一种多用户大规模MIMO混合预编码能效优化方法与流程
本发明属于无线通信技术领域,更具体地,涉及一种多用户大规模mimo混合预编码能效优化方法。
背景技术:
多输入多输出(multiple-inputmultiple-output,mimo)是一种在无线通信系统中采用多根天线收发数据的无线通信技术,它将所传输的信息经过空时编码形成多个子信息流,并由多根天线发射出去。大规模mimo技术在传统mimo系统的基础上,将收发天线增加到几十甚至上百根。大规模mimo系统作为一种新的无线通信技术,保留了传统mimo系统优点的同时,大量增加天线数量,使得系统容量随之大大增加,决定了大规模mimo系统具有很好的发展前景。
5g要求容量提升1000倍。为满足容量需求,大规模mimo和毫米波已成为公认的2个关键技术。但在大规模mimo和毫米波场景下,传统的全数字预编码需要大量的射频链路,引入高昂的硬件成本和大量的能耗。在此背景下,为降低能耗和成本,分为基带预编码和射频预编码的混合预编码,可以使用更少的射频链路,成为很有前景的一项技术。与此同时,随着天线数量增多,带宽扩大,用于线性处理等计算功能的功率显著增加:对于微小区基站,主要执行计算功能的基带所消耗的功率占总功率的40%以上,即使是宏基站,也占10%以上。
因此,在大规模mimo场景下,如何有效地提高能量效率是业界亟需解决的难题。
技术实现要素:
针对现有技术的以上缺陷或改进需求,本发明的目的在于提供了一种多用户大规模mimo混合预编码能效优化方法,由此解决现有的大规模mimo场景下的能量效率较低的技术问题。
为实现上述目的,按照本发明的一个方面,提供了一种多用户大规模mimo混合预编码能效优化方法,包括如下步骤:
s1、获取大规模mimo基站无约束条件时的能效
s2、迭代求解得到基带预编码复矩阵bbb以及射频预编码复矩阵brf,使得brfbbb最大化逼近bopt,从而使得基站能效最大化逼近理论上限
优选地,步骤s1具体包括如下子步骤:
s1.1、初始化i=0,并对b(i)随机赋值,其中,上标(i)表示第i次迭代;
s1.2、由
s1.3、由
s1.4、对于不同μ取值时的temp_b(i+1)(μ),选取使基站能效最大的temp_b(i+1)(μ),并使得b(i+1)=temp_b(i+1)(μ);
s1.5、令i=i+1,若||b(i+1)-b(i)||f≥第一预设门限值,则跳转执行步骤s1.2,否则得到使得
优选地,步骤s2具体包括如下子步骤:
s2.1、初始化i=0,并随机初始化brf(i);
s2.2、根据brf(i)计算得到bbb(i+1);
s2.3、由phase(brf(l,j))=phase(bopt(l,:)bbb(j,:)h),1≤l≤nt,
s2.4、若||bopt-brf(i+1)bbb(i+1)||f≤第二预设门限值,则令
优选地,步骤s2.2具体包括如下子步骤:
s2.2.1、对
s2.2.2、求解
总体而言,本发明方法与现有技术方案相比,能够取得下列有益效果:通过先松弛约束条件,迭代求得基站能效的理论上限。然后以最大逼近理论上限为目标设计基带预编码矩阵和射频预编码矩阵。使用交替最小化的方法,迭代逼近理论上限。不仅可以显著提高能量效率,也可以降低成本效率。
附图说明
图1为本发明实施例公开的一种大规模mimo混合预编码系统图;
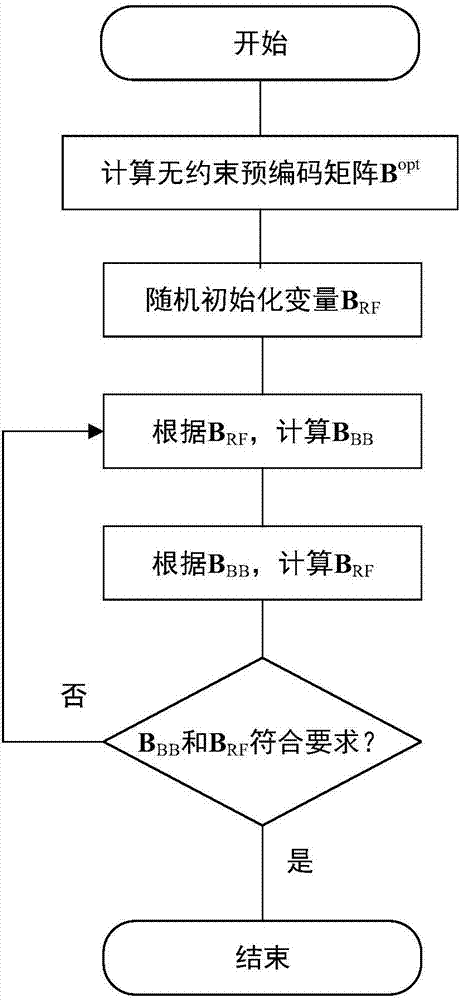
图2为本发明实施例公开的一种多用户大规模mimo混合预编码能效优化方法的流程示意图;
