一种适用于多普勒失真水声信道的估计方法与流程
本发明涉及水声通信信道估计算法技术领域,尤其是一种适用于多普勒失真水声信道的估计方法。
背景技术:
水声信道中显著的多普勒效应和严重的多径扩展给高速稳定的通信带来了很大的挑战。在水声系统中,声波的传输速度为1500m/s,远远低于陆地无线通信中电磁波的传播速度。因此,收发端移动引起的多普勒效应十分显著,表现为引起时域上信号的压缩或扩展。因此,多普勒效应被处理为多普勒扩展因子。另一方面,严重的多径效应是由水下环境中大量的反射导致。由于声波传播速度慢,多径延时大,造成了严重的符号间干扰。为充分了解水声信道特点并克服其带来的挑战,对水声信道精确的建模和估计十分重要。
如很多实验观察到的一样,不同路径的信号经历不同的多普勒扩展,在不同的时间点到达且具有不同的能量,接收信号是这些不同路径信号的叠加。所以多扩展多时延(multi-scalemulti-lag,msml)信道模型能够较好的描述水声信道的特点,为很多文献采用。根据msml信道模型,每一条路径可以被参数化为多普勒扩展因子、时延和幅度三个参数。然而,严重的多径效应使得msml信道的估计过于复杂。为了克服这个困难,很多研究者提出利用水声信道的稀疏特性,即大部分信道能量集中在较小的范围内。所以,msml信道模型中,只有较少的抽头系数是非零的,需要被估计出来。因此,计算复杂度可以显著降低,并且很多利用信道稀疏特性的压缩感知算法得到了应用。
基于压缩感知的算法主要分为两类:动态规划方法,如匹配追踪(matchingpursuit,mp);线性规划方法,如基追踪(basispursuit,bp)。bp算法较高的计算复杂度限制了其应用,而mp算法得到了较为广泛的应用且出现了很多改进算法。
mp算法通过迭代选取字典中与接收信号相关性最大的列来进行信道估计,并且在每次迭代结束时,从接收信号中减去相应的估计分量。在此基础上,通过使剩余信号与已选出的每一列正交,提出了正交匹配追踪(orthogonalmatchingpursuit,omp)算法,omp算法具有更优的估计精度和收敛速度。同时,也有一些算法提出自适应估计路径数,如稀疏自适应匹配追踪(sparsityadaptivematchingpursuit,samp)算法和自适应步长samp算法。进一步,为了降低计算量,有文献提出使用快速傅里叶变换简化omp算法,但该方法降低的计算量有限因为其并没有改变字典本身的大小。另一种降低计算量的方法是分步估计时延和多普勒扩展,该方法仅适用于各条路径的多普勒扩展相差较小且经过了粗补偿的情况。
因此,mp算法及其改进算法的不足之处在于其估计精度依赖于字典的大小,估计精度越高则字典的列数越多,因而计算量也就更大。对于时延-多普勒扩展较大的水声信道,mp算法的计算复杂度限制了高精度的参数估计,因而本发明提出了一种可以降低复杂度同时有较高的估计精度的估计算法。
技术实现要素:
本发明所要解决的技术问题在于,提供一种适用于多普勒失真水声信道的估计方法,能够有较快的收敛速度和较高的估计精度。
为解决上述技术问题,本发明提供一种适用于多普勒失真水声信道的估计方法,包括如下步骤:
(1)在问题空间中初始化鱼群位置,计算相应的适应度值,并将群体中最优适应度值和对应的位置记录在公告板上,进入子迭代过程;
