户发送数据。
优选地,在步骤s1中进一步包括以下步骤:
基站发送下行导频训练;
用户终端根据接收到的导频序列计算出各自的信道状态信息(csi);
用户终端通过反馈链路将信道状态信息(csi)反馈给基站;
基站根据反馈链路信号计算各个终端信号的到达角θk。
优选地,在步骤s2中,
如果第l簇第i个用户不存在,即
优选地,在步骤s2中,
通过设定到达角阈值对用户终端进行分簇,当不同终端的到达角小于该阈值,则将这些终端划分为一个簇。
优选地,在步骤s6中,
对于第l簇的用户数据为
优选地,还包括以下步骤:
用户终端接收基站发送的数据进行解码的步骤。
与现有技术相比较,本发明采用两级预编码方法,从而能够有效的降低了计算复杂度,并取得较好的性能。
附图说明
图1为本发明应用场景的示意图。
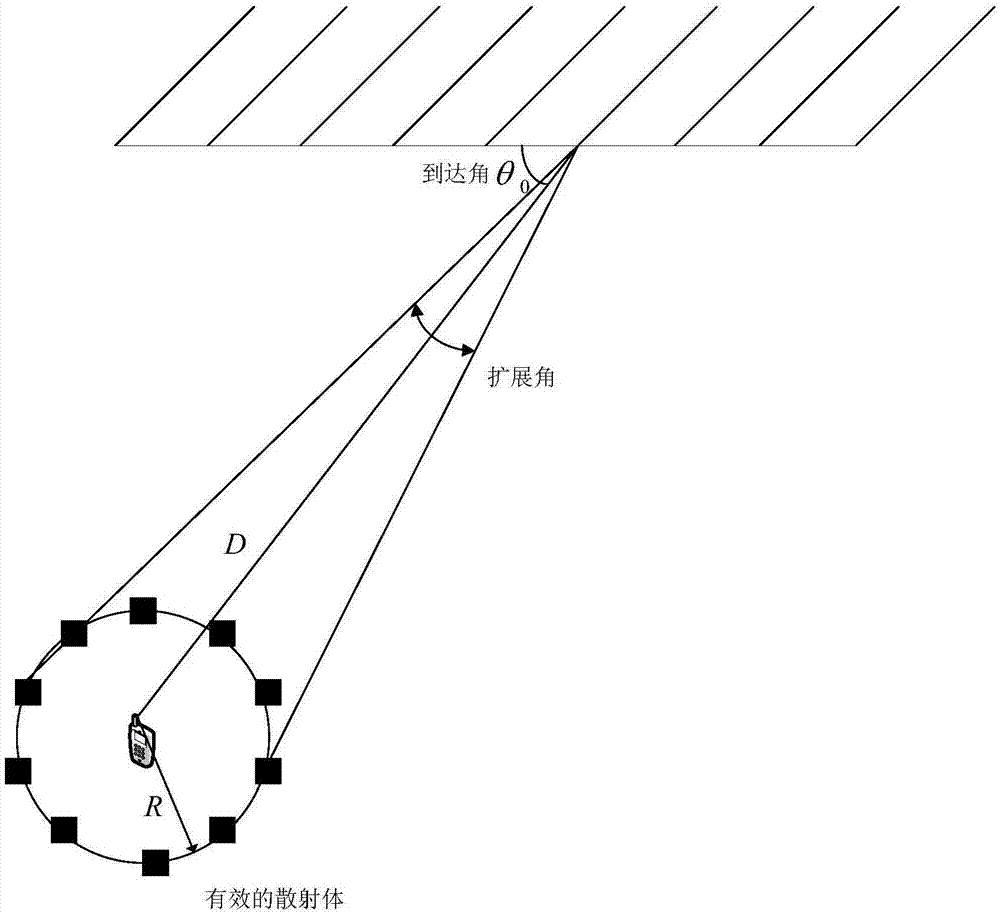
图2为本发明中用户终端信号到达基站的到达角示意图。
图3为本发明应用于聚集用户场景下的大规模mimo系统预编码方法的流程框图。
图4为本发明方法中基于gmd-thp预编码系统框图。
图5为本发明方法中基于zf和gmd-thp级联的两级预编码系统框图。
图6为本发明实施例1中三种预编码方法的性能比较。
图7为本发明实施例2中三种预编码方法的性能比较。
图8为本发明实施例3中三种预编码方法的性能比较。。
如下具体实施例将结合上述附图进一步说明本发明。
具体实施方式
以下将结合附图对本发明提供的技术方案作进一步说明。
在描述本发明的具体技术方案前,先对部分缩写及符号进行定义和系统模型介绍。上标h表示求共轭转置操作,上标t表示求转置操作,上标-1表示取逆操作。
参见图1,所示为本发明应用场景的示意图。考虑一个下行的多用户系统,基站配置nt根发射天线,同时服务于k个单天线用户。本发明表示f=[f1,…fk]∈cnt×k为发射波束,
y=hfu+n
其中,h表示基站到用户的信道矩阵,
为了便于说明本发明的技术方案,参见图2,所示为大规模阵列天线用户到达角示意图,采用简单的lee信道模型,假设有j个散射体均匀的放置在以移动台为中心的半径为r的圆环上,每个一个散射体都代表了实际传播环境中很多散射体所起的作用。第i个有效散射体与基站天线阵列的到达角可以表示为
参见图3至图5,所示为本发明用用于聚集用户场景下的大规模mimo系统预编码方法的流程框图,具体包括如下步骤:
步骤s1:基站发送下行导频训练,用户根据接收到的导频序列估计出各自的信道状态信息(csi)并通过反馈链路进行反馈,基站根据反馈链路信号估计各个终端信号的到达角θk,不失一般性,假设θk≥…≥θk≥θk-1≥…θ1。
步骤s2:基站根据所有终端的到达角,将小区内的所有用户分成l簇。第l簇的用户信道为
步骤s3:基站利用反馈获得的所有终端的csi,设计外层的预编码矩阵w=[w1,…,wl],用于消除部分簇间干扰。
其中,令
步骤s4:根据步骤2得到的信道状态信息,并结合外层的预编码w得到等效的csi矩阵
步骤s5:基站根据等效的csi矩阵
基于zf-gmd-thp的设计,
步骤s6:由外层预编码矩阵w和内层预编码矩阵q得到预编码矩阵f=wq。
对于第l簇的用户数据为
在一种优选实施方式中,还包括以下步骤:
用户终端接收基站发送的数据进行解码的步骤。其为编码过程的逆过程,这里简单介绍些具体的解码过程:
对于第l簇用户接收到的信号为yl,通过接收矩阵
下面通过具体实例对聚集用户场景下的大规模mimo系统预编码方法进行详细说明。
实施例1
设置基站天线数目m=50,用户天线数为k=4,用户分为l=2簇,每组有
参见图6,所示为实施例1的性能仿真图,分别采用三种预编码方法得到的系统的误比特率,其中‘zf’表示基站已知对所有的下行csi矩阵h,采用zf预编码的仿真性能。‘zf-gmd-thp’表示基站已知对所有的下行csi矩阵h,采用zf-gmd-thp预编码的仿真性能;‘zf-gmd-thpclusters’表示基站已知对所有的下行csi矩阵h,采用zf预编码和zf-gmd-thp预编码的级联预编码的仿真性能;可以看出,本发明提出的方法大约有1.5db的性能损耗,但是zf预编码的复杂度为k3,本发明提出的方法的计算复杂度为
实施例2
设置基站天线数目m=100,用户天线数为k=12,假设用户的到达角分别是:
实施例3
设置基站天线数目m=100,用户天线数为k=12。假设用户的到达角分别是:
以上实施例的说明只是用于帮助理解本发明的方法及其核心思想。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也落入本发明权利要求的保护范围内。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!