图3为本发明实施例公开的一种仿真结果图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
如图1所示为本发明实施例公开的一种大规模mimo混合预编码系统图,考虑单小区多用户的大规模mimo系统。有k个活跃用户,每个用户都为单天线。基站有k个基带数据流流入,配备有nrf根射频链路,每根射频链路链接一个天线子阵列。基站共有nt根天线,所以每个天线子阵列上有
基站总传输速率rsum可以表示为:
其中,w是带宽,
基站总功率ptotal可以表示为:
其中,α为功率放大器的效率,pshifter表示一个射频移相器的功率,prf_per_chain是一个射频链路的功率,u=wc·tc表示相干块,wc,tc分别表示相干带宽和相干时间,τ是使导频能够正交的因子,lbs基站计算效率,pcod为信道编码的效率,pfix表示基站固定功率。||||f表示f范数。
基站能效最大化的优化问题可以表示为:
其中,ηee(brf,bbb)表示基站能效,自变量有brf,bbb。
如图2所示为本发明实施例公开的一种多用户大规模mimo混合预编码能效优化方法的流程示意图,包括以下步骤:
s1、获取大规模mimo基站无约束条件时的能效
其中,
其中,步骤s1具体包括如下子步骤:
s1.1、初始化i=0,并对b(i)随机赋值,其中,上标(i)表示第i次迭代;
s1.2、由
由
w表示带宽,hj表示基站到第j个用户的下行信道,bj表示b的第j列,pshifter表示一个射频移相器的功率,prf_per_chain表示一个射频链路的功率,u=wc·tc表示相干块,wc,tc分别表示相干带宽和相干时间,τ是使导频能够正交的因子,lbs表示基站计算效率,pcod表示信道编码的效率,pfix表示基站固定功率,||||f表示f范数,
s1.3、由
其中,步骤s1.3的具体实现方式为:
在第一层循环中令
s1.4、对于不同μ取值时的temp_b(i+1)(μ),选取使基站能效最大的temp_b(i+1)(μ),并使得b(i+1)=temp_b(i+1)(μ);
s1.5、令i=i+1,若||b(i+1)-b(i)||f≥第一预设门限值,则跳转执行步骤s1.2,否则得到使得
其中,第一预设门限值可以根据实际需求进行确定。
s2、求解基带预编码复矩阵bbb以及射频预编码复矩阵brf,使得brfbbb逼近bopt,从而使得基站能效逼近理论上限
其中,步骤s2具体包括如下子步骤:
s2.1、初始化i=0,并随机初始化brf(i);
s2.2、根据brf(i)计算得到bbb(i+1);
s2.3、由phase(brf(l,j))=phase(bopt(l,:)bbb(j,:)h),1≤l≤nt,
s2.4、若||bopt-brf(i+1)bbb(i+1)||f≤第二预设门限值,则令
其中,第二预设门限值可以根据实际需求进行确定。
其中,步骤s2.2具体包括如下子步骤:
s2.2.1、对
其中,
s2.2.2、由
总体而言,和现行混合预编码算法相比,本发明能够取得如下增益:能量效率最高可以提升189.72%。成本效率最高可以提升9.13倍。
图3为能量效率随射频通道数变化的仿真图。图中天线数设定为200,用户数设定为5。从仿真图可以看出,本发明提出的基于子阵列结构的算法比原全连接结构下的算法在能量效率上更优。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!