(2)每一条人工鱼在其视野范围内执行聚群和追尾行为或觅食行为,更新自身位置和适应度值并更新公告板;
(3)当子迭代次数大于设定值的一半时,若公告板中最优适应度值大于设定阈值且不发生变化,则将一半的人工鱼位置设置为最优适应度值对应的位置;
(4)循环执行子迭代过程并不断调整步长,直至达到最大子迭代次数;
(5)从公告板中得到最优位置,作为一条路径的参数,得到相应的信号分量,用以更新残余信号,进入下一次迭代。
优选的,步骤(1)中,问题空间即为路径参数可能的取值空间,包括时延和多普勒扩展因子的取值范围,一般认为最大时延扩展为训练序列的时间长度,最大多普勒扩展为收发端最大相对运动速度与声波在海水中的速度的比值。
优选的,步骤(1)中,人工鱼p的适应度值的计算公式为:
其中r(t)为接收信号,s(t)为训练序列,xp为人工鱼p的位置,
优选的,步骤(2)中,觅食行为是:人工鱼p在其视野范围内随机选取一个位置,若该位置的适应度值大于当前位置的适应度值,则向该位置移动一步;否则继续尝试,若尝试次数大于设定的最大值仍未成功,则随机移动一步。
优选的,步骤(2)中,聚群行为是:人工鱼p在其视野范围内有q个同伴,若q>0,计算q个同伴的中心位置xc和相应的适应度值yc,若yc/q>λyp,其中λ为拥挤度因子,则p向xc移动一步;若yc/q≤λyp或q=0,则执行觅食行为。
优选的,步骤(2)中,追尾行为是:人工鱼p在其视野范围内内有q个同伴,若q>0,找到具有最优适应度值的同伴xq,若其适应度值yq满足yq/q>λyp,则p向xq移动一步,若yq/q≤λyp或q=0,则执行觅食行为。
优选的,步骤(4)中,第k次子迭代步长的调整方法是:
其中,δ为初始步长,k为第k次子迭代,kmax为子迭代最大次数。
优选的,步骤(5)中,更新剩余信号的方法是:
其中,sl和
本发明的有益效果为:本发明提供的一种多普勒失真水声信道估计方案,每一次迭代包含一个子迭代过程和利用估计出的参数更新剩余信号的过程;在子迭代中,自适应步长调整和人工鱼位置调整将使得在最优值附近的搜索更为精确;该方案有较快的收敛速度和较高的估计精度,在计算量和估计准确度上均优于omp算法。
附图说明
图1为本发明的用bellhop产生的水声信道声线图。
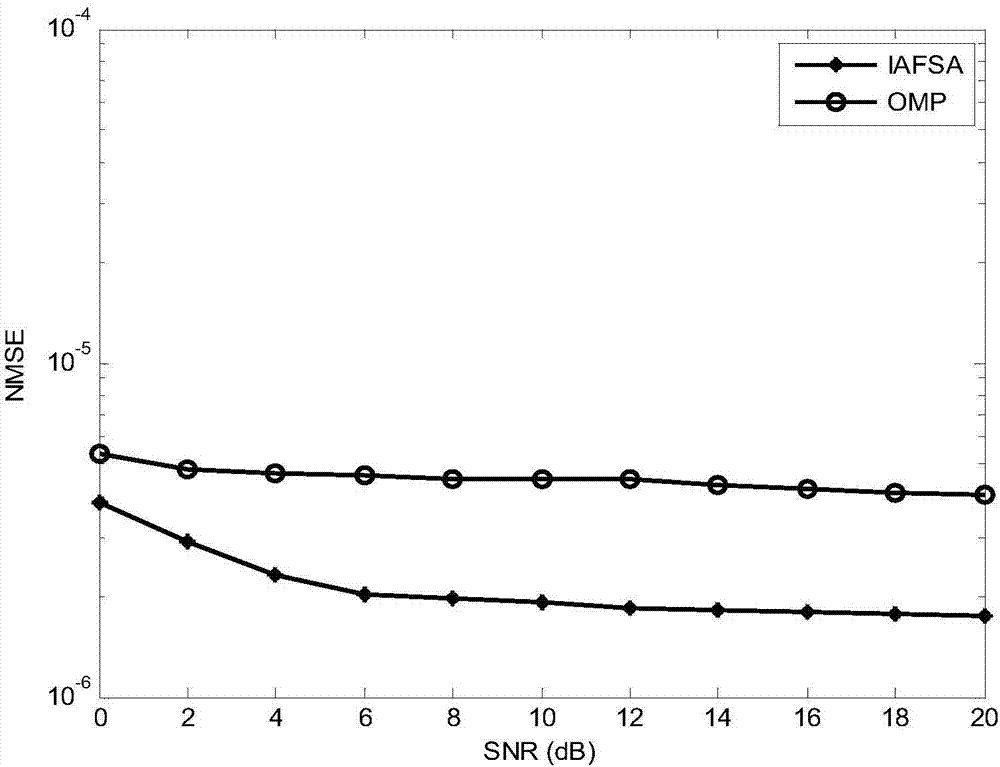
图2为本发明在信道1中,多普勒扩展因子估计的归一化均方误差随信噪比的变化而变化的仿真曲线示意图。
图3为本发明在信道1中,时延估计误差随信噪比的变化而变化的仿真曲线示意图。
图4为本发明在信道1中,剩余信号能量比随信噪比的变化而变化的仿真曲线示意图。
图5为本发明在信道2中,多普勒扩展因子估计的归一化均方误差随信噪比的变化而变化的仿真曲线示意图。
图6为本发明在信道2中,时延估计误差随信噪比的变化而变化的仿真曲线示意图。
图7为本发明在信道2中,剩余信号能量比随信噪比的变化而变化的仿真曲线示意图。
具体实施方式
一种适用于多普勒失真水声信道的估计方法,在鱼群算法的基础上,以迭代的方式分离多径分量,每一次的迭代过程包含一个子迭代和利用估计出的参数对残余信号的更新;在子迭代中,自适应的调整人工鱼的位置和步长。包括如下步骤:
(1)在问题空间中初始化鱼群位置,计算相应的适应度值,并将群体中最优适应度值和对应的位置记录在公告板上,进入子迭代过程;
(2)每一条人工鱼在其视野范围内执行聚群和追尾行为或觅食行为,更新自身位置和适应度值并更新公告板;
(3)当子迭代次数大于设定值的一半时,若公告板中最优适应度值大于设定阈值且不发生变化,则将一半的人工鱼位置设置为最优适应度值对应的位置;
(4)循环执行子迭代过程并不断调整步长,直至达到最大子迭代次数;
(5)从公告板中得到最优位置,作为一条路径的参数,得到相应的信号分量,用以更新残余信号,进入下一次迭代。
步骤(1)中,问题空间即为路径参数可能的取值空间,包括时延和多普勒扩展因子的取值范围,一般认为最大时延扩展为训练序列的时间长度,最大多普勒扩展为收发端最大相对运动速度与声波在海水中的速度的比值。
步骤(1)中,人工鱼p的适应度值的计算公式为:
其中r(t)为接收信号,s(t)为训练序列,xp为人工鱼p的位置,
步骤(2)中,觅食行为是:人工鱼p在其视野范围内随机选取一个位置,若该位置的适应度值大于当前位置的适应度值,则向该位置移动一步;否则继续尝试,若尝试次数大于设定的最大值仍未成功,则随机移动一步。
步骤(2)中,聚群行为是:人工鱼p在其视野范围内有q个同伴,若q>0,计算q个同伴的中心位置xc和相应的适应度值yc,若yc/q>λyp,其中λ为拥挤度因子,则p向xc移动一步;若yc/q≤λyp或q=0,则执行觅食行为。
步骤(2)中,追尾行为是:人工鱼p在其视野范围内内有q个同伴,若q>0,找到具有最优适应度值的同伴xq,若其适应度值yq满足yq/q>λyp,则p向xq移动一步,若yq/q≤λyp或q=0,则执行觅食行为。
步骤(4)中,第k次子迭代步长的调整方法是:
其中,δ为初始步长,k为第k次子迭代,kmax为子迭代最大次数。
步骤(5)中,更新剩余信号的方法是:
其中,sl和
如图1所示,msml水声信道模型可以表示为:
其中,l是信道抽头数.al(t)是第l条路径的时变路径幅度,在较短的时间内可以认为保持恒定。τl和al分别是第l条路径的时延和多普勒扩展因子,δ(t)是单位冲激响应函数:
令s(t)表示发射信号,相应的接收信号r(t)可以写成:
其中w(t)是加性噪声。
考虑到水声信道的稀疏特性,只有少数抽头系数非零。所以,信道估计的复杂度大大减小。
在接收端,采用iafsa进行水声信道估计。令xp表示人工鱼p的位置:
其中p为鱼群大小,n为维数。这里n=2,
则位置xp对应的适应度值为:
其中r(t)为接收信号,s(t)为训练序列,xp为人工鱼p的位置,
定义两条人工鱼xp和xq之间的距离为
人工鱼的觅食行为:
令人工鱼p的当前位置为xp,其在视野范围内随机选取位置xv。如果yv>yp,则该鱼将向xv,移动一步,即:
其中δ是步长,这个过程将重复i次直到有一个xv满足要求;否则,该人工鱼将在视野范围内随机选取一点。
人工鱼的聚群行为:
令xp为人工鱼p的当前位置,其视野范围内有q个同伴,如果q>0,计算这q个同伴的中心位置:
定义λ为拥挤度因子,如果yc/q>λyp,则人工鱼p将会向xc移动一步;否则,将执行觅食行为。若q=0人工鱼也将执行觅食行为。
人工鱼的追尾行为:
人工鱼p的视野范围内有q个同伴,如果q>0,找到具有最大适应度值yq的同伴xq。若yq/q>λyp,人工鱼p将向xq移动一步,若yq/q≤λyp或者q=0,人工鱼p将执行觅食行为。
详细的算法步骤如下:
输入:
发射信号向量s;接收信号向量r;路径数l;阈值ε。
初始化:
设置剩余信号re=r拥挤度因子λ,视野范围d,步长δ,尝试次数i,最大子迭代次数kmax,设置l=1。
迭代:
(1)在问题空间内随机初始化鱼群位置xp(p=1,…,p),计算相应的适应度值yp(p=1,…,p),并将最优适应度值yopt及其对应的位置xopt记录到公告板中。
(2)设置计数器k=1。
(3)执行聚群和追尾行为,更新人工鱼位置。
(4)计算相应的适应度值并更新公告板。
(5)当k>kmax/2时,如果公告板保持不变且yopt>ε,将一半的鱼位置调整为xopt。
(6)设置k=k+1,并调整步长为
(7)从公告板选择最优位置xopt作为路径l的时延和多普勒因子估计值,得到相应的时延-多普勒训练序列sl,和最优适应度值yopt作为路径l的幅度估计值
(8)如果l=l,停止迭代;否则,l=l+1,跳至步骤1.
输出:
估计参数对
注:路径数l可以在信号同步阶段获得;阈值ε根据接收端所能够检测到的信号能量值来设定。
图2—图7给出了不同信道条件下,多普勒扩展因子估计的归一化均方误差、时延估计误差和剩余信号能量比随信噪比的变化而变化的仿真曲线,并与omp算法做了比较。其中,信道1的参数设置为:路径数l=10,各路径信号的到达时间随机分布在0~25ms,且将最小路径时延设为0。归一化路径幅值均匀分布,多普勒扩展因子随机分布在[1,1.02],精确到4位小数。采用长度为511的伪随机序列作训练序列,且用二进制相移键控调制。载波频率为10khz,采样率为20khz。对于omp算法,所构造的字典多普勒因子分辨率为1×10-4,时延分辨率为0.1ms,多普勒扩展为0.02,时延扩展为25ms,这也是iafsa的问题空间。
iafsa的参数设置为:鱼群大小为50,拥挤度因子为0.3,视野范围为[0.005,1.0ms],初始步长为0.2,最大子迭代次数等于10,最大尝试次数等于10,阈值ε=0.2。
信道2采用bellhop产生:水深为100m,收发端水平距离2000m,发射端固定在80m深处,接收端位于50m深处,以15m/s的水平速度向发射端靠近,声速设定为1500m/s。海面和海底的反射系数分别为-0.9和0.7,声线图如图1所示。iafsa的参数与信道1中相同,仅将问题空间中多普勒扩展改为0.01。
从仿真图可见,在所有的实施例中本发明的性能都明显优于omp算法。在计算复杂度上:设训练序列长度为kl,对于omp算法,字典中的列数为n=nanτ,为时延和多普勒网格数之积。因此,一次迭代的乘积运算为ρ=nkl。对于信道1,nτ=250,na=200,因而n=5×104;对于信道2,nτ=250,na=100,因而n=2.5×104。
而对于iafsa,信道1和信道2中,每一次迭代包含的子迭代过程中,人工鱼分别执行聚群和追尾行为,最差的情况下需要搜索2i次,因而一次迭代的乘积运算为ρ=klpkmax2i,即ρ=1×104。可见,本发明的计算复杂度优于omp算法。
尽管本发明就优选实施方式进行了示意和描述,但本领域的技术人员应当理解,只要不超出本发明的权利要求所限定的范围,可以对本发明进行各种变化和修改。
- 还没有人留言评论。精彩留言会获得点赞!